 从简介、计算步骤、应用三方面进行理解PCA的降维作用
从简介、计算步骤、应用三方面进行理解PCA的降维作用
▌概述
本文主要介绍一种降维方法,PCA(Principal Component Analysis,主成分分析)。降维致力于解决三类问题:
1.降维可以缓解维度灾难问题;
2.降维可以在压缩数据的同时让信息损失最小化;
3.理解几百个维度的数据结构很困难,两三个维度的数据通过可视化更容易理解。
下面,将从简介、计算步骤、应用三方面进行理解PCA的降维作用。
▌PCA简介
在理解特征提取与处理时,涉及高维特征向量的问题往往容易陷入维度灾难。随着数据集维度的增加,算法学习需要的样本数量呈指数级增加。有些应用中,遇到这样的大数据是非常不利的,而且从大数据集中学习需要更多的内存和处理能力。另外,随着维度的增加,数据的稀疏性会越来越高。在高维向量空间中探索同样的数据集比在同样稀疏的数据集中探索更加困难。
主成分分析也称为卡尔胡宁-勒夫变换(Karhunen-Loeve Transform),是一种用于探索高维数据结构的技术。PCA通常用于高维数据集的探索与可视化。还可以用于数据压缩,数据预处理等。PCA可以把可能具有相关性的高维变量合成线性无关的低维变量,称为主成分( principal components)。新的低维数据集会尽可能的保留原始数据的变量。
PCA将数据投射到一个低维子空间实现降维。例如,二维数据集降维就是把点投射成一条线,数据集的每个样本都可以用一个值表示,不需要两个值。三维数据集可以降成二维,就是把变量映射成一个平面。一般情况下,nn维数据集可以通过映射降成kk维子空间,其中k≤n。
假如你是一本养花工具宣传册的摄影师,你正在拍摄一个水壶。水壶是三维的,但是照片是二维的,为了更全面的把水壶展示给客户,你需要从不同角度拍几张图片。下图是你从四个方向拍的照片:
第一张图里水壶的背面可以看到,但是看不到前面。第二张图是拍前面,可以看到壶嘴,这张图可以提供了第一张图缺失的信息,但是壶把看不到了。从第三张俯视图里无法看出壶的高度。第四张图是你真正想要的,水壶的高度,顶部,壶嘴和壶把都清晰可见。
PCA的设计理念与此类似,它可以将高维数据集映射到低维空间的同时,尽可能的保留更多变量。PCA旋转数据集与其主成分对齐,将最多的变量保留到第一主成分中。假设我们有下图所示的数据集:
数据集看起来像一个从原点到右上角延伸的细长扁平的椭圆。要降低整个数据集的维度,我们必须把点映射成一条线。下图中的两条线都是数据集可以映射的,映射到哪条线样本变化最大?
显然,样本映射到黑色虚线的变化比映射到红色点线的变化要大的多。实际上,这条黑色虚线就是第一主成分。第二主成分必须与第一主成分正交,也就是说第二主成分必须是在统计学上独立的,会出现在与第一主成分垂直的方向,如下图所示:
后面的每个主成分也会尽量多的保留剩下的变量,唯一的要求就是每一个主成分需要和前面的主成分正交。 现在假设数据集是三维的,散点图看起来像是沿着一个轴旋转的圆盘。
这些点可以通过旋转和变换使圆盘完全变成二维的。现在这些点看着像一个椭圆,第三维上基本没有变量,可以被忽略。当数据集不同维度上的方差分布不均匀的时候,PCA最有用。(如果是一个球壳形数据集,PCA不能有效的发挥作用,因为各个方向上的方差都相等;没有丢失大量的信息维度一个都不能忽略)。
▌PCA的计算步骤
在介绍PCA的运行步骤之前,有一些术语需要说明一下。
方差,协方差和协方差矩阵(对此概念不是很理解可以参考附录链接)
如何通俗易懂地解释「协方差」与「相关系数」的概念?中“GRAYLAMB”的回答。 (https://www.zhihu.com/question/20852004)
方差(Variance)是度量一组数据的分散程度。方差是各个样本与样本均值的差的平方和的均值:
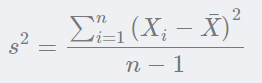
协方差(Covariance)是度量两个变量的变动的同步程度,也就是度量两个变量线性相关性程度。
如果两个变量的协方差为0,则统计学上认为二者线性无关。注意两个无关的变量并非完全独立,只是没有线性相关性而已。计算公式如下:

如果协方差大于0表示一个变量增大是另一个变量也会增大,即正相关,协方差小于0表示一个变量增大是另一个变量会减小,即负相关。
协方差矩阵(Covariance matrix)由数据集中两两变量的协方差组成。矩阵的第(i,j)(i,j)个元素是数据集中第ii和第jj个元素的协方差。例如,三维数据的协方差矩阵如下所示:

让我们计算下表数据的协方差矩阵:

可以有python中的numpy包计算均值和协方差:
importnumpyasnpX=[[2,0,-1.4],[2.2,0.2,-1.5],[2.4,0.1,-1],[1.9,0,-1.2]]print(np.mean(X,axis=0))print(np.cov(np.array(X).T))
得到三个变量的样本均值分别是2.125,0.075和-1.275;协方差矩阵为:

▌特征向量和特征值
(可以直观的理解:“特征向量是坐标轴,特征值是坐标”)
向量是具有大小(magnitude)和方向(direction)的几何概念。
特征向量(eigenvector)是由满足如下公式的矩阵得到的一个非零向量:

其中, 是特征向量,A是方阵,λ是特征值。经过A变换之后,特征向量的方向保持不变,只是其大小发生了特征值倍数的变化。也就是说,一个特征向量左乘一个矩阵之后等于等比例放缩(scaling)特征向量。德语单词eigen的意思是“属于…或…专有( belonging to or peculiar to)”;矩阵的特征向量是属于并描述数据集结构的向量。
是特征向量,A是方阵,λ是特征值。经过A变换之后,特征向量的方向保持不变,只是其大小发生了特征值倍数的变化。也就是说,一个特征向量左乘一个矩阵之后等于等比例放缩(scaling)特征向量。德语单词eigen的意思是“属于…或…专有( belonging to or peculiar to)”;矩阵的特征向量是属于并描述数据集结构的向量。
特征向量和特征值只能由方阵得出,且并非所有方阵都有特征向量和特征值。如果一个矩阵有特征向量和特征值,那么它的每个维度都有一对特征向量和特征值。矩阵的主成分是由其协方差矩阵的特征向量,按照对应的特征值大小排序得到的。最大的特征值就是第一主成分,第二大的特征值就是第二主成分,以此类推。
让我们来计算下面矩阵的特征向量和特征值:
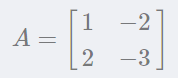
根据前面的公式AA乘以特征向量,必然等于特征值乘以特征向量。我们建立特征方程求解:
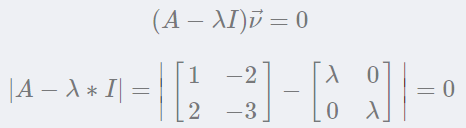
从特征方程可以看出,矩阵与单位矩阵和特征值乘积的矩阵行列式为0,即:
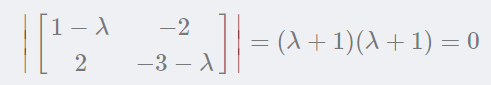
矩阵的两个特征值都等于-1。现在再用特征值来解特征向量。 把λ=−1带入:

得:
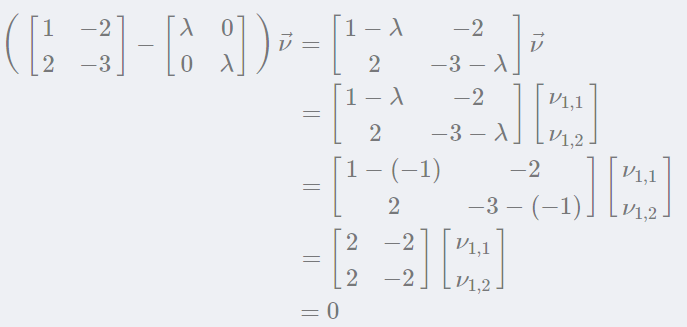
所以有:

任何满足方程 的非零向量(取
的非零向量(取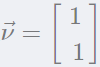 )都可以作为特征向量:
)都可以作为特征向量:

PCA需要单位特征向量,也就是L2范数 等于1的特征向量。
等于1的特征向量。
于是单位特征向量是:
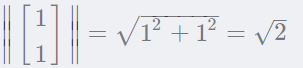
于是单位特征向量是:
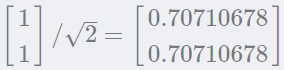
这里可以通过numpy检验手算的特征向量是否正确。eig函数返回特征值和特征向量的元组:
importnumpyasnpw,v=np.linalg.eig(np.array([[1,-2],[2,-3]]))print('特征值:{} 特征向量:{}'.format(w,v))
输出(这里特征值不同为1,是由于python编译器对浮点数据精度要求所致):
特征值:[-0.99999998 -1.00000002]
特征向量:[[ 0.70710678 0.70710678] [ 0.70710678 0.70710678]]
▌用PCA降维
让我们用PCA方法把下表二维数据降成一维:

PCA第一步是用样本数据减去样本均值:

然后,我们计算数据的主成分。前面介绍过,矩阵的主成分是其协方差矩阵的特征向量按照对应的特征值大小排序得到的。主成分可以通过两种方法计算:第一种方法是计算数据协方差矩阵。因为协方差矩阵是方阵,所以我们可以用前面的方法计算特征值和特征向量。第二种方法是用数据矩阵的奇异值分解(singular value decomposition)来找协方差矩阵的特征向量和特征值的平方根。我们先介绍第一种方法,然后介绍scikit-learn的PCA实现,也就是第二种方法。上述数据集的解释变量协方差矩阵如下:

用前面介绍过的方法,特征值是1.25057433和0.03398123,单位特征向量是:

下面我们把数据映射到主成分上。第一主成分是最大特征值对应的特征向量,因此我们要建一个转换矩阵,它的每一列都是主成分的特征向量。如果我们要把5维数据降成3维,那么我们就要用一个3维矩阵做转换矩阵。在本例中,我们将把我们的二维数据映射成一维,因此我们只需要用特征向量中的第一主成分作为转换矩阵。最后,我们用数据矩阵右乘转换矩阵。下面就是第一主成分映射的结果:

通过numpy包中的矩阵调用实现过程如下:
importnumpyasnpx=np.mat([[0.9,2.4,1.2,0.5,0.3,1.8,0.5,0.3,2.5,1.3],[1,2.6,1.7,0.7,0.7,1.4,0.6,0.6,2.6,1.1]])x=x.TT=x-x.mean(axis=0)C=np.cov(x.T)w,v=np.linalg.eig(C)v_=np.mat(v[:,0])#每个特征值对应的是特征矩阵的每个列向量v_=v_.T#默认以行向量保存,转换成公式中的列向量形式y=T*v_print(y)
分割线==================
▌PCA的运用
高维数据可视化
二维或三维数据更容易通过可视化发现模式。一个高维数据集是无法用图形表示的,但是我们可以通过降维方法把它降成二维或三维数据来可视化。 Fisher1936年收集了三种鸢尾花分别50个样本数据(Iris Data):Setosa、Virginica、Versicolour。解释变量是花瓣(petals)和萼片(sepals)长度和宽度的测量值,响应变量是花的种类。鸢尾花数据集经常用于分类模型测试,scikit-learn中也有。让我们把iris数据集降成方便可视化的二维数据:
%matplotlibinlineimportmatplotlib.pyplotaspltfromsklearn.decompositionimportPCAfromsklearn.datasetsimportload_iris
首先,我们导入鸢尾花数据集和PCA估计器。PCA类把主成分的数量作为超参数,和其他估计器一样,PCA也用fit_transform()返回降维的数据矩阵:
data=load_iris()y=data.targetX=data.datapca=PCA(n_components=2)reduced_X=pca.fit_transform(X)
最后,我们把图形画出来:
red_x,red_y=[],[]blue_x,blue_y=[],[]green_x,green_y=[],[]foriinrange(len(reduced_X)):ify[i]==0:red_x.append(reduced_X[i][0])red_y.append(reduced_X[i][1])elify[i]==1:blue_x.append(reduced_X[i][0])blue_y.append(reduced_X[i][1])else:green_x.append(reduced_X[i][0])green_y.append(reduced_X[i][1])plt.scatter(red_x,red_y,c='r',marker='x')plt.scatter(blue_x,blue_y,c='b',marker='D')plt.scatter(green_x,green_y,c='g',marker='.')plt.show()
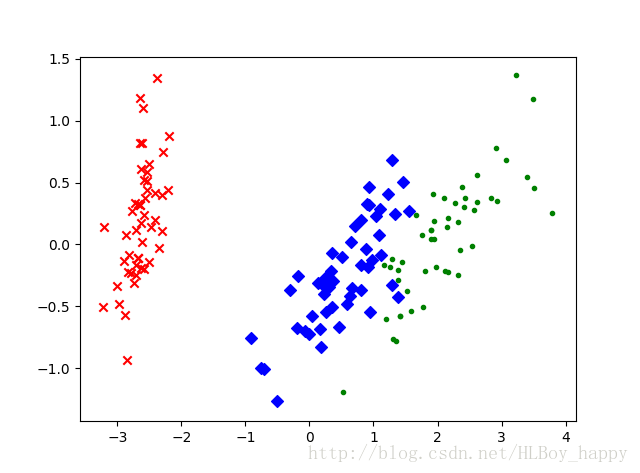
降维的数据如上图所示。每个数据集中三个类都用不同的符号标记。从这个二维数据图中可以明显看出,有一个类与其他两个重叠的类完全分离。这个结果可以帮助我们选择分类模型。
脸部识别
现在让我们用PCA来解决一个脸部识别问题。脸部识别是一个监督分类任务,用于从照片中认出某个人。本例中,我们用剑桥大学AT&T实验室的Our Database of Faces数据集(http://www.cl.cam.ac.uk/Research/DTG/attarchive/pub/data/att_faces.zip),这个数据集包含40个人每个人10张照片。这些照片是在不同的光照条件下拍摄的,每张照片的表情也不同。照片都是黑白的,尺寸为92 x 112像素。虽然这些图片都不大,但是每张图片的按像素强度排列的特征向量也有(92 x 112=)10304维。这些高维数据的训练可能需要很多样本才能避免拟合过度。而我们样本量并不大,所有我们用PCA计算一些主成分来表示这些照片。
我们可以把照片的像素强度矩阵转换成向量,然后用所有的训练照片的向量建一个矩阵。每个照片都是数据集主成分的线性组合。在脸部识别理论中,这些主成分称为特征脸(eigenfaces)。特征脸可以看成是脸部的标准化组成部分。数据集中的每张脸都可以通过一些标准脸的组合生成出来,或者说是最重要的特征脸线性组合的近似值。
fromosimportwalk,pathimportnumpyasnpimportmahotasasmhfromsklearn.cross_validationimporttrain_test_splitfromsklearn.cross_validationimportcross_val_scorefromsklearn.preprocessingimportscalefromsklearn.decompositionimportPCAfromsklearn.linear_modelimportLogisticRegressionfromsklearn.metricsimportclassification_reportX=[]y=[]
下面我们把照片导入Numpy数组,然后把它们的像素矩阵转换成向量:
fordir_path,dir_names,file_namesinwalk('C:/Users/HLB/Desktop/firstblog/att_faces/'):#walk()函数内存放的是数据的绝对路径,同时注意斜杠的方向。forfninfile_names:iffn[-3:]=='pgm':image_filename=path.join(dir_path,fn)X.append(scale(mh.imread(image_filename,as_grey=True).reshape(10304).astype('float32')))y.append(dir_path)X=np.array(X)
然后,我们用交叉检验建立训练集和测试集,在训练集上用PCA:
X_train,X_test,y_train,y_test=train_test_split(X,y)pca=PCA(n_components=150)
我们把所有样本降到150维,然后训练一个逻辑回归分类器。数据集包括40个类;scikit-learn底层会自动用one versus all策略创建二元分类器:
X_train_reduced=pca.fit_transform(X_train)X_test_reduced=pca.transform(X_test)print('训练集数据的原始维度是:{}'.format(X_train.shape))print('PCA降维后训练集数据是:{}'.format(X_train_reduced.shape))classifier=LogisticRegression()accuracies=cross_val_score(classifier,X_train_reduced,y_train)
训练集数据的原始维度是:(300, 10304) PCA降维后训练集数据是:(300, 150)
最后,我们用交叉验证和测试集评估分类器的性能。分类器的平均综合评价指标(F1 score)是0.88,但是需要花费更多的时间训练,在更多训练实例的应用中可能会更慢。
print('交叉验证准确率是:{} {}'.format(np.mean(accuracies),accuracies))classifier.fit(X_train_reduced,y_train)predictions=classifier.predict(X_test_reduced)print(classification_report(y_test,predictions))
最终的分析结果:
交叉验证准确率是:0.829757290513[0.830357140.833333330.8255814]precisionrecallf1-scoresupportC:/Users/HLB/Desktop/firstblog/att_faces/s11.001.001.001C:/Users/HLB/Desktop/firstblog/att_faces/s101.001.001.002C:/Users/HLB/Desktop/firstblog/att_faces/s111.001.001.002C:/Users/HLB/Desktop/firstblog/att_faces/s121.001.001.002C:/Users/HLB/Desktop/firstblog/att_faces/s131.001.001.004C:/Users/HLB/Desktop/firstblog/att_faces/s141.001.001.003C:/Users/HLB/Desktop/firstblog/att_faces/s151.001.001.002C:/Users/HLB/Desktop/firstblog/att_faces/s161.000.750.864C:/Users/HLB/Desktop/firstblog/att_faces/s171.001.001.004C:/Users/HLB/Desktop/firstblog/att_faces/s181.001.001.003C:/Users/HLB/Desktop/firstblog/att_faces/s191.001.001.003C:/Users/HLB/Desktop/firstblog/att_faces/s21.001.001.002C:/Users/HLB/Desktop/firstblog/att_faces/s201.001.001.002C:/Users/HLB/Desktop/firstblog/att_faces/s211.001.001.002C:/Users/HLB/Desktop/firstblog/att_faces/s221.001.001.002C:/Users/HLB/Desktop/firstblog/att_faces/s231.001.001.004C:/Users/HLB/Desktop/firstblog/att_faces/s241.001.001.002C:/Users/HLB/Desktop/firstblog/att_faces/s251.001.001.004C:/Users/HLB/Desktop/firstblog/att_faces/s261.001.001.005C:/Users/HLB/Desktop/firstblog/att_faces/s270.501.000.671C:/Users/HLB/Desktop/firstblog/att_faces/s281.000.670.803C:/Users/HLB/Desktop/firstblog/att_faces/s291.001.001.002C:/Users/HLB/Desktop/firstblog/att_faces/s31.001.001.001C:/Users/HLB/Desktop/firstblog/att_faces/s301.001.001.003C:/Users/HLB/Desktop/firstblog/att_faces/s311.001.001.003C:/Users/HLB/Desktop/firstblog/att_faces/s321.001.001.001C:/Users/HLB/Desktop/firstblog/att_faces/s331.001.001.001C:/Users/HLB/Desktop/firstblog/att_faces/s341.001.001.003C:/Users/HLB/Desktop/firstblog/att_faces/s351.001.001.002C:/Users/HLB/Desktop/firstblog/att_faces/s360.671.000.802C:/Users/HLB/Desktop/firstblog/att_faces/s370.501.000.671C:/Users/HLB/Desktop/firstblog/att_faces/s381.001.001.005C:/Users/HLB/Desktop/firstblog/att_faces/s391.001.001.003C:/Users/HLB/Desktop/firstblog/att_faces/s41.001.001.001C:/Users/HLB/Desktop/firstblog/att_faces/s401.001.001.001C:/Users/HLB/Desktop/firstblog/att_faces/s51.000.830.916C:/Users/HLB/Desktop/firstblog/att_faces/s61.001.001.003C:/Users/HLB/Desktop/firstblog/att_faces/s71.001.001.002C:/Users/HLB/Desktop/firstblog/att_faces/s81.001.001.002C:/Users/HLB/Desktop/firstblog/att_faces/s91.001.001.001avg/total0.980.970.97100
▌总结
本文主要介绍PCA降维问题。高维数据不能轻易可视化。估计器训练高维数据集时,也可能出现维度灾难。通过主成分分析法缓解这些问题,将可能解释变量具有相关性的高维数据集,通过将数据映射到一个低维子空间,降维成一个线性无关的低维数据集。最后拓展用PCA将四维的鸢尾花数据集降成二维数据进行可视化;并将PCA用在一个脸部识别系统。
-
PCA
+关注
关注
0文章
88浏览量
29365 -
数据集
+关注
关注
4文章
1178浏览量
24349
原文标题:通俗理解PCA降维作用
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

【分享】arm技术总结为三方面能力
什么是嵌入式系统?三方面讲解嵌入式系统
增量型拉绳编码器的安装三方面注意要求
LabVIEW与第三方软件交互问题
IGBT多并联双脉冲测试方法
从分层、布局及布线三方面,详解EMC的PCB设计技术
微型计算机原理及应用课后答案
广州三维动画制作流程(一)
watchOS 9将在三方面带来新功能






 工商网监
工商网监
评论