基于检索结果排序的伪相关反馈
大小:0.76 MB 人气: 2017-12-13 需要积分:3
标签:排序(9628)
随着Web的普及,越来越多的用户希望从互联网上获取信息。对于目前主流的基于关键词的搜索方式,用户必须通过构造有限的查询词来表达信息需求( information need)。Carpineto等在查询扩展综述中明确指出,大多数用户喜欢构造短查询交给搜索引擎,且构造的查询词多以1-3个词居多;并且用户的查询构造本身就是一个抽象的过程,查询构造结果具有模糊性、不确定性和描述的多样性。在这种情况下,由于缺乏上下文语境,搜索引擎很难完全理解用户的查询意图,返回的结果中经常会包含大量无关或相似的文档。特别是当查询词出现歧义时,返回的文档集会偏向于某一个主题,而该主题往往并不是用户潜在查询意图。如果搜索引擎能够将与用户初始查询构造相关的信息全部返回给用户,那么,用户就可以在多个不同查询结果中找到自己最想要的结果。
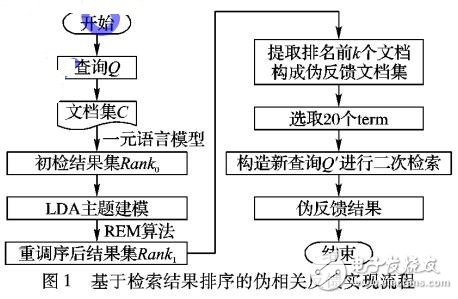
针对传统伪相关反馈(PRF)算法扩展源质量不高使得检索效果不佳的问题,提出一种基于检索结果的排序模型( REM)。首先,该模型从初检结果中选择排名靠前的文档怍为伪相关文档集;然后,以用户查询意图与伪相关文档集中各文档的相关度最大化、并且各文档之间相似性最小化作为排序原则,将伪相关文档集中各文档进行重排序;最后,将排序后排名靠前的文档作为扩展源进行二次反馈。实验结果表明,与两种传统伪反馈方法相比,该排序模型能获得与用户查询意图相关的反馈文档,可有效地提高检索效果。
非常好我支持^.^
(0) 0%
不好我反对
(0) 0%