在Spark Streaming中实现快速状态流处理
大小:0.5 MB 人气: 2017-10-12 需要积分:1
在Spark 1.6 中,我们通过使用新API mapWithState极大地增强对状态流处理的支持。该新的API提供了通用模式的内置支持,而在以前使用updateStateByKey 方法来实现这一相同功能(如会话超时)需要进行手动编码和优化。因此,mapWithState 方法较之于updateStateByKey方法,有十倍之多的性能提升。在本博文当中,我们将对mapWithState方法进行深入讲解,同时提前感受后续新版本中将加入的特性。
使用mapWithState方法进行状态流处理
Spark Streaming中最强大的特性之一是简单的状态流处理API及相关联的本地化、可容错的状态管理能力。开发人员仅需要指定状态的结构和更新逻辑,Spark Streaming便能够接管集群中状态的分发、管理,在程序出错时自动进行恢复并提供端到端的容错保障。尽管现有DStream中updateStateByKey方法能够允许用户执行状态计算,但使用mapWithState方法能够让用户更容易地表达程序逻辑,同时让性能提升10倍之多。让我们通过一个例子对mapWithState方法的优势进行阐述。
假设我们要根据用户历史动作对某一网站的用户行为进行实时分析,对各个用户,我们需要保持用户动作的历史信息,然后根据这些历史信息得到用户的行为模型并输出到下游的数据存储当中。
在Spark Streaming中构建此应用程序时,我们首先需要获取用户动作流作为输入(例如通过Kafka或Kinesis),然后使用mapWithState 方法对输入进行转换操作以生成用户模型流,最后将处理后的数据流保存到数据存储当中。
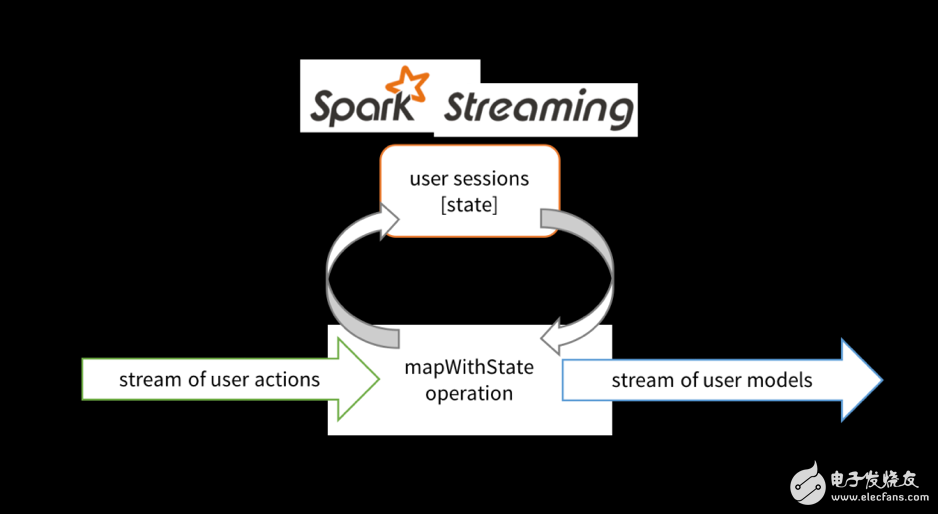
在Spark Streaming中使用状态流处理进行用户会话维护
mapWithState方法可以通过下面的抽象方式进行理解,假设它是将用户动作和当前用户会话作为输入的一个算子(operator),基于某个输入动作,该算子能够有选择地更新用户会话,然后输出更新后的用户模型作为下游操作的输入。开发人员在定义mapWithState方法时可以指定该更新函数。
现在让我们转入到具体代码来说明,首先我们定义状态数据结构及状态更新函数:
def stateUpdateFunction( userId: UserId, newData: UserAction, stateData: State[UserSession]): UserModel = { val currentSession = stateData.get()// 获取当前会话数据 val updatedSession = 。..// 使用newData计算更新后的会话 stateData.update(updatedSession) // 更新会话数据 val userModel = 。..// 使用updatedSession计算模型 returnuserModel // 将模型发送给下游操作 }
然后,在用户动作DStream上定义mapWithState 方法,通过创建StateSpec对象来实现,该对象中包含所有前述指定的操作。
// 用去动作构成的Stream,用户ID作为key val userActions = 。..// key-value元组(UserId, UserAction)构成的stream // 待提交的数据流 val userModels = userActions.mapWithState(StateSpec.function(stateUpdateFunction))
mapWithState的新特性和性能改进
通过前面的例子,我们已经明白其使用方式,现在让我们再深入理解使用该新的API所带来的特定优势。
1. 原生支持会话超时
许多基于会话的应用程序要求具备超时机制,当某个会话在一定的时间内(如用户没有显式地注销而结束会话)没有接收到新数据时就应该将其关闭,与使用updateStateByKey方法时需要手动进行编码实现所不同的是,开发人员可以通过mapWithState方法直接指定其超时时间。
userActions.mapWithState(StateSpec.function(stateUpdateFunction).timeout(Minutes(10)))
除超时机制外,开发人员也可以设置程序启动时的分区模式和初始状态信息。
2. 任意数据都能够发送到下游
与updateStateByKey方法不同,任意数据都可以通过状态更新函数将数据发送到下游操作,这一点已经在前面的例子中有说明(例如通过用户会话状态返回用户模型),此外,最新状态的快照也能够被访问。
val userSessionSnapshots = userActions.mapWithState(statSpec).snapshotStream()
变量userSessionSnapshots 为一个DStream,其中各个RDD为各批(batch)数据处理后状态更新会话的快照,该DStream与updateStateByKey方法返回的DStream是等同的。
3. 更高的性能
最后,与updateStateByKey方法相比,使用mapWithState方法能够得到6倍的低延迟同时维护的key状态数量要多10倍,这一性能提升和扩展性可从后面的基准测试结果得到验证,所有的结果全部在时间间隔为1秒的batch和相同大小的集群中生成。
下图比较的是mapWithState 方法和updateStateByKey 方法处理1秒的batch所消耗的平均时间,在本例中,我们为同样数量(从0.25~1百万)的key保存其状态,然后以同样的速率(30k个更新/s)对其进行更新,如下图所示,mapWithState方法比updateStateByKey方法的处理时间快8倍,从而允许更低的端到端延迟。
非常好我支持^.^
(0) 0%
不好我反对
(0) 0%