异构信息网络构建的推荐系统新算法研究
在这个信息多到快要爆炸的时代,推荐系统在其中承担了重大的责任。不仅能让用户更快地获取有用的信息,同时也给厂商带来了另一中的推广方式,为厂商创造巨大的商业价值,现在许多的互联网公司都会有自己的目推荐团队来从事推荐算法的研究,旨在提升自己的业务效果。
传统的推荐系统中,最常见的方法就是「协同过滤」,典型的例子就是我们在电商网站见到的「购买该商品的用户也购买了/也在看」。协同过滤方法一般包括两种方式,即基于用户和基于商品的协同过滤,以及矩阵分解 (Matrix Factorization)。自从 2007 年 Netflix 百万大奖的推荐系统比赛以来,矩阵分解的方法开始变得流行。尽管矩阵分解可以获得不错的推荐效果,但也有明显的问题:
1)稀疏性(Sparsity)。现实生活里的评分矩阵往往非常稀疏,因为单个用户评分的商品是非常少的;
2)冷启动(Cold Start)。新产生的用户和商品往往都没有评分。
上述两种情况都会严重影响矩阵分解的预测准确性。
除了这两个基本的问题以外,矩阵分解还有一个更严重的问题:它很难适应现在的推荐系统。因为当下的推荐系统需要处理的特征并非只有评分信息,而是各种各样的信息(称作 Side Information),比如商品的描述,图片,用户的好友关系等。我们可以看图 1 的例子,这是 Yelp 上一个餐馆的详情页。
图 1:Yelp 上的一个详情页,Royal House
从图中,我们可以看到,除了评分信息之外,还有餐馆的地理位置,用户上传的图片,评论等信息。显然,在给用户推荐餐馆的过程中,这些信息都非常重要,但它们又很难融入到现有的矩阵分解的模型中。因此,我们需要一个全新的框架来解决这样的问题。这是我们此次 KDD 工作的核心思想:「我们用 HIN 来对 side information 进行建模,同时设计了一套有效的算法框架,从而获得更好的推荐效果」。
算法框架
预备知识
异构信息网络 (Hetegeneous Information Network 以下简称 HIN),是由 UIUC 的 Han Jiawei 和 UCLA 的 Sun Yizhou 在 2011 年的 VLDB 论文中首次提出 [1]。
简单地理解,HIN 就是一个有向图,图中的节点和边都可以有不同的类型,如下图,是一个从上面 Yelp 详情页抽取出来的 HIN。节点可以代表不同类型的实体,比如 user, review, restaurant 等, 边代表不同类型的关系,比如 Check-in, Write, Mention 等。
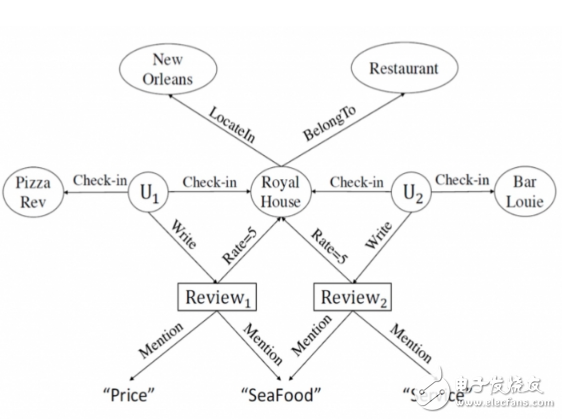
利用 HIN,我们就可以将各种各样的 side information 统一起来,接下来我们将介绍如何在 HIN 这个框架下完成我们的推荐过程。
从meta-path到meta-graph
在Sun Yizhou的VLDB2011的论文中,除了提出HIN,同时也提出了meta-path,用来计算两个节点之间的相似度。meta-path就是一个节点的sequence,节点与节点之间由不同类型的边连接,也就是不同的关系。
比如从上图中的HIN,我们可以设计meta-path:
它表示的意义就是两个用户在同一个餐馆签到。
我们可以提取一条meta-path的实例:
那我们可以衡量和 Bar Louie 之间的相似度,当有越多的meta-path实例来连接和 Bar Louie,它们之间的相似度就越大,我们也会可以给推荐 Bar Louie。我们可以发现,这条 meta-path 正好对应我们熟悉的「基于用户的协同过滤」,即经常去 Royal House 的人也会去 Bar Louie。
从这个例子我们可以看出,对于推荐系统来说,HIN和meta-path有两个好处:
1) 非常完美地将各种side information融入到一个统一的模型;
2)利用meta-path,可以设计出各种各样的推荐策略,除了推荐准确性提升之外,还能提供「可解释性」。
当然,在计算节点相似度这个任务上,meta-path也有自己的问题:「无法处理复杂的关系」。比如两个用户之间有如下连接性。
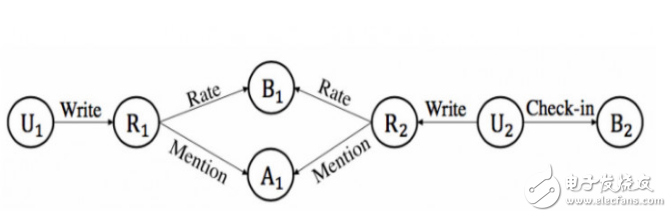
对应到图上的实例, 和 分别给 Royal House 写了一个评论,不仅给了五星好评,还在评论里同时提到了这里的「Seafood」,可以说这两个用户对餐馆的偏好非常相似。但是这样一种相似性,meta-path 无法对其进行建模。为了解决这个问题,有两篇论文 ( KDD 16 [2] 和 ICDE 16 [3]) 提出了一种更为通用通用的结构: meta-graph(也叫 meta-Structure)。相比 meta-path 要求必须是 sequence 的结构,meta-graph 只要求「一个起点和一个终点,中间结构并不限制」,这样大大提升了灵活性。因此,在我们的 KDD 论文中,我们采用了 meta-graph 这样一种结构,来计算用户和商品之间的相似度。在实践中,我们可以设计 条 meta-graph,从而得到多种商品和用户之间的相似度,也就是 个相似度矩阵。
推荐过程: 矩阵分解(MF) + 分解因子机(Factorization Machine)
通过HIN和mega-graph,我们完美地将各种各样的side information统一到一个框架中。接下来的问题就是「如何设计更好的推荐算法」。在这个论文里,我们用到了「MF + FM」的框架,简单来说: 分别对个相似度矩阵进行矩阵分解,得到组用户和商品的隐式特征,然后将所有的特征拼起来,使用分解因子机进行训练和评分预测。
对于一个样本,即用户-商品对,我们分别可以得到组特征,每组的维度为(在矩阵分解的时候,我们设定秩为)。那么我们就可以拼出下图中所以的一个维度为的特征向量。
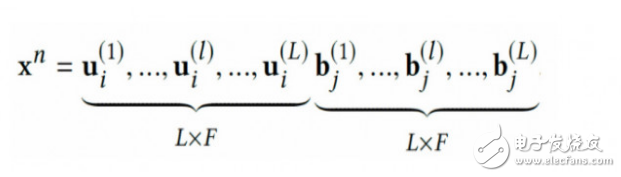
Factorization Machine (FM) [4] 是 2010 年在 ICDM 上提出一种模型,由于可以对特征之间的高阶关系进行建模,以及对二阶参数进行低秩分解,因而在评分预测这个推荐任务上取得了非常好的效果。在实践中,我们一般使用二阶关系:
其中,是一阶参数,是二阶参数。为了学出 和,我们使用了 Least Squared loss:
特征选择: Group Lasso
一般在 FM 的训练过程中,往往也会加上和的正则项来防止过拟合,用的最多的就是 。但是,在我们的工作中,由于我们会设计多条 meta-graph,并不是每条 meta-graph 都有用,为了自动选择出有用的 meta-graph,我们放弃了,而选择,也称作 group lasso。在我们的算法框架中,我们是以 meta-graph 为单位来构造用户和商品的隐式特征的,因此,每条 meta-graph 对应一组用户和商品的隐式特征。一旦某条 meta-graph 没有用,那么它对应的一组特征都应该被去掉,这就是我们采用 group lasso 来做正则项的动机。
使用 group lasso 正则项之后,目标函数优化就变成了一个非凸非光滑(non-convex, non-smooth)的问题,我们使用了邻近梯度算法(proximal gradient)算法来求解它。
以上就是我们的算法框架,接下来,我们将通过部分实验结果,来证明我们算法的优势。
实验结果
数据集和评估标准
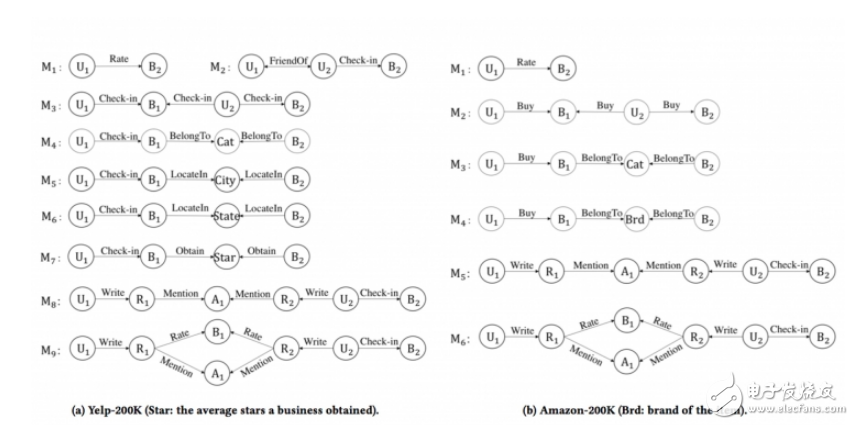
我们使用了 Yelp 和 Amazon 这两个数据集,这两个都是非常经典的推荐系统数据集,同时也包含了丰富的 side information。数据的具体统计数据,可以参看我们的论文,这里只展示我们用到的 meta-graph,如下图。在 Yelp 上,我们设计了 9 条 meta-graph,在 amazon 上,我们设计了 6 种 meta-graph。
在推荐系统中,我们一般用来评估评分预测的好坏,越小意味着推荐效果越好。
其中,是实际评分,是预测评分,是 test set 的个数。
推荐效果
在实验中,我们和一些常见的方法相比,包括基于矩阵分解和基于HIN的方法。具体结果如下图:
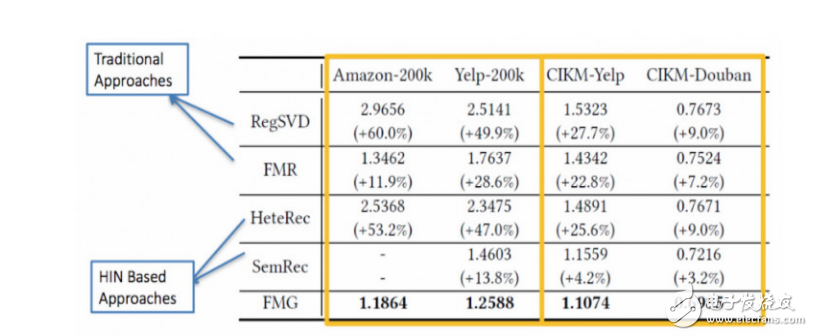
上图中,RegSVD 和 FMR 是基于矩阵分解的方法,HeteRec [5] 和 SemRec [6] 分别是 WSDM14 和 CIKM15 上的两篇论文,在 HIN 上用 meta-path 来进行推荐,FMG 是我们的算法。另外,CIKM-Yelp 和 CIKM-Douban 两个数据集是 CIKM15 的作者 Shi Chuan 提供给我们的。根据上图,我们有以下发现:
在所有的数据集上,FMG 打败了所有的方法,推荐效果取得了不同程度的提升,证明了我们算法的有效性。
在 CIKM-Yelp 和 CIKM-Douban 这两个数据集,我们使用和 CIKM15 一样的 meta-path,依然取得了 4.2% 和 3.2% 的提升,进一步证明在 HIN 这个框架下,我们推荐算法的有效性。
在两种基于 HIN 的方法中,我们发现 SemRec 比 HeteRec 的效果好不少。除去推荐算法的差异,一个重要的不同就是,在 SemRec 中,作者设计了 U→∗←U→B 这样形式的 meta-path,而在 HeteRec,作者使用了 U→B←∗→B 这样形式的 meta-path。在我们的算法中,最终选择出来有效的 meta-graph,大多就是 U→∗←U→B 这样的形式。这个发现非常有意思,说明通过「用户协同」的推荐结果效果会更好一些。这个发现也和现实生活中对应,我们获取感兴趣的商品或者餐馆,除了兴趣本身之外,更多的时候是通过朋友圈里好友推荐而发现。它反过来也能解释 SemRec 好于 HeteRec。
总结
近些年,由于移动互联网和大数据的发展,现在的推荐系统面临丰富side information场景,传统的基于矩阵分解的方法已经很难再发挥作用,而基于人工设计的特征工程又极其费劲。通过HIN和meta-graph,我们提供了一种简单有效的框架,既能够非常灵活地利用side information来提升推荐效果,同时,还能利用人工设计的meta-graph来保留必要的语义信息,从而对推荐结果提供一定的「可解释性」。通过实验,我们也证明了这个框架的有效性。
非常好我支持^.^
(2) 100%
不好我反对
(0) 0%
相关阅读:
- [电子说] 如何设计一种安全的、最优的车载异构网络系统 2022-05-10
- [电子说] 专访UCloud周健:更近距离的了解UCloud在异构网络下的SDN创新历程 2020-10-27
- [安全设备/系统] 加油站视频指挥调度解决方案实现异构网络与多业务的融合 2020-08-08
- [移动通信] 基于一种可以适用于多种异构网络场景的下一代网络协议New IP介绍 2020-04-14
- [电子说] 基于深度学习的智能社会媒体挖掘 2018-12-14
- [电子说] 浅谈L2触发的异构网络 2018-08-31
- [电子说] KeyStone II架构应对异构网络挑战 2018-08-31
- [电子说] 基于晶格量化的异构网络视频联合信源信道编码方法 2018-05-04
( 发表人:黄昊宇 )