 基于Python进行机器学习的流程:探索性数据分析、特征工程、训练模型、评估结果
基于Python进行机器学习的流程:探索性数据分析、特征工程、训练模型、评估结果
编者按:Sapient数据科学家Deepak Jhanji通过实例演示了基于Python进行机器学习的流程:探索性数据分析、特征工程、训练模型、评估结果.
机器学习提供了一个无需明确编程、可以自行学习和提升的系统。它使用特定的处理数据的算法自行学习。在这篇教程中,我们将使用Python和XGBoost预测签证结果。
这篇教程主要介绍以下内容:
探索性数据分析
特征工程和特征提取
基于XGBoost算法训练数据集
使用训练好的模型进行预测
加载库
Python库是函数和方法的汇集,让你在无需自行实现算法的情况下编写代码。相应地,你需要下载、安装、引入所用的库。
NumPy,简称np,是Python的基础性的科学计算包。它包括强大的N维数组对象,精密的函数,集成C/C++的工具,线性代数,随机数。紧随其后的是pandas,简称pd,一个开源的BSD许可库,提供高性能、易于使用的数据结构和数据分析工具。接着是scikit learn/sklean库,提供机器学习算法。除了这些基础性的库之外,这篇教程还用到了Statistics(提供mode()等统计函数)、re(正则表达式)、XGboost(XGBoost分类器)。
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model importLogisticRegression
from sklearn.metrics import confusion_matrix, classification_report
from statistics import mode
import re
from xgboost importXGBClassifier
H1B签证和数据集
数据集可以通过Kaggle获取:nsharan/h-1b-visa
它包括五年的H-1B申请记录,共计近三百万条记录。数据集的列包括状态、雇主名称、工作地点、职位、现行工资、职业代码、年份。
数据来自外国劳工认证办公室(OFLC),每年都把可公开披露的数据上传至网络。H1B签证是一种需求强烈的非移民签证,允许专门职业的外国劳工进入国境。H-1B签证是一种基于雇佣关系的非移民签证,对美国的临时外国劳工发放。外国人想要申请H1-B签证,必须有美国雇主为其提供工作,并向美国移民局提交H-1B申请。这也是国际留学生完成学业开始全职工作后最常见的签证申请类别。
H1B申请流程的第一步是美国雇主为外国劳工提交H1B申请。第二步是由州就业保障机构确认现行工资和实际工资。如果现行工资高于潜在雇主提供的工资,那么需要进行工资标准审批。H1B申请流程的第三步是提交劳工条件申请。接下来的步骤是提交H1B申请至USCIS(美国公民及移民服务局)的相应办公室。各地的H1B申请处理时间不同。如果你希望加快申请,可以选择加急处理。H1B申请流程的最后一步是通过输入收据号查询H1B签证状态。一旦USCIS记录了你的申请,就会在他们的系统中更新你的签证状态。
数据集中,每个样本应该包含以下信息:
CASE_ID每个申请唯一的编号
CASE_STATUS申请状态,这是目标变量。
EMPLOYER_NAME提交申请的雇主名称。
SOC_NAME职业名称。
JOB_Title头衔。
FULL_TIME_POSITION是否是全职职位。
PREVAILING_WAGE职位的现行工资为支付给类似劳工的平均工资。
YEAR提交h1b申请的年份。
WORKSITE工作地点所在州、城市。
Lon工作地点经度。
Lat工作地点纬度。
加载数据集
首先要做的是将数据集加载为对象。pandas的.read_csv()方法可以加载csv文件:
df = pd.read_csv('C:/Users/djhanj/Downloads/h1b_TRAIN.csv')
理解数据
加载数据后,总是建议探索数据集,以确保加载的数据结构、格式正确,所有变量或特征正确加载。
.info()方法可以用来检查数据信息。在我们的例子上,这个方法显示数据以DataFrame的格式存储,其中1个变量为整数格式,4个变量为浮点数格式,6个变量为对象格式。
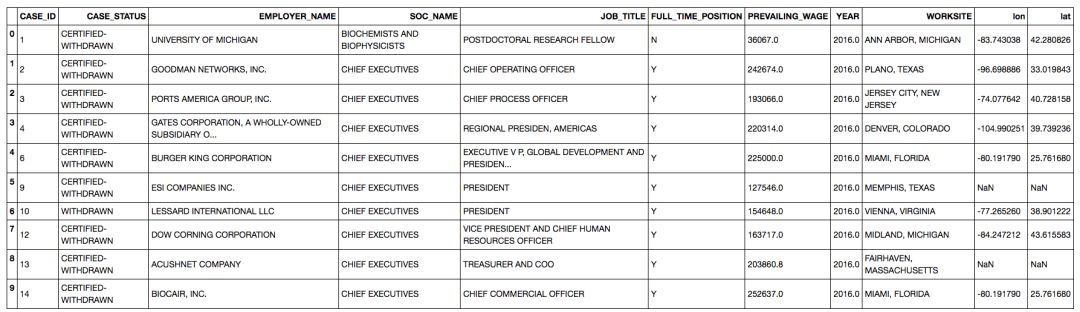
.head()方法返回首5行数据。这能让你大概了解数据集。
.describe()方法将显示最小值、最大值、均值、中位数、标准差,以及所有整数和浮点数变量的数目。
df.info()
df.head()
df.describe()
RangeIndex: 2251844 entries, 0 to 2251843
Data columns (total 11 columns):
CASE_ID int64
CASE_STATUS object
EMPLOYER_NAME object
SOC_NAME object
JOB_TITLE object
FULL_TIME_POSITION object
PREVAILING_WAGE float64
YEAR float64
WORKSITE object
lon float64
lat float64
dtypes: float64(4), int64(1), object(6)
memory usage: 189.0+ MB
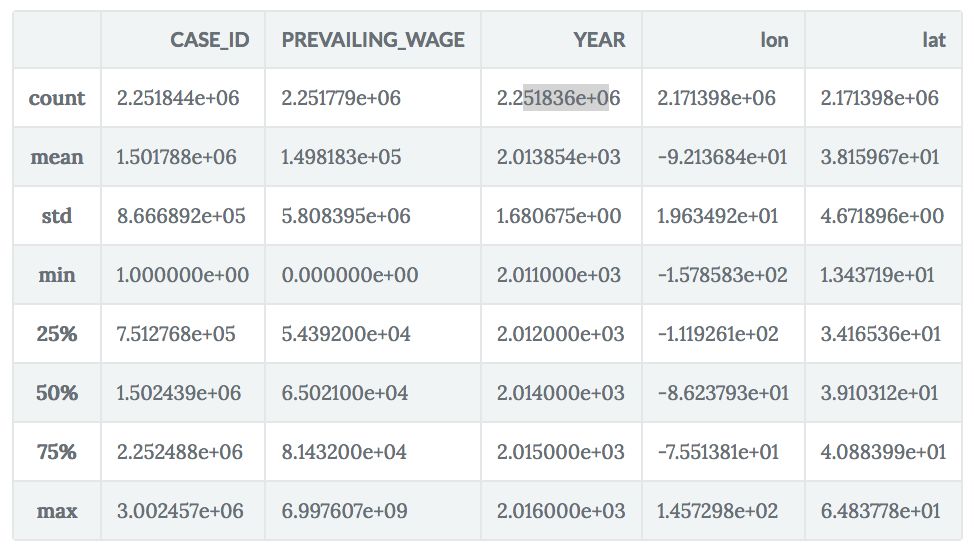
数据集共有11列,其中1列是目标变量(case_status)。也就是说,数据有1个目标变量和10个独立变量。你当然应该检查下目标变量的分类。你可以在df的case_status特征上使用.unique()方法。
这是一个分类问题。你需要预测case_status的所属分类。
df['CASE_STATUS'].unique()
df.head(10)
特征工程和数据预处理
注意,目标变量包含6个不同的分类:
Certified
Certified Withdrawn
Rejected
Invalidatd
Pending Quality and compliance review
Denied
取决于具体的业务问题,你需要决定这是一个多元分类问题,还是一个二元分类问题。如果是二元分类问题,那么只有Certified(批准)和Denied(拒签)两个分类。所以你要做的第一件事是将剩余的分类转换为Certified或Denied。其中,Rejected和Invalidated都是拒签的情形,所以应该将这两种状态转换为Denied。在美签中,Pending Quality and compliance的最终结果最可能是拒签,所以也应该转换为Denied。Certified withdrawn(批准后撤回)则是批准的情形,因为签证已经批准了,只不过雇主因为种种原因(比如劳工更换工作单位)而决定撤回申请。
df.CASE_STATUS[df['CASE_STATUS']=='REJECTED'] = 'DENIED'
df.CASE_STATUS[df['CASE_STATUS']=='INVALIDATED'] = 'DENIED'
df.CASE_STATUS[df['CASE_STATUS']=='PENDING QUALITY AND COMPLIANCE REVIEW - UNASSIGNED'] = 'DENIED'
df.CASE_STATUS[df['CASE_STATUS']=='CERTIFIED-WITHDRAWN'] = 'CERTIFIED'
至于Withdrawn(撤回)分类,由于很难预测数据集中的Withdrawn案例最终结果如何,我们可以直接移除这一分类。另一个移除Withdrawn分类的原因是它在整个数据集中所占的比例小于1%,这意味着模型很可能无法精确分类Withdrawn分类。
df = df.drop(df[df.CASE_STATUS == 'WITHDRAWN'].index)
查看下数据集中批准和拒签的比例各是多少?
df = df[df['CASE_STATUS'].notnull()]
print(df['CASE_STATUS'].value_counts())
结果:
CERTIFIED 2114025
DENIED 70606
Name: CASE_STATUS, dtype: int64
整个数据集中,只有大约3.2%的申请被拒,这意味着,数据集中大约96.8%的申请被批准了。这表明数据集是高度失衡的。失衡数据集的一大问题是模型将更偏向频繁出现的分类;在这个例子中,模型将偏向批准。有一些解决失衡问题的技术,不过本教程没有使用它们。
处理缺失值
这个数据集并不整洁,其中包含很多缺失值。你必须处理缺失值。最简单的方法是移除它们,不过这会损失信息。让我们逐步看看如何处理缺失值:
CASE_ID 0
CASE_STATUS 0
EMPLOYER_NAME 11
SOC_NAME 12725
JOB_TITLE 6
FULL_TIME_POSITION 1
PREVAILING_WAGE 41
YEAR 0
WORKSITE 0
lon 77164
lat 77164
dtype: int64
就EMPLOYER_NAME(雇主名称)而言,我们可以用众数(最常出现的值)填充11项缺失值:
df['EMPLOYER_NAME'] = df['EMPLOYER_NAME'].fillna(df['EMPLOYER_NAME'].mode()[0])
如果不放心,我们可以用assert语句确保不存在空值。如有空值,Python会抛出AssertionError。
assert pd.notnull(df['EMPLOYER_NAME']).all().all()
下面我们将查看prevailing_wage(现行工资)。大部分申请的工资都在4万到8万美元之间。某些申请的工资超过50万美元,有些则为0美元——由于这些情形很罕见,它们应该作为离散值移除(在2%分位和98%分位处截断)。
df.loc[df.PREVAILING_WAGE < 34029, 'PREVAILING_WAGE']= 34029
df.loc[df['PREVAILING_WAGE'] > 138703, 'PREVAILING_WAGE']= 138703
截断之后,现行工资的均值和中位数非常接近。中位数为6万5千美金,而均值为6万8千美金。我们最终将用均值替换缺失值。不过由于这两个值非常接近,你也可以用中位数替换。
df.PREVAILING_WAGE.fillna(df.PREVAILING_WAGE.mean(), inplace = True)
JOB_TITLE、FULL_TIME_POSITION、SOC_NAME列也可以使用众数填充缺失值。
df['JOB_TITLE'] = df['JOB_TITLE'].fillna(df['JOB_TITLE'].mode()[0])
df['FULL_TIME_POSITION'] = df['FULL_TIME_POSITION'].fillna(df['FULL_TIME_POSITION'].mode()[0])
df['SOC_NAME'] = df['SOC_NAME'].fillna(df['SOC_NAME'].mode()[0])
移除lat和lon列
我们将移除lat(纬度)和lon(经度)列,因为它们和工作地点列重复了。在DataFrame上使用drop方法可以移除列,只需指定列名和轴(0表示行、1表示列)。
df = df.drop('lat', axis = 1)
df = df.drop('lon', axis = 1)
特征创建
基于现有的数据有可能制作一个模型,不过,某些列包含尚待提取的信息。
EMPLOYER_NAME包含雇主的名称,其中包含大量不同的雇主(为雇员提交申请的公司)。我们无法直接在模型中使用EMPLOYER_NAME,因为类别太多了;超过500个不同雇主。
提交申请最多的5家公司是Infosys、TCS、Wipro、Deloitte、IBM。不过,根据经验,由大学提交的申请更容易通过。
所以,问题是,我们如何从该特征中提取出一些信息?
好吧,我们大概可以创建一个名为NEW_EMPLOYER的新特征:雇主名称是否包含University(大学)字符串。
创建一个空列相当简单:
df['NEW_EMPLOYER'] = np.nan
在检查是否包含字符串时,为了避免大小写问题,我们将雇主名称统一转换为小写:
df['EMPLOYER_NAME'] = df['EMPLOYER_NAME'].str.lower()
df.NEW_EMPLOYER[df['EMPLOYER_NAME'].str.contains('university')] = 'university'
df['NEW_EMPLOYER']= df.NEW_EMPLOYER.replace(np.nan, 'non university', regex=True)
变量SOC_NAME也存在这个问题。它包括职业名称。我们将创建一个名为OCCUPATION的新变量:
df['OCCUPATION'] = np.nan
df['SOC_NAME'] = df['SOC_NAME'].str.lower()
df.OCCUPATION[df['SOC_NAME'].str.contains('computer','programmer')] = 'computer occupations'
df.OCCUPATION[df['SOC_NAME'].str.contains('software','web developer')] = 'computer occupations'
df.OCCUPATION[df['SOC_NAME'].str.contains('database')] = 'computer occupations'
df.OCCUPATION[df['SOC_NAME'].str.contains('math','statistic')] = 'Mathematical Occupations'
df.OCCUPATION[df['SOC_NAME'].str.contains('predictive model','stats')] = 'Mathematical Occupations'
df.OCCUPATION[df['SOC_NAME'].str.contains('teacher','linguist')] = 'Education Occupations'
df.OCCUPATION[df['SOC_NAME'].str.contains('professor','Teach')] = 'Education Occupations'
df.OCCUPATION[df['SOC_NAME'].str.contains('school principal')] = 'Education Occupations'
df.OCCUPATION[df['SOC_NAME'].str.contains('medical','doctor')] = 'Medical Occupations'
df.OCCUPATION[df['SOC_NAME'].str.contains('physician','dentist')] = 'Medical Occupations'
df.OCCUPATION[df['SOC_NAME'].str.contains('Health','Physical Therapists')] = 'Medical Occupations'
df.OCCUPATION[df['SOC_NAME'].str.contains('surgeon','nurse')] = 'Medical Occupations'
df.OCCUPATION[df['SOC_NAME'].str.contains('psychiatr')] = 'Medical Occupations'
df.OCCUPATION[df['SOC_NAME'].str.contains('chemist','physicist')] = 'Advance Sciences'
df.OCCUPATION[df['SOC_NAME'].str.contains('biology','scientist')] = 'Advance Sciences'
df.OCCUPATION[df['SOC_NAME'].str.contains('biologi','clinical research')] = 'Advance Sciences'
df.OCCUPATION[df['SOC_NAME'].str.contains('public relation','manage')] = 'Management Occupation'
df.OCCUPATION[df['SOC_NAME'].str.contains('management','operation')] = 'Management Occupation'
df.OCCUPATION[df['SOC_NAME'].str.contains('chief','plan')] = 'Management Occupation'
df.OCCUPATION[df['SOC_NAME'].str.contains('executive')] = 'Management Occupation'
df.OCCUPATION[df['SOC_NAME'].str.contains('advertis','marketing')] = 'Marketing Occupation'
df.OCCUPATION[df['SOC_NAME'].str.contains('promotion','market research')] = 'Marketing Occupation'
df.OCCUPATION[df['SOC_NAME'].str.contains('business','business analyst')] = 'Business Occupation'
df.OCCUPATION[df['SOC_NAME'].str.contains('business systems analyst')] = 'Business Occupation'
df.OCCUPATION[df['SOC_NAME'].str.contains('accountant','finance')] = 'Financial Occupation'
df.OCCUPATION[df['SOC_NAME'].str.contains('financial')] = 'Financial Occupation'
df.OCCUPATION[df['SOC_NAME'].str.contains('engineer','architect')] = 'Architecture & Engineering'
df.OCCUPATION[df['SOC_NAME'].str.contains('surveyor','carto')] = 'Architecture & Engineering'
df.OCCUPATION[df['SOC_NAME'].str.contains('technician','drafter')] = 'Architecture & Engineering'
df.OCCUPATION[df['SOC_NAME'].str.contains('information security','information tech')] = 'Architecture & Engineering'
df['OCCUPATION']= df.OCCUPATION.replace(np.nan, 'Others', regex=True)
由于所在州对签证申请影响重大,我们将从WORKSITE中分割出州信息:
df['state'] = df.WORKSITE.str.split('\s+').str[-1]
为了计算概率,我们需要将目标分类转换为二值,即0和1.
from sklearn import preprocessing
class_mapping = {'CERTIFIED':0, 'DENIED':1}
df["CASE_STATUS"] = df["CASE_STATUS"].map(class_mapping)
移除用不到的变量:
df = df.drop('EMPLOYER_NAME', axis = 1)
df = df.drop('SOC_NAME', axis = 1)
df = df.drop('JOB_TITLE', axis = 1)
df = df.drop('WORKSITE', axis = 1)
df = df.drop('CASE_ID', axis = 1)
在阅读建模部分之前,别忘了检查变量的数据类型。例如,有些变量应该被用作类别或因子,但是它们的格式却是对象字符串。
所以,我们需要将这些变量的类型从对象转为类别,因为它们属于类别特征。
df1[['CASE_STATUS', 'FULL_TIME_POSITION', 'YEAR','NEW_EMPLOYER','OCCUPATION','state']] = df1[['CASE_STATUS', 'FULL_TIME_POSITION', 'YEAR','NEW_EMPLOYER','OCCUPATION','state']].apply(lambda x: x.astype('category'))
切分数据为训练集和测试集
将数据集一分为二,60%为训练集,40%为测试集。
X = df.drop('CASE_STATUS', axis=1)
y = df.CASE_STATUS
seed = 7
test_size = 0.40
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=seed)
检查一下训练集中是否有null值:
print(X_train.isnull().sum())
应该没有:
FULL_TIME_POSITION 0
PREVAILING_WAGE 0
YEAR 0
NEW_EMPLOYER 0
OCCUPATION 0
state 0
dtype: int64
由于XGBoost只能处理数值数据。因此我们需要使用pd.get_dummies()对类别值进行独热编码。
X_train_encode = pd.get_dummies(X_train)
X_test_encode = pd.get_dummies(X_test)
XGBoost
XGBoost是“Extreme Gradient Boosting”(极端梯度提升)的简称,这是一种监督学习方法。具体而言,是梯度提升决策树的一种注重速度和性能的实现。
提升是一种集成方法,集成方法寻求基于“弱”分类器创建强分类器(模型)。在这一上下文中,弱和强指预测目标变量实际值的准确程度。通过在其他模型基础上迭代地添加模型,前一个模型的误差将由下一个预测模型纠正,直到达到满意的表现。
梯度提升同样包含逐渐增加模型,纠正之前模型误差地集成方法。不过,并不在每次迭代中给分类器分配不同的权重,而是用新模型去拟合之前预测的新残差,并最小化加上最新预测后的损失。
所以,最终将使用梯度下降技术更新模型,梯度提升由此得名。
关于XGBoost更多的信息,可以参考我们的XGBoost课程。
XGBoost可以直接通过pip安装:
pip install xgboost
用于分类的XGBoost模型为XGBClassifier()。创建XGBClassifier()时,max_features可以设为sqrt,即特征数的平方根。max_features是寻找最佳分割时需要考虑的特征数。所以,假设n_features为100,那么max_features取值为10.
import xgboost
gbm=xgboost.XGBClassifier(max_features='sqrt', subsample=0.8, random_state=10)
我们使用GridSearchCV()调整超参数:
GridSearchCV()实现了fit和score方法。它也同样实现了predict、predict_probad、decision_function、transform、inverse_transform方法(如果底层使用的估计器实现了这些方法。)
应用这些方法的估计器的参数是通过在参数网格上交叉验证、网格搜索得到的。
n_estimators的取值,推荐1、10、100,learning_rate的取值,推荐0.1、0.01、0.5。
n_estimators是提升阶段数。梯度提升对过拟合的鲁棒性相当不错,因此较大的取值通常意味着更好地表现。
学习率。学习率可以减慢模型的训练速度,避免过快学习导致过拟合。通常将学习率设为0.1到0.3之间的数字。
通过三折交叉验证,选出最佳learning_rate和n_estimators值。
from sklearn.model_selection importGridSearchCV
parameters = [{'n_estimators': [10, 100]},
{'learning_rate': [0.1, 0.01, 0.5]}]
grid_search = GridSearchCV(estimator = gbm, param_grid = parameters, scoring='accuracy', cv = 3, n_jobs=-1)
grid_search = grid_search.fit(train_X, train_y)
拟合训练集得到了97%的精确度(学习率0.5):
grid_search.grid_scores_, grid_search.best_params_, grid_search.best_score_
grid_search.best_estimator_将返回网格搜索得到的最佳模型:
XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bytree=1, gamma=0, learning_rate=0.5, max_delta_step=0,
max_depth=3, max_features='sqrt', min_child_weight=1, missing=None,
n_estimators=100, n_jobs=1, nthread=None,
objective='binary:logistic', random_state=10, reg_alpha=0,
reg_lambda=1, scale_pos_weight=1, seed=None, silent=True,
subsample=0.8)
使用这一最佳的超参数组合在训练集上进行训练,并在测试集上进行预测。最终得到了96.56%的精确度。
从精确度上来看,我们的模型表现得相当不错。然而,果真如此吗?别忘了,我们的数据集是一个失衡的数据集。模型表现到底如何?不能只看精确度。
我们绘制AUROC曲线看看。
from sklearn import metrics
import matplotlib.pyplot as plt
fpr_xg, tpr_xg, thresholds = metrics.roc_curve(y_test, y_pred)
auc_xgb = np.trapz(tpr_xg,fpr_xg)
plt.plot(fpr_xg,tpr_xg,label=" auc="+str(auc_xgb))
plt.legend(loc=4)
plt.show()
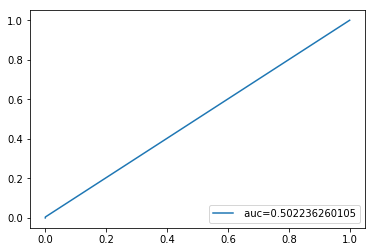
果然,在AUROC曲线下,模型原形毕露了。AUC值0.5左右,ROC曲线基本上是对角线,这是随机猜测的水平!
看来,我们真应该用些应对失衡分类的技术,例如欠采样和过采样,或者SMOTE方法。
由于这篇文章已经够长了,这里就不深入讨论如何克服失衡问题了。虽然结果不如人意,但是我们仍然通过这个例子熟悉了机器学习的基本流程。
最后,我们将介绍如何储存模型,这样下次预测就可以直接使用了,不用再费时费力地从头开始训练模型。最简单直接的方法,就是使用Python的Pickle模块。
import pickle
XGB_Model_h1b = 'XGB_Model_h1b.sav'
pickle.dump(gbm, open(XGB_Model_h1b, 'wb'))
结语
创建模型最重要的部分是特征工程和特征选取过程。我们应该从特征中提取最多的信息,让我们的模型更坚韧、更精确。特征选取和提取需要时间和经验。可能有多种处理数据集中的信息的方法。
有许多机器学习算法,你应该选择能够给出最佳结果的算法。你也可以使用不同的算法然后将它们集成起来。在生产环境中也可以进行A/B测试,以知晓哪个模型表现更优。勇往直前,动手编程,尝试不同的方法。快乐编程!
-
机器学习
+关注
关注
66文章
8118浏览量
130550 -
数据分析
+关注
关注
2文章
1351浏览量
33732 -
python
+关注
关注
51文章
4675浏览量
83465
原文标题:Python | 如何使用机器学习预测H1B签证状态
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
怎么有效学习Python数据分析?
什么是探索性测试ET
Python机器学习经典实例教程指南和附带源码
成为Python数据分析师,需要掌握哪些技能
成为Python数据分析师,需要掌握哪些技能

设计多网络协议的Python网络编程的探索性指南
细分模型探索性数据分析和预处理

Sweetviz让你三行代码实现探索性数据分析
Sweetviz: 让你三行代码实现探索性数据分析





 工商网监
工商网监
评论