 一种使用卷积神经网络来预测斗地主游戏中玩家行为的方法
一种使用卷积神经网络来预测斗地主游戏中玩家行为的方法
近年来,从围棋到 Dota 团战赛,深度神经网络应用在各种游戏竞赛中不断取得突破。这一次,有人把这种方法用到斗地主游戏的研究中,可以说真的很接地气了!
本论文是 ICLR 2019 的投稿论文,目前该论文还处于双盲审状态,因此也还未公布作者。营长在看到这篇论文的时候,就想第一时间分享给大家。接下来,我们就一起来看看这个有趣的研究吧!也预祝作者的论文能够成功被接收,今后在这个项目上还可以再有进展!
摘要
近几年,深度神经网络在围棋,国际象棋和日本象棋(Shogi)等多款游戏中都能够击败人类。和这些棋类相比,中国的纸牌游戏“斗地主”也是非常出名!斗地主属于非完整信息类的游戏即不知对方底牌,在游戏过程中包含隐藏信息,具有随机性,并且多个玩家间存在合作与竞争关系。本文,我们将介绍一种使用卷积神经网络(CNN)来预测斗地主游戏中玩家行为的方法,它是通过人类的游戏记录来进行监督训练。在没有搜索情况下,此网络就能以绝大优势击败了性能最好的AI程序;在重复模式(Duplicate Mode)下也能战胜了顶级的人类业余玩家。
简介
斗地主(CCP)易于学习但想要擅长或精通却是难事,它不仅需要数学知识和战略性的思考,更需要玩家精心策划每一步。游戏规则我们在这里就不多说了,主要说一下我们的研究思路和成果。
我们选择 CNN来解决斗地主游戏问题的主要原因如下:
首先,CNN在完善的信息游戏中取得了超越人类的卓越表现
其次,在CCP中存在同一类别不同等级的两套出牌方式(例如“34567”比“45678”等级来得低,等级低的不能压等级高的。)
迄今为止,还没有使用深度神经网络来研究斗地主游戏的。该网络是否能够在游戏输入信息不完善的情况下选择合理的操作还有待证明。由于在每局游戏中有队友的存在,这就出现了两个问题:一是要教会该网络进行合作;二是它要具备良好的推理能力。针对这些问题,我们设计了 DeepRocket,它是目前能够在斗地主游戏中取得最好效果的一种网络。在下面的实验中,我们证明了该网络可以在不完善的信息游戏中学会合作与推理。
Deep Rocket 框架
DeepRocket系统包含三个部分:叫地主模块、策略网络以及带牌(Kicker)网络。当游戏开始时叫地主模块会被调用以便计算 DeepRocket的得分(叫地主和抢地主时分数会加倍)。在 DeepRocket出牌之前会先调用策略网络,策略网络会依据当前环境预测出最应该执行的策略,其中包括带牌模式(带单张或者一对)。当策略中含有带牌时,Kicker 网路才会被调用。游戏流程如下图1、2所示。
图1 DeepRocket游戏流程
图2 策略网络和 Kicker 网络的工作流程
▌叫地主模块
在分完牌后需要先确定谁是地主,所以我们为此设计了一个基于逻辑代码的叫地主模块。叫地主的关键因素在于手牌的好坏。是否决定叫地主取决于手牌中是否有大牌(如:“A”、“2”以及大小王)和手牌顺不顺(有较少的杂牌)。
▌策略网络
策略网络采用监督学习的方式。其中该网络包含 10 层 CNN 层和 1 层全连接层,激活函数采用 Relu。最终的 softmax层输出所有合理出牌方式 a的概率分布。输入为当前的游戏状态。策略网络的训练样本来自于随机抽样,这些样本包含当前状态以及最优的决策,采用随机梯度上升的方式训练网络,让策略网络的出牌与人类的出牌越来越相近。
我们使用 800 万条游戏记录来训练策略网络,一条记录代表一场完整的游戏,一局斗地主按回合来分,又能分为许多样本。
策略网络的输入是一个 15×19×21 的三维二元张量。我们用 X、Y和 Z代表三个维度。其中 X代表牌的种类,从 3 到大小王。Y表示每个种类牌的数量(从 1 张到 4 张),以及 CCP中卡牌的组合如单张、对子等。Z代表每一轮的顺序信息,作用是在游戏中将可变长度变换为固定长度,具体细节如表 1 所示。

表1 Z的含义
重复试验之后发现,512 滤波器最为合适,10 层 CNN能使得模型获得最佳的性能,其中每层都使用不同的步长。当我们将 Kicker网络加到 DeepRocket中后,策略网络会输出 309 个决策的概率。具体的组合情况如表 2 所示。
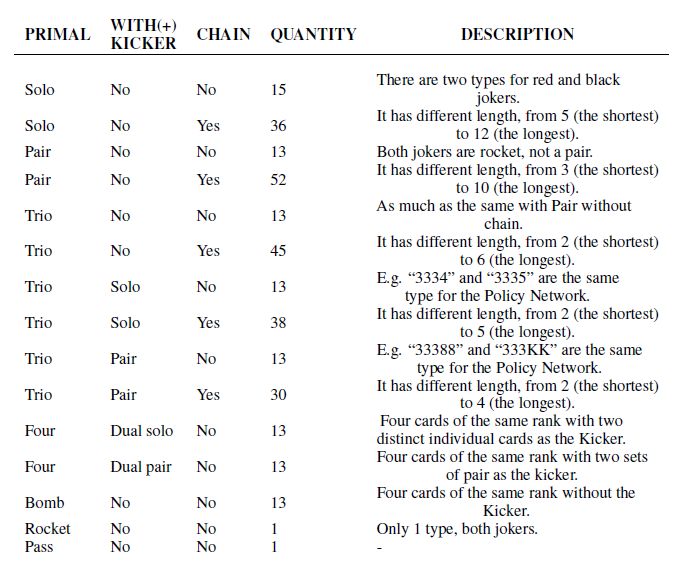
表2 组合类型
▌Kicker 网络
仅凭叫地主模块以及策略网络就足以完成一场游戏,但决定带牌的类型对游戏来说也至关重要。
我们将带不同的牌标记为不同的策略。并额外建立了一个 Kicker网络来预测所带的牌。策略网络负责预测 Main Group(如: 3334中的 3 个 3)和所带牌的种类如单张或者对子。而 Kicker网络则负责预测所带的牌具体是哪几张。
Kicker网络的输入包含剩余的牌以及策略网络的输出值,它由一个15×9×3的三维二元张量构成。其中 X的含义与策略网络中相同,而 Y与 Z的含义如表所示。Kicker网络包含 28 种输出,其中 15 种为单牌,13 种为对子。
Kicker网络由 5 层 CNN层和 1 层全连接层构成,输出为带牌的概率。Kicker网络每次仅输出一个带牌种类。如果策略网络预测应该出“333444”以及两张单牌,这时则要调用两次 Kicker网络。
实验
▌实验设置
我们获取了 800 万条游戏记录,首先将其划分为 8000 万个“状态-行为”对,90%作为训练数据集,10%作为测试数据集;然后将其作为网络的输入;最后使用 TFRecords 存储到硬盘中;这样不仅方便修改网络参数,也加快了训练速度。策略网络的大小为 256,对人类专家的行为预测准确度可达 86%-88%。使用 i7-7900X CPU,NAVIDA 1080Ti GPU以及 Ubuntu 16.04的操作系统计算策略网络的输出需要 0.01-0.02 秒。
Kicker网络同样是监督式学习,也使用以上的 800 万条游戏记录作为数据集,但在训练之后它能达到 90%的准确度,甚至比策略网络更高。
▌与目前最好的 AI 对比
在 DeepRocket出现之前,MicroWe是最好的CCP AI。如图 3 和图 4 所示,我们进行了 50000 场游戏测试,每一次迭代表示 5000 场。我们将 20 张卡牌直接发给地主,这样地主的胜率会比平常低。“DR VS MW”代表 DeepRocket是地主,而 MicroWe是农民。从图中可看出 DR 表现比 MW好。
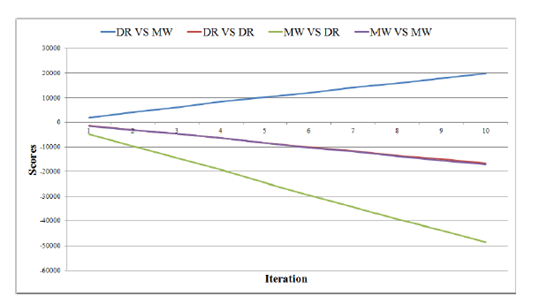
图3 DR与 MW的比赛结果
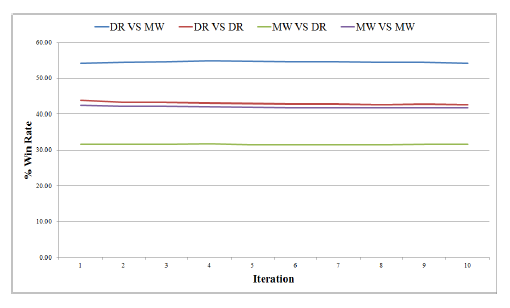
图4不同 AI之间比赛的胜率
▌与人类专家对比
我们举办了一场人机比赛,邀请了四位顶级业余选手,在循环模式下进行了 10 场比赛。结果,DR以 30:24 的分数战胜了人类团队。
▌合作与推理
在 DR的游戏记录中,我们找到了一个典型的例子能够展现其良好的合作能力(T:10;B:大王;S:小王。其中冒号之前表示玩家,冒号后表示打出的牌,以分号作为某玩家出牌结束标志,0 代表地主)
牌面:
4456777889JKKAA2B;
335567899TTJJKAA2;
4456689TTJQQQK22S;
33Q;
游戏进程:
0,33;1,55;2,66;0,77;1,AA;1,6;2,T;0,J;1,K;0,2;2,S;2,44;0,KK;2,22;2,89TJQK;2,QQ;0,AA;0,56789;1,789TJ;1,3;2,5;
以上加粗部分是关键步骤,在游戏的最后 DR打出一张“3”来帮助队友取得胜利,由此可见 DR具有良好合作能力的。
我们也找到了一个能够展现 DR推理能力的例子:
牌面:
33345578TTJKKA22S;
34566789TQQQKKAA2;
4456678999TJJQA2B;
78J;
游戏进程:
0,345678;1,56789T;0,6789TJ;0,QQQKK;0,AA;2,22;2,55;2,3334;2,TT;2,A;0,2;
以上加粗部分是关键步骤,虽然最后农民输了,但是他选择打“A”是一个不错的选择,因为地主只剩一张牌,而农民手里还有 (“7, 8, J, A, S”)五张牌,选择出“A”也是人类专家的正常逻辑,DR 能够从人类中学到此行为。
展望
虽然,我们已经证明了 CNN能够预测斗地主游戏中玩家的行为,并与队友进行合作;在没有任何的 MCTS之下能达到顶级选手的水平甚至更高。但是,我们也还有许多方面要进行完善。第一个是强化问题,直接将应用在 AlphaGo的方法移植到 CCP中是行不通的;第二个是关于 Monte Carlo搜索或者 MCTS的问题。
在未来,DR可以在以下方面进行改进:
叫地主的方式可以改进,在抢地主的过程中只有 0、1、2 和 3 是正确操作,0 代表玩家不想当地主。我们将尝试用深度神经网络去训练叫地主的方式。
我们将尝试使用随机权重训练模型。
我们将训练分别代表三个角色的三个输出模型。
最后预祝作者的论文被成功接收,今后在这个项目上还可以再有进展!
-
神经网络
+关注
关注
42文章
4572浏览量
98746 -
数据集
+关注
关注
4文章
1178浏览量
24351
原文标题:来呀!AI喊你斗地主——首个搞定斗地主的深度神经网络
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论