声纹识别技术在身份认证方面的应用分析
虚拟引擎
时变问题
人的整个发声系统随着时间的推移会产生一定的变化,这些变化直接导致了其语音信息中的声纹信息的变化,如果算法或系统不考虑这些变化,那么一段时间后,系统的识别性能将有所下降。为此我们录制了长达4年的100人的时变语音库,基于此语音库分析,我们找到了和时变相关的一些特征信息和规律,并试用其对MFCC和PLP特征的提取过程进行了修改。另外在工程方面,以声密保系为例,其在架构设计中就考虑到了模型的在线更新问题,并设计了专门的语音筛选算法,系统会定期的挑选用户符合条件的最新语音进行模型的重新训练。
噪音问题
正如软件工程中所提的没有银弹的概念一样,任何技术都有一定的局限性,不可能无限制地应用于任何场景,声纹技术在大噪音环境下并不适用。针对此我们开发了一套语音质量检测的库来对环境噪音和语音的信噪比进行检测,将不符合条件的语音排除在系统之外并对用户进行提示。此套噪音检测系统采用了传统的基于能量、包络、自相关系数等特征的检测算法和RNN/LSTM相结合方法,能准确的检测出96%以上不符合条件的场景。
防录音重放攻击措施
在解决这些传统问题的同时,为了保证用声纹进行远程身份认证的安全性,我们还提出了一系列防攻击措施,包括动态密码语音、用户自定义密码、多特征活体检测和录音重放等。由于篇幅有限,下面详细介绍我们在录音重放上的工作。
录音重放是一种常见的声纹特征盗取手段,由于采用动态密码的方式,很难将一个人的各种发音组合全部录制下来。但我们还是假设如果把这个人所有的文本发音(在声密保系统中为0~9的数字发音)全部录下来,然后根据系统提示的数字密码进行拼接重放,那么还是同一个人的声音,是否能够通过声纹识别系统验证呢?
我们先分析一个典型的录音重放过程:
正常语音信号:y(t)=x(t)*a(t)
录音重放语音信号:y’(t)=x(t)*a’(t) *d’(t)*a(t)
图5中录音ADCs(模数转换)和重放DACs(数模转换)是对语音信号的两次传输,均会对原始信号产生影响,且ADCs和DACs是非连续可逆的,除了ADCs和DACs外,传输过程还包括噪音、混响等因素,录音重放会造成信道失配和信号强度衰减等现象。
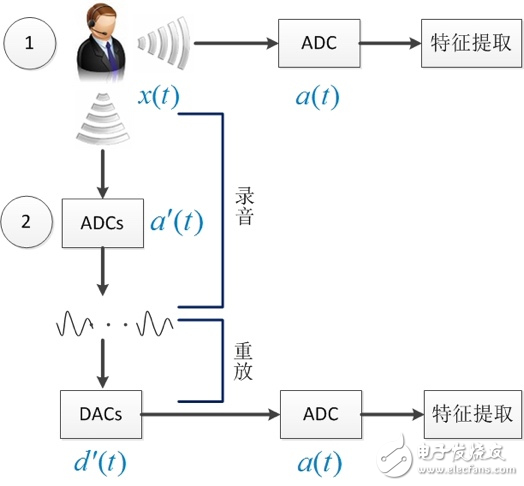
图5 典型的录音重放过程
图6给出了一段真实语音和其录音重放后语音的时频分析,可以看出在这种情况下真实语音和录音重放语音很难被区分,录音重放可以说是最容易实施和最难被检测的假体攻击方式。
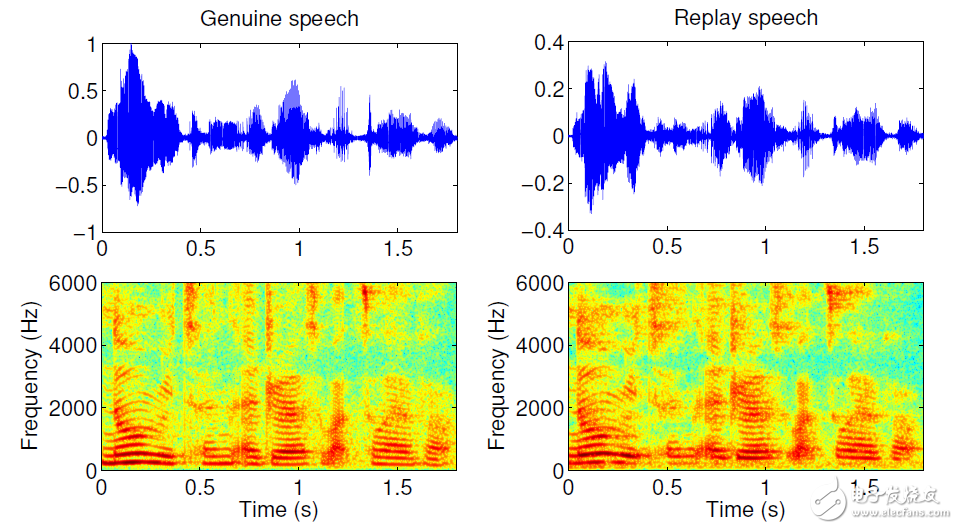
图6 一段真语音和录音重放语音的时频分析
2017年的Automatic Speaker Verification Spoofing and Countermeasures (ASVspoof) Challenge中,首次将录音重放检测纳入到说话人识别的防闯入比赛中,一个理想的录音重放检测系统应该在已知和未知的条件下都很鲁棒,包含与训练数据不同的说话人、不同的录音重放内容和不同的录音重放设备。ASVspoof针对录音重放检测进行的比赛中,全球近100个团队参加,最终提交了49个,我司的结果排在第5。相关的声纹确认防录音论文发表在Interspeech上。
《A Study on Replay Attack and Anti-Spoofing for Automatic Speaker Verification》论文主要分两部分:第一部分分析了不同的说话人、文本和设备对录音重放检测性能的影响;第二部分给出了有效的录音重放检测算法实现。
论文用F-ratio来分析不同因素对重放检测性能的影响。F-ratio是一个简单的频域加权方法,频带的权重可以由其对任务的判别能力决定。假设在分析语音谱时采用的滤波器个数为M,第i个滤波器的F-ratio可以定义为:
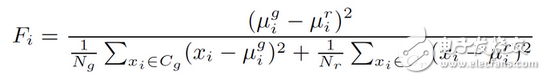
Cg表示真实语音,Cr表示重放语音。xi表示第i个滤波器语音帧x的值,uig和uir分别是滤波器内真实语音和重放语音所有帧的均值,Ng和Nr分别是两类语音的语音帧数。最后用M个滤波器的F-ratio值组[F1,F2,…,FM]来分析真实语音和重放语音在不同频带上的区分性。
在ASVspoof中,开发集和测试集中含有比训练集种类更多的录音重放设备。在训练集中利用少量设备的录音重放语音进行模型训练非常容易导致过拟合,弱化了提取的特征和训练的模型的概化能力。为了提高概化能力,降低这种变化对重放检测的影响,论文采用了频率弯折的方法,如图7所示,Mel方法增强了特征在低频段的区分能力,IMel方法增强了特征在高频段的区分能力。
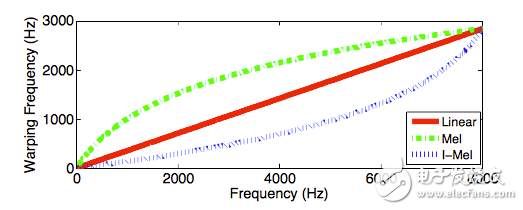
图7 三种频率弯折曲线
图8给出了在Mel和IMel两种频率弯折方法下,不同的说话人、文本内容、和录音重放设备在滤波器组上的F-ratio值,从(c)列图中可以看出用Mel方法,不同的录音重放设备对滤波器组的F-ratio值影响很明显;但是IMel方法大大降低了设备间差异对F-ratio的影响,这对后面建立概化能力更强的模型具有非常重要的意义。
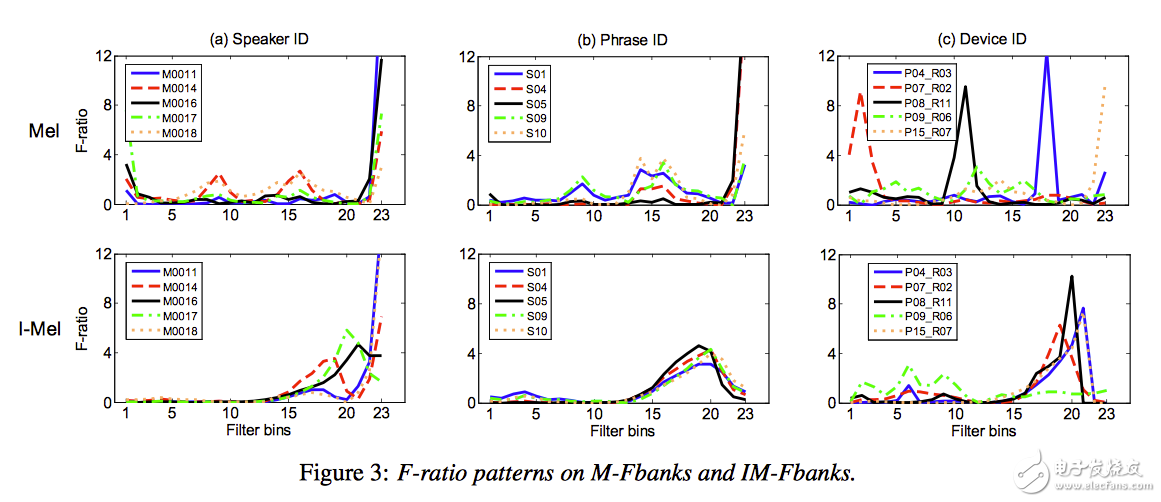
图8 Mel和IMel方法在不同的说话人、文本和设备情况下对F-ratio的影响
在录音重放检测部分,论文使用(MFCC,LPCC和IMFCC)三种特征在训练集上建立了基于GMM、ivector/SVM和DNN的重放检测系统,并在开发集中进行了测试。从下面结果可以看出IMFCC特征是最有效的,最简单的GMM模型取得了最好的效果,DNN模型虽然在表中也取得了不错的效果,但是存在不稳定的问题,不同的初始化将导致不同的结果,有的差异很大。
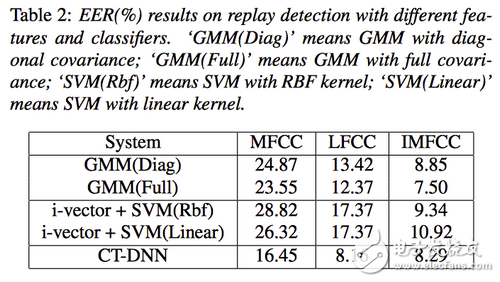
其实在日常生活中用手机进行录音重放是最方便的。相比于多样性的录音重放设备,手机等移动设备上的录音重放检测要简单的多,我们曾经对60种不同型号的手机进行了接近十万条的录音重放检测,结果重放的检出率基本为100%。
总结
声纹作为生物特征中的行为特征,配合语音识别技术,通过互动方式在远程身份认证“用自己来证明自己”方面有其他生物特征难以替代的优势。当然,就像前面提到的任何技术都有一定的局限性,不可能无限制的应用于任何场景。只有通过结合声纹和其他生物特征组成多因子认证手段,才能更好地保证远程身份认证安全。
非常好我支持^.^
(0) 0%
不好我反对
(0) 0%
下载地址
声纹识别技术在身份认证方面的应用分析下载
相关电子资料下载
- 曙光一体化算力服务平台为声纹识别技术提供大规模算力算法服务 860
- 声纹识别技术与智慧城市建设同步发展 2561
- 人工智能(AI)推动声纹识别技术应用落地 1533
- 六大场景 看懂声纹识别技术怎样“抗疫防疫” 1668
- 声纹识别技术能否不像其他技术那样多难 1055
- 声纹识别技术研究的方向在哪里 668
- 声纹识别技术或将成为下一个行业新风口 571
- 君林科技应邀做了《声纹识别技术及其在电梯声音监控及分析领域的应用》主题 3013
- 深度神经网络算法打造顶尖声纹识别技术 3347
- 声纹识别技术排名全球前三,快商通凭什么? 7747