 以预测葡萄酒品质作为例子,带你步入机器学习的大门
以预测葡萄酒品质作为例子,带你步入机器学习的大门
编者按:Udacity机器学习、深度学习导师Ashwin Hariharan以预测葡萄酒品质作为例子,带你步入机器学习的大门。
机器学习(ML)是人工智能的一个子领域。它赋予计算机学习的能力,而无需显式地编程。从搜索趋势来看,这几年机器学习的流行度和需求明显上涨。
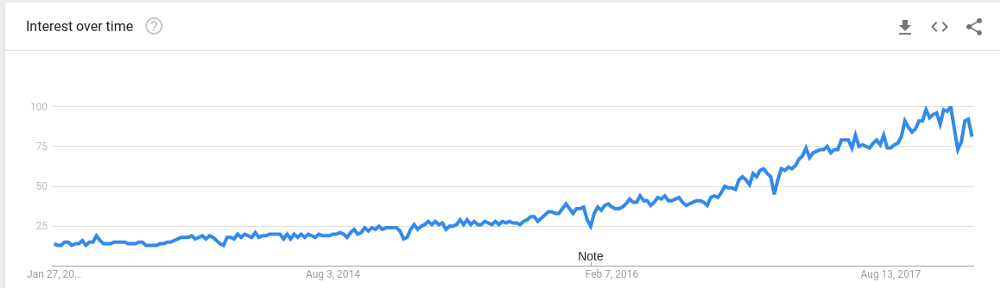
这篇机器学习入门教程是我写的上一篇数据科学教程的姊妹篇。上一篇展示了如何使用数据科学来理解葡萄酒的属性。如果你还没有读过上一篇,推荐首先阅读一下,你将了解数据科学大概是怎么回事。
什么是机器学习?
人类通过过往的经验学习。利用眼、耳、触等感官输入从周围获得数据。我们接着以许多有趣、有意义的方式使用这些数据。最常见的,我们使用它对未来做出精确的预测。换句话说,我们学习。
例如,今年的这个时候会下雨吗?如果你忘记了女友的生日,她会发疯吗?红灯时应该停下吗?你应该投资某处不动产吗?Jon Snow在《权力的游戏》的下一季存活的概率?为了回答这些问题,你需要过去的数据。
另一方面,传统上计算机不像我们一样使用数据。它们需要一组明确的指令(算法)以供遵循。
现在问题来了——计算机可以像人类一样从过去的经验(数据)中学习吗?是的——你可以赋予它们学习和预测未来事件的能力,而无需显式地编程。从自动驾驶到搜索行星,机器学习的应用场景广阔无垠。
另外,我读过一篇很棒的解释数据科学、机器学习、人工智能区别的文章。这是一篇比较详尽全面的文章,所以我在这里总结一下:
数据科学产生洞见
机器学习产生预测
人工智能产生行动
这些领域间有许多交叉重叠,因此这些术语经常被不加区别地使用。
融资时,是AI。招聘时,是ML。实现时,是线性回归。调试时,是printf()
在Netflix,机器学习用来从用户的行为数据中学习,显示推荐。Google搜索显示和你有关的结果——同样,这需要使用很多ML技术不断学习场景背后的数据。在数据科学和ML地带,数据就是黄金。如果Tyrion Lannister面对ML和AI的世界,他可能会说:
一家公司需要数据,就像剑需要磨刀石才能保持锋利。
现在我们理解了什么是机器学习,是时候深入了。
谁应该阅读这篇教程:
如果你想要入门机器学习,却因为发现数学,统计学,从头实现算法太复杂,本文很适合你。
在你学习的某个阶段,你将需要进一步深入——你不可能总是回避数学!我希望你读完本文后,能有动机探索这一领域各个深度的问题。
如果你有Python编程基础,并阅读过上一篇文章,你可以开始了。
让我们开始!
我们将学习构建一个基于葡萄酒属性预测葡萄酒品质的机器学习模型。读完本文后,你将理解:
不同的ML算法和技术
如何训练和创建分类器
构建ML模型的常见错误,以及如何摆脱它们
如何分析和解释模型的表现
机器学习类型
监督学习(本教程将讨论这一主题)
顾名思义,监督学习需要人类来“监督”,告诉计算机正确答案。我们传入包含许多特征的训练数据,并给出正确答案。
为了类比,想象计算机是一个如同一张白纸的小孩。他什么也不知道。
现在,你如何教会Jon Snow猫和狗的区别?答案很直观——你带它出去散步,当你看到一只猫时,你指着猫说:“这是猫。”你继续走,可能会看到一条狗,所以你指着狗说:“这是狗。”随着时间的推移,你不断展示狗和猫,小孩会学习两者的区别。
当然,你总是可以给Jon看很多猫狗图片,而不用外出散步。Instagram是你的救星!:P
就我们的葡萄酒数据集而言,我们的机器学习模型将学习葡萄酒的品质(quality)和剩余属性的关系。换句话说,它将学习识别特征和目标(品质)间的模式。
无监督学习
这里我们不给计算机需要预测的“目标”标签。相反,我们让计算机自行发现模式,接着选择最说得通的模式。这一技术很有必要,因为经常我们甚至不知道要在数据中找出什么。
强化学习
强化学习用来训练智能体的“表现”,以及学习给定场景下的最佳行动,基于奖励和反馈。这和AI有很多交叉。
除此之外,还有其他类型的ML,比如半监督学习、聚类。
监督学习可以解决什么问题?
总体来说,监督学习用于解决两类问题:
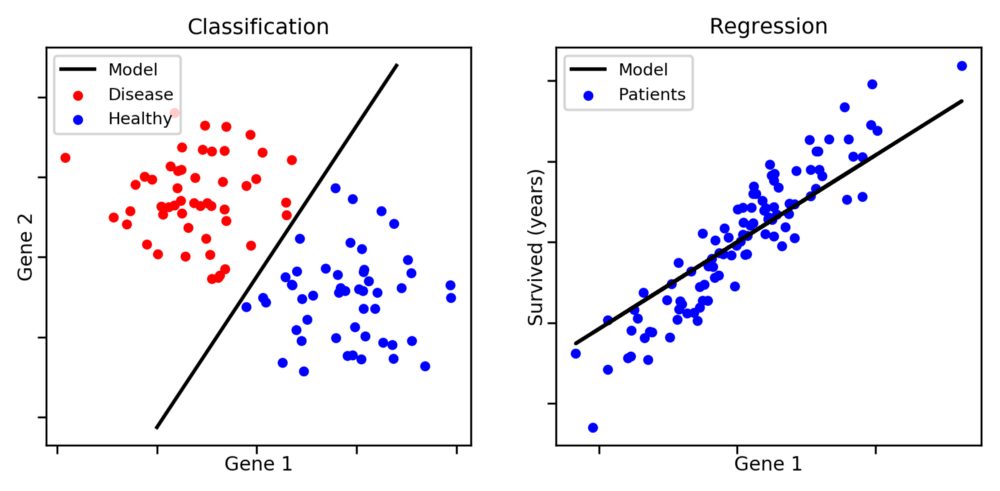
图片来源:aldro61.github.io
分类:当你需要将特定观测归类为一组。在上图中,给定一个数据点,你需要分类它是蓝点还是红点。其他例子包括,识别垃圾邮件,分配资讯的类别——比如运动、天气、科学。
回归:用于预测连续值。例如,预测不动产价格。
注意,分类问题不一定是二元的——我们可以有两个分类以上的问题。
另一方面,判定癌症患者的期望寿命会是一个回归问题。在这一情形下,我们的模型将需要找到一条能够很好地概括大多数数据点的直线或曲线。
一些回归问题也可以被转换为分类问题。此外,某些特定种类的问题可能既是分类问题,又是回归问题。
机器学习的机制
大部分监督学习问题分为三步:
第一步:预处理、转换、分割数据
第一步是分析数据,并为训练作准备。我们观察数据的倾向性、分布、特征的平均数和中位数等统计数据。上一篇教程介绍了这些。
之后我们可以预处理数据,并在必要时应用特征转换。
接着,我们将数据分为两部分——较大的一部分用作训练,较小的一部分用作测试。分类器将使用训练数据集进行“学习”。我们需要单独的数据来测试和验证,这样我们可以看到我们的模型在未见数据上工作得有多好。
第二步:训练
接着我们创建模型。我们通过创建函数或“模型”,并使用数据训练它做到这一点。函数将使用我们选择的算法,使用我们的数据训练自身,并理解模式(也就是学习)。注意,分类器表现得多好取决于它的老师——我们需要以正确的方式训练它。

忧心忡忡的父母:如果你所有的朋友跳桥了,你会跟随他们吗?机器学习算法:会。
第三步:测试和验证
训练好模型后,我们可以给它新的未见数据,而模型将给出输出或预测。
第四步:超参数调整
最后,我们将尝试改善算法的表现。
现在,在我们深入机器学习算法之前,让我们了解下分类或回归问题中可能出现的误差。
偏离导致的误差——精确度和欠拟合
当模型具有足够多的数据但复杂度不足以捕捉其中的关系时,偏离出现了。模型持续、系统地错误表示数据,导致预测的低精确度。这被称为欠拟合。
简单而言,当我们拥有一个贫乏的模型时,偏离出现了。例如,当我们试图基于《权力的游戏》角色的身高和服饰识别他们是贵族还是农夫时,如果我们的模型只能根据身高划分和分类角色,那么它会把Tyrion Lannister(矮人)标记为农夫——这大错特错!
另一个例子,当我们想要通过颜色和形状分类目标(例如复活节彩蛋)时,如果我们的模型只能根据颜色划分和分类目标,它将持续地错误标记未来的目标——例如将五颜六色的彩虹标记为复活节彩蛋。
就我们的葡萄酒数据集而言,如果我们的机器学习分类器只“喝”一种葡萄酒,它会欠拟合。:P
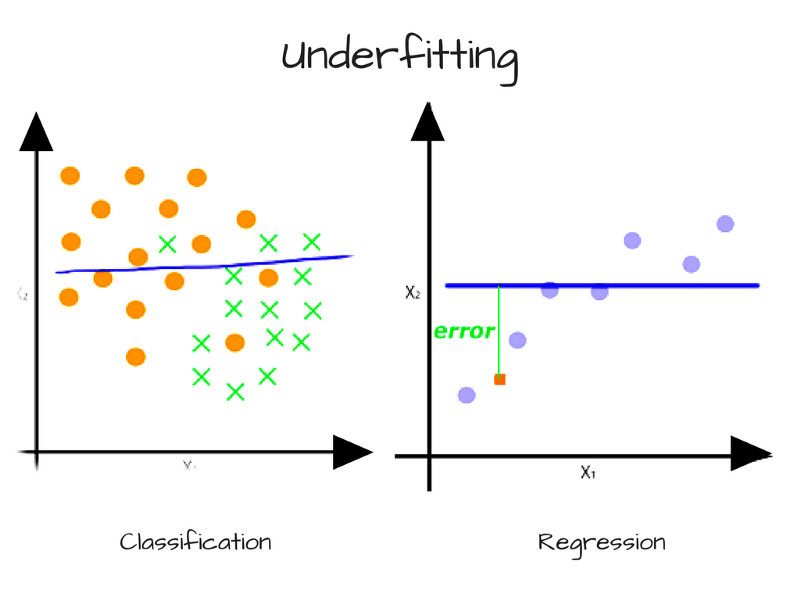
另一个例子是本质上为多项式的连续数据,而模型只能表示线性关系。在这一情形下,我们传给模型再多的数据也无济于事,因为模型无法表示内在的关系。为了克服偏离导致的误差,我们需要更复杂的模型。
方差导致的误差——准确率和欠拟合
方差是衡量模型对训练数据的子集有多“敏感”的测度。
训练模型时,我们通常使用有限数量的样本。如果我们使用随机选择的数据子集反复训练模型,我们会期望它的预测会因为特定样本的不同而不同。

出现一些方差是正常的,但过多方差意味着模型无法将其预测推广到更大的数据集。在这一场景下,模型在已见数据上表现得很精确,但在未见数据点上表现得很糟糕。对训练集高度敏感也称为过拟合,一般在模型过于复杂时出现。
通常我们可以通过训练更多数据降低模型预测的方差,提升预测的准确率。如果无法获得更多数据,我们也可以通过限制模型的复杂度控制方差。

对于程序员而言,挑战在于使用能够解决问题的最优算法,避免高偏离或高方差,因为:
增加偏离将减少方差
增加方差将减少偏离
这通常被称为偏离和方差的折衷。关于这点的细节,可以参考scott.fortmann-roe.com/docs/BiasVariance.html
和传统编程不同,当你试图找到机器学习和深度学习问题的最佳模型时,常常需要涉及大量基于试错的方法。
现在,你需要对可以用来训练模型的一些算法有个概念。我不会深入数学或底层的实现细节,但应该足以让你观其大略。
一些最常用的机器学习算法:
1. 高斯朴素贝叶斯
这个方法在20世纪50年代就出现了。它属于概率分类器或条件概率算法家族,假定特征之间相互独立。对识别垃圾邮件和分类资讯之类的分类问题而言,朴素贝叶斯很有效。
2. 决策树
基本上这是一个类树的数据结构,作用和流程图差不多。决策树是一种使用类树的数据结构建模决策和可能结果的分类算法。算法工作的方式是:
将数据集的最佳属性作为树的根节点。
节点,或者说分岔处,经常被称为“决策节点”。它通常表示一个测试或条件(比如是多云还是晴天)。
分岔表示每个决策的输出。
叶节点表示最终输出,即标签(在分类问题中),或离散值(在回归问题中)。
3. 随机森林
单独使用时,决策树倾向于过拟合。而随机森林有助于纠正可能出现的过拟合。随机森林使用多棵决策树——使用大量不同的决策树(预测不同),结合这些树的结果以得到最终输出。
随机森林使用一种称为bagging的集成算法,这种算法有助于减少方差和过拟合。
给定训练集X = x1, …, xn,相应标签/输出Y = y1, …, yn,bagging反复(B次)选择训练集中的一个随机样本(有放回)。
基于这些样本训练决策树。
通过分类树的多数投票做出最终分类。
除此之外,还有其他机器学习算法,比如支持向量机,集成方法和很多非监督学习方法。
现在,是时候开始我们的训练了!
首先,我们需要预备我们的数据
在机器学习的游戏中,你回归,或者你分类
在这篇教程中,我们将把回归问题转换为分类问题。所有评分低于5分的葡萄酒分类为0(差),评分为5分或6分的葡萄酒分类为1(一般),7分以上的葡萄酒分类为2(好)。
# 定义类别的分割点。
bins = [1,4,6,10]
# 定义类别
quality_labels=[0,1,2]
data['quality_categorical'] = pd.cut(data['quality'], bins=bins, labels=quality_labels, include_lowest=True)
# 显示头两行
display(data.head(n=2))
# 分离数据为特征和目标标签
quality_raw = data['quality_categorical']
features_raw = data.drop(['quality', 'quality_categorical'], axis = 1)

如你所见,我们有了一个新的列quality_categorical(品质类别),基于之前选择的区间分类品质评分。quality_categorical列将作为目标值,而其他列作为特征。
接着,创建数据的训练子集和测试子集:
from sklearn.model_selection import train_test_split
# 将数据分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(features_raw,
quality_raw,
test_size = 0.2,
random_state = 0)
# 显示分离的结果
print("Training set has {} samples.".format(X_train.shape[0]))
print("Testing set has {} samples.".format(X_test.shape[0]))
Trainingset has 1279 samples.
Testingset has 320 samples.
在上面的代码中,我们使用了sklearn的train_test_split方法。该方法接受特征数据(X)和目标标签(y)作为输入。它打乱数据集,并将其分为两部分——80%用于训练,剩余20%用于测试。
接着,我们将使用一种算法训练,并评估其表现
我们需要一个函数,接受我们选择的算法、训练数据集、测试数据集。函数将运行训练,接着使用一些表现测度评估算法的表现。
最终我们编写了一个可以使用任意3种选定的算法的函数,并为每种算法进行训练。然后汇总结果,并加以可视化。
# 从sklearn导入任意3种监督学习分类模型
from sklearn.naive_bayes importGaussianNB
from sklearn.tree importDecisionTreeClassifier
from sklearn.ensemble importRandomForestClassifier
#from sklearn.linear_model import LogisticRegression
# 初始化3个模型
clf_A = GaussianNB()
clf_B = DecisionTreeClassifier(max_depth=None, random_state=None)
clf_C = RandomForestClassifier(max_depth=None, random_state=None)
# 计算训练集1%、10%、100%样本数目
samples_100 = len(y_train)
samples_10 = int(len(y_train)*10/100)
samples_1 = int(len(y_train)*1/100)
# 收集结果
results = {}
for clf in [clf_A, clf_B, clf_C]:
clf_name = clf.__class__.__name__
results[clf_name] = {}
for i, samples in enumerate([samples_1, samples_10, samples_100]):
results[clf_name][i] =
train_predict_evaluate(clf, samples, X_train, y_train, X_test, y_test)
#print(results)
# 可视化选定的3种学习模型的测度
vs.visualize_classification_performance(results)
输出将类似:

上图第一行为训练数据上的表现,第二行为测试数据上的表现。这些表现测度意味着什么?请继续阅读……
分类问题的表现测度
精确度
最简单也最常用的测度,正确预测除以数据点总数。
何时精确度不是一个良好的表现指标?
有时,数据集中的类别分布会有很严重的倾向性,也就是说,某些分类有很多数据点,而另一些分类的数据点要少得多。让我们看一个例子。
在一个由100封邮件组成的数据集中,10封是垃圾邮件,其他90封不是。这意味者数据集有倾向性,并不是均匀分布的。
现在,想象一下,我们训练一个预测是否是垃圾邮件的分类器。它的表现是90%精确率。听起来很不错?并非如此。
分类器可以标记或预测所有100封邮件为“非垃圾邮件”,而仍然能得到90%的精确度!但这个分类器完全无用,因为它把所有邮件都分类为非垃圾邮件。
所以,精确度并不总是一个良好的指标。在特定情况下,其他测度能帮助我们更好地评估模型:
准确率
准确率告诉我们,分类为垃圾邮件的邮件中有多少确实是垃圾邮件,即真阳性/(真阳性 + 假阳性)
召回
召回或灵敏度告诉我们确实是垃圾邮件的邮件中有多少被分类为垃圾邮件,即真阳性/(真阳性 + 假阴性)
我们之前提到的具有90%精确度的分类器,它的准确率和召回是多少呢?让我们算一下——它的真阳性是0,假阳性是0,假阴性是10。根据前面提到的公式,我们的分类器的准确率和召回均为0——相当反常的评分!现在看起来不那么好了,不是吗?
F1评分
F1为准确率(precision)和召回(recall)的调和平均数:
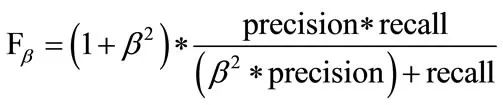
就F1而言,β = 1. 上式是F评分的公式,β值越大,越强调准确率。
现在,让我们回顾下我们的ML算法的表现:

这些结果表明,高斯朴素贝叶斯的表现不像决策树和随机森林那么好。
你觉得为什么高斯朴素贝叶斯的表现不佳?(提示:你可以往上滚动,重新阅读高斯朴素贝叶斯的解释!)
特征重要性
scikit-learn提供的一些分类算法,有一个特征重要性属性,可以让你查看基于选定算法的每个特征的重要性。
比如,scikit-learn中的随机森林分类器带.feature_importance_:
# 导入一个带`.feature_importance_`的模型
model = RandomForestClassifier(max_depth=None, random_state=None)
# 训练模型
model = model.fit(X_train, y_train)
# 提取特征重要性
importances = model.feature_importances_
print(X_train.columns)
print(importances)
# 绘图
vs.feature_plot(importances, X_train, y_train)
结果如下:
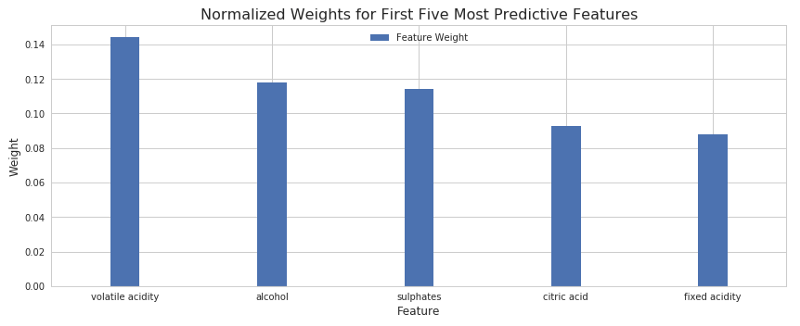
上图显示了5个最重要的特征。酒精含量和挥发性酸水平看起来是最具影响力的因子,接着是硫酸盐、柠檬酸、固定酸度。
超参数调整和优化
你也许已经注意到了,机器学习和数据科学有关。像任何科学一样,它从一些先验观测开始。接着你做出假说,运行一些试验,然后分析它们多大程度上重现了之前的观测。这被称为科学方法,其实这和工程过程也很相似。
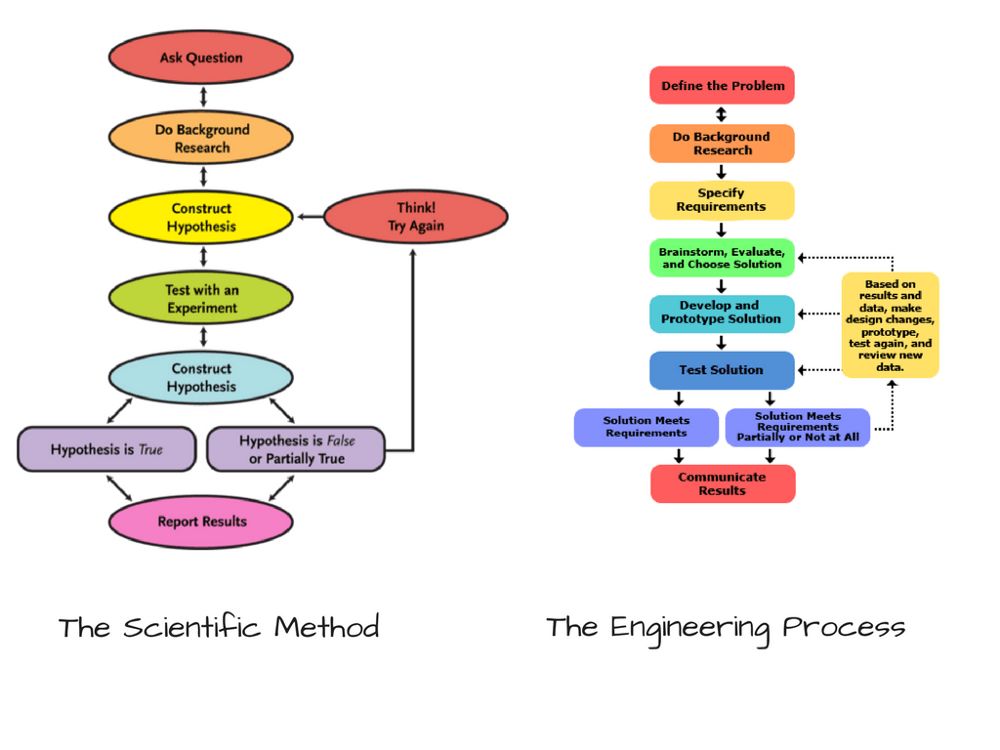
假说可以被认为是“假定”。创建分类器的时候,我们首先假设一些算法,在我们看来,这些算法的效果应该不错。但我们的假说也可能不对。常常,我们需要调整我们的假说,看看它们能不能做得更好。
当选择机器学习模型时,我们做了一些关于它们的超参数的假定。超参数是特殊类型的配置变量,其值无法通过数据集直接计算。数据科学家或机器学习工程师需要通过试验找出这些超参数的最佳值。这一过程称为超参数调整。
现在,就随机森林算法而言,哪些可能是它的超参数?
森林中决策树的数目
寻找树的最佳分岔时考虑的特征数
树的最大深度,即根节点至叶节点的最长路径
就这些超参数而言,我们的随机森林分类器使用scikit-learn的默认值。
scikit-learn提供了一个非常方便的API,让我们可以在“网格”中指定超参数的不同值,然后通过scikit-learn的GridSearchCV API使用这些超参数的可能组合训练并进行交叉验证,给出最优配置。这样我们就不用手工运行这么多迭代。
from sklearn.model_selection importGridSearchCV
from sklean.metrics import make_scorer
clf = RandomForestClassifier(max_depth=None, random_state=None)
# 创建打算调整的参数列表,有必要时使用字典。
"""
n_estimators: 森林中的决策树数量
max_features: 寻找最佳分割时考虑的特征数量
max_depth: 树的最大深度
"""
parameters = {'n_estimators': [10, 20, 30], 'max_features': [3, 4, 5, None], 'max_depth': [5, 6, 7, None]}
# 创建F0.5评分
scorer = make_scorer(fbeta_score, bate=0.5, average="micor")
# 进行网格搜索
grid_obj = GridSearchCV(clf, parameters, scoring=scorer)
# 找到最优参数
grid_fit = grid.obj.fit(X_train, y_train)
# 得到最佳逼近
best_clf = grid_fit.best_estimator_
# 分别使用未优化超参数的模型和优化了超参数的模型进行预测:
predictions = (clf.fit(X_train, y_train)).predict(X_test)
best_predicotins = best_clf.predict(X_test)
# 报告之前和之后的评分
print("Unpotimized model ------")
print("Accuracy score on testing data: {:.p6}".format(accuracy_score(y_test, predictions)))
print("F-score on testing data: {:.4f}".format(fbeta_score(y_test,predictions, beta=0.5, average="micro")))
好了。你可以看到,我们模型的表现略有提升。

使用模型进行预测
最终,给我们的模型多个特征的一组值,看看它的预测:
恭喜!你成功搭建了你自己的机器学习分类器,该分类器可以预测好酒和烈酒。
思考题
你的分类器更适合检测一般的葡萄酒,还是更适合检测好的葡萄酒?你认为可能的原因是什么?
你会向酿酒厂推荐你的分类器吗?为什么?
如果使用回归技术,而不是分类技术,模型的表现将如何?
接下来呢?
尝试在白葡萄酒数据集上预测酒的品质
去Kaggle逛逛,看看不同的数据集,尝试下你觉得有趣的数据集
编写一个使用你的机器学习模型的API服务,然后创建一个web应用/移动应用
-
人工智能
+关注
关注
1776文章
43845浏览量
230591 -
机器学习
+关注
关注
66文章
8122浏览量
130556 -
数据集
+关注
关注
4文章
1178浏览量
24349
原文标题:如何使用机器学习预测葡萄酒品质
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
别墅酒窖--彰显品味生活
PSoC Creator在线或W / W /葡萄酒问题
以浅显易懂的方式带你敲开Linux驱动开发的大门
如何使用NodeMCU、Thingspeak和传感器远程天气跟踪
自回归滞后模型进行多变量时间序列预测案例分享
基于机器学习的车位状态预测方法
区块链技术给葡萄酒拍卖业务带来了哪些优势?
改进粒子群优化神经网络的葡萄酒质量识别





 工商网监
工商网监
评论