 英特尔推出金字塔型的数据存储架构,使得数据更加靠近CPU和GPU
英特尔推出金字塔型的数据存储架构,使得数据更加靠近CPU和GPU
数据的海量增长如今已成为共识,随着5G、AI、物联网技术和应用的发展,人们还发现越来越多的数据需要及时有效地收集,整理,分析和再利用,数据处理得越早越能体现其作用和价值,并产生洞察。
例如针对当前全球肆虐的新型冠状病毒,科学家越早收集病例信息、越早通过AI进行筛查,就能越早地分析和提炼出诊断方案并加速疫苗研发。同时,让数据在AI数据管道中经历采集、准备、训练和推理,更需要海量的数据存储,海量的算力和有效的算法,因为这些数据不仅来源复杂,数量庞大,格式也是杂乱多样的。
在早期,很多数据都是传回数据中心进行梳理和分析。在5G发展起来之后,随着人们对于数据实时处理的需求的增加,就越发需要实现存储和计算在边缘的融合。
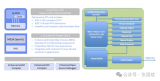
鉴于人们对于存储和计算融合的需求越来越强烈,英特尔推出金字塔型的数据存储架构,既通过英特尔傲腾技术让更多的数据靠近处理器,以获取及时的洞察,又能实现大容量的数据存储,让整个数据基础架构的投资成本在可控的范围之内。
英特尔基于数据需求推出的金字塔型的数据存储架构,从最上面的DRAM,英特尔傲腾持久内存,到下面的SSD、HDD和磁带,其中傲腾持久内存可以提供超高的性能和超低的延迟,使得数据更加靠近CPU和GPU,以便获得及时的洞察。英特尔傲腾固态盘以及以英特尔为代表的TLC、QLC等大容量、高性能的NAND固态盘则更适合作为温热存储或者温存储。基于此,我们可以根据不同的工作负载对数据进行冷热分层,然后根据性能、成本、及功耗的预算,来不断地优化性能。
今年是英特尔在中国35年,作为高科技公司,英特尔一直在积极探索前瞻性技术和技术创新驱动的能力,并在一次一次的产业浪潮发展中得到了验证。在不久前,英特尔首次提出“智能X效应”,这一效应的背后是如今越来越多智能的物连接起来,势必将带来指数级的数据量爆炸,同时推动跨越不同产业的庞大的业务,形成促进经济发展的新的创新模式。
面对这样的趋势,英特尔中国研究院院长宋继强提出针对AI时代,对于数据处理的需求几乎是实时的,英特尔对此在存储技术创新的战略之一便是近内存计算——将数据在存储层级向上移动,使其更接近处理单元进行计算。这将是未来数据处理最迫切的需求,特别是AI计算。近内存计算单元,包含乘加器和单独的静态内存,能让内存和计算资源更紧密地结合在一起。
同时,这种近内存计算单元可以构成分布式计算架构,使大规模数据处理的效率大幅攀升。
英特尔中国区非易失性存储解决方案事业部战略业务开发总监倪锦峰告诉至顶网,传统的数据计算方式需要把数据迁移到CPU,会消耗很多CPU资源和DRAM的资源。而英特尔最新展示的近内存计算技术是把计算和存储更好地融合在一起,使得存储和计算更加靠近。“近内存计算可以有多种创新的实现方式,其中之一便是用FPGA加上Intel的NVM存储架构在一起,很好地解决类似的实时计算要求,比如压缩、解压缩、AI训练等。实时存储和计算问题的架构,一是可以解决数据的时效性问题,二是解决CPU资源以及DRAM的资源损耗问题。”
面对未来对于实时数据处理的业务场景,我们可以看到英特尔基于金字塔型的存储架构为各种复杂的工作负载提供了持续的、可靠的且按需扩展的灵活多变的解决方案。包括近内存技术以及英特尔傲腾技术结合3D NAND的技术来满足像AI、物联网等低时延、高性能的工作负载需求;英特尔的傲腾持久内存及英特尔傲腾固态盘使数据可以更加靠近CPU;而英特尔QLC 3D NAND固态盘,以其出色的更高的容量密度以及优异的性价比为海量数据存储提供各种解决方案。
责任编辑:gt
-
英特尔
+关注
关注
60文章
9421浏览量
168808 -
数据
+关注
关注
8文章
6511浏览量
87595 -
存储
+关注
关注
12文章
3856浏览量
84660
发布评论请先 登录
相关推荐
X-Silicon发布RISC-V新架构 实现CPU/GPU一体化
英特尔五款优秀的CPU介绍




TC275如何设置XCP的标定数据区,使得数据擦除时不会影响应用程序的运行?
传英特尔明年推出的Lunar Lake CPU将由台积电代工


安装OpenVINO工具套件英特尔Distribution时出现错误的原因?
被砍,推迟,命运多舛的英特尔GPU产品线
英特尔媒体加速器参考软件Linux版用户指南
英特尔放弃同时封装 CPU、GPU、内存计划
英特尔、AMD、英伟达GPU架构的区别分析






 工商网监
工商网监
评论