 阿里巴巴内部Flink版本Blink正式开源
阿里巴巴内部Flink版本Blink正式开源
如同我们去年12月在 Flink Forward China 峰会所约,阿里巴巴内部 Flink 版本Blink 将于2019 年 1 月底正式开源。今天,我们终于等到了这一刻。
阿里资深技术专家大沙,将为大家详细介绍本次开源的Blink主要功能和优化点,希望与业界同仁共同携手,推动Flink社区进一步发展。
Blink简介
ApacheFlink是德国柏林工业大学的几个博士生和研究生从学校开始做起来的项目,早期叫做Stratosphere。2014年,StratoSphere项目中的核心成员从学校出来开发了Flink,同时将Flink计算的主流方向定位为流计算,并在同年将Flink捐赠Apache,后来快速孵化成为Apache的顶级项目。现在Flink是业界公认的最好的大数据流计算引擎。
阿里巴巴在2015年开始尝试使用Flink。但是阿里的业务体量非常庞大,挑战也很多。彼时的Flink不管是规模还是稳定性尚未经历实践,成熟度有待商榷。为了把这么大的业务体量支持好,我们不得不在Flink之上做了一系列的改进,所以阿里巴巴维护了一个内部版本的Flink,它的名字叫做Blink。
基于Blink的计算平台于2016年正式上线。截至目前,阿里绝大多数的技术部门都在使用Blink。Blink一直在阿里内部错综复杂的业务场景中锻炼成长着。对于内部用户反馈的各种性能、资源使用率、易用性等诸多方面的问题,Blink都做了针对性的改进。虽然现在Blink在阿里内部用的最多的场景主要还是在流计算,但是在批计算场景也有不少业务上线使用了。例如,在搜索和推荐的算法业务平台中,它使用Blink同时进行流计算和批处理。Blink被用来实现了流批一体化的样本生成和特征抽取这些流程,能够处理的特征数达到了数千亿,而且每秒钟处理数亿条消息。在这个场景的批处理中,我们单个作业处理的数据量已经超过400T,并且为了节省资源,我们的批处理作业是和流计算作业以及搜索的在线引擎运行在同样的机器上。所以大家可以看到流批一体化已经在阿里巴巴取得了极大的成功,我们希望这种成功和阿里巴巴内部的经验都能够带回给社区。
Blink开源的背景
其实从我们选择Flink的第一天开始我们就一直和社区紧密合作。过去的这几年我们也一直在把阿里对Flink 的改进推回社区。从2016年开始我们已经将流计算SQL的大部分功能,针对runtime的稳定性和性能优化做的若干重要设计都推回了社区。但是Blink本身发展迭代的速度非常快,而社区有自己的步伐,很多时候可能无法把我们的变更及时推回去。对于社区来说,一些大的功能和重构,需要达成共识后,才能被接受,这样才能更好地保证开源项目的质量,但是同时就会导致推入的速度变得相对较慢。经过这几年的开发迭代,我们这边和社区之间的差距已经变得比较大了。
Blink有一些很好的新功能,比如性能优越的批处理功能,在社区的版本是没有的。在过去这段时间里,我们不断听到有人在询问Blink的各种新功能。期望Blink尽快开源的呼声越来越大。我们一直在思考如何开源的问题,一种方案就是和以前一样,继续把各种功能和优化分解,逐个和社区讨论,慢慢地推回Flink。但这显然不是大家所期待的。另一个方案,就是先完整的尽可能的多的把代码开源,让社区的开发者能够尽快试用起来。第二个方案很快收到社区广大用户的支持。因此,从2018年年中开始我们就开始做开源的相关准备。经过半年的努力,我们终于把大部分Blink的功能梳理好,开源了出来。
Blink开源的方式
我们把代码贡献出来,是为了让大家能先尝试一些他们感兴趣的功能。Blink永远不会单独成为一个独立的开源项目来运作,他一定是Flink的一部分。开源后我们期望能找到办法以最快的方式将Blink merge到Flink中去。Blink开源只有一个目的,就是希望 Flink 做得更好。Apache Flink 是一个社区项目,Blink以什么样的形式进入 Flink 是最合适的,怎么贡献是社区最希望的方式,我们都要和社区一起讨论。
在过去的一段时间内,我们在Flink社区征求了广泛的意见,大家一致认为将本次开源的Blink代码作为Flink的一个branch直接推回到ApacheFlink项目中是最合适的方式。并且我们和社区也一起讨论规划出一套能够快速mergeBlink到Flink master中的方案(具体细节可以查看Flink社区正在讨论的FLIP32)。我们期望这个merge能够在很短的时间内完成。这样我们之后的Machine Learning等其他新功能就可以直接推回到Flink master。相信用不了多久,Flink 和 Blink 就完全合二为一了。在那之后,阿里巴巴将直接使用Flink用于生产,并同时协助社区一起来维护Flink。
本次开源的Blink的主要功能和优化点
本次开源的Blink代码在Flink1.5.1版本之上,加入了大量的新功能,以及在性能和稳定性上的各种优化。主要贡献包括,阿里巴巴在流计算上积累的一些新功能和性能的优化,一套完整的(能够跑通全部TPC-H/TPC-DS,能够读取Hive meta和data)高性能Batch SQL,以及一些以提升易用性为主的功能(包括支持更高效的interactive programming, 与zeppelin更紧密的结合, 以及体验和性能更佳的Flink web)。未来我们还将继续给Flink贡献在AI,IoT以及其他新领域的功能和优化。更多的关于这一版本Blink release的细节,请参考Blink代码根目录下的README.md文档。下面,我来分模块介绍下Blink主要的新的功能和优化点。
Runtime
为了更好的支持batch processing,以及解决阿里巴巴大规模生产场景中遇到的各种挑战,Blink对Runtime架构、效率、稳定性方面都做了大量改进。在架构方面,首先Blink引入了Pluggable ShuffleArchitecture,开发者可以根据不同的计算模型或者新硬件的需要实现不同的shuffle策略进行适配。此外Blink还引入新的调度架构,容许开发者根据计算模型自身的特点定制不同调度器。为了优化性能,Blink可以让算子更加灵活的chain在一起,避免了不必要的数据传输开销。在Pipeline Shuffle模式中,使用了ZeroCopy减少了网络层内存消耗。在BroadCast Shuffle模式中,Blink优化掉了大量的不必要的序列化和反序列化开销。
此外,Blink提供了全新的JM FailOver机制,JM发生错误之后,新的JM会重新接管整个JOB而不是重启JOB,从而大大减少了JM FailOver对JOB的影响。最后,Blink也开发了对Kubernetes的支持。不同于Standalone模式在Kubernetes上的拉起方式,在基于Flink FLIP6的架构上基础之上,Blink根据job的资源需求动态的申请/释放Pod来运行TaskExecutor,实现了资源弹性,提升了资源的利用率。
SQL/TableAPI
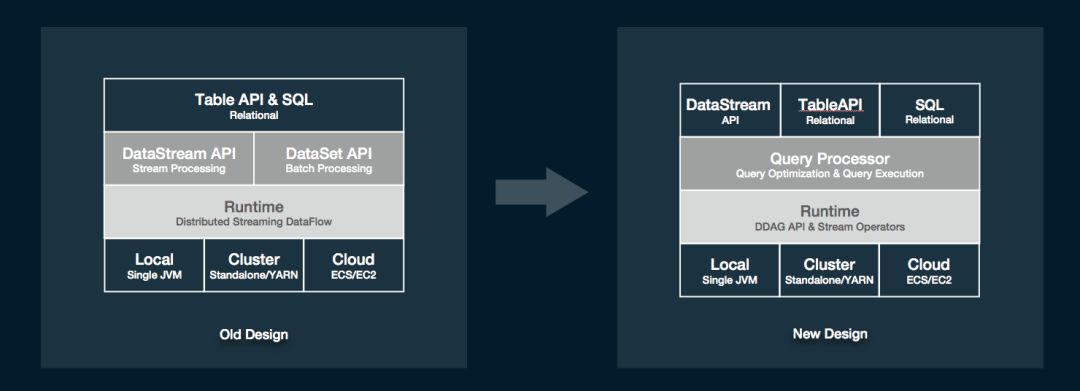
SQL/TableAPI架构上的重构和性能的优化是Blink本次开源版本的一个重大贡献。首先,我们对SQL engine的架构做了较大的调整。提出了全新的Query Processor(QP), 它包括了一个优化层(Query Optimizer)和一个算子层(Query Executor)。这样一来,流计算和批计算的在这两层大部分的设计工作就能做到尽可能的复用。
另外,SQL和TableAPI的程序最终执行的时候将不会翻译到DataStream和DataSet这两个API上,而是直接构建到可运行的DAG上来,这样就使得物理执行算子的设计不完全依赖底层的API,有了更大的灵活度,同时执行代码也能够被灵活的codegen出来。唯一的一个影响就是这个版本的SQL和TableAPI不能和DataSet这个API进行互相转换,但仍然保留了和DataStream API互相转换的能力(将DataStream注册成表,或将Table转成DataStream后继续操作)。未来,我们计划把dataset的功能慢慢都在DataStream和TableAPI上面实现。到那时DataStream和SQL以及tableAPI一样,是一个可以同时描述bounded以及unbounded processing的API。
除了架构上的重构,Blink还在具体实现上做了较多比较大的重构。首先,Blink引入了二进制的数据结构BinaryRow,极大的减少了数据存储上的开销以及数据在序列化和反序列化上计算的开销。其次,在算子的实现层面,Blink在更广范围内引入了CodeGen技术。由于预先知道算子需要处理的数据的类型,在QP层内部就可以直接生成更有针对性更高效的执行代码。
Blink的算子会动态的申请和使用资源,能够更好的利用资源,提升效率,更加重要的是这些算子对资源有着比较好的控制,不会发生OutOfMemory 的问题。此外,针对流计算场景,Blink加入了miniBatch的执行模式,在aggregate、join等需要和state频繁交互且往往又能先做部分reduce的场景中,使用miniBatch能够极大的减少IO,从而成数量级的提升性能。除了上面提到的这些重要的重构和功能点,Blink还实现了完整的SQL DDL,带emit策略的流计算DML,若干重要的SQL功能,以及大量的性能优化策略。
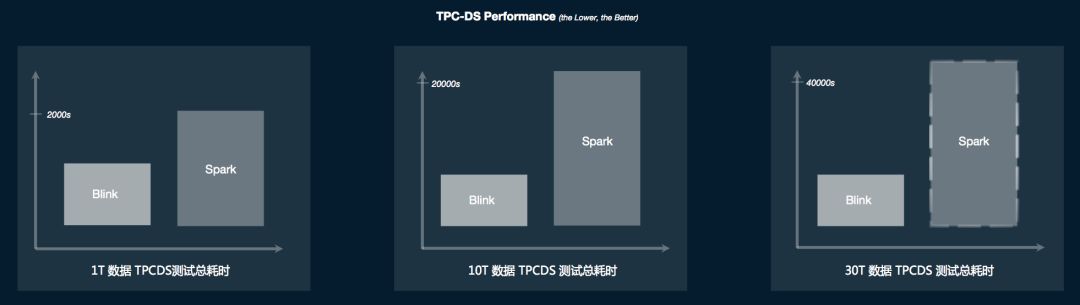
有了上面提到的诸多架构和实现上的重构。Blink的SQL/tableAPI在功能和性能方面都取得了脱胎换骨的变化。在批计算方面,首先Blinkbatch SQL能够完整的跑通TPC-H和TPC-DS,且性能上有着极大的提升。如上图所示,是这次开源的Blink版本和spark 2.3.1的TPC-DS的benchmark性能对比。柱状图的高度代表了运行的总时间,高度越低说明性能越好。可以看出,Blink在TPC-DS上和Spark相比有着非常明显的性能优势。而且这种性能优势随着数据量的增加而变得越来越大。在实际的场景这种优势已经超过 Spark的三倍。在流计算性能上我们也取得了类似的提升。我们线上的很多典型作业,它的性能是原来的3到5倍。在有数据倾斜的场景,以及若干比较有挑战的TPC-H query,流计算性能甚至得到了数十倍的提升。
除了标准的Relational SQL API。TableAPI在功能上是SQL的超集,因此在SQL上所有新加的功能,我们在tableAPI也添加了相对应的API。除此之外,我们还在TableAPI上引入了一些新的功能。其中一个比较重要是cache功能。在批计算场景下,用户可以根据需要来cache计算的中间结果,从而避免不必要的重复计算。它极大的增强了interactiveprogramming体验。我们后续会在tableAPI上添加更多有用的功能。其实很多新功能已经在社区展开讨论并被社区接受,例如我们在tableAPI增加了对一整行操作的算子map/flatMap/aggregate/flatAggregate(FlinkFLIP29)等等。
Hive的兼容性
我们这次开源的版本实现了在元数据(meta data)和数据层将Flink和Hive对接和打通。国内外很多公司都还在用 Hive 在做自己的批处理。对于这些用户,现在使用这次Blink开源的版本,就可以直接用Flink SQL去查询Hive的数据,真正能够做到在Hive引擎和Flink引擎之间的自由切换。
为了打通元数据,我们重构了Flink catalog的实现,并且增加了两种catalog,一个是基于内存存储的FlinkInMemoryCatalog,另外一个是能够桥接Hive metaStore的HiveCatalog。有了这个HiveCatalog,Flink作业就能读取Hive的metaData。为了打通数据,我们实现了HiveTableSource,使得Flink job可以直接读取Hive中普通表和分区表的数据。因此,通过这个版本,用户可以使用Flink SQL读取已有的Hive meta和data,做数据处理。未来我们将在Flink上继续加大对Hive兼容性的支持,包括支持Hive特有的query,datatype,和Hive UDF等等。
Zeppelin for Flink
为了提供更好的可视化和交互式体验,我们做了大量的工作让Zeppelin能够更好的支持Flink。这些改动有些是在Flink上的,有些是在Zeppelin上的。在这些改动全部推回Flink和Zeppelin社区之前,大家可以使用这个Zeppelin image(具体细节请参考Blink代码里的docs/quickstart/zeppelin_quickstart.md)来测试和使用这些功能。这个用于测试的Zeppelin版本,首先很好的融合和集成了Flink的多种运行模式以及运维界面。使用文本SQL和tableAPI可以自如的查询Flink的static table和dynamic table。
此外,针对Flink的流计算的特点,这一版Zeppelin也很好的支持了savepoint,用户可以在界面上暂停作业,然后再从savepoint恢复继续运行作业。在数据展示方面,除了传统的数据分析界面,我们也添加了流计算的翻牌器和时间序列展示等等功能。为了方便用户试用,我们在这一版zeppelin中提供3个built-in的Flink tutorial的例子: 一个是做StreamingETL的例子, 另外两个分别是做Flink Batch,Flink Stream的基础样例。
Flink Web
我们对Flink Web的易用性与性能等多个方面做了大量的改进,从资源使用、作业调优、日志查询等维度新增了大量功能,使得用户可以更方便的对Flink作业进行运维。在资源使用方面,新增了Cluster、TaskManager与Job三个级别的资源信息,使得资源的申请与使用情况一目了然。作业的拓扑关系及数据流向可以追溯至 Operator 级别,Vertex 增加了InQueue,OutQueue等多项指标,可以方便的追踪数据的反压、过滤及倾斜情况。TaskManager 和 JobManager 的日志功能得到大幅度加强,从Job、Vertex、SubTask 等多个维度都可以关联至对应日志,提供多日志文件访问入口,以及分页展示查询和日志高亮功能。
另外,我们使用了较新的Angular 7.0 对Flink web进行了全面重构,页面运行性能有了一倍以上的提升。在大数据量情况下也不会发生页面卡死或者卡顿情况。同时对页面的交互逻辑进行了整体优化,绝大部分关联信息在单个页面就可以完成查询和比对工作,减少了大量不必要的跳转。
未来的规划
Blink迈出了全面开源的第一步,接下来我们会和社区合作,尽可能以最快的方式将Blink的功能和性能上的优化merge回Flink。本次的开源版本一方面贡献了Blink多年在流计算的积累,另一方面又重磅推出了在批处理上的成果。接下来,我们会持续给Flink社区贡献其他方面的功能。我们期望每过几个月就能看到技术上有一个比较大的亮点贡献到社区。下一个亮点应该是对机器学习的支持。要把机器学习支持好,有一系列的工作要做,包括引擎的功能,性能,和易用性。这里面大部分的工作我们已经开发完成,并且很多功能都已经在阿里巴巴内部服务上线了。
除了技术上创新以及新功能之外,Flink的易用性和外围生态也非常重要。我们已经启动了若干这方面的项目,包括Python以及Go等多语言支持,Flink集群管理,Notebook,以及机器学习平台等等。这些项目有些会成为Flink自身的一部分贡献回社区,有些不是。但它们都基于Flink,是Flink生态的一个很好的补充。独立于Flink之外的那些项目,我们都也在认真的考虑开源出来。总之,Blink在开源的第一天起,就已经完全all-in的融入了Flink社区,我们希望所有的开发者看到我们的诚意和决心。
未来,无论是功能还是生态,我们都会在Flink社区加大投入,我们也将投入力量做 Flink 社区的运营,让 Flink 真正在中国、乃至全世界大规模地使用起来。我们衷心的希望更多的人加入,一起把Apache Flink开源社区做得更好!
-
源码
+关注
关注
8文章
573浏览量
28585 -
阿里
+关注
关注
6文章
428浏览量
32695
原文标题:阿里正式向 Apache Flink 贡献 Blink 源码
文章出处:【微信号:TheBigData1024,微信公众号:人工智能与大数据技术】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
阿里巴巴减持小鹏汽车股份至9.24%
阿里巴巴推出全新AI图生视频模型EMO
阿里巴巴重返中国顶级电商轨道
阿里巴巴涨超3% 财报或超预期
阿里巴巴推出自主多模态AI代理MobileAgent
软银子公司确认减持阿里 阿里巴巴最大股东易主
软银已完成减持阿里巴巴股份
马云大幅增持阿里股票 马云取代软银成为阿里巴巴最大股东
镭神智能入选阿里巴巴诸神之战2023年度智能制造赛道之星

深夜,阿里巴巴“出售”小鹏?
2023云栖大会 阿里巴巴要打造AI时代最开放的云
英特尔携手阿里巴巴制定多重优化方案,助力阿里Noslate吞吐量提升49%至61%






 工商网监
工商网监
评论