 CPU共享资源隔离的利器MPAM特性介绍
CPU共享资源隔离的利器MPAM特性介绍
MPAM(Memory System Resource Partitioning and Monitoring)[1]特性用于解决混部业务时由于共享资源竞争带来的性能下降问题,MPAM 作为继 x86 RDT[2]技术后的另一个针对 CPU 访存系统资源隔离的全新特性倍受关注,相比其他架构的类似特性,Arm64 架构下的 MPAM 特性采用全新的确定性流控方式,控制手段更加丰富,控制对象覆盖更广,目前在鲲鹏服务器上的应用取得了良好的结果。openEuler kernel 已于 openEuler 21.03 创新版本支持 MPAM,成为首个同时支持 x86 RDT 和 MPAM 的开源平台;MPAM 项目组联合下游各大厂商及研究机构在 POC 场景上做了验证,使能 MPAM 并在云场景下进行了多个测试点的适配和测试,解决了不同虚拟机因为 Cache 和访存干扰带来的性能干扰问题,目前已具备相当的成熟度;为支撑下游厂商使用 MPAM,构建完整端到端基础软件栈,项目组后续还会在 openEuler 推出一系列配套调测工具和部署软件。
特性介绍
如何处理诸如 L3 Cache 等内存系统资源竞争的问题一直是业界研究的焦点,例如 Kpart[3],DICER[4],dcat[5],这些研究为工业界应用共享资源隔离技术打下了基础。MPAM 是 Arm Architecture v8.4 的 Extension 特性,其目的是用于解决服务器系统中,混部不同类型业务时,由于 CPU 访存过程中共享资源的竞争带来的某些关键应用性能下降或者系统整体性能下降的问题。
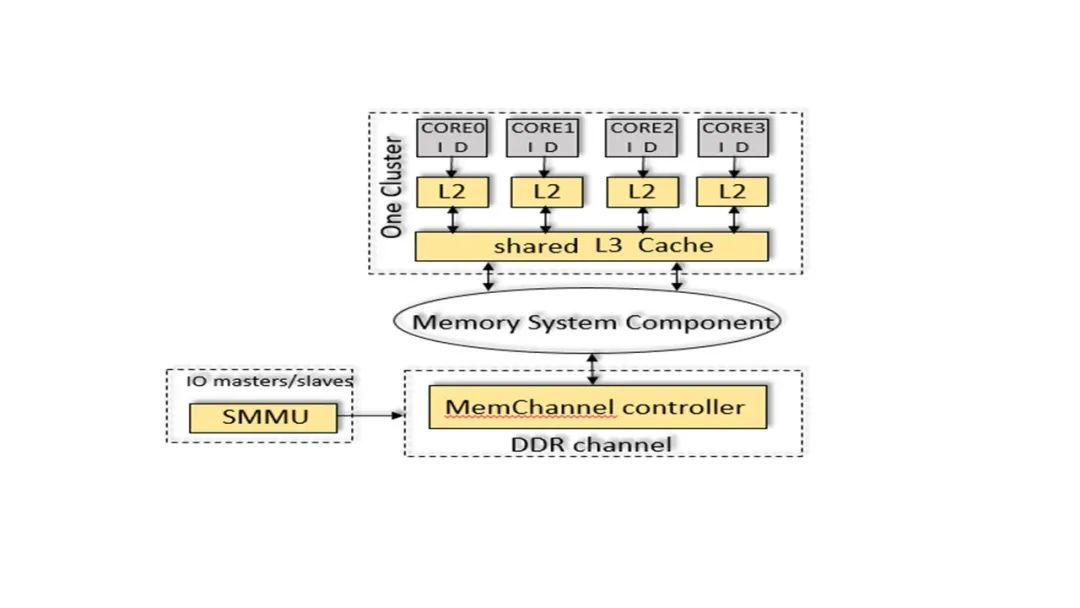
MPAM 系统框架参考图 1,相比其他架构的类似特性,MPAM 设计上参考了更多前沿技术,MPAM 最显著的特征是:
提供更多控制手段,针对 Cache 资源以及访存通道,增加了对访存流的优先级控制和完全隔离控制;
按照 Cache way 为粒度,以 bitmap 的形式分配 Cache way,不要求所分配的 Cache way 在 bitmap 中连续;
MPAM 支持在虚拟机内部划分共享资源;
MPAM 增加了对 SMMU 的支持,可以限制 IO 设备对 Cache 和相关内存系统资源的使用;
从体系结构角度优化·最佳配置,在对访存流的限制上,MPAM 流控方式可精确控制访存流百分比,可以确定性地保障访存敏感型业务的性能。
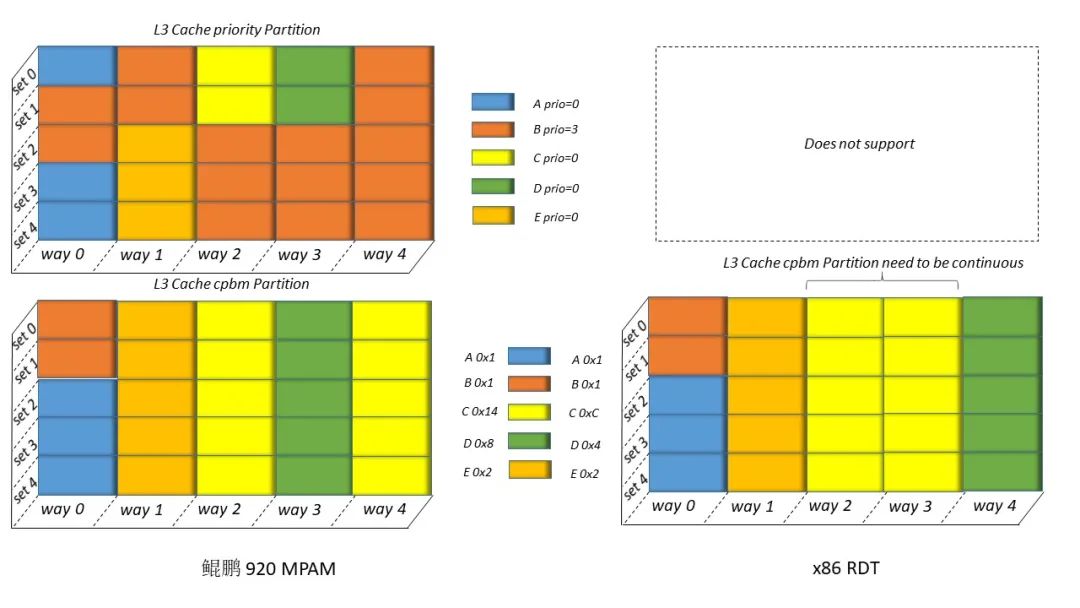
图 2 MPAM 和 RDT L3 Cache 控制方式异同 如图 2,MPAM 规定配置 Cache 主要有两种方式,一种是通过优先级配置,这种情况下,优先级高的业务流将优先使用 Cache 的使用权;第二种是以 Cache way 为粒度,按照 bitmap 形式隔离不同业务对 Cache 的使用,不要求 Cache way 分配连续,这也是目前鲲鹏 920 采取的控制方式。x86 RDT 目前仅支持第二种,且大部分型号要求 Cache way 分配连续[6]。图 3 为鲲鹏 920 和常用 x86 型号 RDT 特性对流量控制的比较,对比其他架构的类似特性,MPAM 在流量控制上的最大特点是参考当前 DDR 通道的传输能力,从而对业务流限制一个明确的上下限,若当前受控流量超过该 DDR 通道设定百分比对应的上限流量时,则限制到该百分比以下,同时在小于下限流量时享有优先访问权。对比 x86 RDT,其限制流量的动作发生在 L2 和 L3 之间,使用给受控流量主动加时延的方式降低目标流量[6]。
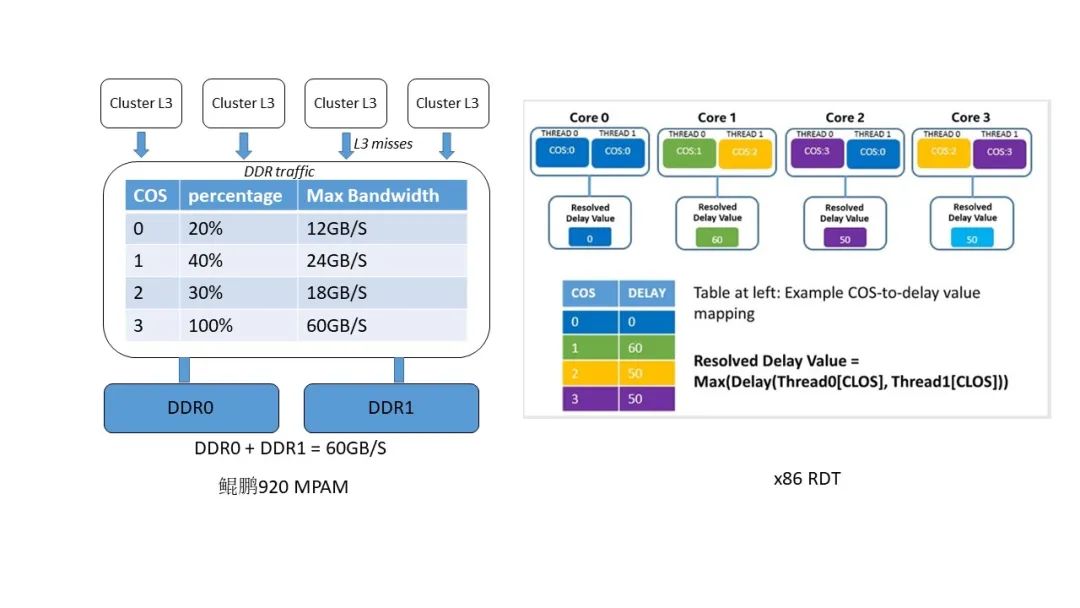
图 3 鲲鹏 920 MPAM 与 x86 RDT 流量限制上的异同 除此之外,MPAM 协议规定了额外两种流量控制方式,如图 4 所示,一种是采用 bitmap 的方式完全隔离开不同的业务流,被隔离的业务流将会按照 bitmap 划分的时间片分区间轮询使用访存通道;第二种,在第一种方式的基础上,还可使用优先级方式调整业务流的优先级,在发生访存拥挤时,同一时刻高优先级业务流将优先享有该 DDR 通道。
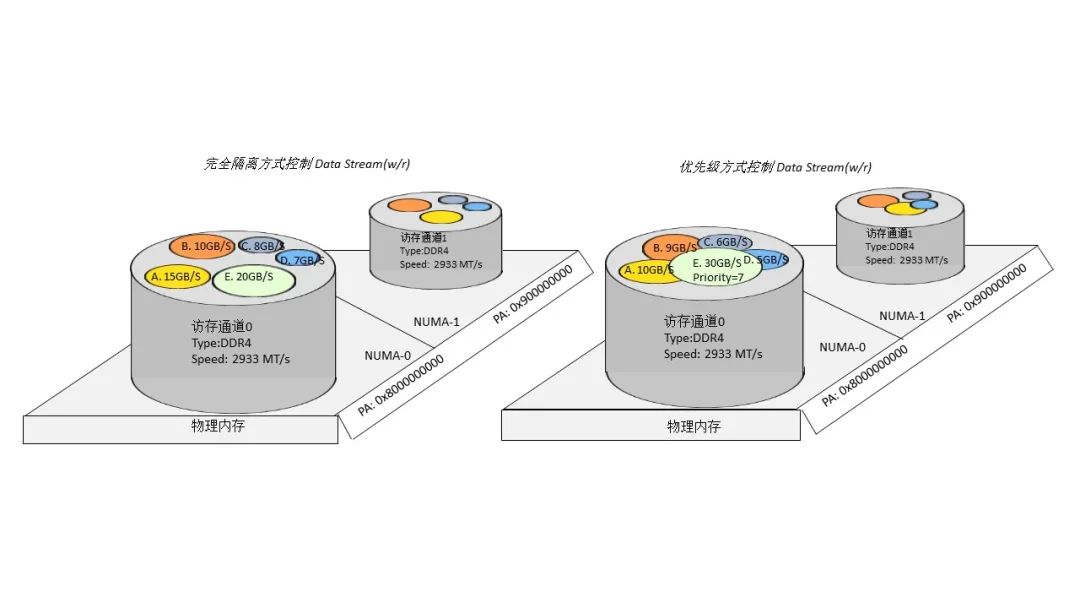
图 4 MPAM 带宽的完全隔离和优先级控制方式 MPAM 可以在更多维度灵活配置业务对 Cache 和带宽的使用,适应更多的应用场景,易于获得更大的优化空间。
特性使能
硬件支持:鲲鹏 920[7]
内核支持:openEuler 21.03 或 openEuler 20.03 LTS SP1[8]
用户手册:https://gitee.com/openeuler/openRSO/blob/master/docs/manual/arm_mpam_resctrlfs_user_interface.md
鲲鹏 920 已支持 MPAM 特性的部分功能,如图 5 所示:
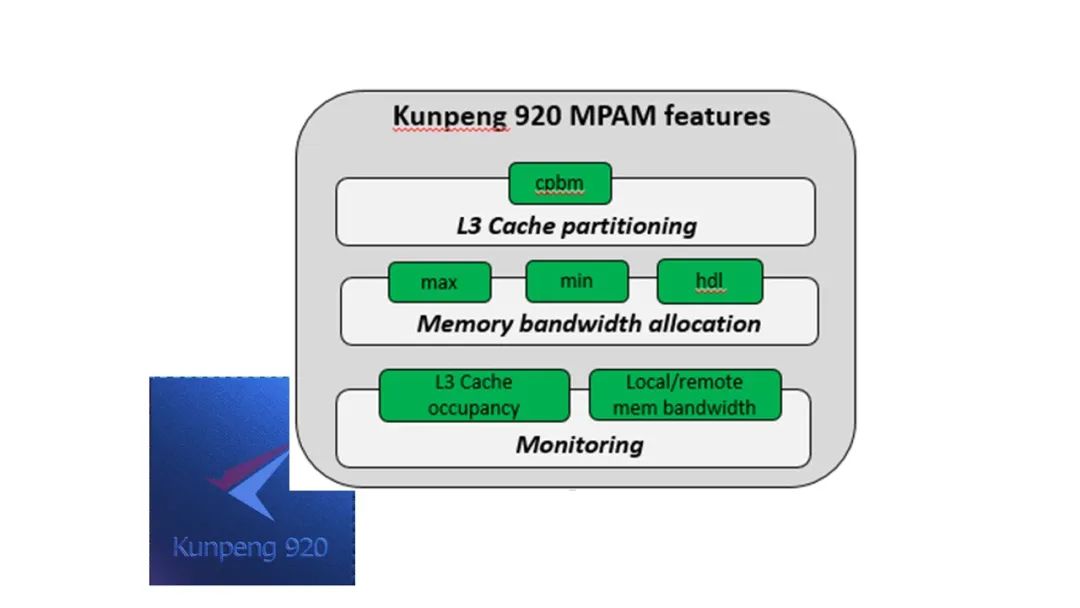
图 5 鲲鹏 920 MPAM 所使能功能
cpbm: Cache Portion Bit Map,按照位图控制分配特定容量和特定位置的 L3 Cache,其中每个 bit 代表一条 Cache way;
max: Memory Bandwidth Maximum Partition,按照能够通过受控 DDR 通道最大带宽的百分比进行访存流量限制;
min: Memory Bandwidth Minimum Partition,提供最小带宽百分比表示允许通过受控 DDR 通道的容量,小于最小百分比将享受较高优先级的通过权;
hdl: Memory Bandwidth Hard Limit,开启会使得分区的带宽使用率降至最大带宽控制的范围之内,参考 Max,否则,只有在通道拥挤时才会做适当限制;
Monitoring: Cache/Memory Bandwidth monitoring,对 L3 Cache 占用大小和访存带宽大小进行实时监控。
性能测试
硬件平台:鲲鹏 920 @CORE 96 2.6GHZ
DDR:Configured Memory Speed: 2666 MT/s
OS:openEuler 21.03
BIOS:Taishan 170
基础功能指标
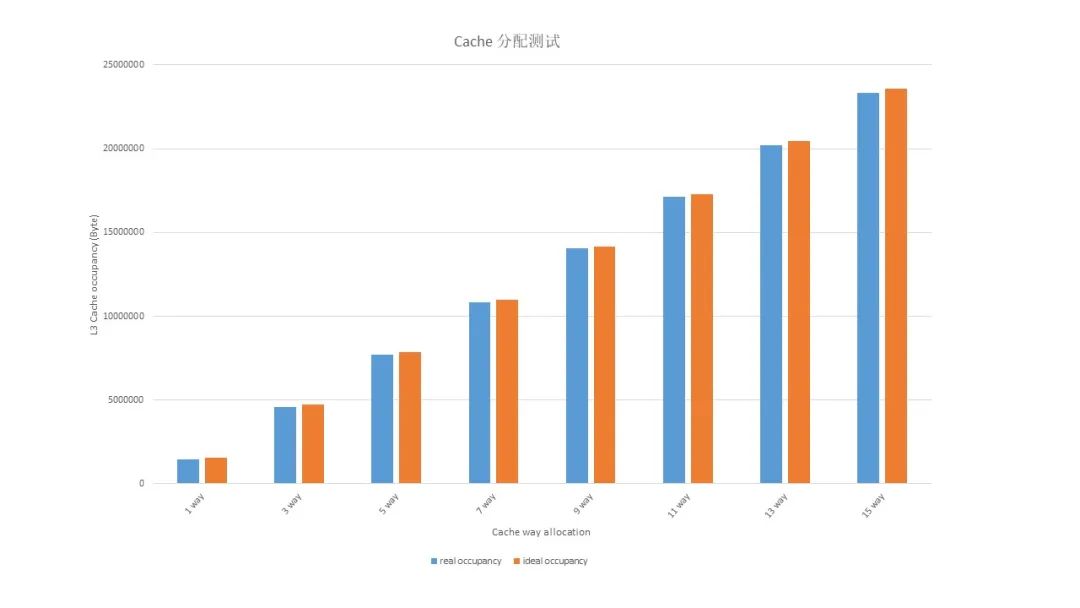
图 6 实验一 MPAM 单 workload L3 Cache 分配和监控实验一
workload: numactl –m 0 bw_mem –P 8 –N 4 128M rd如图 6 所示,启动一个 workload,workload 也可自行选择,对 L3 Cache 按 cpbm 分配,通过 MPAM 的 monitor 查看 workload 占用的 L3 Cache 容量变化,可见 workload 真实占用的 Cache 容量和理论大小基本一致。
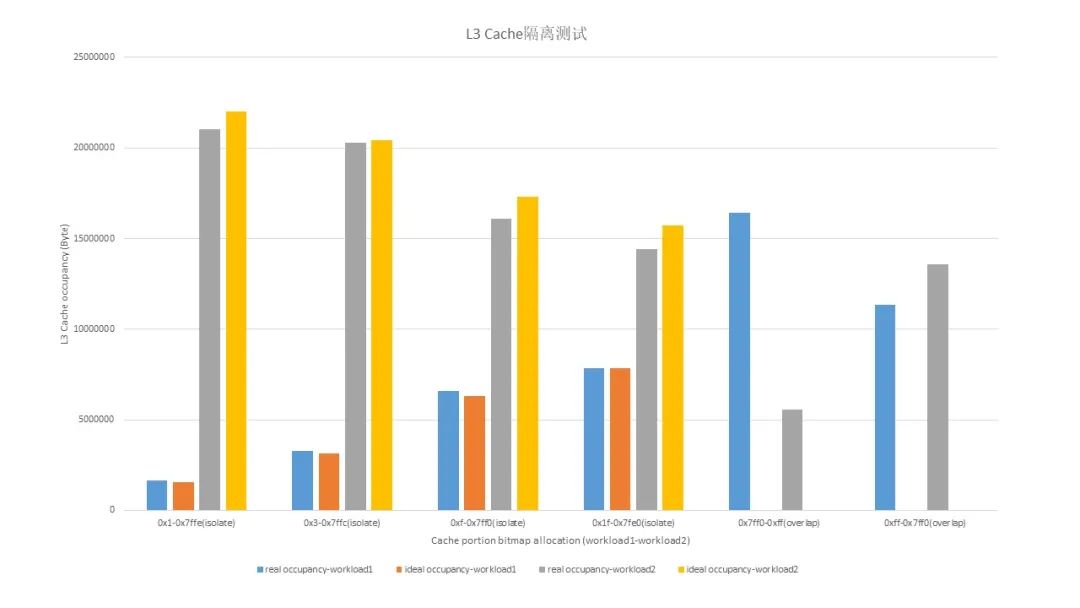
图 7 实验二 MPAM 双 workload Cache 隔离实验二
workload1: numactl –m 0 stress-ng –cache 10 --aggressive workload2: numactl –m 0 bw_mem –P 8 –N 4 128M rd如图 7 所示,启动两个 workload,使用 cpbm 方式对两个 workload 做 Cache 隔离测试,通过 MPAM 的 monitor 查看 workload 占用的 L3 Cache 容量变化,该测试分为两部分,前四组为 Cache way 完全隔离测试,后两组为 overlap 测试,可见 Cache 隔离效果与理论值基本一致,后两组实际效果与 workload 对 Cache 的占用强度有关。
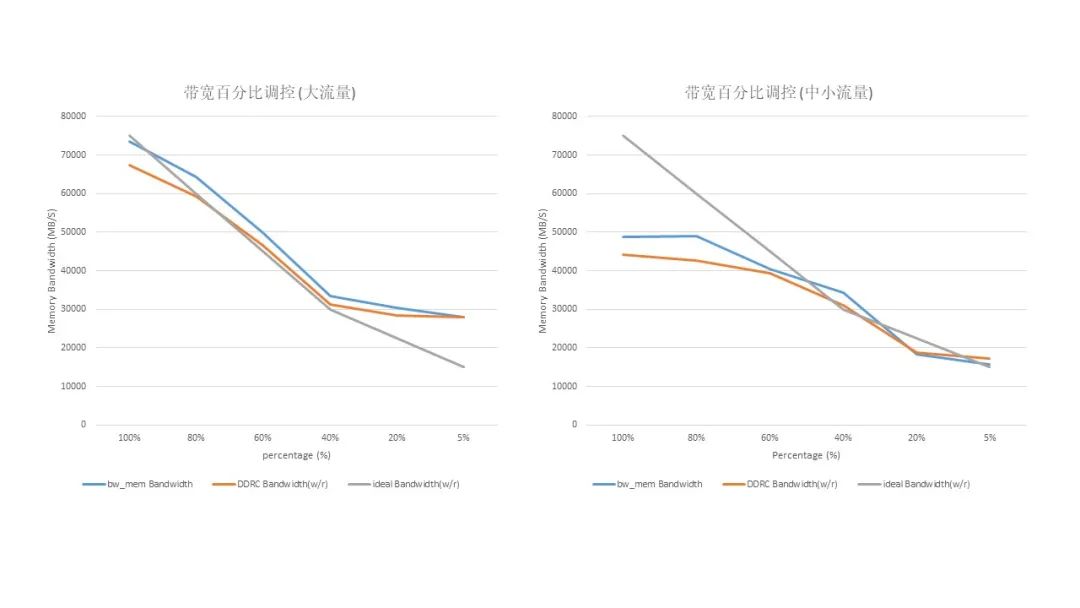
图 8 实验三带宽最大百分比调控实验三
workload: numactl –m 0 bw_mem –P 8 –N 4 128M rd如图 8 所示,在大流量下和中小流量下(当前 DDR 通道最大带宽约为 75MB/S)对带宽做最大百分比调控,通过 MPAM monitor 查看 workload 对应流量大小变化,可见流量控制效果基本与预期相符,鲲鹏 920 上 MPAM 设定的带宽控制有效百分比约在 20%-80%。
spec CPU 2006 测试
选用 spec CPU 2006 omnet 测试套和 spec CPU 2006 milc,分析 Cache 干扰:cpu+内存型业务混合部署场景下,通过 CPBM 隔离 L3 Cache 可以削弱不同业务对 Cache 的竞争,提升性能,如图 9 所示,非隔离时两种业务之的 Cache 实际占用大小波动非常大,这是造成性能下降的主要原因。
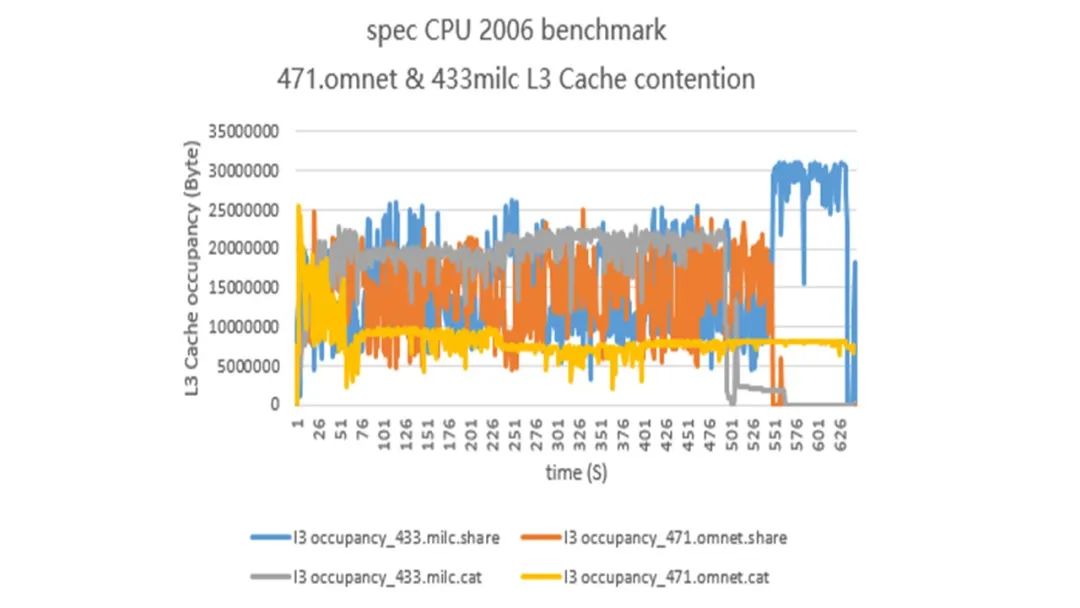
图 9 MPAM spec 2006 L3 Cache 隔离测试[9] 通过对两组业务的 Cache 进行完全隔离,可以看到隔离后的业务 Cache 实际占用大小波动明显减少,对比不做隔离的情况,omnet 业务最终获得了 10+%的性能提升,milc 业务性能也略有提升。
DPDK 隔离带宽干扰
裸机场景下,使用 pktgen+DPDK 进行试验,并对 DPDK 施加带宽压力,使用 MPAM 对比隔离前后 DPDK 性能变化:
solo加压加压+MPAM限制带宽20%
每秒平均指令数2E+09 + 5E+071.7E+092E+09 + 4E+07
指令数下降比NA22%0.7%
dpdk性能下降NA≈21%≈0
如表 1 所示,可知加压后导致性能退化 22%左右,加压参数参考[9],使用 MPAM 限制压力程序 20%带宽,DPDK 性能恢复正常。
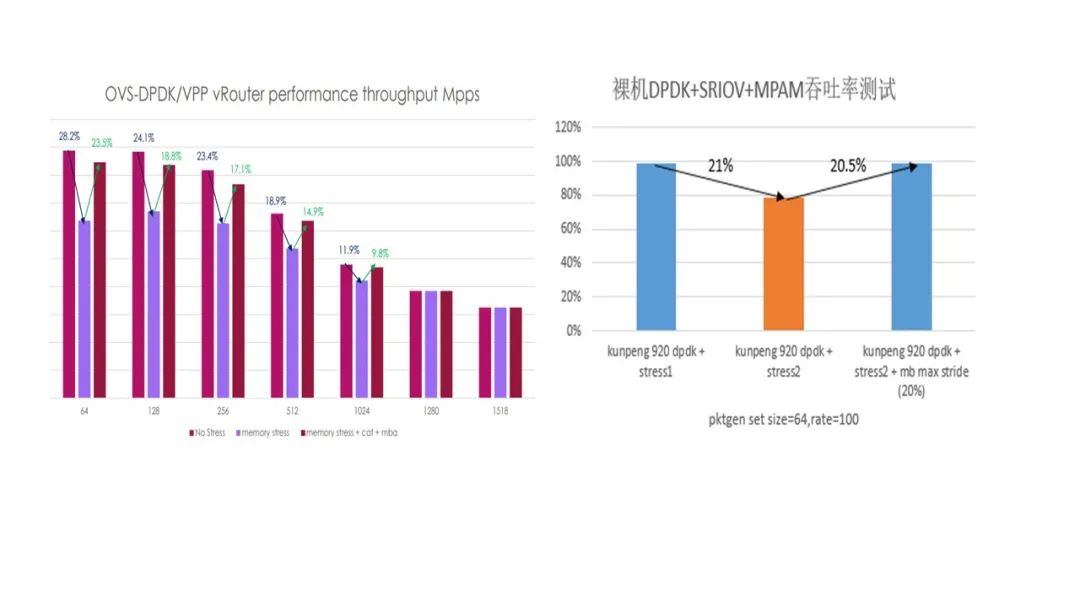
图 10 RDT 和 MPAM DPDK 场景测试[10][11]
内存大页+Cache 隔离
如图 11 所示,网络转发业务选用 2G 内存大页,左图不同线程之间存在稳定的 Cache 干扰,右图表示性能下降比例,通过隔离 Cache 可消除该干扰,保证关键业务的性能。
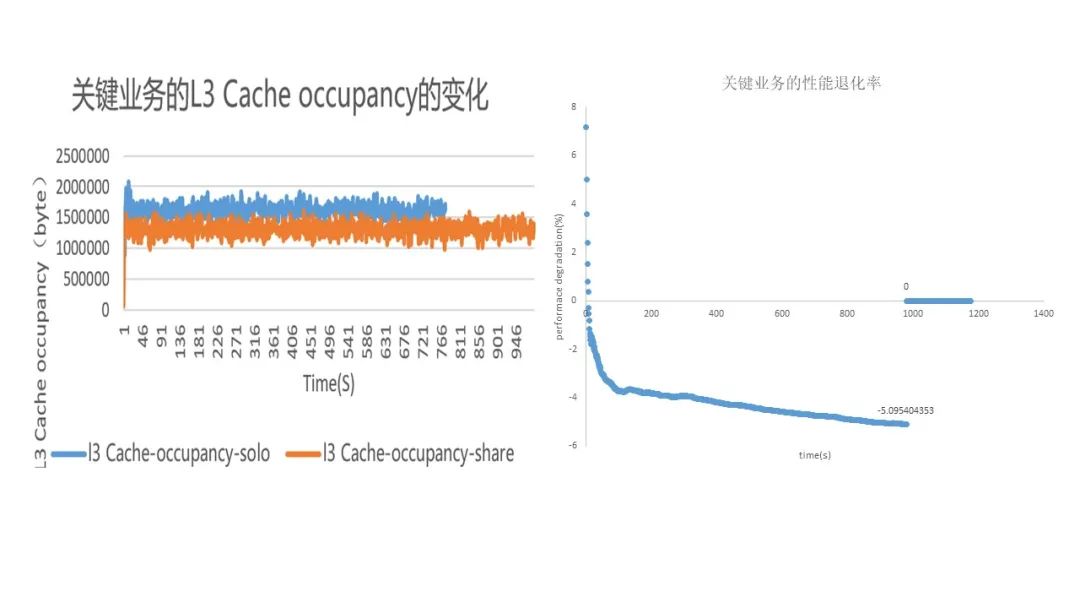
图 11 内存大页和 MPAM Cache 隔离测试网络转发业务[9]
开放生态
资源隔离是 OS 中非常重要的一个组成部分,针对 cpu 核访存侧的隔离技术又是资源隔离中的一个重要组成部分,如何规划好未来对内存系统资源的高效使用,对保障业务在更加复杂的平台上稳定运转至关重要。为减少跨平台成本,丰富调试手段,提升业务部署效率,我们希望归一化不同架构的输出接口,开放应用端到端统一部署框架,针对不同场景定制化通用化的资源隔离调度引擎,构建一整套应用资源管理基础软件栈。
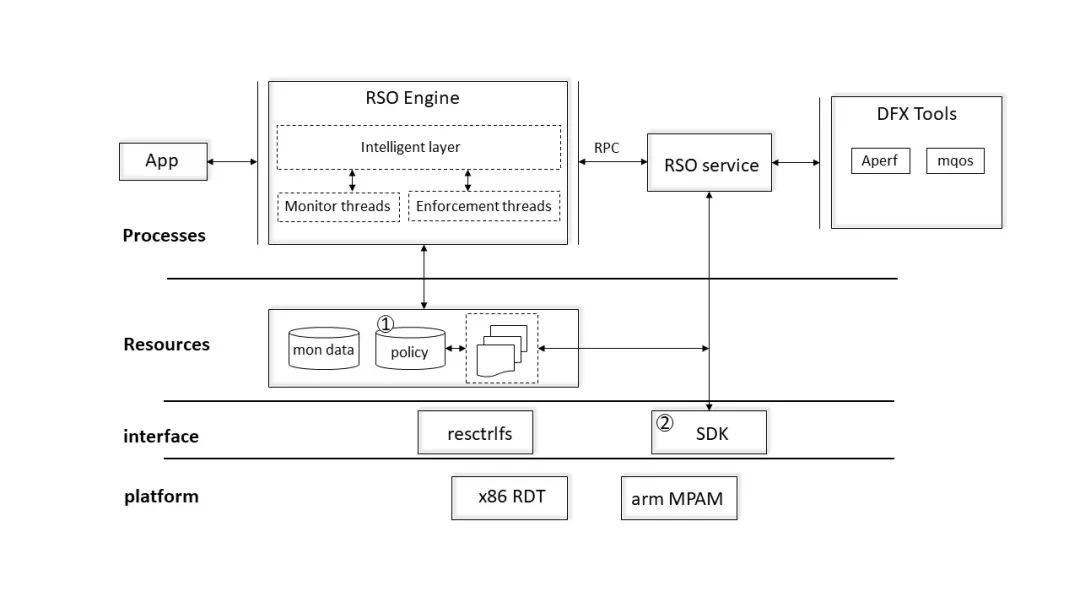
图 12 共享资源调控基础软件框架我们计划在 openEuler 开源一套共享资源调控基础软件框架,用于跨平台统一管理业务使用 Cache 及相关内存系统资源,通过引入丰富、实用的调试工具帮助用户排查相关性能问题,并增加通用资源调度引擎处理针对不同场景下的资源动态调控问题,按照部署业务的层级整合和编排共享资源的使用,方便用户部署业务和整合系统资源分配。针对 MPAM 技术,目前已和通信行业、电商、云服务商等合作领域企业进行沟通合作,并已在部分场景上取得成效,欢迎业界专家建言献策,共同打造实用,稳固,开放的底层资源隔离基础软件底座。
原文标题:openEuler 21.03 特性解读 | CPU 共享资源隔离的利器 - MPAM
文章出处:【微信公众号:Linuxer】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
cpu
+关注
关注
68文章
10442浏览量
206547
原文标题:openEuler 21.03 特性解读 | CPU 共享资源隔离的利器 - MPAM
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
AMD Radeon RX 7000M系列显卡特性分析

如何在Semaphore(信号量)和Mutex(互斥)之间做选择?

浅析Redis 分布式锁解决方案
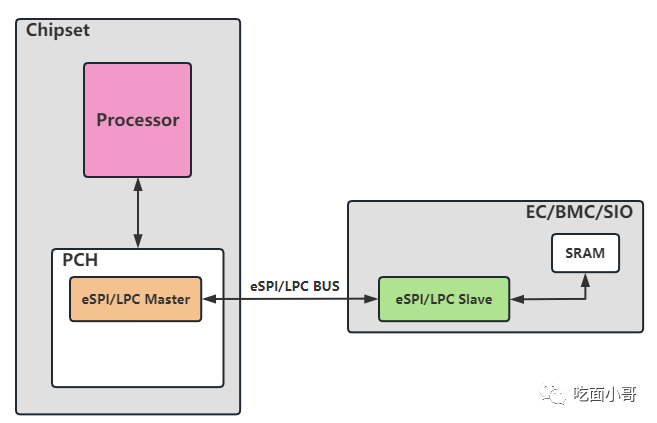
EC SRAM映射到CPU Memory空间的共享内存设计
redis分布式锁如何实现
9个超使用的cmd命令你知道多少?
用于内存系统资源分区和监控2.0平台的ACPI设计文档
了解体系结构-内存系统资源分区和监视(MPAM)概述
ARMv8-A同步原语介绍
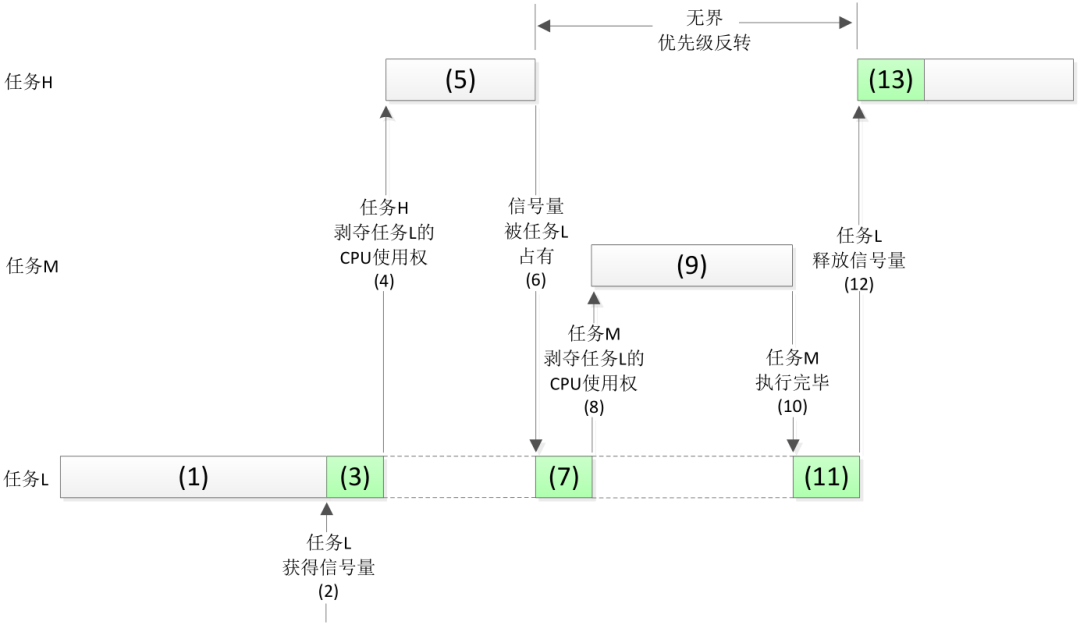
I2C子系统优先级翻转与优先级继承
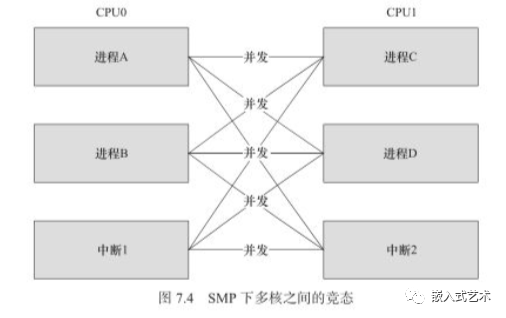
Linux内核处理并发和竞争的几种方法






 工商网监
工商网监
评论