 深度学习在58同城首页推荐中的应用
深度学习在58同城首页推荐中的应用
引言
58 同城作为国内最大的生活信息服务提供商,涵盖招聘、房产、车辆、兼职、黄页等海量的生活分类信息。随着各个业务线业务的蓬勃发展,用户在网站上可获取的分类信息是爆炸性增长的。如何解决信息过载,帮助用户快速找到关注的信息,已经成为用户体验提升的关键点与服务的核心竞争力。
背景
目前,搜索与推荐是两个主要手段。其中,搜索需要人工启发属于被动查找,而推荐可以主动推送,使得用户查看信息这一过程更加智能化。
近几年随着计算机硬件性能的提升以及深度学习的快速发展,在自然语言处理、图像处理、推荐系统等领域有了很多应用,因此实现准确、高效基于深度学习的个性化推荐,不仅能提升用户体验,同时也能提升平台效率。
58 App 推荐涉及的推荐场景有首页猜你喜欢、大类页、详情页、搜索少无结果,首页推荐场景和电商场景类似,不同的用户同样会有不同的兴趣偏好。
比如用户需要租房、买车,或者找工作、找保洁,针对用户的个性化偏好产生千人千面的推荐结果;同时用户对于相似的帖子表现为不同的兴趣,比如同一车标不同的车系,这其实就是一个用户兴趣建模问题。
目前平台已经积累了丰富的用户行为数据,因此我们需要通过模型动态捕捉用户的实时兴趣,从而提升线上 CTR。
58 推荐系统概述
整个推荐系统架构可以分为数据算法层、业务逻辑层、对外接口层。为各类场景产生推荐数据,如图 1 所示。
推荐过程可以概括为数据算法层通过相关召回算法根据用户的兴趣和行为历史在海量帖子中筛选出候选集,使用相关机器学习、深度学习模型为候选帖子集合进行打分排序,进而将产生用户感兴趣并且高质量的 topN 条推荐帖子在首页猜你喜欢、大类页、详情页、少无结果等场景进行展示。
从数据算法层来看推荐的核心主要围绕召回算法和排序模型进行,当然算法和策略同等重要,因此需通过理解业务来优化模型、策略之间的冲突。
其中排序模型的构建则是进一步影响线上用户体验的关键,本文主要围绕深度学习在 58 首页推荐排序上的应用展开介绍。
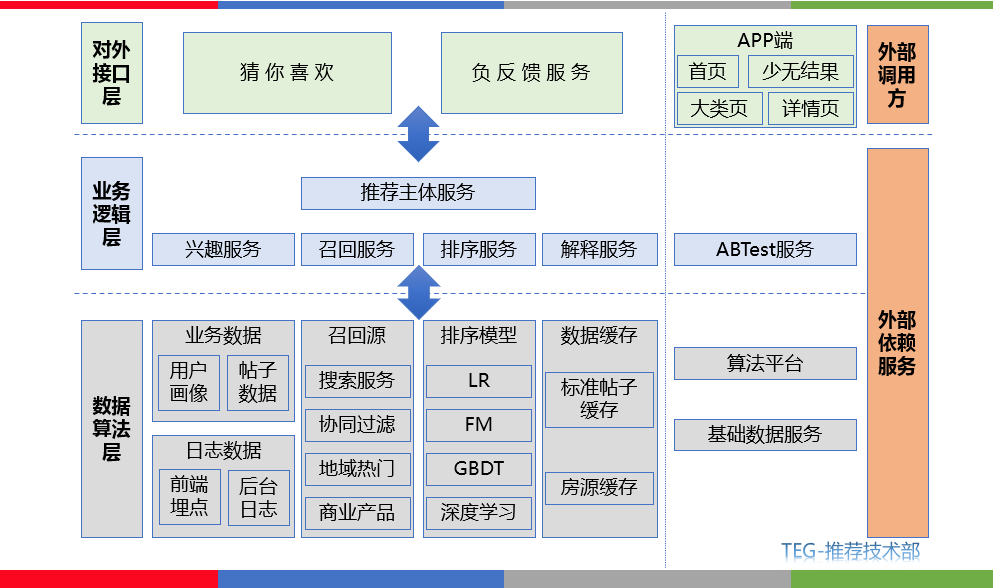
图 1 58 推荐系统架构
首页推荐场景位于 58 同城 App 首页下方的推荐 tab,包含招聘、租房、二手房、二手车等多品类业务信息。
图 2 首页推荐场景 tab
如图 2 可以看到左图用户兴趣主要为租房,右图用户兴趣为二手房、二手车、租房,这也就体现出首页场景下多业务融合的特点。用户在首页推荐场景下行为特点表现为强兴趣,即用户兴趣明确,但是在多业务信息融合的背景下,用户的兴趣又具有不同的周期性,以及不同的行为等,比如租房周期明显要低于二手车成交周期,这些不同的特性对于多业务融合推荐排序任务提出了重大挑战。
业界技术路径
2016 年 Youtube 将 DNN[1]应用于视频召回、推荐;Google 提出 Wide&Deep[2] 模型、为后来深度学习模型在推荐任务中的优化改进提供了基础。58 同城 TEG - 推荐技术团队一直紧跟技术前沿,在 58 同城各推荐场景探索并落地了一系列深度学习模型。本章节将介绍深度学习模型在推荐排序任务中的创新及经典应用,并以现有模型为基础结合我们的业务特点进行模型选型并优化改进。
1. YouTube-DNN
DNN [1]应用场景为 YouTube App 首页视频推荐,通过 Word2Vec 生成用户历史观看视频以及搜索关键词 Embedding,之后将历史行为向量进行平均得到 watch vector、search vector 其他类别特征也需要进行 Embedding 最终和连续值特征拼接处理,最终作为 DNN 的输入。
对于类别特征的 Embedding 有两种基本处理方式,通过模型生成向量比如 Word2Vec,或者采用 Embedding 层初始化后和 DNN 一起训练。
对于图 3(左)召回任务,YouTube 将目标定义为用户 next watch,通过 softmax 函数得到所有候选视频的概率分布。对于图 3(右)排序任务,作者在输入特征部分除了在召回时用到的 Embedding 之外还加入了一些视频描述特征、用户画像特征、用户观看同类视频间隔时间、当前视频曝光给当前用户次数等体现二者关系的特征。
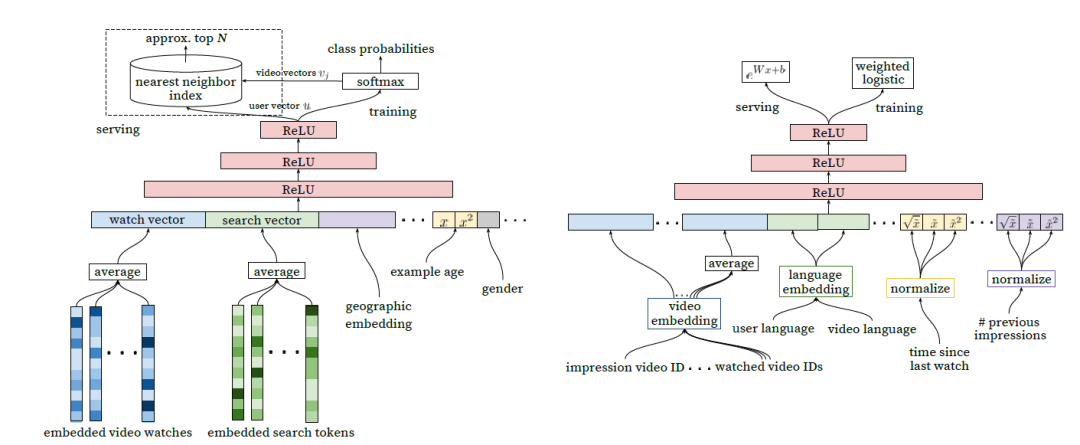
图 3 YouTube DNN [1] 模型结构
2. Google-Wide&Deep
Wide&Deep[2]模型应用场景为 Google Play 也就是用于 App 推荐,论文强调该模型设计的目的在于具有较强的“Memorization”、“Generalization”。
文章中描述如下假设用户安装了 Netflix,并且该用户之前曾查看过 pandora,计算如下组合特征 (user_installed_app=Netflix,impression_app=pandora) 和安装 pandora 的共现频率,假设该频率比较高则我们希望模型发现这一规律在用户出现这一组合特征时则推荐 pandora。
像 Logistic Regression 图 4(左)这样的广义线性模型可以做到 Memorization 这一点。而对于 DNN 图 4(右)模型则可以通过低纬稠密的 Embedding 向量学习到之前未出现的特征组合从而减少特征工程的负担并且做到 Generalization。
最终组合之后的 Wide&Deep 图 4(中)模型即便输入特征是非常稀疏的,同样可以得到较高质量的推荐结果。
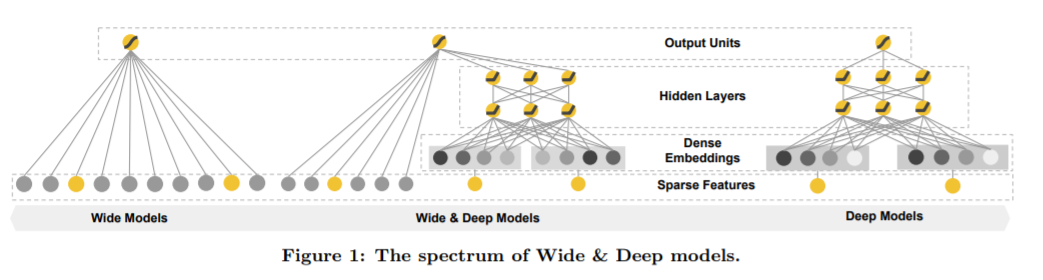
图 4 Google Wide&Deep[2] 模型结构
3. 华为-DeepFM
DeepFM[3] 模型应用场景为华为应用商店,Wide&Deep 模型为之后两种模型左右组合的结构改进提供了基础。
其中图 5 DeepFM 则是对 W&D 模型的 Wide 部分进行改进的成果,由 FM 替换 LR,原因在于 Wide 部分仍然需要繁杂的人工特征工程。通过 FM 则可以自动学习到特征之间的交叉信息,相比 W&D 模型 DeepFM 则包含了一阶、二阶、deep 三部分组成从而实现不同特征域之间的交叉。
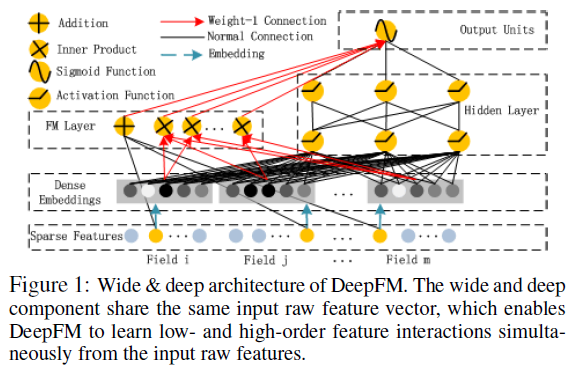
图 5 华为 DeepFM[3] 模型结构
4. 阿里巴巴-DIN
DIN[4] 模型应用场景为阿里巴巴在线广告推荐,考虑用户兴趣的多样性,YouTube-DNN 模型中也利用了用户历史行为特征,但是将所有视频 Embedding 进行平均,这样就相当于是所有历史行为对于现在的行为产生相同的影响,这样的设计对于用户体验是不合常理的。因此,考虑引入 NLP 中的 Attention 机制,针对每一个历史行为计算不同的权重。
总的来讲 DIN (图 6)模型在为当前待排序帖子预测点击率时,对用户历史行为特征的注意力是不一样的,对于相关的帖子权重更高,对于不相关的帖子权重更低。
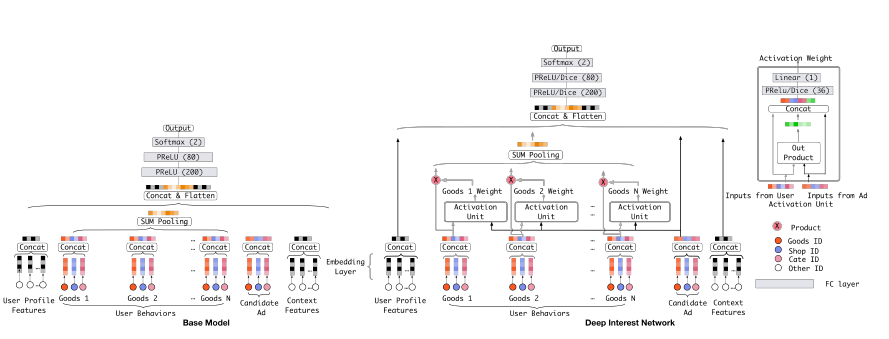
图 6 阿里巴巴 DIN[4]模型结构
5. 阿里巴巴-DIEN
DIEN[5](图 7)模型应用场景为阿里巴巴在线广告推荐,该模型是对 DIN 的改进模型,主要考虑以下两个方面,DIN 只考虑了用户兴趣的多样性引入 Attention,但是并没有考虑用户兴趣的动态变化。
因此引入兴趣抽取层,使用 GRU 序列模型对用户历史行为建模、引入兴趣进化层,使用 Attention、GRU 对用户兴趣衍化建模。在用户无搜索关键词的情况下捕捉用户兴趣的动态变化将是提升线上点击率的关键。
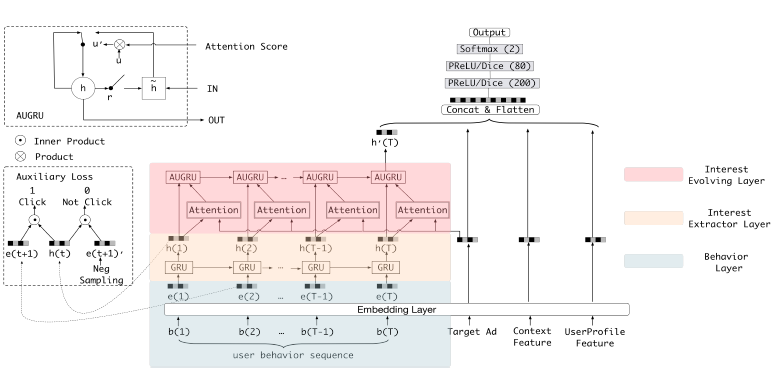
图 7 阿里巴巴 DIEN[5] 模型结构
通过分析以上模型我们可以发现深度学习模型可以减少人工特征工程,但减少并不等同于不进行人工特征工程。
Embedding&MLP 结构将大规模稀疏数据转化为低纬稠密特征,最终通过转换 (Concatenate、Attention、Average) 操作,将其转化为固定长度的向量 feed 到 MLP,学习特征间的非线性关系。
相同结构的模型在不同的业务上效果会有差异,在近几年发表的论文中,没有一个模型会在所有数据集上表现最优,因此需要寻找适合不同场景、不同业务的模型并加以改造。
以 DIEN 为例,由于作者考虑到用户购买兴趣在不同的时间点不同,用户购买手机后可能需要购买手机壳等,用户的兴趣存在一个进化的过程,并且用户的整个兴趣行为需要准确、完整等。推荐的目标是为用户展示相关信息提升平台效率,那么就要从用户角度考虑去构建模型,而不是单纯验证模型。
深度学习在 58 首页推荐的应用
对于 58 同城推荐任务,深度学习模型在不同的场景中也是不通用的,即使是对同一类业务下的不同场景同样需要定制才可以达到提升用户体验以及平台收益的目的。
点击率预估模型的目标是提升用户线上点击率,因此平台为每一个用户展示的信息以及用户点击或者其他行为的信息对于模型的离线训练以及线上效果至关重要。
上文中提到的 DNN、Wide&Deep、DeepFM 模型为后来的一些深度学习模型的改进提供了基础,这些模型我们在前几年也进行了验证,并且能够达到预期效果。由于目前平台已经积累了大量的用户行为数据我们的目标则是通过为用户兴趣建模来提升线上点击率,利用阿里提出的用户兴趣网络以及用户兴趣进化网络模型来定制模型结构对于我们的目标是有帮助的,因此我们需要根据首页推荐场景多业务融合的特点进行改进。
本章节将展开介绍 58 首页推荐场景下是如何以现有模型为基础,并结合我们的业务特性来设计可以适配当前场景的模型架构。
模型
58 同城首页推荐场景中的深度学习模型也是遵循 Embedding&MLP 结构。对于用户行为特征,我们根据业务选择了用户比较敏感的三类 ID 特征,帖子 ID、类目 ID、地域 ID,通过 Attention 计算用户历史兴趣对于待排序帖子的影响程度,通过 AUGRU 捕捉用户兴趣的动态变化。
其中用户行为中 ID 类特征 Embedding 特征维度统一(定长,对应下图中的 Infoid、Cateid、Localid),其他类别特征维度可根据实际业务情况进行修改(变长,对应下图中的 category1…categoryN),除用户行为特征外,其他类别特征、连续特征可通过配置文件进行单独配置。
深度学习模型离线训练、在线预估部分输入保持一致,保证多内聚低耦合降低依赖就可以加快离线验证迭代速度,同时可以快速迁移到线上其他场景。
结合首页多业务融合的特点,用户兴趣网络实现结构如图 8 所示,特征部分包含人工业务特征、人工向量化交叉、兴趣特征等。
其中 Item Embedding 是在用户行为数据中应用 Word2Vec 得到的向量、User Embedding 则是根据 Word2Vec 向量加权得到,具体加权可使用 TF-IDF、待排序帖子与用户历史点击帖子相似度等方式。
在实现模型时特征处理部分需要注意,不建议使用 tf.feature_column API,需要在特征工程部分实现处理逻辑,可减少线上推理耗时。
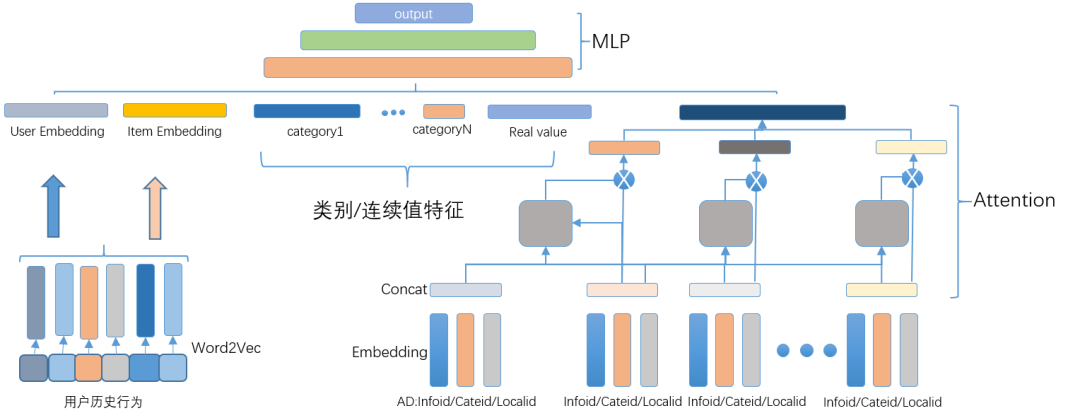
图 8 58 首页推荐场景下的深度学习模型结构
基础特征
对于基础特征部分我们分别构建了帖子特征、用户特征以及用户-帖子组合特征,基础特征由于具有明显的物理意义,可解释性强等特点在各个业务中不容忽视,具体基础特征可参考下表。
以租房业务中的用户-帖子类特征为例,通过建立租房用户对于房源的地域、价格、厅室等兴趣标签以及房源本身的地域、价格、厅室等属性信息可以计算用户与房源之间的相关程度。
由于 58 首页场景为多品类推荐,部分特征对齐工作比较困难,比如用户同时关注二手房,二手车等,那么房价以及车的价格不属于同一空间维度,无法在传统机器学习模型中直接使用,还有用户兴趣具有不同的周期性不同的行为等。由于这些问题的存在,我们考虑在用户行为上进行构建特征,线上 CTR 取得进一步的提升。
| 类目 | 帖子所属类目 |
| 地域 | 帖子所属地域 |
| 历史点击次数 | 帖子历史被点击次数 |
| 历史ctr | 帖子历史点击率 |
| Word2vec | 帖子向量 |
| 其他 | 其他帖子特征 |
| 帖子特征 | 含义 |
|---|
| 地域 | 用户所处地域 |
| 用户兴趣 | 用户历史兴趣特征 |
| 其他 | 其他用户特征 |
| 用户特征 | 含义 |
|---|
| 用户地域-帖子地域 | 用户所处地域与帖子所属地域匹配度 |
| 兴趣类目-帖子类目 | 用户兴趣中类目与帖子类目匹配度 |
| 兴趣地域-帖子地域 | 用户兴趣中地域与帖子地域匹配度 |
| 其他 | 其他用户-帖子特征 |
| 用户-帖子特征 | 含义 |
|---|
离线向量化特征
2013 年 Google 开源词向量计算工具 -Word2Vec[6],该模型通过浅层神经网络训练之后的词向量可以很好的学习到词与词之间的相似性,并在学术界、工业界得到了广泛应用。
这种通过低维稠密向量表示高维稀疏特征的表达方式非常适合深度学习。Embedding 思想从 NLP 领域扩散到其他机器学习、深度学习领域。与句中的词相类似,用户在 58 同城全站行为数据中 Item 则同样可进行 Embedding 从而得到帖子的低纬稠密特征向量。全站行为可以指用户的点击行为序列,也可以指用户的转化行为序列。因此点击率预估任务则可以通过 Word2Vec 得到帖子向量表示以及用户向量表示。
Word2vec 可以根据给定的语料库,通过优化后的训练模型快速有效地将一个词语表达成向量形式。Word2Vec 训练向量一般分为 CBOW(Continuous Bag-of-Words) 与 Skip-Gram 两种模型。CBOW 模型的训练输入是上下文对应的词向量,输出是中心词向量,而 Skip-Gram 模型的输入是中心词向量,而输出是中心词的上下文向量。
帖子向量的训练数据来源于用户行为日志中抽取出的点击曝光日志,各个业务场景下每天会出现用户更新以及新发布的帖子,训练帖子向量的数据使用用户最近 7 天的点击转化行为数据。
针对业务对用户行为数据进行处理,首先用户每次点击的停留时长小于 3s,认为是误点击或对当前帖子不感兴趣,则将当前点击从行为序列中剔除;保留点击数据,去除微聊、收藏和打电话行为数据,将每条点击数据按用户 id 聚合并按点击转化时间排序;用户行为序列中前后两次行为超过 3 小时的认为兴趣已经发生改变,对数据进行切分,生成新的行为序列。
样本构建之后需要针对样本需要进行负采样,负采样流程是对所有样本构建一个负采样序列,对于租房业务来说对于用户点击的一条位于北京房源随机采样到长沙的一个房源作为负样本。
长沙的房源显然是一条合格的负样本,但是为了让同城内正负样本更具有区分性,针对负采样流程做了以下优化,对每个词也就是帖子记录城市、local 信息,词频平滑处理,分城市对同城内的词频求和;拼接多个城市的负采样序列作为最终的负采样序列,同时记录每个城市负采样区间的起始和结束位置;同城内负采样序列按照词频占比越高所占区间越长的规则构建,记录当前中心词所在点击序列的所有出现的词,作为正样本,不进行负采样;负采样时,获取中心词的城市,传入当前城市在负采样序列中的采样起始下标和结束下标,在当前城市区间内进行随机取样;负样本的 local 不等于中心词的 local,且负样本没有在中心词的点击序列中出现过,即成功采样负样本,否则继续负采样;对每个负样本的采样次数限制在 10 次之内,超过 10 次即在同城内随机负采样。
考虑到用户的转化行为也是一个更重要的行为特征,在训练向量的过程中加入合理的正样本使得相关的向量更相似,比如保留点击、微聊和打电话行为数据,用户的微聊和打电话行为相较于点击行为有更强烈的的喜好,可用于生成正样本;记录序列中每个帖子的行为及对应的时间戳,遍历当前序列,记录微聊和打电话行为发生的时间戳以及对应帖子所在的位置下标,若中心词位置在最近一次的微聊或打电话行为之前。
考虑到用户的兴趣在某个时间段内有连续性,将间隔时间设置在 15 分钟之内,在这个时间范围内的点击可以认为对之后发生的微聊和打电话行为有间接影响,将下一次的微聊或点击作为当前中心词的正样本;为了避免产生噪音数据,限制中心词和微聊帖或打电话帖的地域信息相同或价格区间相同,满足条件后作为正样本进行训练。
用户行为特征
图 9 用户行为定义
58 同城全站用户行为一般包含点击和转化,转化则是指收藏、微聊、电话,图 9 展示了租房、二手车、二手房、招聘业务中收藏、微聊/在线聊、电话、申请职位所在详情页的位置。
基于对用户行为的分析以及首页推荐场景多业务融合的特点,从用户角度出发,考虑到用户一般对于发布帖子本身以及帖子所在位置关注度比较高,最终将帖子 ID、类目 ID、区域 ID作为用户行为属性进行 Embedding 编码。
特征的分布式表示在深度学习特征工程中至关重要,组合以上三类 ID 特征通过模型 Embedding 层获得低纬稠密的帖子向量表示,最终可通过 Attention 或者其他相似度度量方式等计算出当前待排序帖子和用户历史点击帖子的相关程度,从而使得模型学习到用户关注点。
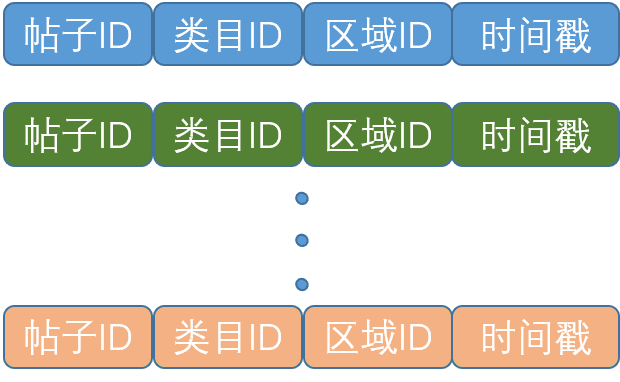
图 10 用户行为特征
离线用户行为数据是将全站用户行为特征按时间戳排序(如图 10 所示)保存在 HDFS 中,其中单个用户行为包含帖子 ID、类目 ID、区域 ID、时间戳等基础信息,最终在离线训练和在线预估中选择使用用户最近 N 条行为特征,通过模型将这些基础信息进行embedding编码。离线向量化特征则是通过用户行为序列中的帖子 ID 序列使用 Word2vec 训练所得。对于用户行为中帖子 ID 的 embedding 向量可以在模型中通过 end2end 的方式训练得到,也可以通过加载预训练向量在模型中加载使用。
离线样本

图 11 样本特征
整个离线样本处理流程如图 11 所示,包含用户行为特征,基础特征。由于训练样本数据数量级已达到亿级别,为了加快模型离线训练速度我们对训练样本采用两种负采样方法进行采样:
随机负采样,即一次曝光的帖子列表中用户未点击的样本按照自定义正负样本比例进行采样;
自定义采样,即保留一次曝光帖子列表中用户最后一次点击之前的未点击样本作为负样本。
深度学习模型要求输入样本不可以存在缺失值,因此需要补全策略,我们针对样本中出现的每一种类别特征设置了一个 ID 为 0 的 Embedding 标记该特征为缺失值,对于连续特征目前将缺失值设置为 0,后期会继续进行缺失值补全策略的实验,比如平均值、中位数等。
离线训练
使用离线样本生成流程我们将所有样本通过 MapReduce 保存在 HDFS,使用 TensorFlowDataSet 等 API 可直接读取 HDFS 上的离线数据,对于 DNN、DIN、DIEN 模型我们实现了单机以及分布式版本,目前单机版本已在线上使用,分布式版本还在优化过程中。
模型离线训练优化初期可通过 tensorboard 监控训练过程中的 accuracy、loss 等指标(图 12),通过监控可以看出模型已收敛,模型正常训练上线之后不再使用 TensorFlow 的 summary API 可减少部分离线训练时长。
此外,模型中如果使用到 tf.layers.batch_normalization 时应特别注意其中的 training 参数,并且在训练过程中需要更新 moving_mean、moving_variance 参数,保存PB模型时则需要将BN层中的均值和方差保存,否则在 serving 阶段取不到参数时直接使用均值为 0、方差为 1 的初始值预测,出现同一条样本在不同的 batch 中不同打分的错误结果。
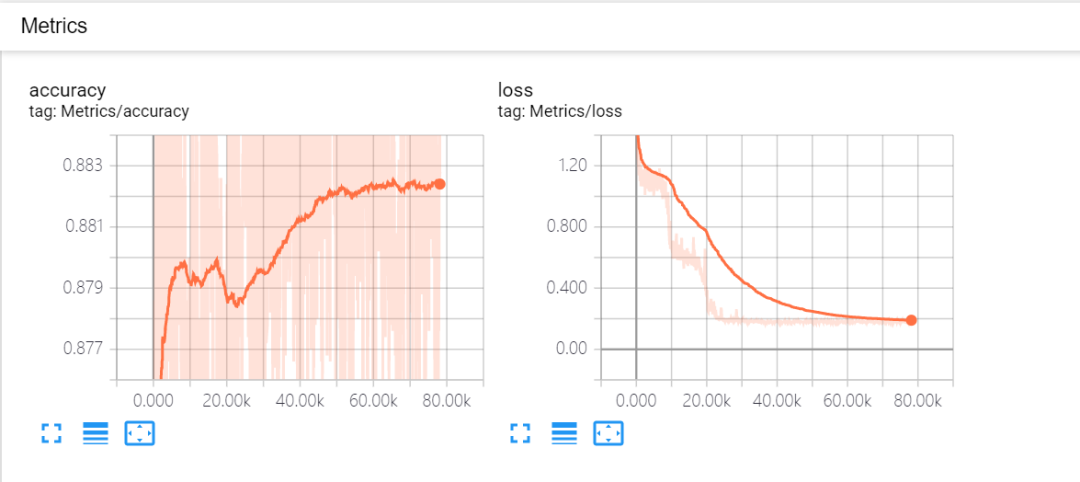
图 12 Accuracy、Loss 变化曲线
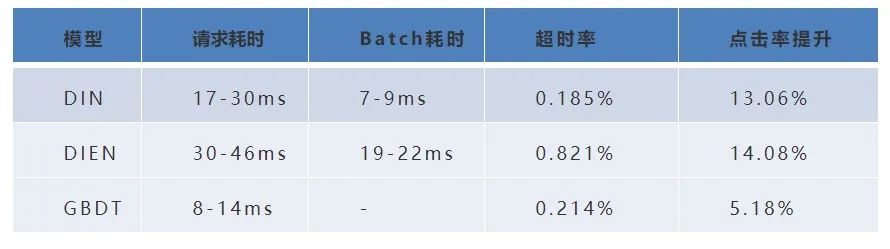
下表为 GBDT、DIN、DIEN 的离线效果,可见 DIN、DIEN 均已超过传统机器学习模型。接下来我们将介绍线上实验部分。
| GBDT | 0.634 |
| DIN | 0.643 |
| DIEN | 0.651 |
| 模型 | AUC |
|---|
排序服务
用户实时行为数据构建,离线数据已经保存在 HDFS,线上则是通过实时解析 kafka 消息将用户实时行为保存在分片 Redis 集群中,单天可产生亿级别的用户行为数据,用户行为特征基本解析流程可参考图 1。
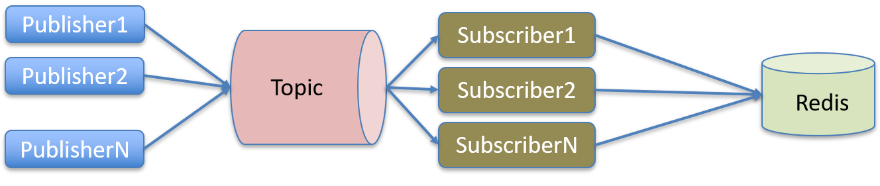
图 13 实时用户行为特征解析
特征抽取部分实现了帖子信息、用户兴趣、用户行为的特征并行处理,首页场景线上一次排序请求约 120 条帖子,为降低 TensorFlow-Serving 单节点 QPS 同时考虑单次排序请求的整体耗时,我们将一次排序请求拆分成多个 batch 并行请求深度学习模型打分服务(图 14)。
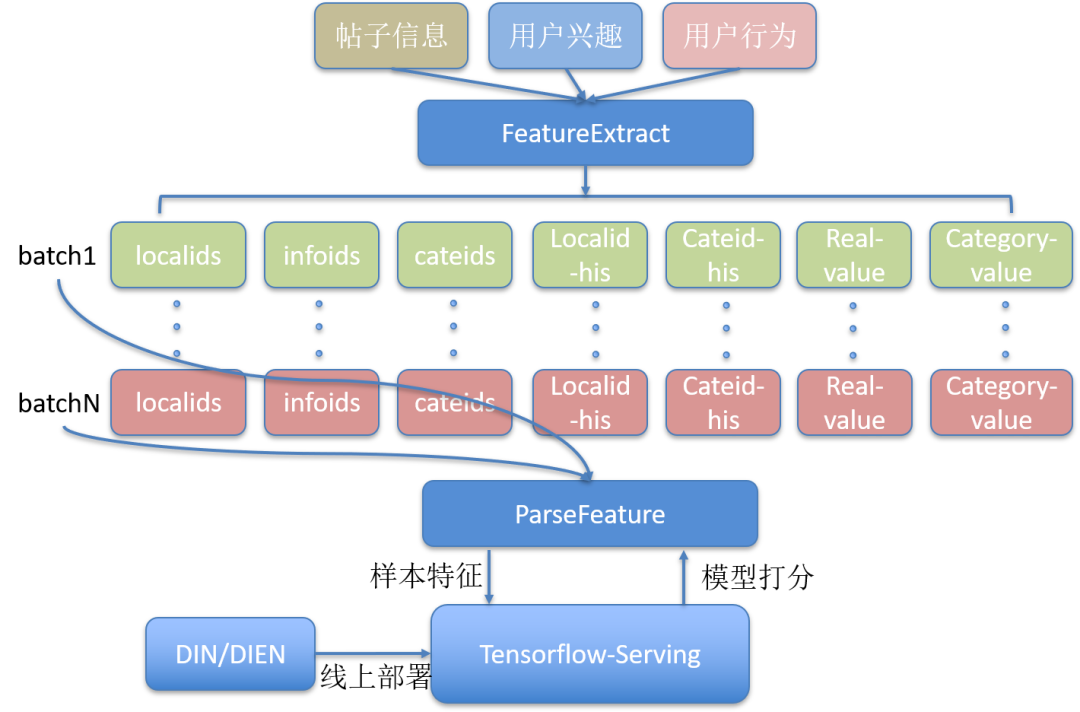
图 14 多 Batch 请求 TensorFlow-Serving
在测试环境下我们进行了排序耗时评估,发现 batch 为 2,10,20 平均耗时差距约为 10ms,随着 batch 增加,一次可打分帖子量增加,则 tensorflow-serving 各节点 QPS 会降低。
上线后对耗时日志进行统计,通过分析耗时统计结果(图 15),99% 以上的请求均低于 22ms 最终权衡排序总耗时之后将线上 batch 设置为 20。
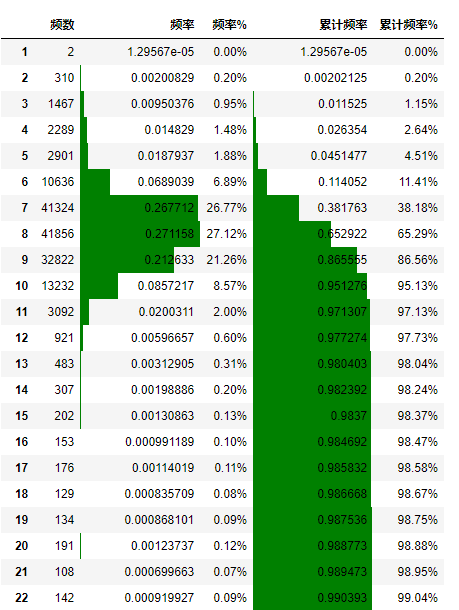
图 15 线上单个 batch 请求耗时分布
通过线上耗时监控,DIN 模型每个 batch 平均耗时 6-9ms(图 16 左),DIEN 每个 batch 平均耗时19-22ms(图 16 右)均已满足线上耗时限制。
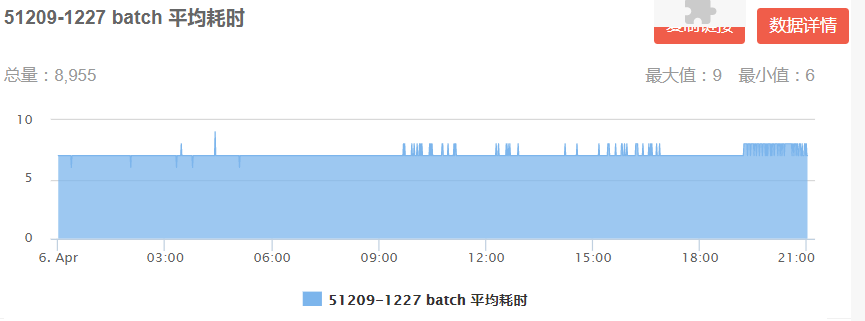
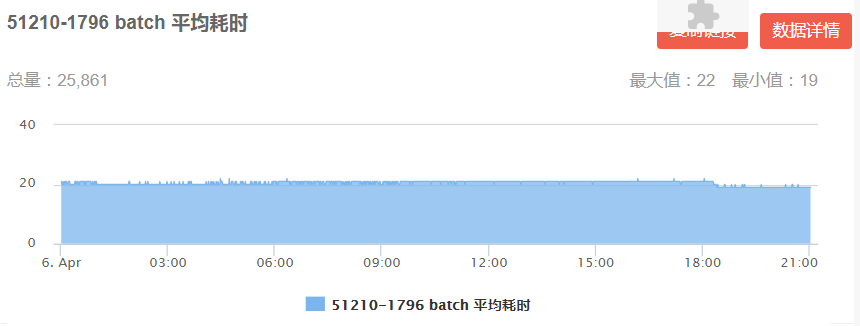
图 16 DIN/DIEN 线上 Batch 平均耗时
首页场景下 DIN、DIEN 模型排序实验阶段,在小流量测试阶段 TensorFlow-Serving 服务 QPS 峰值可达几千时,服务请求量及耗时量指标可参考图 17。
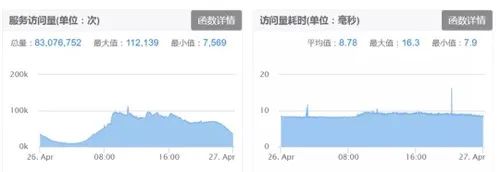
图 17 DIN/DIEN 线上 Tensorflow-serving 请求量及耗时
实验总结
实时/截断用户行为特征
模型上线之后发现离线 AUC 高于线上最优 GBDT 模型,但是线上点击率却低于 GBDT,排查之后定位问题出现在实时行为特征部分。
离线样本生成过程会使用曝光时间戳去截取用户历史行为特征,但是线上则是通过 kafka 实时解析用户行为,通过监控解析 kafka 写入 Redis 发现存在部分行为数据堆积情况以及实时日志上传 kafka 存在延迟。用户行为数据达到 8000 万左右(图 18 左)时,大于两分钟写入 Redis 的数据已经存在 500 万左右(图 18 右)。
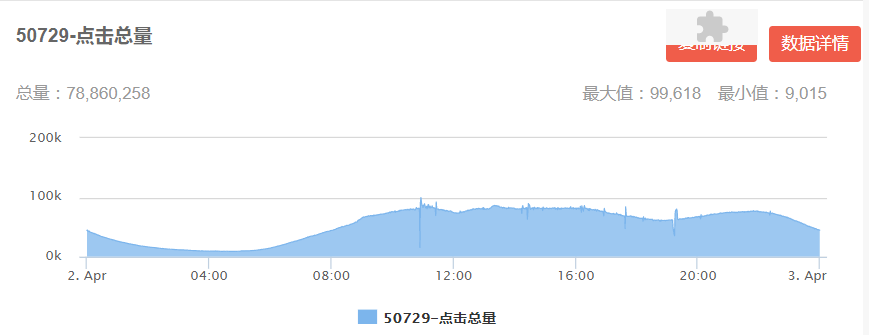
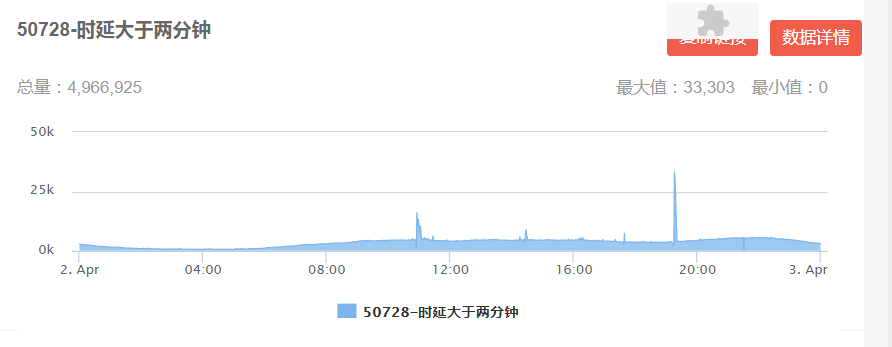
图 18 kafka 解析用户实时行为监控
因此通过线上监控统计后初步断定为行为特征时间穿越问题,因此对线上线下的用户点击行为特征按照统计的时间进行截断并进行线上 AB 实验,1819(DIN)、1820(DIEN) 算法号直接读取线上实时行为特征,1227(DIN)、1796(DIEN) 算法号则通过设置时间间隔进行截断。
通过图 19,20 我们可以发现线上(实验号 1227)线下用户行为特征进行两分钟截取时间后线上点击率比通过曝光时间戳截取(实验号 1819)有 2%-4% 的提升,1796 则比 1820 有 5%-8% 的提升。
通过线上 AB 实验表明模型使用实时性要求比较高的用户行为特征时对于是否存在时间穿越问题需要重点关注,当然这个问题也可以通过增加处理 kafka 的线程数来降低消息的堆积量,不过线上线下用户行为特征是否对齐仍需要验证。
因此用户实时行为特征在 58 App 首页推荐场景下需要根据实际业务数据设置时延,保证线上线下实时用户行为特征一致。
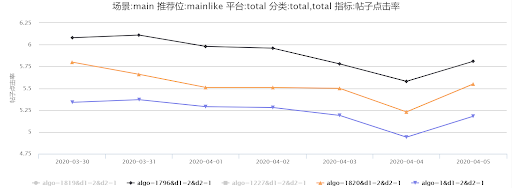
图 19 DIEN- 验证行为特征时间穿越
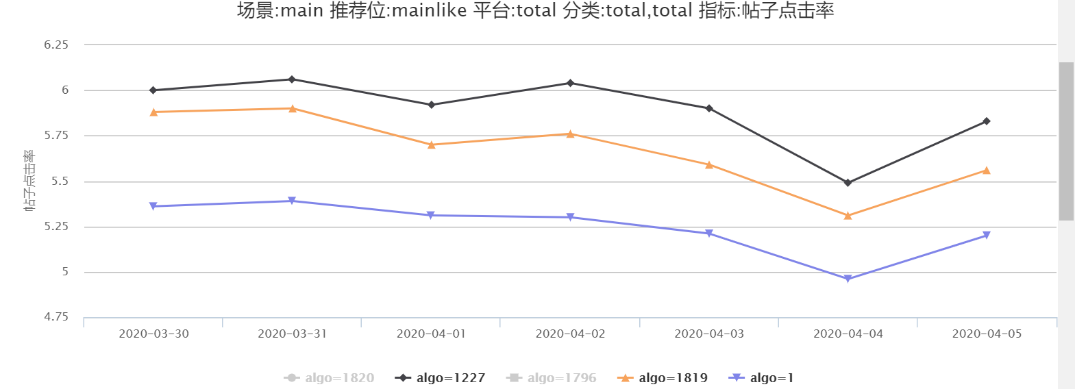
图 20 DIN- 验证行为特征时间穿越
使用 Word2Vec 向量
离线向量特征部分提到我们使用 Word2Vec 模型对用户行为特征中的帖子进行离线预训练得到了帖子的 Embedding 向量。
对于 Word2Vec 向量的使用可分为两种,一种是离线预训练,之后在模型 Embedding 层中用户行为特征部分的 infoid 加载预训练向量,一种是将预训练的帖子向量作为连续特征直接输入 DNN 使用,在接下来的实验中我们优先使用第二种方式进行,后期会继续使用第一种方法进行线上实验。
图 21-22 中可见对于使用 Word2Vec 向量的 1209(DIN)、1222(DIEN)比未使用 Word2Vec 向量的 1227(DIN)、1796(DIEN) 均有 1.5%-4.3% 的提升。
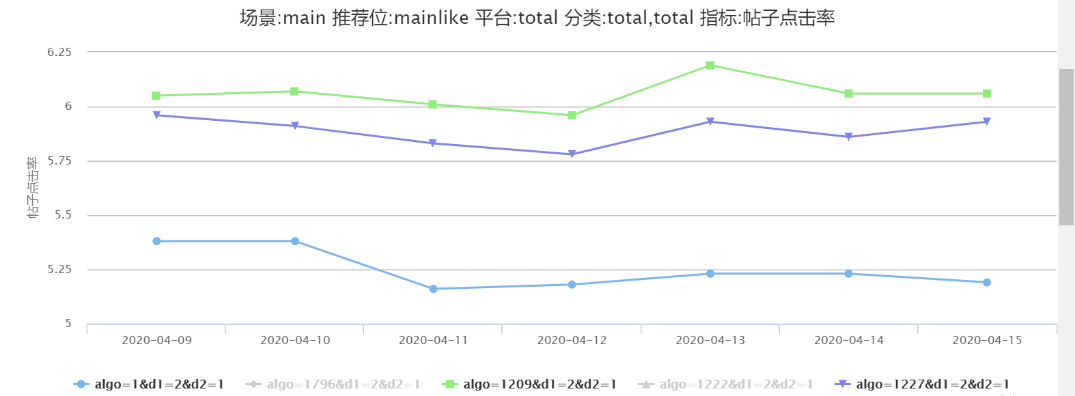
图 21 DIN- 是否使用 Word2Vec 向量
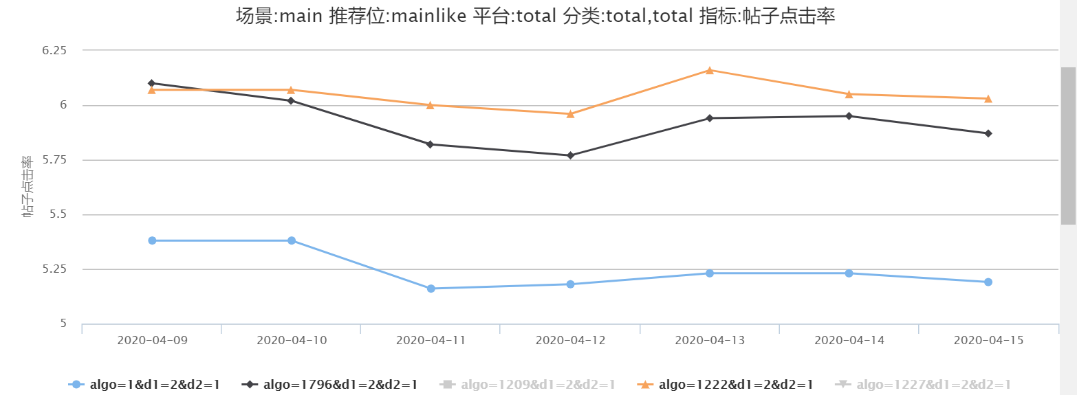
图 22 DIEN- 是否使用 Word2Vec 向量
以上实验为上线初期的部分数据,目前线上点击率实验中DIN比基线周平均提升 13.06%,曝光转化率提升 16.16%;DIEN 相比基线曝光转化率提升 17.32%,均已超过线上最优 GBDT 模型, DIEN 模型已全量部署,目前各模型线上指标可参考下表。
总结与展望
通过团队协作打通基于用户兴趣相关的深度学习模型离线训练、线上打分流程,将 58 App 中丰富的用户行为数据成功应用到深度学习模型,并能够提升首页推荐点击率,从而达到提升用户体验,提升平台效率的目的。
用户行为数据中的每一个帖子对于当前要推荐的帖子的相关程度是不一样的,不可一概而论。注意力机制将用户序列 Embedding 加和平均改成加权平均,使得推荐模型可以学习到用户关注点。
用户行为是与时间顺序相关的序列,序列模型可以用来学习用户行为的演化过程,可以用于预测用户下一次的行为。前期的离线实验包括目前的线上效果能够证明通过对用户兴趣建模可以捕捉到用户关注点以及动态的兴趣变化。
目前深度学习已经在 TEG- 推荐技术团队内部负责的各个场景进行实验,当然还有一些待优化的事情,比如离线分布式训练及复杂深度学习模型线上性能。
还有一些特征层面的实验工作,比如对于用户行为特征,不局限于帖子 id、类目 id、地域 id、用户行为序列长度扩增等、帖子向量和用户向量交叉等。
在模型层面,对其他 Attention 结构进行实验、DNN 部分考虑使用残差网络、通过 Graph Embedding 等生成帖子向量、线上支持其他深度学习排序模型等。
责任编辑:lq
-
Google
+关注
关注
5文章
1713浏览量
56790 -
算法
+关注
关注
23文章
4455浏览量
90753 -
深度学习
+关注
关注
73文章
5237浏览量
119908
原文标题:社区分享 | 深度学习在 58 同城首页推荐中的应用
文章出处:【微信号:tensorflowers,微信公众号:Tensorflowers】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

一文详解机器学习和深度学习的区别

深度学习在医学图像分割与病变识别中的应用实战
深度学习服务器怎么做 深度学习服务器diy 深度学习服务器主板用什么
深度学习的七种策略








 工商网监
工商网监
评论