 BN降低内部协方差偏移是流言吗?
BN降低内部协方差偏移是流言吗?
编者按:DRDO研究人员Ayoosh Kathuria深入介绍了批归一化的概念,终结了广泛流传的批归一化降低内部协方差偏移的流言。
认出上面的人了吗?这是探索频道的《留言终结者》。
今天,我们也要分辨一下,批归一化到底能不能解决内部协方差偏移的问题?尽管批归一化(Batch Normalization)提出已经有一些年了,已经成为深度架构的主要部件,它仍然是深度学习中最容易误解的概念之一。
批归一化真的可以解决内部协方差偏移问题?如果不能解决,那它的作用是什么?你所接受的整个深度学习教育是一个谎言吗?让我们来寻找答案吧!
开始之前……
我想提醒一下,本文是深度学习优化算法系列的第四篇,前三篇文章讨论了:
随机梯度下降如何克服深度学习中的局部极小值和鞍点问题?
动量和Adam等方法如何加强原始梯度下降,以应对优化曲面上的病态曲率问题?
如何使用不同的激活函数处理梯度消失问题?
上一篇文章中,我们学到的一点是,为了让神经网络高效学习,传入网络层的输入应该大致符合:
零中心化
不同batch和不同网络层的数据分布,应保持一定程度上的一致
第二个条件的一种反例是epoch和epoch间的分布剧烈变动。
内部协方差偏移
批归一化的论文题为Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift(批归一化:通过降低内部协方差偏移加速深度网络训练),从标题就可以看出,这篇论文的假定是批归一化可以解决内部协方差偏移的问题。
那么,内部协方差偏移,简称ICS,到底是什么?ICS指神经网络层间的输入分布摇摆不定。内部指这种摇摆不定发生在神经网络的中间层(视作网络的内部)。协方差指以权重为参数的分布在网络层之间的差异。偏移指分布在改变。
让我们尝试描述下事情是怎么发生的。同样,想象一个尽可能简单的网络,线性堆叠的神经元,你可以通过用网络层替换神经元来扩展这一类比。
假设我们优化上述网络的损失函数L,那么神经元d的权重ωd的更新规则为:
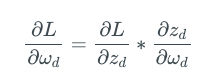
这里,zd= ωdzc,为神经元d的激活值。因此,上式可以化简为:
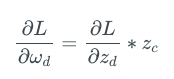
所以,我们看到,网络层d的权重的梯度取决于网络层c的输出。神经网络中的每一层同理。神经元的权重梯度取决于它的输入,即后一层的输出。
接着,梯度反向传播,权重更新,这一过程不断重复。现在,让我们回到网络层d.
由于我们在d上进行了梯度更新,我们现在期望ωd能得到更低的损失。然而结果也许不符合我们的期望。为什么?让我们仔细看下。
我们在迭代i时进行了初次更新,让我们将此时c在迭代i的输出分布记为pci。现在,d的更新假定输入为pci。
然而,在反向传播阶段,c的权重ωc也得到了更新。这导致c的输出分布发生了偏移。
假设在下一次迭代i+1中,zc的分布偏移至pci+1。由于网络层d的权重之前是根据pci更新的,但现在网络层d面临的输入分布却是pci+1。这一显著差异可能导致网络层生成的输出损失不下降。
现在,我们有两个问题。
为什么输入分布偏移让网络层更难学习?
这个偏移是否大到足以导致上面描述的场景?
我们先回答第一个问题。
为什么内部协方差偏移会成为问题?
神经网络所做的是生成输入x到输出y之间的映射f。为什么x的分布改变会造成问题?
例如,假设x从正态分布
变为非正态分布:
假设我们尝试拟合的映射是f = 2x. 那x分布的密度向左偏移,还是均匀散布,又有什么区别?
然而,由于神经网络,更准确的说,现代的深度网络是极为强大的曲线拟合器,这样的分布偏移确实有影响。正像《蜘蛛侠》所言:“能力越大,责任越大。”
假设网络层l面对的x有着如下图所示的分布,并且,到目前为止,通过训练,网络层学习到的函数可以用下图中的虚线表示。
现在,假设梯度更新后,下一个minibatch的x分布变化了:
注意到没有?和之前相比,这一mini-batch的损失变大了。
让我们回过头去看原先的图形。如你所见,我们原本学习的映射f在降低前一个mini-batch的损失方面做的不错。同样,还有许多其他函数在这方面的表现也不错。
如果我们当初选择的是红色虚线,那么下一mini-batch的损失也不会大。
很明显,现在我们需要回答的问题是如何修改算法,使得我们最终学习到红色虚线而不是黑色虚线?简单的回答是,这个问题不存在简单的答案。在这一点上,与其尝试找到解决这类情况的方案,不如集中精力避免这类情况发生。
ICS最终扰乱学习的原因是神经网络总是在输入分布的稠密区表现较好。稠密区的数据点的损失下降得更多,因为稠密区的数据点统治了平均损失,而我们试图最小化的正是平均损失。
然而,如果在训练期间ICS最终改变了后续batch的输入分布的稠密区,那么网络从之前的迭代中学到的权重就不再是最优的了。这大概需要非常小心地调整超参数才能合理地学习。这解释了为什么ICS可能造成问题。
当然,mini-batch内部还是要有适当差异的。差异可以确保映射没有过度拟合输入分布的单个区域。另外,我们也想要输入的均值在零左右,原因详见本系列的上一篇文章。
归一化输入
应对这一问题的一种方法是归一化神经网络的输入,使输入分布均值为零,方差为单位方差。然而,只有当网络不够深的时候这个方法才有效果。当网络变得越来越深,例如,20层以上,即使输入经过了归一化,20多层权重的微小波动可能造成深层输入分布的巨大改变。
一个不太正确的类比是语言的变化。随着我们旅行距离的增加,语言也发生了变化。然而,距离较近的地方,语言有很多相似性。比如,西班牙语和葡萄牙语。这两种语言都源自原始印欧语。然而,8000公里之外的印度人说的印度斯坦语,同样源自原始印欧语,和西班牙的差别却远大于西班牙语和葡萄牙语的差别。原因是短距离内的微小变动随着距离的增加而逐渐放大。深度网络同理。
进入批归一化
现在我们介绍批归一化(BN)的概念,BN归一化网络层的激活输出,同时进行了其他一些操作。
上面的公式描述了批归一化层做了什么。等式2-4描述了mini-batch间的激活的均值、方差是如何计算的,以及通过减去均值除以标准差归一化分布。
等式5是关键部分。γ和β是所谓的批归一化层的参数,等式5的输出均值为β,标准差为γ。从效果上说,批归一化层有助于优化算法控制网络层输出的均值和方差。
ICS袪魅
引入批归一化的论文将批归一化的成功归功于摆脱了内部协方差偏移。然而,这是一个荒谬的陈述,批归一化根本没有防止ICS。
内部协方差偏移是指网络训练过程中输入分布的改变。批归一化的参数γ和β是为了调整激活的均值和方差。然而,这意味着这两个参数是可训练的,也就是是说,将随着训练的进行而改变,那么批归一化自身就会导致激活分布的改变,也就是内部协方差偏移。如果它防止了内部协方差偏移,参数γ和β毫无意义。
为何批归一化有效?
既然批归一化没能克服内部协方差偏移,那么批归一化是怎么起效的呢?
GAN之父Ian Goodfellow曾经在一个讲座中提出过一种可能的解释(讲座的网址见文末)。我必须提醒你注意,到目前为止,尽管来自深度学习的权威,这仍然只是一项未经证明的猜测。
Goodfellow认为原因在于批归一化层的两个参数。
让我们再次考虑之前的超级简单的玩具网络。
这里,当我们更新a的权重的时候,仅仅计算∂L/∂a,即损失函数在a上的反应。然而,我们没有考虑改变a的权重同时也将改变后续层b、c、d的输出。
这实际上是因为算力限制,我们无法利用二阶以上的优化方法。梯度下降及其变体只能捕捉一阶交互(我们在本系列的第二篇文章中深入讨论了这一点)。
深度神经网络具有高阶交互,这意味着改变某一层的权重也许会在损失函数之外影响其他层的统计特征。如果不考虑这样的跨层交互,就会产生内部协方差偏移。每次更新一个网络层的权重,都有可能对之后的网络层的统计特征造成不利影响。
在这样的情形下,可能需要精心的初始化、超参数调整、长时间的训练才能收敛。然而,当我们在层间添加批归一化层之后,网络层的统计特征只受γ、β这两个参数的影响。
现在,优化算法只需调整两个参数即可控制任意层的统计特征,而不需要调整之前层的所有权重。这大大加速了收敛,并免去了精心初始化和超参数调整的需要。因此,批归一化更多地起到设置检查点的作用。
注意,具备任意设定网络层的均值和标准差的能力同时意味着我们可以恢复原分布,如果恢复原分布足以使训练正常的话。
在激活前还是激活后进行批归一化
尽管原始论文在激活函数之前应用批归一化,在实践中发现在激活之后应用批归一化能得到更好的结果。这看起来很有道理,因为如果我们在批归一化之后放置激活,那么由于批归一化层的输出还需要经过激活,批归一化就无法完全控制下一层的输入。
推理阶段的批归一化
在推理阶段使用批归一化有一定技巧性。这是因为在推理阶段我们不一定有批次可言。例如,进行实时目标检测时,每次只处理一帧,并不存在批次。
而没有批次,我们就无法计算均值和方差,也就无法得到批归一化层的输出。在这一情形下,我们维持一个训练阶段的均值、方差的移动平均,然后在推理阶段使用这一移动平均。这是大多数自带批归一化层的深度学习库的做法。
这一做法的依据是大数定律。在样本足够的的情况下,批统计量趋向于收敛至真实统计量。移动平均也有助于消除mini batch自带的噪声。
如果测试阶段可以使用批次,那么我们使用和上文提到的几乎一模一样的公式,只有一处例外。我们不使用
而使用如下公式:
为何分母使用m-1而不是m是因为均值已经是我们估计的,mini batch中只有m-1个项独立观测了。用术语来说,就是自由度只有m-1,具体细节的讨论超出了本文的范围。
起正则作用的批归一化
批归一化同时也起到了正则化的作用。相比真实均值和方差,为每个批次估计的均值和方差是一个加噪的版本,这给优化搜索过程引入了随机性,从而起到了正则化的作用。
结语
尽管批归一化已经成为当今深度架构的标准元素,直到最近研究方向才转向理解批归一化到底为何有效。最近受到很多关注的一篇论文,直接以How Does Batch Normalization Help Optimization? (No, It Is Not About Internal Covariate Shift)为题(批归一化如何帮助优化?不,它和内部协方差偏移无关)。这篇论文揭示了,和没有使用批归一化的网络相比,批归一化实际上增加了内部协方差。论文的主要洞见在于,批归一化平滑了损失曲面,所以批归一化才这么有效。2017年,有人提出了SELU(扩展指数线性激活单元)激活函数,隐式地归一化其激活(批归一化显式地进行了这一点)。SELU的原论文包含100页数学精确说明这一切是如何发生的,偏爱数学的读者应该读一下。
优化是深度学习中一个激动人心的领域。这些年来,许多深度学习应用得到了加强,已经可以实用,但直到最近我们才开始探索诱人的深度学习理论部分。
最后,让我们说……流言终结!
进一步阅读
批归一化论文:https://arxiv.org/abs/1502.03167
How Does Batch Normalization Help Optimization? (No, It Is Not About Internal Covariate Shift): https://arxiv.org/abs/1805.11604
扩展指数线性激活单元论文:https://arxiv.org/abs/1706.02515
Ian Goodfellow关于批归一化的讲座:https://youtu.be/Xogn6veSyxA
Reddit上关于把批归一化放在ReLU前面还是后面的讨论:https://www.reddit.com/comments/67gonq/
-
神经网络
+关注
关注
42文章
4572浏览量
98743 -
深度学习
+关注
关注
73文章
5237浏览量
119905
原文标题:优化算法入门:四、批归一化揭秘
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Matlab协方差矩阵的计算原理
Matlab协方差矩阵的计算原理
基于协方差矩阵的CFA插值盲检测方法
基于协方差矩阵特征分解的多通道SAR-GMTI方法及性能分析
基于杂波协方差矩阵特征向量分析STAP降维方法
协方差公式_协方差的计算公式例子

协方差矩阵是什么_协方差矩阵计算公式_如何计算协方差矩阵

基于协方差矩阵降维稀疏表示的二维波达方向估计方法
基于邻域差分和协方差信息处理单目标优化的进化算法
基于协方差矩变异系数的能量泄露评估模型






 工商网监
工商网监
评论