 【AI简报20230616】英伟达推出Instinct MI300、OpenAI凌晨再给ChatGPT、GPT-4加码!
【AI简报20230616】英伟达推出Instinct MI300、OpenAI凌晨再给ChatGPT、GPT-4加码!
AI 简报 20230616 期
1. AMD硬刚英伟达,推出Instinct MI300,单芯片可运行800亿参数
原文:https://mp.weixin.qq.com/s/NeSIBtjZ71evn09NPEAc2Q美国时间本周二,AMD举行了重磅发布会,推出了一款全新的人工智能GPU Instinct MI300,并表示这款处理器将于今年晚些时候开始向部分客户发货。自英伟达发布了AI芯片后,便彻底带动了市场的投资热情,也推动英伟达登上万亿美元市值的高峰。此次AMD发布重磅AI芯片,有望对英伟达当前的市场地位形成一定冲击。AMD推出高性能AI芯片在这次AMD的新品发布会中,核心产品无疑是用于训练大模型的GPU Instinct MI300。早在今年初,AMD便已经宣布了新一代Instinct MI300,是全球首款同时集成CPU、GPU的数据中心APU。如今,这款芯片的名字变成了Instinct MI300A,而纯GPU产品则命名为Instinct MI300X。据AMD的CEO苏姿丰透露,MI300A是全球首个为AI和HPC(高性能计算)打造的APU加速卡,拥有13个小芯片,总共包含1460亿个晶体管,24个Zen 4 CPU核心,1个CDNA 3图形引擎和128GB HBM3内存。相比前代MI250,MI300的性能提高八倍,效率提高五倍。AMD在发布会稍早介绍,新的Zen 4c内核比标准的Zen 4内核密度更高,比标准Zen 4的内核小35%,同时保持100%的软件兼容性。而GPU MI300X更是本次发布会的重点,这款芯片是AMD针对大语言模型优化的版本,该产品的晶体管数量达到1530亿个,内存达到了192GB,内存带宽为5.2TB/s,Infinity Fabric带宽为896GB/s。对比英伟达的H100,MI300X提供的HBM(高带宽内存)密度约为H100的2.4倍,HBM带宽是1.6倍。这意味着AMD的这款产品可以运行比英伟达H100更大的模型,在现场AMD演示了MI300X运行400亿参数的Falcon模型,而OpenAI的GPT-3模型有1750亿个参数。苏姿丰还用Hugging Face基于MI300X的大模型写了一首关于活动举办地旧金山的诗。这也是全球首次在单个GPU上运行这么大的模型,据AMD介绍,单个MI300X可以运行一个参数多达800亿的模型。而在未来随着AI模型越来越大,意味着需要更多GPU来运行最新的大模型,而AMD芯片上内存的增加,意味着开发人员不需要那么多GPU,可以为用户节省大量成本。苏姿丰表示,MI300X将于今年第三季度向一些客户提供样品,并于第四季度量产。同时AMD还发布了AMD Instinct Platform,集合了8个MI300X,可提供总计1.5TB的HBM3内存。对标英伟达的CUDA,AMD也介绍了自身的芯片软件ROCm,AMD总裁Victor Peng称,在构建强大的软件堆栈方面,AMD取得了真正的巨大进步,ROCm软件栈可与模型、库、框架和工具的开放生态系统配合使用。之所以将重心放在AI芯片,也是因为AMD非常看好未来的AI市场。苏姿丰认为,数据中心人工智能加速器的潜在市场总额将从今年的300亿美元增长到2027年的1500亿美元以上。硬刚英伟达,但尚未透露大客户从AMD所介绍的产品性能来看,将成为当下AI市场的有力竞争者,尤其在ChatGPT等生成式AI的带动下,市场对高性能GPU需求旺盛。不过当前市场中,英伟达处于绝对优势,占据80%的市场。而AMD并没有公布这款GPU的具体价格,但是对比英伟达H100价格大多在3万美元以上,如果MI300X价格能够更加实惠,将显著的对英伟达产品造成冲击,并有助于降低生成式AI的研发成本。有意思的是,在如此强劲的性能面前,市场却似乎并不买单。截至当日收盘,AMD股价反而下降了3.61%,市值来到2000亿元关口。而英伟达股价则拉升了3.9%,总市值达到1.01万亿美元,是AMD的五倍。此次AMD并未透露哪些公司会采用MI300X或简配版MI300A,而在此前的发布会中,AMD都会披露新产品的大客户。这可能让市场认为,目前并没有大客户为这款芯片买单。另一方面,AMD并没有透露新款AI芯片的具体售价,但想要有显著的成本优势可能不太现实,因为高密度的HBM价格昂贵。即便MI300X的内存达到了192GB,但这也不是显著优势,因为英伟达也拥有相同内存规格的产品。更重要的原因在于,MI300并不具备H100所拥有的Transformer Engine。Transformer Engine能够用于加速Transformer模型,以在AI的训练和推理中以较低的内存利用率提供更好的性能。有分析师认为,如果训练一个新的模型,需要投入数千个GPU,并耗费一年的时间,那么几乎不会有人会浪费2-3年或者投入3倍数量的GPU。而Transformer Engine能够让大模型实现三倍的性能表达。尽管市场中认为,AMD的MI300芯片应该是除了谷歌的TPU之外,能与英伟达在AI训练端上匹敌的产品。成为当前大企业在训练AI大模型时,除了英伟达之外的另一个重要选择。但想要在短时间内挑战英伟达,显然还是比较困难的。就如AMD总裁VictorPeng说的那样,“尽管这是一个过程,但我们在构建强大的软件堆栈方面取得了很大进展,该软件堆栈与开放的模型、库、框架和工具生态系统兼容。”无论如何需要市场中有大客户切实的使用AMD新款芯片。小结AMD此次重磅发布的MI300系列芯片,无疑为AI市场注入了一剂强心针,不仅预示着AMD在持续看好未来的AI市场,也将表明AMD将在这一市场中与英伟达正面竞争。至少对于相关企业及用户而言,有更多的选择是一件好事。
2. 价格最高降75%、API函数调用上线、上下文长度提高4倍,OpenAI凌晨再给ChatGPT、GPT-4加码!
原文:https://mp.weixin.qq.com/s/GcsAk_qqqWfwck4KSdvJew就在今天凌晨,OpenAI 马不停蹄地又双叒叕更新啦!这一次,不仅重磅升级了 ChatGPT 背后的 GPT-3.5-turbo 模型、以及最先进的 GPT-4 文本生成模型,而且大幅降低了价格,另外还为 gpt-3.5-turbo 提供 16000 个 Token 的语境窗口(Context Window)上下文选项。更新速览详细来看,在今天的更新中,OpenAI 主要聚焦在下面几个维度:
- 全新的 16k 上下文 GPT-3.5-Turbo 模型版本(今天向所有人提供)
- 升级版的 GPT-4 和 GPT-3.5-Turbo 模型
- Chat Completions API 中的新函数调用功能
- 最先进的 V2 嵌入模型降价 75%
- gpt-3.5-turbo 的输入 Token 成本降低 25%
- 宣布 gpt-3.5-turbo-0301 和 gpt-4-0314 模型的淘汰时间表
- GPT-4 的 API 权限将开放给更多的人
 由于它提供了 4 倍于 gpt-3.5-turbo 的上下文长度,这意味着 gpt-3.5-turbo-16k 模型现在可以在一次请求中支持 20 页的文本。这对于需要模型处理和生成较大块文本响应的开发者来说是一个相当大的提升。不过,想要广泛使用还需要再等一等。
由于它提供了 4 倍于 gpt-3.5-turbo 的上下文长度,这意味着 gpt-3.5-turbo-16k 模型现在可以在一次请求中支持 20 页的文本。这对于需要模型处理和生成较大块文本响应的开发者来说是一个相当大的提升。不过,想要广泛使用还需要再等一等。 再者,gpt-3.5-turbo-0613 版本与 GPT-4 一样有着函数调用功能,以及通过系统消息提供的更可靠的可引导性,这两个特性使开发者能够更有效地引导模型的响应。函数调用支持新版 GPT-4 和 GPT-3.5要论最最最为重磅的更新,便是开发者现在可以向 gpt-4-0613 和 gpt-3.5-turbo-0613 描述函数,并让模型智能地选择输出一个包含参数的 JSON 对象来调用这些函数。这是一种全新的方式,开发者可以更可靠地将 GPT 的能力与外部工具和 API 连接起来。简单来看,OpenAI 联合创始人Greg Brockman 解释道,这是插件的底层机制,允许开发者与自己的工具集成起来:那该具体怎么用?OpenAI 举了三个例子,其表示,这些模型已经过微调,既可以检测到何时需要调用一个函数(取决于用户的输入),又可以用符合函数签名的 JSON 来响应。函数调用允许开发人员更可靠地从模型中获得结构化的数据。例如,开发人员可以:
再者,gpt-3.5-turbo-0613 版本与 GPT-4 一样有着函数调用功能,以及通过系统消息提供的更可靠的可引导性,这两个特性使开发者能够更有效地引导模型的响应。函数调用支持新版 GPT-4 和 GPT-3.5要论最最最为重磅的更新,便是开发者现在可以向 gpt-4-0613 和 gpt-3.5-turbo-0613 描述函数,并让模型智能地选择输出一个包含参数的 JSON 对象来调用这些函数。这是一种全新的方式,开发者可以更可靠地将 GPT 的能力与外部工具和 API 连接起来。简单来看,OpenAI 联合创始人Greg Brockman 解释道,这是插件的底层机制,允许开发者与自己的工具集成起来:那该具体怎么用?OpenAI 举了三个例子,其表示,这些模型已经过微调,既可以检测到何时需要调用一个函数(取决于用户的输入),又可以用符合函数签名的 JSON 来响应。函数调用允许开发人员更可靠地从模型中获得结构化的数据。例如,开发人员可以:- 创建聊天机器人,通过调用外部工具(例如,像 ChatGPT 插件)来回答问题
- 将自然语言转换为 API 调用或数据库查询
- 从文本中提取结构化数据
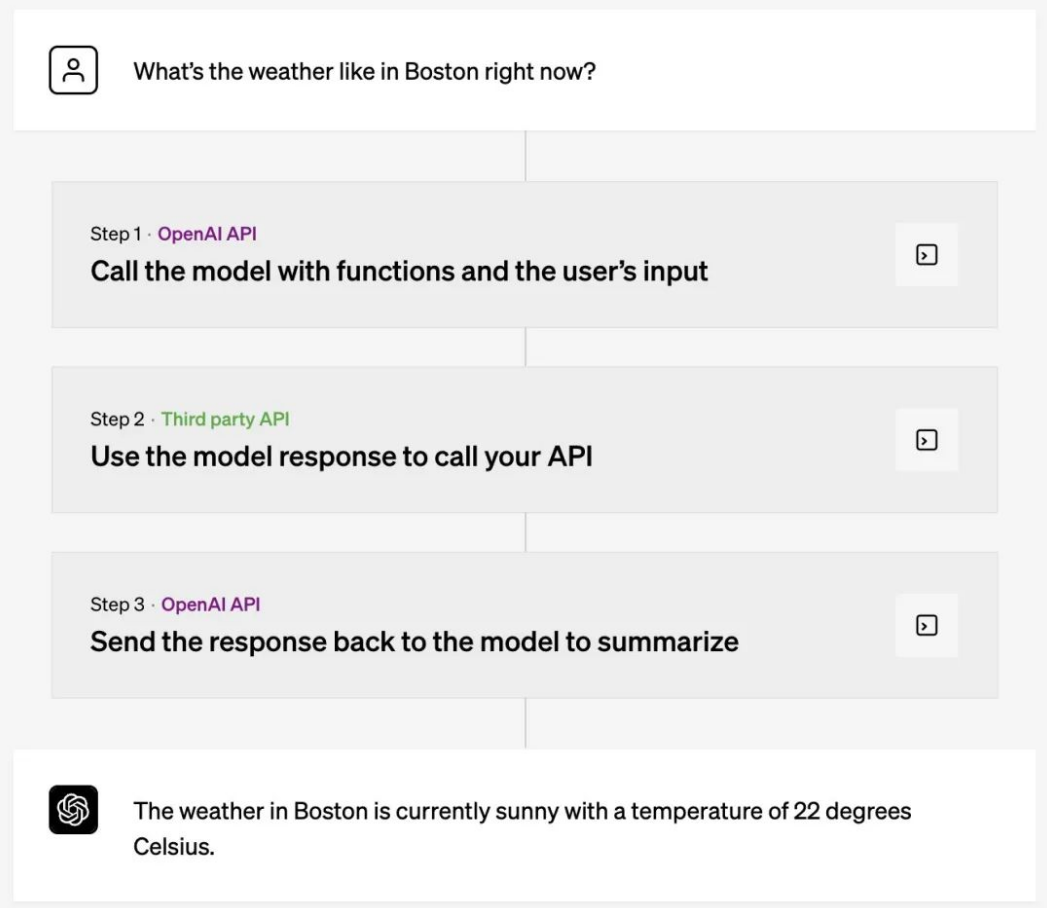 如果,现在你有 GPT-4 访问权限,那么这些模型可以用函数调用功能。
如果,现在你有 GPT-4 访问权限,那么这些模型可以用函数调用功能。
 旧模型即将废弃今天,OpenAI 将开始对 3 月份宣布的 gpt-4 和 gpt-3.5-turbo 的初始版本进行升级和废弃处理。使用稳定模型名称(gpt-3.5-turbo、gpt-4 和 gpt-4-32k)的应用程序将在 6 月 27 日自动升级到上面列出的新模型。为了比较不同版本的模型性能,OpenAI 还提供开源的 Evals 库(https://github.com/openai/evals)支持公共和私人评估 LLM,帮助开发者评测模型的变化将如何影响你的用例。当然,对于需要更多时间过渡的开发者,OpenAI 也表示,可以继续使用旧的模型。这些旧型号将在 9 月 13 日之后,彻底弃用。加量不加价,即日起生效除了以上功能更新之外,OpenAI 宣布下调价格,即日起生效。首先,对于 OpenAI 最受欢迎的嵌入模型——text-embedding-ada-002,OpenAI 将成本降低 75%,至每 1K Token 是 0.0001 美元。其次,对于最受欢迎的聊天模型——GPT-3.5 Turbo,OpenAI 将输入 Token 的成本直降 25%,现在每 1K 输入 Token 只需 0.0015 美元,每 1K 输出 token 只需 0.002 美元,这相当于 1 美元大约有 700 页的文本。再者,最新推出的 gpt-3.5-turbo-16k 的价格是每 1K 输入 token 是 0.003 美元,每 1K 输出 Token 为 0.004 美元。OpenAI 表示,降低成本是通过提高其系统的效率来实现的。毫无疑问,这是初创公司关注的关键领域,因为它在研发和基础设施上花费了数亿美元。
旧模型即将废弃今天,OpenAI 将开始对 3 月份宣布的 gpt-4 和 gpt-3.5-turbo 的初始版本进行升级和废弃处理。使用稳定模型名称(gpt-3.5-turbo、gpt-4 和 gpt-4-32k)的应用程序将在 6 月 27 日自动升级到上面列出的新模型。为了比较不同版本的模型性能,OpenAI 还提供开源的 Evals 库(https://github.com/openai/evals)支持公共和私人评估 LLM,帮助开发者评测模型的变化将如何影响你的用例。当然,对于需要更多时间过渡的开发者,OpenAI 也表示,可以继续使用旧的模型。这些旧型号将在 9 月 13 日之后,彻底弃用。加量不加价,即日起生效除了以上功能更新之外,OpenAI 宣布下调价格,即日起生效。首先,对于 OpenAI 最受欢迎的嵌入模型——text-embedding-ada-002,OpenAI 将成本降低 75%,至每 1K Token 是 0.0001 美元。其次,对于最受欢迎的聊天模型——GPT-3.5 Turbo,OpenAI 将输入 Token 的成本直降 25%,现在每 1K 输入 Token 只需 0.0015 美元,每 1K 输出 token 只需 0.002 美元,这相当于 1 美元大约有 700 页的文本。再者,最新推出的 gpt-3.5-turbo-16k 的价格是每 1K 输入 token 是 0.003 美元,每 1K 输出 Token 为 0.004 美元。OpenAI 表示,降低成本是通过提高其系统的效率来实现的。毫无疑问,这是初创公司关注的关键领域,因为它在研发和基础设施上花费了数亿美元。3. Altman、Hinton 中国首秀:GPT 终将过时,AI 是当今世界最迫切的问题!
原文:https://mp.weixin.qq.com/s/TsjS-2b-UEE7zsWLA2f7AAOpenAI、DeepMind 和 Stability AI 的科学家科普 AI 治理,Google、Meta 和微软的领航人物共论开源未来,图灵奖得主与斯坦福、UC Berkeley、MIT 的教授展开学术辩论——这描述的并不是远在大洋彼岸的 NeurIPS 或 ACL 会议,而是由中国智源研究院主办的年度盛会:北京智源大会。今年的北京智源大会于 6 月 9-10 日召开,20 场论坛、100 场报告、顶尖的专家、顶尖的观众,汇聚了 AI 领域纯粹、专业的前沿思想。OpenAI 创始人 Sam Altman 以及“深度学习三巨头”中的两位 Yann LeCun 与 Geoffrey Hinton 现身于分论坛视频连线的大荧幕上,Max Tegmark 与 Stuart Russell 等来自顶尖学府的教授亲赴现场。CSDN 在现场参加了这场为时两天的 AI 盛会。科技大咖智聚京城,共论当前 AI 领域最前沿的争议焦点:
- 对 AI 保持乐观主义的 Yann LeCun,认为 AI 还远远未发展到还需要操心的程度。GPT 终将过时,未来的 AI 会面临三大挑战,解决后将能训练出「世界模型」(World Model)。
- 曾用一份“暂停 6 个月 AI 研究”的公开信震惊业界的 Max Tegmark 教授则表示,罔顾 AI 的最坏结果将会是人类灭绝。对齐问题将是学术界接下来的一大难题:如此庞大而复杂的智能模型,要怎样才能保持和人类同一水准的价值观和道德观?
- 一亮相便轰动北京会场的 Sam Altman,则发表了一份真诚的呼吁:国际科技界需要团结一心,携手促进 AGI 安全的透明化,为未来十年内诞生的“超级智能”做好准备。
- 学术界还有一部分人,对这些围绕 GPT 的话题并不买账,而是关心更深远的 AI 话题。Stuart Russell 教授直言,目前的大语言模型缺乏「内部目标」,而人类也不理解它们的“黑匣子”里都发生了什么。
- Geoffrey Hinton 则带来了一场精彩绝伦的谢幕演讲:“超级智能”已成雏形,但人类尚未给它建立道德准则——现在为时不晚。
- AGI 可能很快会出现,超级智能在未来十年内可能会成为现实。
- 目前已经取得了一些全球合作的突破,但全球合作仍然面临困难。
- AI 安全性的研究是一个复杂的问题,需要考虑多个因素,并需要大量的投入,希望中国和美国的研究人员能做出贡献。
- 当被问及是否打算重新开放 GPT 的源代码时,Altman 表示已经作出了一定的努力,未来将会有许多开源大模型诞生。但开源模型在 AI 发展中起了重要作用,当模型变得更大时,就更需要谨慎安全问题。
- 杨立昆即将参加一个辩论,与 Joshua Bengio、Max Tegmark 和 Melanie Mitchell 讨论人工智能是否会威胁人类生存。
- Max Tegmark 和 Joshua Bengio 认为强大的人工智能系统可能对人类构成风险,而杨立昆和 Melanie Mitchell 则持相反观点。
- 杨立昆指出,他并不是想说“AI 完全不存在风险”,而是认为“目前的 AI 风险可以被谨慎的工程设计减轻或抑制”。
- 杨立昆表示自己不能预测超级智能在未来能造成多大的影响,因为超级智能尚未问世。他举了一个例子:如果你去问一个 1930 年的航空工程师,“我该如何确保涡轮喷气发动机的安全可靠性?”那他肯定答不出来,因为涡轮喷气发动机在 1930 年还没被发明出来。
4. CVPR23|清华大学提出LiVT:用视觉Transformer学习长尾数据,解决不平衡标注数据不在话下
原文:https://mp.weixin.qq.com/s/1MfOWcE9x7Vk7tP2n1V4bg背景在机器学习领域中,学习不平衡的标注数据一直是一个常见而具有挑战性的任务。近年来,视觉 Transformer 作为一种强大的模型,在多个视觉任务上展现出令人满意的效果。然而,视觉 Transformer 处理长尾分布数据的能力和特性,还有待进一步挖掘。目前,已有的长尾识别模型很少直接利用长尾数据对视觉 Transformer(ViT)进行训练。基于现成的预训练权重进行研究可能会导致不公平的比较结果,因此有必要对视觉 Transformer 在长尾数据下的表现进行系统性的分析和总结。

论文链接:https://arxiv.org/abs/2212.02015代码链接:https://github.com/XuZhengzhuo/LiVT本文旨在填补这一研究空白,详细探讨了视觉 Transformer 在处理长尾数据时的优势和不足之处。本文将重点关注如何有效利用长尾数据来提升视觉 Transformer 的性能,并探索解决数据不平衡问题的新方法。通过本文的研究和总结,研究团队有望为进一步改进视觉 Transformer 模型在长尾数据任务中的表现提供有益的指导和启示。这将为解决现实世界中存在的数据不平衡问题提供新的思路和解决方案。文章通过一系列实验发现,在有监督范式下,视觉 Transformer 在处理不平衡数据时会出现严重的性能衰退,而使用平衡分布的标注数据训练出的视觉 Transformer 呈现出明显的性能优势。相比于卷积网络,这一特点在视觉 Transformer 上体现的更为明显。另一方面,无监督的预训练方法无需标签分布,因此在相同的训练数据量下,视觉 Transformer 可以展现出类似的特征提取和重建能力。基于以上观察和发现,研究提出了一种新的学习不平衡数据的范式,旨在让视觉 Transformer 模型更好地适应长尾数据。通过这种范式的引入,研究团队希望能够充分利用长尾数据的信息,提高视觉 Transformer 模型在处理不平衡标注数据时的性能和泛化能力。文章贡献本文是第一个系统性的研究用长尾数据训练视觉 Transformer 的工作,在此过程中,做出了以下主要贡献:首先,本文深入分析了传统有监督训练方式对视觉 Transformer 学习不均衡数据的限制因素,并基于此提出了双阶段训练流程,将视觉 Transformer 模型内在的归纳偏置和标签分布的统计偏置分阶段学习,以降低学习长尾数据的难度。其中第一阶段采用了流行的掩码重建预训练,第二阶段采用了平衡的损失进行微调监督。
 其次,本文提出了平衡的二进制交叉熵损失函数,并给出了严格的理论推导。平衡的二进制交叉熵损失的形式如下:
其次,本文提出了平衡的二进制交叉熵损失函数,并给出了严格的理论推导。平衡的二进制交叉熵损失的形式如下: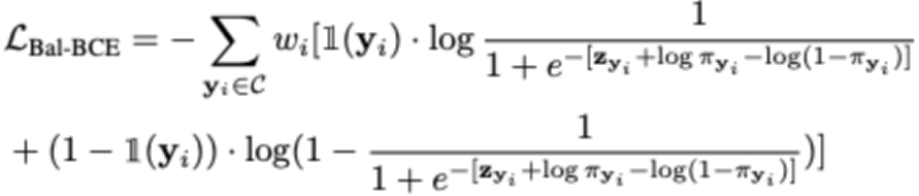 与之前的平衡交叉熵损失相比,本文的损失函数在视觉 Transformer 模型上展现出更好的性能,并且具有更快的收敛速度。研究中的理论推导为损失函数的合理性提供了严密的解释,进一步加强了我们方法的可靠性和有效性。
与之前的平衡交叉熵损失相比,本文的损失函数在视觉 Transformer 模型上展现出更好的性能,并且具有更快的收敛速度。研究中的理论推导为损失函数的合理性提供了严密的解释,进一步加强了我们方法的可靠性和有效性。 基于以上贡献,文章提出了一个全新的学习范式 LiVT,充分发挥视觉 Transformer 模型在长尾数据上的学习能力,显著提升模型在多个数据集上的性能。该方案在多个数据集上取得了远好于视觉 Transformer 基线的性能表现。
基于以上贡献,文章提出了一个全新的学习范式 LiVT,充分发挥视觉 Transformer 模型在长尾数据上的学习能力,显著提升模型在多个数据集上的性能。该方案在多个数据集上取得了远好于视觉 Transformer 基线的性能表现。 不同参数量下在 ImageNet-LT 上的准确性。
不同参数量下在 ImageNet-LT 上的准确性。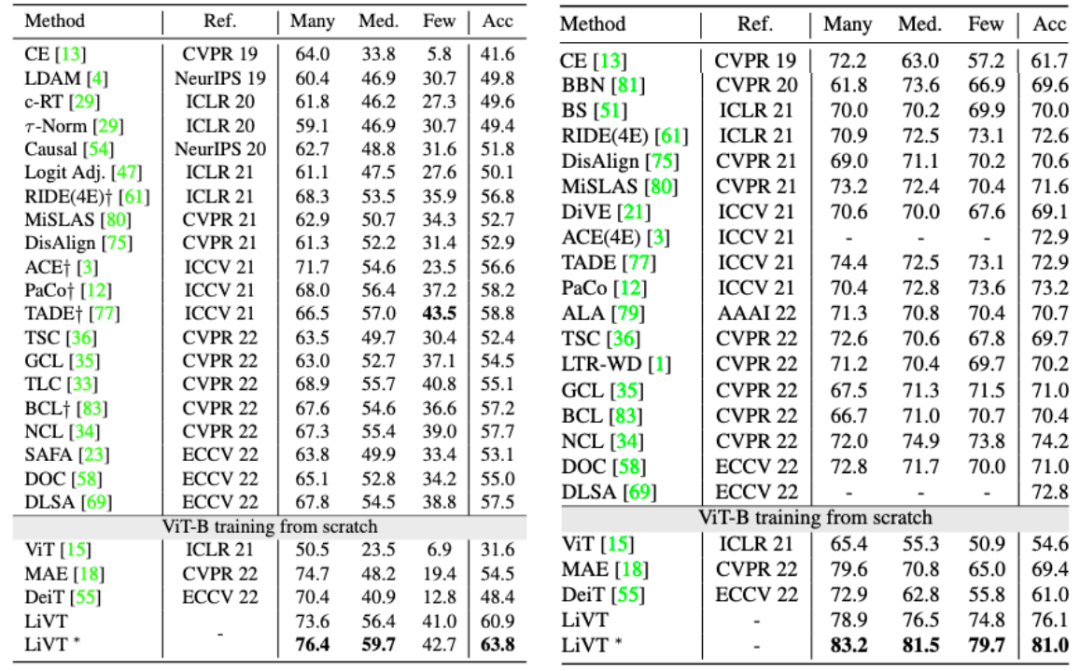 同时,本文还验证了在相同的训练数据规模的情况下,使用ImageNet的长尾分布子集(LT)和平衡分布子集(BAL)训练的 ViT-B 模型展现出相近的重建能力。如 LT-Large-1600 列所示,在 ImageNet-LT 数据集中,可以通过更大的模型和 MGP epoch 获得更好的重建结果。总结本文提供了一种新的基于视觉 Transformer 处理不平衡数据的方法 LiVT。LiVT 利用掩码建模和平衡微调两个阶段的训练策略,使得视觉 Transformer 能够更好地适应长尾数据分布并学习到更通用的特征表示。该方法不仅在实验中取得了显著的性能提升,而且无需额外的数据,具有实际应用的可行性。
同时,本文还验证了在相同的训练数据规模的情况下,使用ImageNet的长尾分布子集(LT)和平衡分布子集(BAL)训练的 ViT-B 模型展现出相近的重建能力。如 LT-Large-1600 列所示,在 ImageNet-LT 数据集中,可以通过更大的模型和 MGP epoch 获得更好的重建结果。总结本文提供了一种新的基于视觉 Transformer 处理不平衡数据的方法 LiVT。LiVT 利用掩码建模和平衡微调两个阶段的训练策略,使得视觉 Transformer 能够更好地适应长尾数据分布并学习到更通用的特征表示。该方法不仅在实验中取得了显著的性能提升,而且无需额外的数据,具有实际应用的可行性。5. LeCun世界模型首项研究来了:自监督视觉,像人一样学习和推理,已开源
原文:https://mp.weixin.qq.com/s/A_MmOIOQ08SzWntpd6VYGg去年初,Meta 首席 AI 科学家 Yann LeCun 针对「如何才能打造出接近人类水平的 AI」提出了全新的思路。他勾勒出了构建人类水平 AI 的另一种愿景,指出学习世界模型(即世界如何运作的内部模型)的能力或许是关键。这种学到世界运作方式内部模型的机器可以更快地学习、规划完成复杂的任务,并轻松适应不熟悉的情况。LeCun 认为,构造自主 AI 需要预测世界模型,而世界模型必须能够执行多模态预测,对应的解决方案是一种叫做分层 JEPA(联合嵌入预测架构)的架构。该架构可以通过堆叠的方式进行更抽象、更长期的预测。6 月 9 日,在 2023 北京智源大会开幕式的 keynote 演讲中,LeCun 又再次讲解了世界模型的概念,他认为基于自监督的语言模型无法获得关于真实世界的知识,这些模型在本质上是不可控的。今日,Meta 推出了首个基于 LeCun 世界模型概念的 AI 模型。该模型名为图像联合嵌入预测架构(Image Joint Embedding Predictive Architecture, I-JEPA),它通过创建外部世界的内部模型来学习, 比较图像的抽象表示(而不是比较像素本身)。I-JEPA 在多项计算机视觉任务上取得非常不错的效果,并且计算效率远高于其他广泛使用的计算机视觉模型。此外 I-JEPA 学得的表示也可以用于很多不同的应用,无需进行大量微调。
 举个例子,Meta 在 72 小时内使用 16 块 A100 GPU 训练了一个 632M 参数的视觉 transformer 模型,还在 ImageNet 上实现了 low-shot 分类的 SOTA 性能,其中每个类只有 12 个标签样本。其他方法通常需要 2 到 10 倍的 GPU 小时数,并在使用相同数据量训练时误差率更高。相关的论文《Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture》已被 CVPR 2023 接收。当然,所有的训练代码和模型检查点都将开源。
举个例子,Meta 在 72 小时内使用 16 块 A100 GPU 训练了一个 632M 参数的视觉 transformer 模型,还在 ImageNet 上实现了 low-shot 分类的 SOTA 性能,其中每个类只有 12 个标签样本。其他方法通常需要 2 到 10 倍的 GPU 小时数,并在使用相同数据量训练时误差率更高。相关的论文《Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture》已被 CVPR 2023 接收。当然,所有的训练代码和模型检查点都将开源。
通过自监督学习获取常识型知识I-JEPA 基于一个事实,即人类仅通过被动观察就可以了解关于世界的大量背景知识,这些常识信息被认为是实现智能行为的关键。通常,AI 研究人员会设计学习算法来捕获现实世界的常识,并将其编码为算法可访问的数字表征。为了高效,这些表征需要以自监督的方式来学习,即直接从图像或声音等未标记的数据中学习,而不是从手动标记的数据集中学习。在高层级上,JEPA 的一个输入中某个部分的表征是根据其他部分的表征来预测的。同时,通过在高抽象层次上预测表征而不是直接预测像素值,JEPA 能够直接学习有用的表征,同时避免了生成模型的局限性。相比之下,生成模型会通过删除或扭曲模型输入的部分内容来学习。然而,生成模型的一个显著缺点是模型试图填补每一点缺失的信息,即使现实世界本质上是不可预测的。因此,生成模型过于关注不相关的细节,而不是捕捉高级可预测的概念。
- 论文地址:https://arxiv.org/pdf/2301.08243.pdf
- GitHub 地址:https://t.co/DgS9XiwnMz
 自监督学习的通用架构,其中系统学习捕获其输入之间的关系。迈向能力广泛的 JEPA 的第一步I-JEPA 的核心思路是以更类似于人类理解的抽象表征来预测缺失信息。与在像素 /token 空间中进行预测的生成方法相比,I-JEPA 使用抽象的预测目标,潜在地消除了不必要的像素级细节,从而使模型学习更多语义特征。另一个引导 I-JEPA 产生语义表征的核心设计是多块掩码策略。该研究使用信息丰富的上下文来预测包含语义信息的块,并表明这是非常必要的。
自监督学习的通用架构,其中系统学习捕获其输入之间的关系。迈向能力广泛的 JEPA 的第一步I-JEPA 的核心思路是以更类似于人类理解的抽象表征来预测缺失信息。与在像素 /token 空间中进行预测的生成方法相比,I-JEPA 使用抽象的预测目标,潜在地消除了不必要的像素级细节,从而使模型学习更多语义特征。另一个引导 I-JEPA 产生语义表征的核心设计是多块掩码策略。该研究使用信息丰富的上下文来预测包含语义信息的块,并表明这是非常必要的。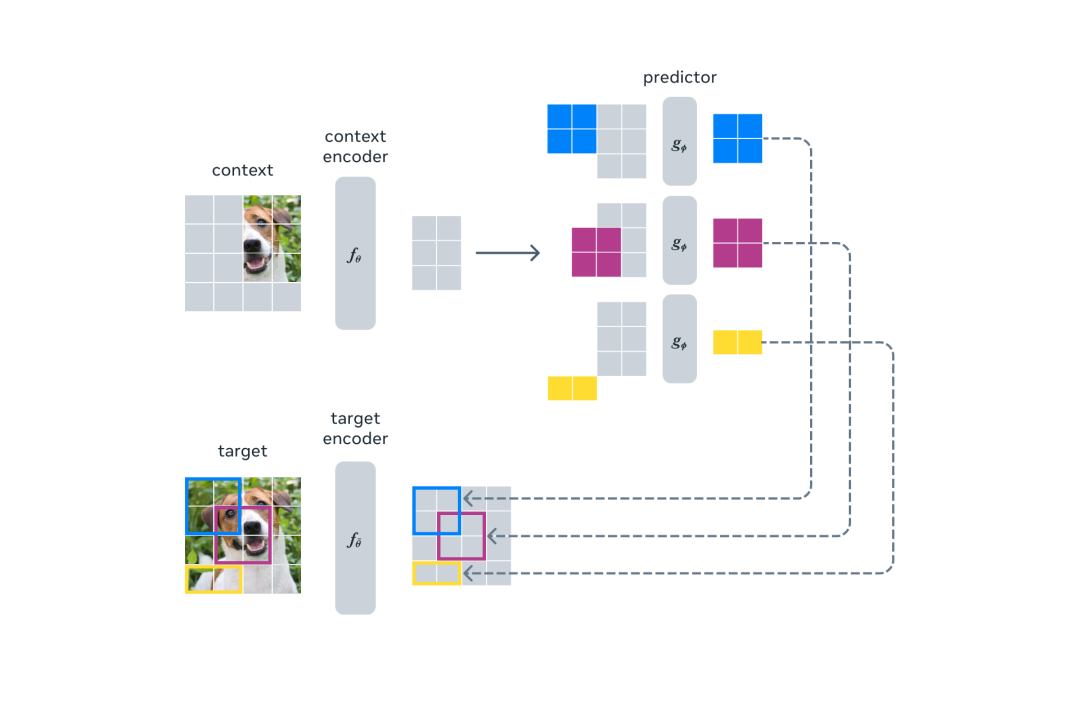 I-JEPA 使用单个上下文块来预测源自同一图像的各种目标块的表征。I-JEPA 中的预测器可以看作是一个原始的(和受限的)世界模型,它能够从部分可观察的上下文中模拟静态图像中的空间不确定性。更重要的是,这个世界模型是语义级的,因为它预测图像中不可见区域的高级信息,而不是像素级细节。预测器如何学习建模世界的语义。对于每张图像,蓝框外的部分被编码并作为上下文提供给预测器。然后预测器输出它期望在蓝框内区域的表示。为了可视化预测,Meta 训练了一个生成模型, 它生成了由预测输出表示的内容草图,并在蓝框内显示样本输出。很明显,预测器识别出了应该填充哪些部分的语义(如狗的头部、鸟的腿、狼的前肢、建筑物的另一侧)。为了理解模型捕获的内容,Meta 训练了一个随机解码器,将 I-JEPA 预测的表示映射回像素空间,这展示出了探针操作后在蓝框中进行预测时的模型输出。这种定性评估表明,I-JEPA 正确捕获了位置不确定性,并生成了具有正确姿态的高级对象部分(如狗的头部、狼的前肢)。简而言之,I-JEPA 能够学习对象部分的高级表示,而不会丢弃它们在图像中的局部位置信息。高效率、强性能I-JEPA 预训练在计算上也很高效,在使用更多计算密集型数据增强来生成多个视图时不会产生任何开销。目标编码器只需要处理图像的一个视图,上下文编码器只需要处理上下文块。实验发现,I-JEPA 在不使用手动视图增强的情况下学习了强大的现成语义表示,具体可见下图。此外 I-JEPA 还在 ImageNet-1K 线性探针和半监督评估上优于像素和 token 重建方法。
I-JEPA 使用单个上下文块来预测源自同一图像的各种目标块的表征。I-JEPA 中的预测器可以看作是一个原始的(和受限的)世界模型,它能够从部分可观察的上下文中模拟静态图像中的空间不确定性。更重要的是,这个世界模型是语义级的,因为它预测图像中不可见区域的高级信息,而不是像素级细节。预测器如何学习建模世界的语义。对于每张图像,蓝框外的部分被编码并作为上下文提供给预测器。然后预测器输出它期望在蓝框内区域的表示。为了可视化预测,Meta 训练了一个生成模型, 它生成了由预测输出表示的内容草图,并在蓝框内显示样本输出。很明显,预测器识别出了应该填充哪些部分的语义(如狗的头部、鸟的腿、狼的前肢、建筑物的另一侧)。为了理解模型捕获的内容,Meta 训练了一个随机解码器,将 I-JEPA 预测的表示映射回像素空间,这展示出了探针操作后在蓝框中进行预测时的模型输出。这种定性评估表明,I-JEPA 正确捕获了位置不确定性,并生成了具有正确姿态的高级对象部分(如狗的头部、狼的前肢)。简而言之,I-JEPA 能够学习对象部分的高级表示,而不会丢弃它们在图像中的局部位置信息。高效率、强性能I-JEPA 预训练在计算上也很高效,在使用更多计算密集型数据增强来生成多个视图时不会产生任何开销。目标编码器只需要处理图像的一个视图,上下文编码器只需要处理上下文块。实验发现,I-JEPA 在不使用手动视图增强的情况下学习了强大的现成语义表示,具体可见下图。此外 I-JEPA 还在 ImageNet-1K 线性探针和半监督评估上优于像素和 token 重建方法。 I-JEPA 还能与以往在语义任务上依赖手动数据增强的方法竞争。相比之下,I-JEPA 在对象计数和深度预测等低级视觉任务上取得了更好的性能。通过使用较小刚性归纳偏置的更简单模型,I-JEPA 适用于更广泛的任务集合。
I-JEPA 还能与以往在语义任务上依赖手动数据增强的方法竞争。相比之下,I-JEPA 在对象计数和深度预测等低级视觉任务上取得了更好的性能。通过使用较小刚性归纳偏置的更简单模型,I-JEPA 适用于更广泛的任务集合。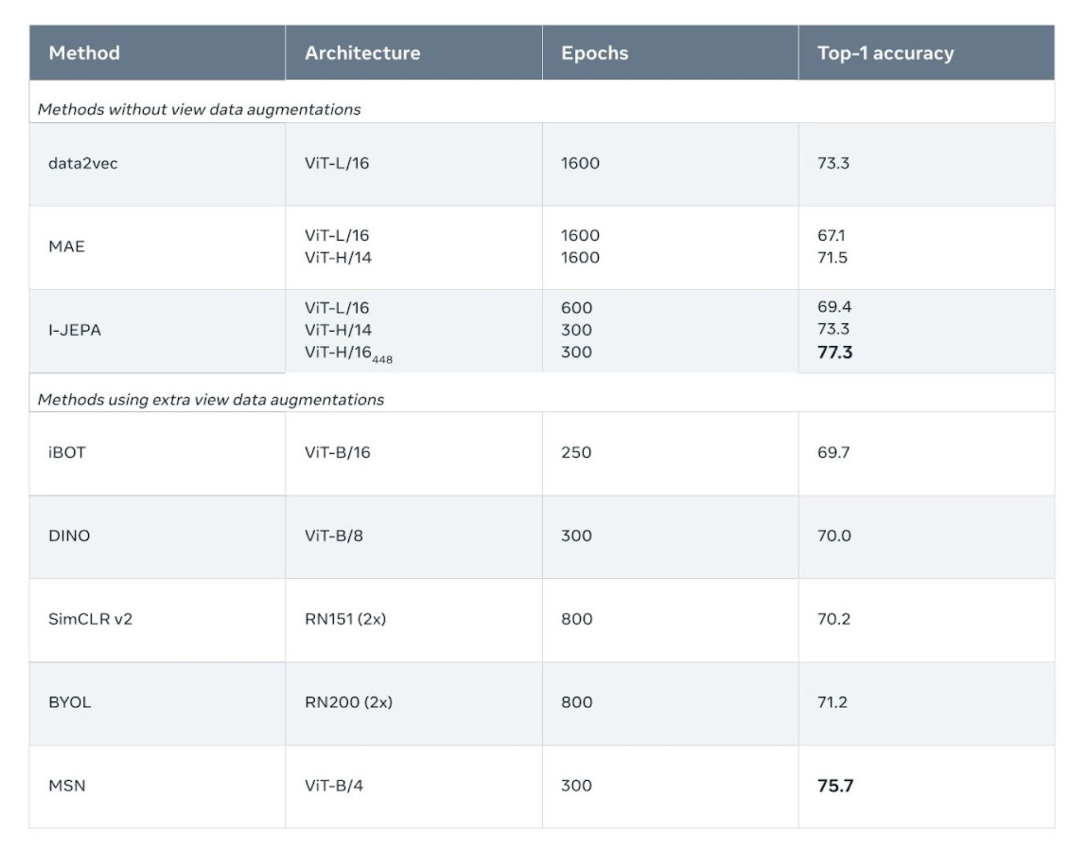 low shot 分类准确性:使用 1% 标签时 ImageNet-1k 上的半监督评估结果(每类只有 12 张标签图像)。AI 智能向人类水平更近了一步I-JEPA 展示了无需通过手动图像变换来编码额外知识时,学习有竞争力的现成图像表示的潜力。继续推进 JEPA 以从更丰富模态中学习更通用世界模型将变得特别有趣,比如人们从一个短上下文中对视频中的将来事件做出长期空间和时间预测,并利用音频或文本 prompt 对这些预测进行调整。Meta 希望将 JEPA 方法扩展到其他领域,比如图像 - 文本配对数据和视频数据。未来,JEPA 模型可以在视频理解等任务中得到应用。这是应用和扩展自监督方法来学习更通用世界模型的重要一步。
low shot 分类准确性:使用 1% 标签时 ImageNet-1k 上的半监督评估结果(每类只有 12 张标签图像)。AI 智能向人类水平更近了一步I-JEPA 展示了无需通过手动图像变换来编码额外知识时,学习有竞争力的现成图像表示的潜力。继续推进 JEPA 以从更丰富模态中学习更通用世界模型将变得特别有趣,比如人们从一个短上下文中对视频中的将来事件做出长期空间和时间预测,并利用音频或文本 prompt 对这些预测进行调整。Meta 希望将 JEPA 方法扩展到其他领域,比如图像 - 文本配对数据和视频数据。未来,JEPA 模型可以在视频理解等任务中得到应用。这是应用和扩展自监督方法来学习更通用世界模型的重要一步。6. 视频版Midjourney免费开放,一句话拍大片!网友:上一次这么激动还是上次了
https://mp.weixin.qq.com/s/Eeuea9l_iQ87eMghCIHpMQ家人们,现在做个影视级视频,也就是一句话的事了!例如只需简单输入“丛林(Jungle)”,大片镜头便可立刻呈现:而且围绕着“丛林”变换几个搭配的词语,比如“河流”、“瀑布”、“黄昏”、“白天”等,这个AI也能秒懂你的意思。还有下面这些自然美景、宇宙奇观、微观细胞等高清视频,统统只需一句话。这就是Stable Diffusion和《瞬息全宇宙》背后技术公司Runway,出品的AI视频编辑工具Gen2。而且就在最近,一个好消息突然袭来——Gen2可以免费试用了!这可把网友们开心坏了,纷纷开始尝鲜了起来。体验Gen2实录如此好玩的技术,我们当然也要亲手体验上一番。例如我们给Gen2投喂了一句中文:
上海外滩夜景,影视风格。
一个航拍视角的视频片段便立即被做了出来。如果想让视频的风格变换一下,也可以上传一张图片,例如我们用的是一张赛博朋克风格的城市照片。
目前Runway官网可免费体验Gen2的功能是文生视频(Text to Video),但Gen1也开放了视频生视频(Video to Video)的功能。例如一个国外小哥可能受《瞬息全宇宙》的启发,凭借Gen1也玩了一把更刺激的穿越。他先是在家录了一段打响指的视频,然后“啪的一下”,瞬间让自己步入欧洲皇室贵族的“片场”:
更多内容请查阅源文档。
7. 分割一切模型(SAM)的全面综述调研
https://mp.weixin.qq.com/s/39imonlyIdSHYW9VnQhOjw人工智能(AI)正在向 AGI 方向发展,这是指人工智能系统能够执行广泛的任务,并可以表现出类似于人类的智能水平,狭义上的 AI 就与之形成了对比,因为专业化的 AI 旨在高效执行特定任务。可见,设计通用的基础模型迫在眉睫。基础模型在广泛的数据上训练,因而能够适应各种下游任务。最近 Meta 提出的分割一切模型(Segment Anything Model,SAM)突破了分割界限,极大地促进了计算机视觉基础模型的发展。SAM 是一个提示型模型,其在 1100 万张图像上训练了超过 10 亿个掩码,实现了强大的零样本泛化。许多研究人员认为「这是 CV 的 GPT-3 时刻,因为 SAM 已经学会了物体是什么的一般概念,甚至是未知的物体、不熟悉的场景(如水下、细胞显微镜)和模糊的情况」,并展示了作为 CV 基本模型的巨大潜力。为了充分了解 SAM,来自香港科技大学(广州)、上海交大等机构的研究者对其进行了深入研究并联合发表论文《 A Comprehensive Survey on Segment Anything Model for Vision and Beyond 》。

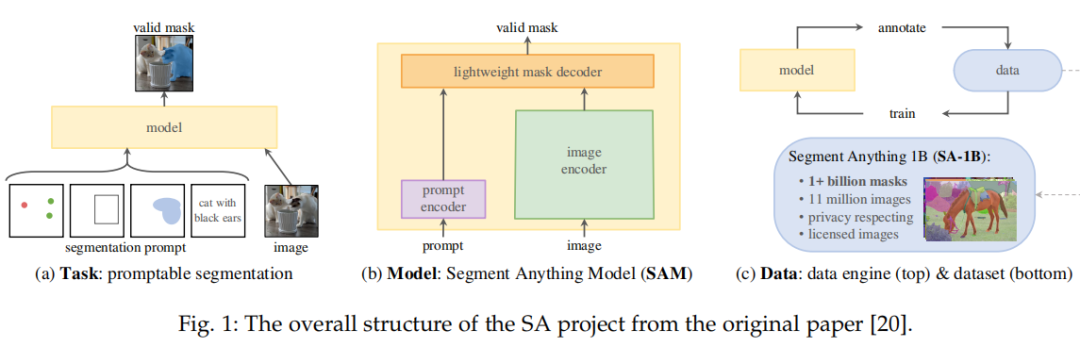
论文链接:https://arxiv.org/abs/2305.08196作为首个全面介绍基于 SAM 基础模型进展的研究,该论文聚焦于 SAM 在各种任务和数据类型上的应用,并讨论了其历史发展、近期进展,以及对广泛应用的深远影响。本文首先介绍了包括 SAM 在内的基础模型的背景和术语,以及对分割任务有重要意义的最新方法;然后,该研究分析并总结了 SAM 在各种图像处理应用中的优势和限制,包括软件场景、真实世界场景和复杂场景,重要的是,该研究得出了一些洞察,以指导未来的研究发展更多用途广泛的基础模型并改进 SAM 的架构;最后该研究还总结了 SAM 在视觉及其他领域的应用。下面我们看看论文具体内容。SAM 模型概览SAM 源自于 2023 年 Meta 的 Segment Anything (SA) 项目。该项目发现在 NLP 和 CV 领域中出现的基础模型表现出较强的性能,研究人员试图建立一个类似的模型来统一整个图像分割任务。然而,在分割领域的可用数据较为缺乏,这与他们的设计目的不同。因此,如图 1 所示,研究者将路径分为任务、模型和数据三个步骤。
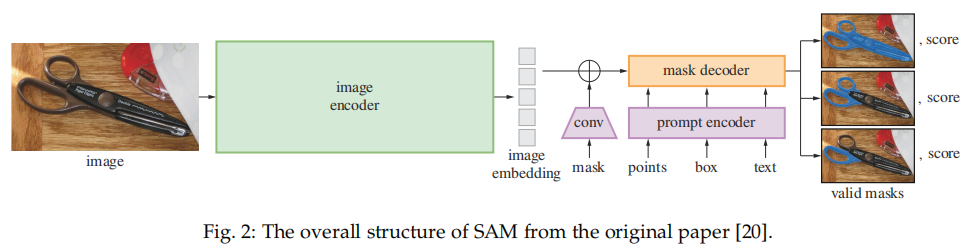
 SAM 架构如下所示,主要包含三个部分:图像编码器;提示编码器;以及掩码解码器。
SAM 架构如下所示,主要包含三个部分:图像编码器;提示编码器;以及掩码解码器。
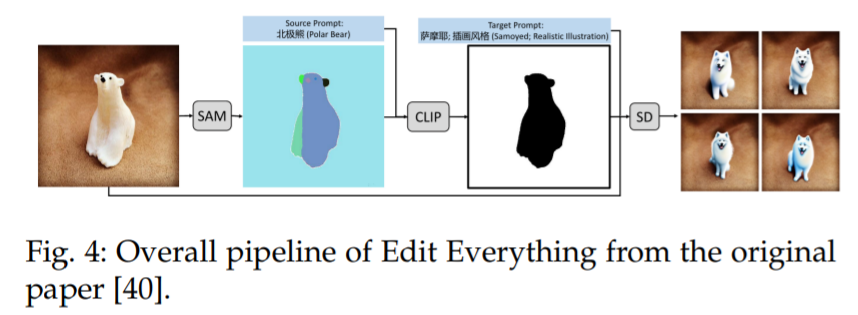
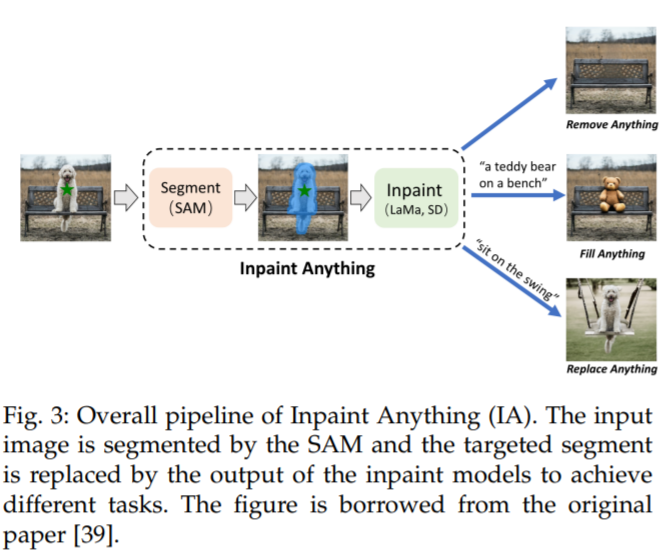 一个类似的想法也可以在 Edit Everything [40] 中看到,如图 4 所示,该方法允许用户使用简单的文本指令编辑图像。
一个类似的想法也可以在 Edit Everything [40] 中看到,如图 4 所示,该方法允许用户使用简单的文本指令编辑图像。
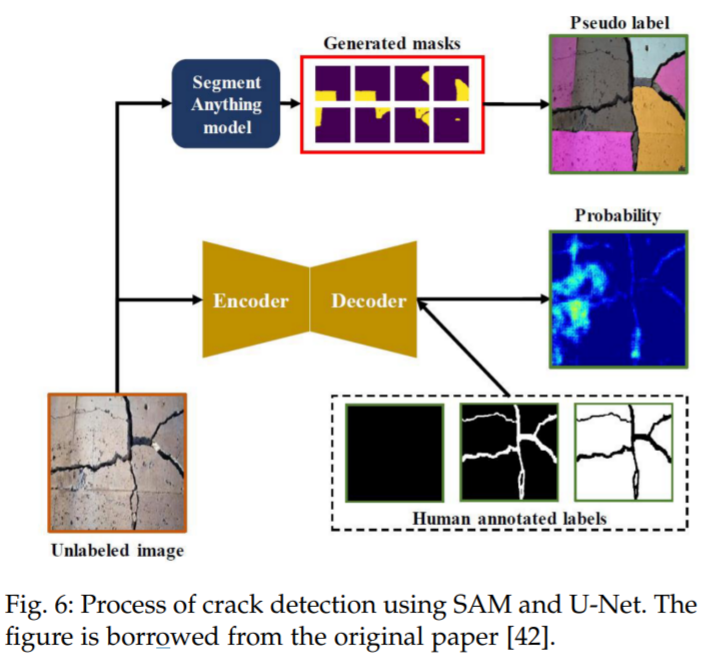 与裂缝检测中的复杂图像案例不同,由于陨石坑的形状主要集中在圆形或椭圆形,所以使用 SAM 作为检测工具来进行陨石坑检测更为合适。陨石坑是行星探索中最重要的形态特征之一,检测和计数它们是行星科学中一个重要但耗时的任务。尽管现有的机器学习和计算机视觉工作成功地解决了陨石坑检测中的一些特定问题,但它们依赖于特定类型的数据,因此在不同的数据源中无法很好地工作。在 [110] 中,研究者提出了一种使用 SAM 对不熟悉对象进行零样本泛化的通用陨石坑检测方案。这个流程使用 SAM 来分割输入图像,对数据类型和分辨率没有限制。然后,它使用圆形 - 椭圆形指数来过滤不是圆形 - 椭圆形的分割掩码。最后,使用一个后处理过滤器来去除重复的、人为的和假阳性的部分。这个流程在当前领域显示出其作为通用工具的巨大潜力,并且作者还讨论了只能识别特定形状的缺点。复杂场景除了上述的常规场景,SAM 是否能解决复杂场景(如低对比度场景)中的分割问题,也是一个有意义的问题,可以扩大其应用范围。为了探索 SAM 在更复杂场景中的泛化能力,Ji 等人 [22] 在三种场景,即伪装动物、工业缺陷和医学病变中,定量地将其与尖端模型进行比较。他们在三个伪装物体分割(COS)数据集上进行实验,即拥有 250 个样本的 CAMO [116],拥有 2026 个样本的 COD10K [117],以及拥有 4121 个样本的 NC4K [118]。并将其与基于 Transformer 的模型 CamoFormer-P/S [119] 和 HitNet [120] 进行比较。结果表明,SAM 在隐蔽场景中的技巧不足,并指出,潜在的解决方案可能依赖于在特定领域的先验知识的支持。在 [29] 中也可以得出同样的结论,作者在上述同样的三个数据集上,将 SAM 与 22 个最先进的方法在伪装物体检测上进行比较。Cao 等人 [115] 提出了一个新的框架,名为 Segment Any Anomaly + (SAA+),用于零样本异常分割,如图 7 所示。该框架利用混合提示规范化来提高现代基础模型的适应性,从而无需领域特定的微调就能进行更精确的异常分割。作者在四个异常分割基准上进行了详细的实验,即 VisA [122],MVTecAD [123],MTD [124] 和 KSDD2 [125],并取得了最先进的性能。
与裂缝检测中的复杂图像案例不同,由于陨石坑的形状主要集中在圆形或椭圆形,所以使用 SAM 作为检测工具来进行陨石坑检测更为合适。陨石坑是行星探索中最重要的形态特征之一,检测和计数它们是行星科学中一个重要但耗时的任务。尽管现有的机器学习和计算机视觉工作成功地解决了陨石坑检测中的一些特定问题,但它们依赖于特定类型的数据,因此在不同的数据源中无法很好地工作。在 [110] 中,研究者提出了一种使用 SAM 对不熟悉对象进行零样本泛化的通用陨石坑检测方案。这个流程使用 SAM 来分割输入图像,对数据类型和分辨率没有限制。然后,它使用圆形 - 椭圆形指数来过滤不是圆形 - 椭圆形的分割掩码。最后,使用一个后处理过滤器来去除重复的、人为的和假阳性的部分。这个流程在当前领域显示出其作为通用工具的巨大潜力,并且作者还讨论了只能识别特定形状的缺点。复杂场景除了上述的常规场景,SAM 是否能解决复杂场景(如低对比度场景)中的分割问题,也是一个有意义的问题,可以扩大其应用范围。为了探索 SAM 在更复杂场景中的泛化能力,Ji 等人 [22] 在三种场景,即伪装动物、工业缺陷和医学病变中,定量地将其与尖端模型进行比较。他们在三个伪装物体分割(COS)数据集上进行实验,即拥有 250 个样本的 CAMO [116],拥有 2026 个样本的 COD10K [117],以及拥有 4121 个样本的 NC4K [118]。并将其与基于 Transformer 的模型 CamoFormer-P/S [119] 和 HitNet [120] 进行比较。结果表明,SAM 在隐蔽场景中的技巧不足,并指出,潜在的解决方案可能依赖于在特定领域的先验知识的支持。在 [29] 中也可以得出同样的结论,作者在上述同样的三个数据集上,将 SAM 与 22 个最先进的方法在伪装物体检测上进行比较。Cao 等人 [115] 提出了一个新的框架,名为 Segment Any Anomaly + (SAA+),用于零样本异常分割,如图 7 所示。该框架利用混合提示规范化来提高现代基础模型的适应性,从而无需领域特定的微调就能进行更精确的异常分割。作者在四个异常分割基准上进行了详细的实验,即 VisA [122],MVTecAD [123],MTD [124] 和 KSDD2 [125],并取得了最先进的性能。

 更多模型和应用:视觉及其他视觉相关首先是医疗成像。医疗图像分割的目的是展示相应组织的解剖或病理结构,可以用于计算机辅助诊断和智能临床手术。下图 10 为医疗图像 SAM 概览,包括了计算机断层扫描(CT)图像、磁共振成像(MRI)图像、结肠镜检查图像、多格式图像、H&E 染色组织切片图像等。
更多模型和应用:视觉及其他视觉相关首先是医疗成像。医疗图像分割的目的是展示相应组织的解剖或病理结构,可以用于计算机辅助诊断和智能临床手术。下图 10 为医疗图像 SAM 概览,包括了计算机断层扫描(CT)图像、磁共振成像(MRI)图像、结肠镜检查图像、多格式图像、H&E 染色组织切片图像等。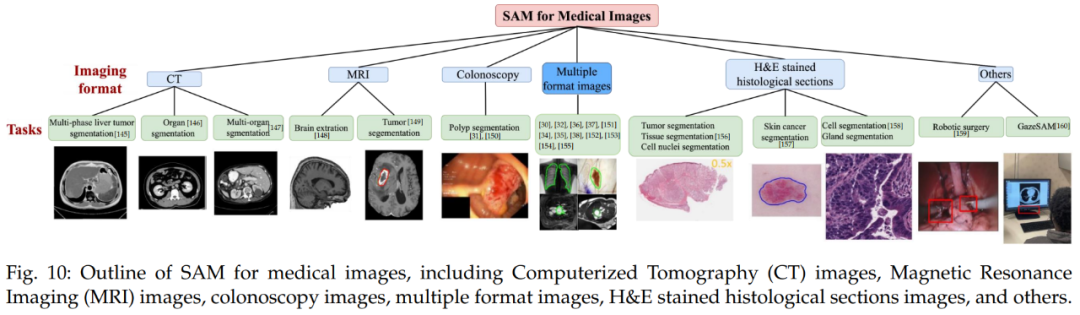 其次是视频。在计算机视觉领域,视频目标跟踪(VOT)和视频分割被认为是至关重要且不可或缺的任务。VOT 涉及在视频帧中定位特定目标,然后在整个视频的其余部分对其进行跟踪。因此,VOT 具有各种实际应用,例如监视和机器人技术。SAM 在 VOT 领域做出了杰出贡献。参考文献 [46] 中引入了跟踪一切模型(Track Anything Model, TAM),高效地在视频中实现了出色的交互式跟踪和分割。下图 11 为 TAM pipeline。结语本文首次全面回顾了计算机视觉及其他领域 SAM 基础模型的研究进展。首先总结了基础模型(大语言模型、大型视觉模型和多模态大模型)的发展历史以及 SAM 的基本术语,并着重于 SAM 在各种任务和数据类型中的应用,总结和比较了 SAM 的并行工作及其后续工作。研究者还讨论 SAM 在广泛的图像处理应用中的巨大潜力,包括软件场景、真实世界场景和复杂场景。此外,研究者分析和总结了 SAM 在各种应用程序中的优点和局限性。这些观察结果可以为未来开发更强大的基础模型和进一步提升 SAM 的稳健性和泛化性提供一些洞见。文章最后总结了 SAM 在视觉和其他领域的大量其他令人惊叹的应用。
其次是视频。在计算机视觉领域,视频目标跟踪(VOT)和视频分割被认为是至关重要且不可或缺的任务。VOT 涉及在视频帧中定位特定目标,然后在整个视频的其余部分对其进行跟踪。因此,VOT 具有各种实际应用,例如监视和机器人技术。SAM 在 VOT 领域做出了杰出贡献。参考文献 [46] 中引入了跟踪一切模型(Track Anything Model, TAM),高效地在视频中实现了出色的交互式跟踪和分割。下图 11 为 TAM pipeline。结语本文首次全面回顾了计算机视觉及其他领域 SAM 基础模型的研究进展。首先总结了基础模型(大语言模型、大型视觉模型和多模态大模型)的发展历史以及 SAM 的基本术语,并着重于 SAM 在各种任务和数据类型中的应用,总结和比较了 SAM 的并行工作及其后续工作。研究者还讨论 SAM 在广泛的图像处理应用中的巨大潜力,包括软件场景、真实世界场景和复杂场景。此外,研究者分析和总结了 SAM 在各种应用程序中的优点和局限性。这些观察结果可以为未来开发更强大的基础模型和进一步提升 SAM 的稳健性和泛化性提供一些洞见。文章最后总结了 SAM 在视觉和其他领域的大量其他令人惊叹的应用。
———————End———————
RT-Thread线下入门培训
7月 - 上海,南京
1.免费2.动手实验+理论3.主办方免费提供开发板4.自行携带电脑,及插线板用于笔记本电脑充电5.参与者需要有C语言、单片机(ARM Cortex-M核)基础,请提前安装好RT-Thread Studio 开发环境
报名通道

立即扫码报名
(报名成功即可参加)
扫码添加rtthread2020可参加活动可加微信拉进活动现场微信群

主办单位

报名链接:https://jinshuju.net/f/UYxS2k
点击阅读原文,进入RT-Thread 官网
原文标题:【AI简报20230616】英伟达推出Instinct MI300、OpenAI凌晨再给ChatGPT、GPT-4加码!
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
RT-Thread
+关注
关注
31文章
1154浏览量
38939
原文标题:【AI简报20230616】英伟达推出Instinct MI300、OpenAI凌晨再给ChatGPT、GPT-4加码!
文章出处:【微信号:RTThread,微信公众号:RTThread物联网操作系统】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
AMD硬刚英伟达,推出Instinct MI300,单芯片可运行800亿参数
了AI芯片后,便彻底带动了市场的投资热情,也推动英伟达登上万亿美元市值的高峰。此次AMD发布重磅AI芯片,有望对英伟达当前的市场地位形成一定冲击。 AMD

OpenAI推出ChatGPT新功能:朗读,支持37种语言,兼容GPT-4和GPT-3
据悉,“朗读”功能支持37种语言,且能够自主识别文本类型并对应相应的发音。值得关注的是,该功能对GPT-4以及GPT-3.5版本的ChatGPT均适用。此举彰显了OpenAI致力于“多
AMD首批Instinct MI300X已开始交付
AMD开始交付其首批用于AI和HPC的Instinct MI300X GPU。据LaminiAI首席执行官Sharon Zhou透露,该公司已经收到了这批GPU,并计划使用它们来运行大型
AMD Instinct MI300A获得德国订单
先进微设备公司(AMD)于本月6日成功举办了"推进人工智能"(Advancing AI)主题活动,期间正式发布了专为数据中心设计的Instinct MI300系列计算卡,首批推出

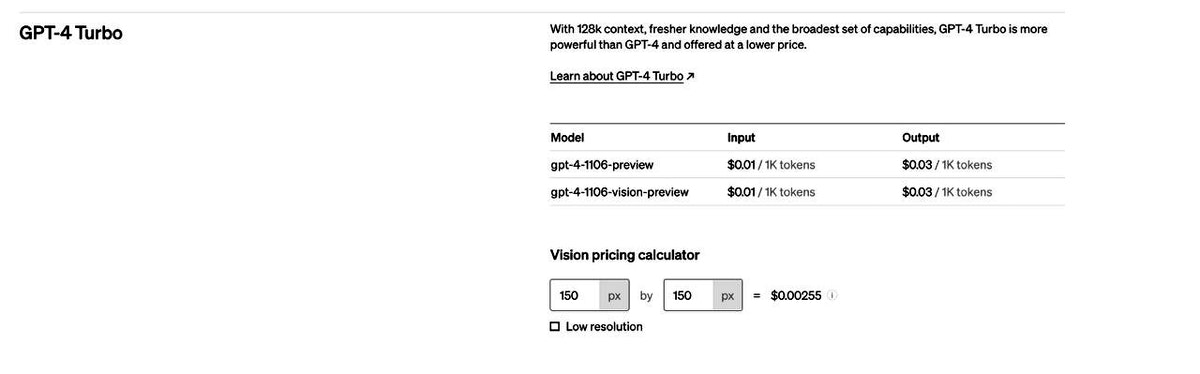
ChatGPT plus有什么功能?OpenAI 发布 GPT-4 Turbo 目前我们所知道的功能
OpenAI 发布 GPT-4 Turbo 目前我们所知道的功能分析解答 在最近的OpenAI DevDay上,该组织发布了一项备受期待的公告:推出

OpenAI发布的GPT-4 Turbo版本ChatGPT plus有什么功能?
OpenAI的GPT-4 Turbo以前所未有的功能和价格改变人工智能的未来 在人工智能领域的一次里程碑式活动中,OpenAI开发者大会上发布了GPT-4 Turbo,这是突破性人工智
戴尔禁止经销商在中国销售RX 7900 XTX、7900 XT、PRO W7900 和MI300 GPU
被禁止销售的产品有isg的instinct加速器和csg的客户端解决方案组的radeon gpu。戴尔禁止销售的“amd isg”产品包括instinct mi210、mi250、
OpenAI发生严重故障 GPT-4 Turbo模型太火爆 ChatGPT停服两小时
OpenAI发生严重故障 ChatGPT停服两小时 就在前两天OpenAI首届开发者大会广受关注,OpenAI才发布了超级重磅的更新,发布了GPT-
ChatGPT重磅更新 OpenAI发布GPT-4 Turbo模型价格大降2/3
发布GPT-4 Turbo模型 北京时间11月7日凌晨两点,OpenAI首届开发者大会在洛杉矶正式开幕。 Sam Altman分享了ChatGPT取得的成就。“有大约200万开发人员,

ChatGPT Plus怎么支付 GPT4得订阅吗?
自去年年底 OpenAI 转型发布 ChatGPT 以来,生成式 AI 成为许多硅谷投资者关注的焦点。该聊天机器人使用从互联网和其他地方抓取的大量数据来对人类提示产生预测响应。GPT-4
AMD对抗英伟达的王牌,MI Instinct
大语言模型市场,专门推出了纯CDNA 3 GPU架构打造的MI300X,集成192GB的HBM3。 下一代数据中心与超算的选择 , Instinct MI300 随着

GPT-3.5 vs GPT-4:ChatGPT Plus 值得订阅费吗 国内怎么付费?
GPT-3.5 vs GPT-4:ChatGPT Plus值得订阅费吗?ChatGPT Plus国内如何付费? ChatGPT-3.5一切
OpenAI宣布GPT-4 API全面开放使用!
OpenAI 在博客文章中写道:“自 3 月份以来,数百万开发者请求访问 GPT-4 API,并且利用 GPT-4 的创新产品范围每天都在增长。” “我们设想基于对话的模型未来可以支持任何用例。”
亚马逊高管称AWS云服务将考虑采用AMD MI300芯片
目前,人工智能领域仍由英伟达的芯片主导,h100、a100等加速卡供不应求。amd将推出instint mi300系列产品,与英伟达竞争,抢占人工智能计算领域的市场份额。amd首席执行
AMD硬刚英伟达,推出Instinct MI300,单芯片可运行800亿参数
在这次AMD的新品发布会中,核心产品无疑是用于训练大模型的GPU Instinct MI300。早在今年初,AMD便已经宣布了新一代Instinct MI300,是全球首款同时集成CP






 工商网监
工商网监
评论