雅虎机器学习平台CaffeOnSpark解读
大小:0.3 MB 人气: 2017-10-10 需要积分:1
标签:机器学习平台(6067)
Andy Feng是Apache Storm的Committer,同时也是雅虎公司负责大数据与机器学习平台的副总裁。他带领雅虎机器学习团队基于开源的Spark和Caffe开发了深度学习框架CaffeOnSpark,以支持雅虎的业务团队在Hadoop和Spark集群上无缝地完成大数据处理、传统机器学习和深度学习任务,并在CaffeOnSpark较为成熟之后将其开源(https://github.com/yahoo/CaffeOnSpark)。Andy Feng接受《程序员》记者专访,从研发初衷、设计思想、技术架构、实现和应用情况等角度对CaffeOnSpark进行了解读。CaffeOnSpark概况
CaffeOnSpark研发的背景,是雅虎内部具有大规模支持YARN的Hadoop和Spark集群用于大数据存储和处理,包括特征工程与传统机器学习(如雅虎自己开发的词嵌入、逻辑回归等算法),同时雅虎的很多团队也在使用Caffe支持大规模深度学习工作。目前的深度学习框架基本都只专注于深度学习,但深度学习需要大量的数据,所以雅虎希望深度学习框架能够和大数据平台结合在一起,以减少大数据/深度学习平台的系统和流程的复杂性,也减少多个集群之间不必要的数据传输带来的性能瓶颈和低效(如图1)。
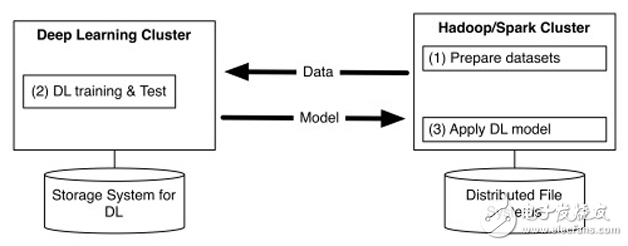
图1 深度学习集群与大数据集群分离的低效
CaffeOnSpark就是雅虎的尝试。对雅虎而言,Caffe与Spark的集成,让各种机器学习管道集中在同一个集群中,深度学习训练和测试能被嵌入到Spark应用程序,还可以通过YARN来优化深度学习资源的调度。
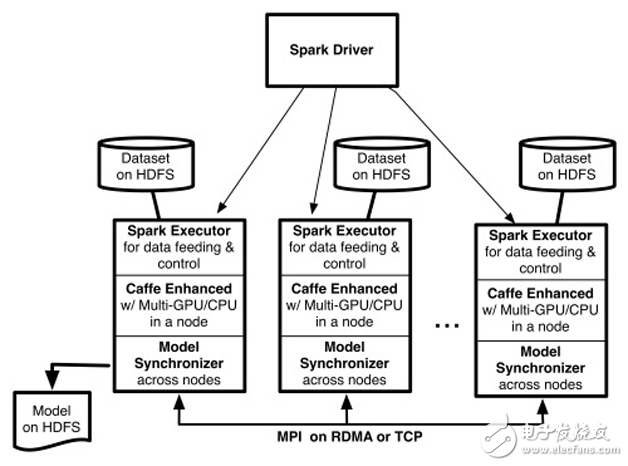
图2 CaffeOnSpark系统架构
CaffeOnSpark架构如图2所示,Spark on YARN加载了一些执行器(用户可以指定Spark执行器的个数(–num-executors 《# of EXECUTORS》),以及为每个执行器分配的GPU的个数(-devices 《# of GPUs PER EXECUTOR》))(Executor)。每个执行器分配到一个基于HDFS的训练数据分区,然后开启多个基于Caffe的训练线程。每个训练线程由一个特定的GPU处理。使用反向传播算法处理完一批训练样本后,这些训练线程之间交换模型参数的梯度值,在多台服务器的GPU之间以MPI Allreduce形式进行交换,支持TCP/以太网或者RDMA/Infiniband。相比Caffe,经过增强的CaffeOnSpark可以支持在一台服务器上使用多个GPU,深度学习模型同步受益于RDMA。
考虑到大数据深度学习往往需要漫长的训练时间,CaffeOnSpark还支持定期快照训练状态,以便训练任务在系统出现故障后能够恢复到之前的状态,不必从头开始重新训练。从第一次发布系统架构到宣布开源,时间间隔大约为半年,主要就是为了解决一些企业级的需求。
CaffeOnSpark解决了三大问题
《程序员》:在众多的深度学习框架中,为什么选择了Caffe?
Andy Feng:Caffe是雅虎所使用的主要深度学习平台之一。早在几个季度之前,开发人员就已将Caffe部署到产品上(见Pierre Garrigues在RE.WORK的演讲),最近,我们看到雅虎越来越多的团队使用Caffe进行深度学习研究。作为平台组,我们希望公司的其它小组能够更方便地使用Caffe。
在社区里,Caffe以图像深度学习方面的高级特性而闻名。但在雅虎,我们也发现很容易将Caffe扩展到非图像的应用场景中,如自然语言处理等。
作为一款开源软件,Caffe拥有活跃的社区。雅虎也积极与伯克利Caffe团队和开发者、用户社区合作(包括学术和产业)。
《程序员》:除了贡献到社区的特性,雅虎使用的Caffe相对于伯克利版本还有什么重要的不同?
Andy Feng:CaffeOnSpark是伯克利Caffe的分布式版本。我们对Caffe核心只做了细微改动,重点主要放在分布式学习上。在Caffe的核心层面,我们改进Caffe来支持多GPU、多线程执行,并引入了新的数据层来处理大规模数据。这些核心改进已经加入了伯克利Caffe的代码库,整个Caffe社区都能因此而受益。
非常好我支持^.^
(0) 0%
不好我反对
(0) 0%
下载地址
雅虎机器学习平台CaffeOnSpark解读下载
相关电子资料下载
- GTC23 | 阿里云机器学习平台 PAI 精选演讲推荐 1680
- 在微软云机器学习平台Azure ML上利用OpenVINO快速实现AI推理 629
- NVIDIA Modulu物理机器学习平台的功能 797
- 火山引擎机器学习平台与NVIDIA加深合作 619
- 云端机器学习平台PAI最新的创新实践 739
- GTC2022大会黄仁勋:Triton支持各类机器学习平台 1154
- 深兰科技智能大健康产品入驻山东 达闼打造融合智能机器学习平台 1557
- 如何建设机器学习平台,该如何去做 1205
- MathWorks入选 2021年Gartner《数据科学和机器学习平台魔力象限》并荣膺领导者称号 1988
- 华邦电子最新推出 GoAI 2.0 机器学习平台 1307