 来看看Pythoner志朋的爬虫实验
来看看Pythoner志朋的爬虫实验
下面我们来看看Pythoner志朋的爬虫实验。
一、使用的技术栈:
爬虫:python27 +requests+json+bs4+time
分析工具: ELK套件
开发工具:pycharm
二、数据成果
爬取了知乎部分的用户数据信息。
三、简单的可视化分析
1.性别分布
0 绿色代表的是男性 ^ . ^ ——1代表的是女性———— -1 性别不确定
可见知乎的用户男性颇多。
2.粉丝最多的top30
粉丝最多的前三十名:依次是张佳玮、李开复、黄继新等等,去知乎上查这些人,也差不多这个排名,说明爬取的数据具有一定的说服力。
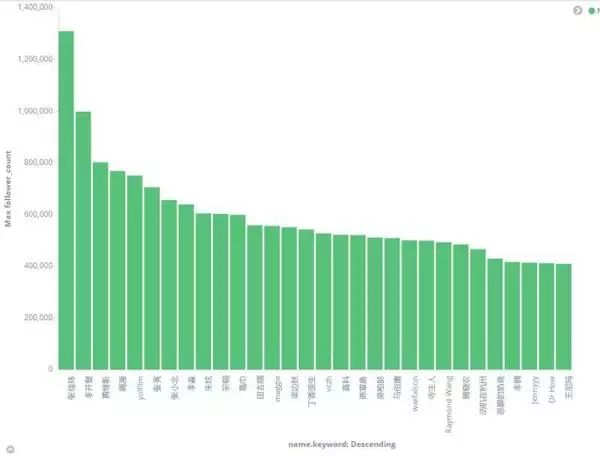
3.写文章最多的top30
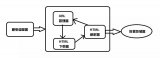
四、爬虫架构
爬虫架构图如下:
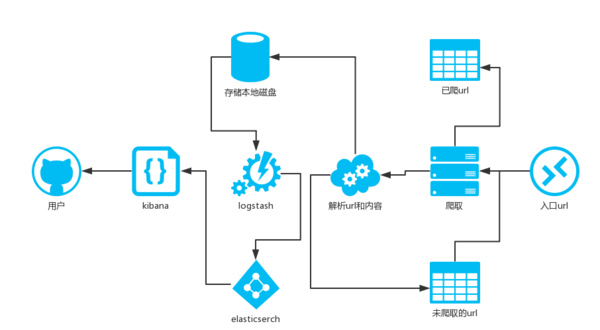
说明:
选择一个活跃的用户(比如李开复)的url作为入口url.并将已爬取的url存在set中。
抓取内容,并解析该用户的关注的用户的列表url,添加这些url到另一个set中,并用已爬取的url作为过滤。
解析该用户的个人信息,并存取到本地磁盘。
logstash取实时的获取本地磁盘的用户数据,并给elsticsearch
kibana和elasticsearch配合,将数据转换成用户友好的可视化图形。
五.编码
爬取一个url:
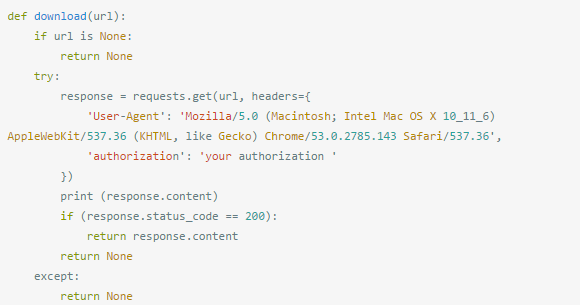
解析内容:

存本地文件:
代码说明:
需要修改获取requests请求头的authorization。
需要修改你的文件存储路径。
源码下载:https://github.com/forezp/ZhihuSpiderMan,记得star哦!
六.如何获取authorization
打开chorme,打开https://www.zhihu.com/,
登陆,首页随便找个用户,进入他的个人主页,F12(或鼠标右键,点检查)
点击关注,刷新页面,见图:
七、可改进的地方
可增加线程池,提高爬虫效率
存储url的时候我才用的set(),并且采用缓存策略,最多只存2000个url,防止内存不够,其实可以存在redis中。
存储爬取后的用户我说采取的是本地文件的方式,更好的方式应该是存在mongodb中。
对爬取的用户应该有一个信息的过滤,比如用户的粉丝数需要大与100或者参与话题数大于10等才存储。防止抓取了过多的僵尸用户。
八.关于ELK套件
关于elk的套件安装就不讨论了,具体见官网就行了。网站:https://www.elastic.co/
另外logstash的配置文件如下:
九、结语
从爬取的用户数据可分析的地方很多,比如地域、学历、年龄等等,我就不一一列举了。
另外,我觉得爬虫是一件非常有意思的事情,在这个内容消费升级的年代,如何在广阔的互联网的数据海洋中挖掘有价值的数据,是一件值得思考和需不断践行的事情。
-
互联网
+关注
关注
54文章
10906浏览量
100742 -
python
+关注
关注
51文章
4675浏览量
83466
原文标题:碉堡了!一小时爬取百万知乎用户信息的Python神器曝光
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
大朋VR全景声巨幕VR影院值不值购买?详细体验总结
网络爬虫nodejs爬虫代理配置
爬虫是如何实现数据的获取爬虫程序如何实现
如何使用表格做爬虫
一文读懂关于爬虫的概念






 工商网监
工商网监
评论