 Ravi Munde利用强化学习,实现了对Dino Run的控制
Ravi Munde利用强化学习,实现了对Dino Run的控制
Chrome 浏览器里面有一个小彩蛋,当你没有网络时,打开任意的 URL 都会出现一个恐龙小游戏(Dino Run),按空格键就可以跳跃。当然,直接打开 chrome://dino 也可以玩这个小游戏。近期,一名来自东北大学(美国)的研究生 Ravi Munde 利用强化学习,实现了对 Dino Run 的控制。
以下内容来自 Ravi Munde 博客,人工智能头条编译:
本文将从强化学习的基础开始,并详细介绍以下几个步骤:
在浏览器(JavaScript)和模型(Python)之间构建双向接口
捕获和预处理图像
训练模型
评估
▌强化学习
对许多人来说,强化学习可能是一个新词,但其实小孩学步利用的就是强化学习(RL)的概念,这也是我们的大脑仍然工作的方式。奖励系统是任何 RL 算法的基础,就像小孩学步的阶段,积极的奖励将是来自父母的鼓掌或糖果,而负面奖励则是没有糖果。孩子在开始走路之前首先学会站起来。就人工智能而言,智能体(Agent)的主要目标(在我们的案例中是 Dino)是通过在环境中执行特定的操作序列来最大化某个数字奖励。RL 中最大的挑战是缺乏监督(标记数据)来指导智能体,它必须自己探索和学习。智能体从随机行动开始,观察每个行动带来的回报,并学习如何在面临类似环境状况时预测最佳行动。
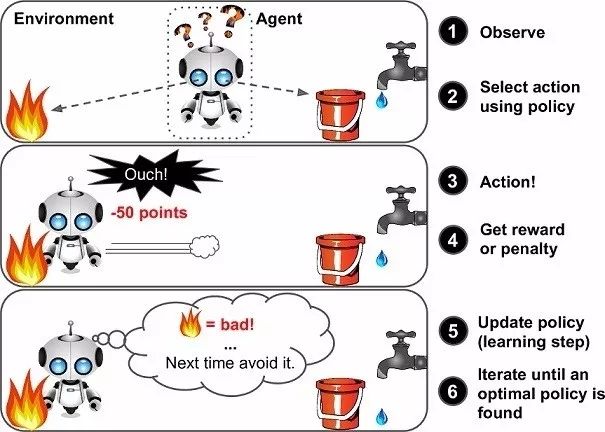
图注:vanilla 强化学习框架
▌Q-learning
我们使用 Q-Learning(RL 中的一种)来尝试逼近一个特殊函数,这个函数可以驱动任何环境状态序列的动作选择策略。Q-Learning 是 RL 的一种无模型实现,针对每个状态、采取的行动和得到的奖励来更新 Q-table,它能让我们了解数据的结构。在我们的例子中,状态是游戏的截图、行动、不动、跳[0,1]。
我们通过回归方法来解决这个问题,并选择具有最高预测 Q 值的动作。

图注:Q-table 样本
▌设置
首先设置环境:
1、选择虚拟机
我们需要一个完整的桌面环境,在这里我们可以捕获和利用屏幕截图对模型进行训练。我选择了 Paperspace ML-in-a-box(MLIAB)Ubuntu 镜像。MLIAB 的优势在于它预装了Anaconda 和许多其他 ML 库。
2、设置和安装 Keras 以使用GPU
Paperspace 的虚拟机已经预先安装了,如果没有的话,可以按照下面的方式:
pip install keraspip install tensorflow
另外,为了确保 GPU 可以被设置识别,执行下面的 python 代码,你应该看到可用的 GPU 设备:
from keras import backend as KK.tensorflow_backend._get_available_gpus()
3、安装 Dependencies
Selenium:
pip install selenium
OpenCV:
pip install opencv-python
下载 Chromedrive:
http://chromedriver.chromium.org
▌游戏框架
打开 chrome://dino,按空格键就可以玩这个游戏了。如果需要修改游戏代码,就要 chromium 的开源库中提取游戏了。
由于这个游戏是用 JavaScript 写的,而我们的模型是用 Python 写的,因此我们需要运用到一些接口工具。
Selenium 是一个比较流行的浏览器自动化工具,用于向浏览器发送操作,并获取当前分数等不同的游戏参数。
在有了发送操作的接口之后,我们还需要一种捕获游戏画面的机制:
Selenium 和 OpenCV 分别为屏幕捕获和图像预处理提供了最佳性能,可实现 6-7 fps 的帧率。
游戏模块
我们使用这个模块实现了 Python 和 JavaScript 之间的接口,下面的代码可以让你知道模块的实现原理:
class Game: def __init__(self): self._driver = webdriver.Chrome(executable_path = chrome_driver_path) self._driver.set_window_position(x=-10,y=0) self._driver.get(game_url) def restart(self): self._driver.execute_script("Runner.instance_.restart()") def press_up(self): self._driver.find_element_by_tag_name("body").send_keys(Keys.ARROW_UP) def get_score(self): score_array = self._driver.execute_script("return Runner.instance_.distanceMeter.digits") score = ''.join(score_array). return int(score)
智能体模块
我们使用智能体模块来封装所有接口。我们使用此模块控制 Dino,并获取智能体在环境中的状态。
class DinoAgent: def __init__(self,game): #takes game as input for taking actions self._game = game; self.jump(); #to start the game, we need to jump once def is_crashed(self): return self._game.get_crashed() def jump(self): self._game.press_up()
游戏状态模块
为了将动作发送到模块并获得相应的结果状态,我们使用了 Game-State 模块。它通过接收和执行操作来简化流程,决定奖励并返回经验元组。
class Game_sate: def __init__(self,agent,game): self._agent = agent self._game = game def get_state(self,actions): score = self._game.get_score() reward = 0.1 #survival reward is_over = False #game over if actions[1] == 1: #else do nothing self._agent.jump() image = grab_screen(self._game._driver) if self._agent.is_crashed(): self._game.restart() reward = -1 is_over = True return image, reward, is_over #return the Experience tuple
▌图像通道
图像捕捉
我们可以通过多种方式捕获游戏画面,例如使用 PIL 和 MSS python 库截取整个屏幕,并裁剪感兴趣区域(RegionofInterest, ROI)。然而,这个方法最大的缺点是对屏幕分辨率和窗口位置的敏感度问题。幸运的是,该游戏使用了 HTML Canvas,我们可以使用 JavaScript 轻松获得 base64 格式的图像。现在,我们使用 selenium 来运行这个脚本。
#javascript code to get the image data from canvasvar canvas = document.getElementsByClassName('runner-canvas')[0];var img_data = canvas.toDataURL()return img_data
def grab_screen(_driver = None): image_b64 = _driver.execute_script(getbase64Script) screen = np.array(Image.open(BytesIO(base64.b64decode(image_b64)))) image = process_img(screen)#processing image as required return image
图像处理
捕捉到的原始图像的分辨率为 600x150,具有 3 通道(RGB)。我们打算使用 4 个连续的屏幕截图作为模型的单个输入,这使得我们单个输入的尺寸为 600x150x3x4。输入太大,需要消耗大量的计算力,而且并不是所有的特征都是有用的,所以我们使用 OpenCV 库来调整、裁剪和处理图像。最终处理后的输入仅为 80x80 像素,而且是单通道(灰度,grey scale)。
def process_img(image): image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) image = image[:300, :500] return image
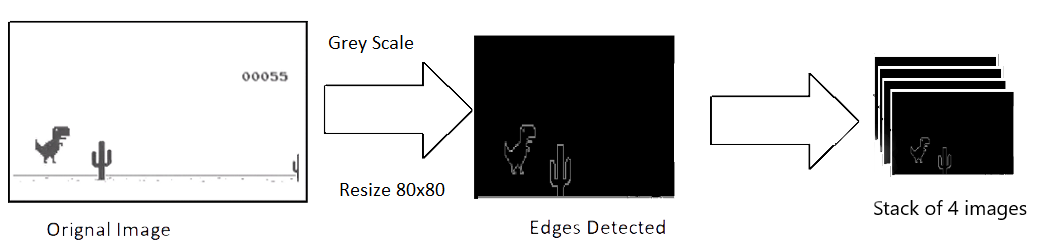
图注:图像处理
模型架构
现在让我们看看模型架构。我们使用一系列的三个卷积层,然后将它们展平为密集层和输出层。针对 CPU 的模型不包括池化层,因为我已经删除了许多特征,添加池化层会导致本已稀疏的特征大量丢失。但有了 GPU 之后,我们的模型可以容纳更多的特征,而不用降低帧率。
最大池化图层显著改善了密集要素集的处理过程。
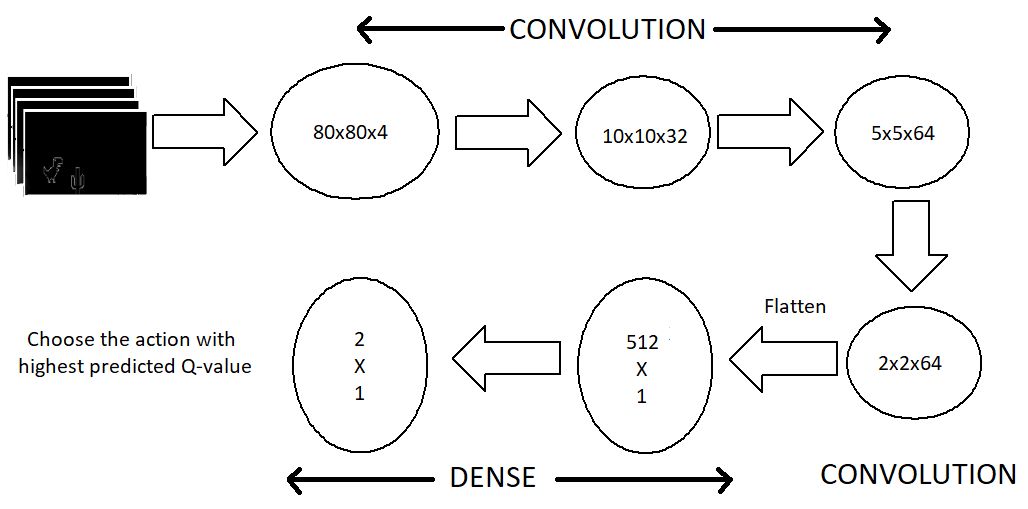
图注:模型架构
输出层由两个神经元组成,每个神经元代表每个动作的最大预测回报。然后我们选择具有最大回报( Q值)的动作。
def buildmodel():
print("Now we build the model")
model = Sequential()
model.add(Conv2D(32, (8, 8), padding='same',strides=(4, 4),input_shape=(img_cols,img_rows,img_channels))) #80*80*4
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Activation('relu'))
model.add(Conv2D(64, (4, 4),strides=(2, 2), padding='same'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3),strides=(1, 1), padding='same'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Activation('relu'))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dense(ACTIONS))
adam = Adam(lr=LEARNING_RATE)
model.compile(loss='mse',optimizer=adam)
print("We finish building the model")
return model
▌训练
以静止开始,并获得初始状态(s_t)
观察步骤数量
预测并执行操作
在 Replay Memory 中存储经验
从 Replay Memory 中随机选择一个批次并在此基础上训练模型
游戏结束后重新开始
def trainNetwork(model,game_state):
# store the previous observations in replay memory
D = deque() #experience replay memory
# get the first state by doing nothing
do_nothing = np.zeros(ACTIONS)
do_nothing[0] =1 #0 => do nothing,
#1=> jump x_t, r_0, terminal = game_state.get_state(do_nothing) # get next step after performing the action
s_t = np.stack((x_t, x_t, x_t, x_t), axis=2).reshape(1,20,40,4) # stack 4 images to create placeholder input reshaped 1*20*40*4
OBSERVE = OBSERVATION epsilon = INITIAL_EPSILON t = 0 while (True): #endless running
loss = 0
Q_sa = 0
action_index = 0
r_t = 0 #reward at t
a_t = np.zeros([ACTIONS]) # action at t
q = model.predict(s_t)
#input a stack of 4 images, get the prediction
max_Q = np.argmax(q)
# chosing index with maximum q value
action_index = max_Q
a_t[action_index] = 1
# o=> do nothing, 1=> jump
#run the selected action and observed next state and reward
x_t1, r_t, terminal = game_state.get_state(a_t)
x_t1 = x_t1.reshape(1, x_t1.shape[0], x_t1.shape[1], 1) #1x20x40x1
s_t1 = np.append(x_t1, s_t[:, :, :, :3], axis=3) # append the new image to input stack and remove the first one
D.append((s_t, action_index, r_t, s_t1, terminal))# store the transition
#only train if done observing; sample a minibatch to train on
trainBatch(random.sample(D, BATCH)) if t > OBSERVE else 0
s_t = s_t1
t += 1
请注意,我们正在从 replay memory 中抽样 32 个随机经验重放,并使用分批训练的方法。这样做的原因是游戏结构中的动作分布不平衡以及避免过度拟合。
def trainBatch(minibatch): for i in range(0, len(minibatch)):
loss = 0
inputs = np.zeros((BATCH, s_t.shape[1], s_t.shape[2], s_t.shape[3])) #32, 20, 40, 4
targets = np.zeros((inputs.shape[0], ACTIONS))
#32, 2
state_t = minibatch[i][0] # 4D stack of images
action_t = minibatch[i][1] #This is action index
reward_t = minibatch[i][2] #reward at state_t due to action_t
state_t1 = minibatch[i][3] #next state
terminal = minibatch[i][4] #wheather the agent died or survided due the action
inputs[i:i + 1] = state_t
targets[i] = model.predict(state_t) # predicted q values
Q_sa = model.predict(state_t1)
#predict q values for next step
if terminal:
targets[i, action_t] = reward_t # if terminated, only equals reward
else:
targets[i, action_t] = reward_t + GAMMA * np.max(Q_sa)
loss += model.train_on_batch(inputs, targets)
结果
我们通过使用这种架构获得了良好的结果。下图显示了训练开始时的平均分数,训练结束时,每 10 场比赛的平均得分远远高于 1000 。
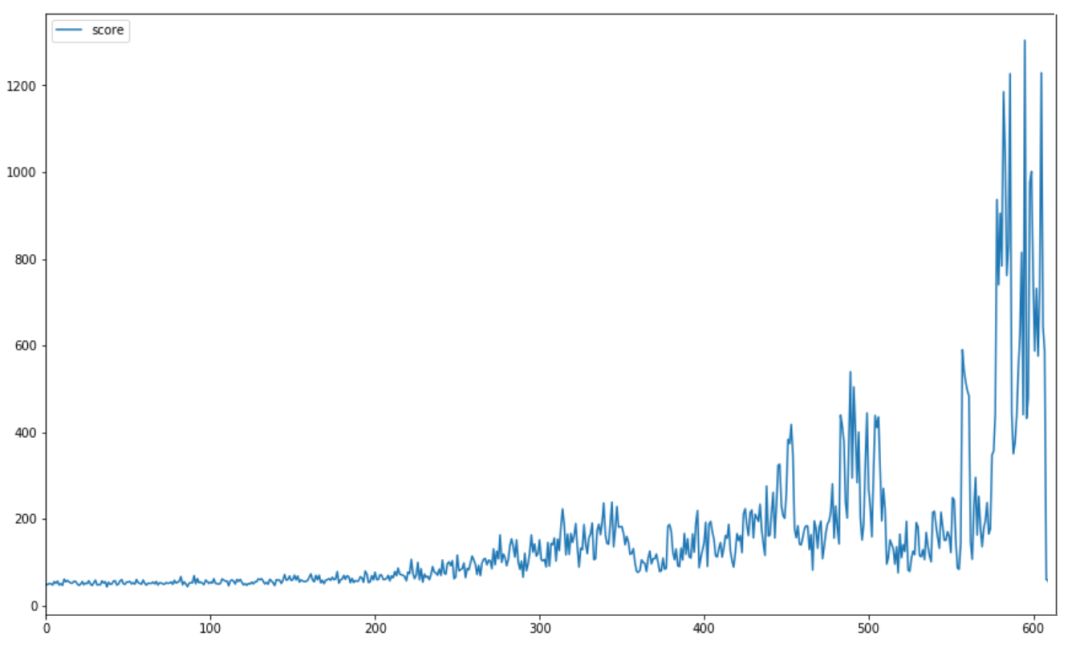
最高分数记录是 4000 +,远远超过了之前模型的的 250 分(也远远超过了大多数人所能做到的!) 。下图显示了训练期间比赛最高得分的进度。
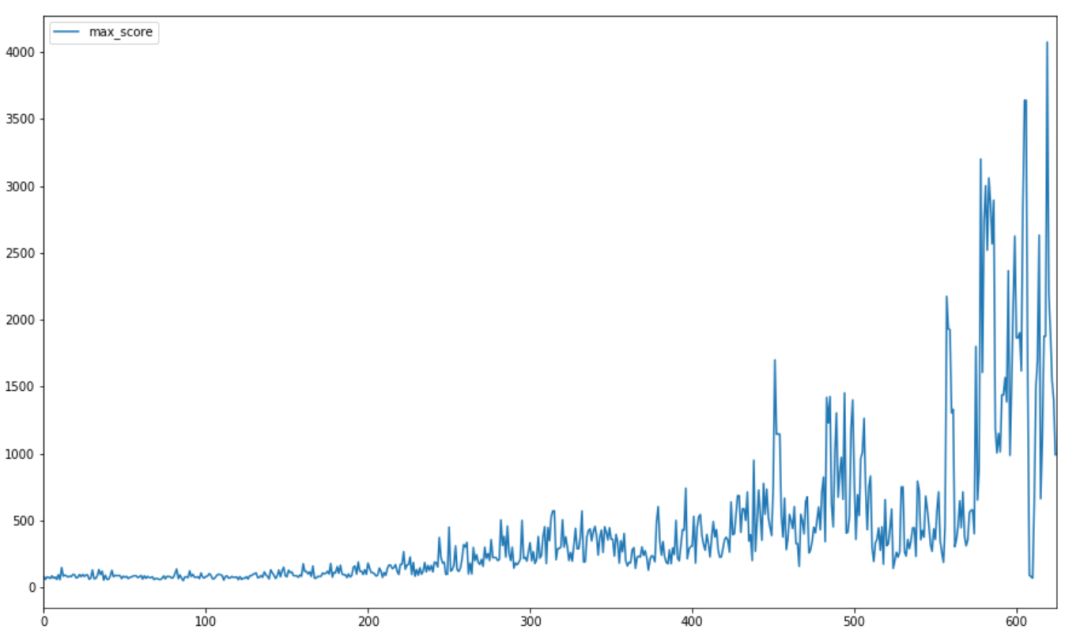
Dino 的速度与分数成正比,这使得在更高的速度下检测和决定一个动作更加困难。因此,整个游戏都是以恒定速度训练的。
-
人工智能
+关注
关注
1776文章
43845浏览量
230596 -
强化学习
+关注
关注
4文章
259浏览量
11114
原文标题:东北大学研究生:用强化学习玩Chrome里的恐龙小游戏
文章出处:【微信号:AI_Thinker,微信公众号:人工智能头条】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
什么是深度强化学习?深度强化学习算法应用分析

深度强化学习实战
将深度学习和强化学习相结合的深度强化学习DRL
萨顿科普了强化学习、深度强化学习,并谈到了这项技术的潜力和发展方向
什么是强化学习?纯强化学习有意义吗?强化学习有什么的致命缺陷?

83篇文献、万字总结强化学习之路
基于深度强化学习仿真集成的压边力控制模型
《自动化学报》—多Agent深度强化学习综述

强化学习的基础知识和6种基本算法解释
模拟矩阵在深度强化学习智能控制系统中的应用






 工商网监
工商网监
评论