深度解读AlphaGo
大小:0.5 MB 人气: 2017-10-12 需要积分:1
AlphaGo与李世石的对战已经进行了四局。前三局世人惊叹于AlphaGo对李世石的全面碾压,很多人直呼人类要完。因为被视为人类智能的圣杯-围棋,在冷酷的机器(或者是疯狂的小狗)面前变成了唾手可得的普通马克杯,而人类的顶尖棋手似乎毫无还手之力。3月12号的第四局,李世石终于扳回一居,而且下了几手让人惊叹的好棋。特别是第 78 手,围棋吧很多人赞为 “神之一手”,“名留青史”,“扼住命运喉咙的一手”。因为这一局,围棋吧的主流舆论已经从前几天的震惊, 叹息,伤心,甚至是认为李世石收了谷歌的黑钱转变为惊喜,甚至认为李世石已经找到了打狗棒法。而人类要完党则认为这比 AlphaGo 5:0 大胜更可怕,因为这只狗甚至知道下假棋来麻痹人类,真是细思极恐。
不论怎样,AlphaGo在与人类顶尖围棋高手的对决中已经以3胜的优势锁定了胜局,李世石目前只是在为人类的尊严而战了。围棋一年前还通常被认为是 10年 内都无法被人工智能攻克的防线,然而转眼就变成了马其诺防线了。那么这场人机大战到底意味着什么?人类已经打开了潘多拉魔盒吗? AlphaGo 的胜利是否意味着人工智能的黑色方碑(图 1, 请参见电影《2001:太空漫游》)已经出现? 本文将从 AlphaGo 的原理入手逐步探讨这个问题。
一、AlphaGo 的原理
网上介绍 AlphaGo 原理的文章已经有不少,但是我觉得想深入了解其原理的同学还是应该看看 Nature 上的论文原文 “Mastering the game of Go with deep neural networks and tree search”。虽然这篇文章有 20 页,但是正文部分加上介绍部分细节的 Method 部分也就 8 页,其中还包括了很多图。个人觉得介绍 AlphaGo 的原理还是这篇最好。为了后面的讨论方便,这里对其原理做简要总结。
对于围棋这类完全信息博弈,从理论上来说可以通过暴力搜索所有可能的对弈过程来确定最优的走法。对于这类问题,其难度完全是由搜索的宽度和深度来决定的。1997年 深蓝解决了国际象棋,其每步的搜索宽度和深度分别约为 35 和 80 步。而围棋每步的搜索宽度和深度则分别约为 250 和 150 步,搜索计算量远远超过国际象棋。减少搜索量的两个基本原则是:1. 通过评估局势来减少搜索的深度,即当搜索到一定深度后通过一个近似局势判断函数 (价值函数) 来取代更深层次的搜索;2. 通过策略函数来选择宽度搜索的步骤,通过剔除低可能性的步骤来减少搜索宽度。很简单的两个原则,但难度在于减少搜索量和得到最优解之间是根本性矛盾的,如何在尽可能减少搜索量和尽可能逼近最优解之间做到很好的平衡才是最大的挑战。
传统的暴力搜索加剪枝的方法在围棋问题上长期无法有大的突破, 直到 2006年 蒙特卡洛树搜索 (Monte Carlo Tree Search) 在围棋上得到应用,使得人工智能围棋的能力有了较大突破达到了前所未有的业余 5-6 段的水平。MCTS 把博弈过程的搜索当成一个多臂老虎机问题(multiarmed bandit problem),采用 UCT 策略来平衡在不同搜索分支上的 Exploration 和 Exploitation 问题。MCTS 与暴力搜索不同点在于它没有严格意义的深度优先还是宽度优先,从搜索开始的跟节点,采用随机策略挑选搜索分支,每一层都是如此,当随机搜索完成一次后,又会重新回到根节点开始下一轮搜索。纯随机的搜索其效率是极低的,如同解决多臂老虎机的问题一样,MCTS 会记录每次搜索获得的收益,从而更新那些搜索路径上的节点的胜率。在下一轮搜索时就可以给胜率更高的分支更高的搜索概率。当然为了平衡陷入局部最优的问题,概率选择函数还会考虑一个分支的被搜索的次数,次数越少被选中的概率也会相应提高。面对围棋这么巨大的搜索空间,这个基本策略依然是不可行的。在每次搜索过程中的搜索深度还是必须予以限制。对于原始的 MCTS 采取的策略是当一个搜索节点其被搜索的次数小于一定阈值时(在 AlphaGo 中好像是 40), 就终止向下搜索。 同时采用 Simulation 的策略,从该节点开始,通过一轮或者若干轮随机走棋来确定最后的收益。当搜索次数大于阈值时,则会将搜索节点向下扩展。Wikipedia 上 MCTS 词条中的示例图(图 2)展示了 MCTS 的四个步骤:
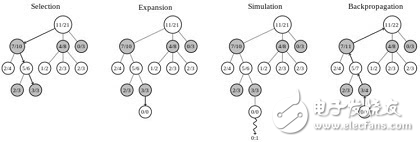
图2
1. 选择:根据子节点的胜率随机选择搜索路径。
2. 扩展:当叶子节点的搜索次数大于阈值时向下扩展出新的叶子节点(如无先验则随机选择)。
3. 仿真:从叶子节点开始随机走棋一轮或者若干轮得到终局的收益。
4. 回传:将此次搜索的结果回传到搜索路径的每个节点来更新胜率。
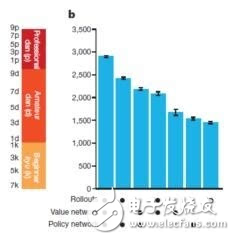
图3
AlphaGo 其基本原理也是基于 MCTS 的,其实一点也不深奥。但是 AlphaGo 在 MCTS 上做了两个主要的优化工作,使得围棋人工智能从业余水平飞跃至职业顶尖水平。这两个优化工作分别是策略网络和价值网络,这两个网络都是深度神经网络,本质上是还是两个函数。这两个网络分别解决什么问题呢?在原始 MCTS 中的选择步骤中,开始的那些搜索只能纯随机的挑选子节点,其收敛效率显然是很低的。而策略网络以当前局势为输入,输出每个合法走法的概率,这个概率就可以作为选择步骤的先验概率,加速搜索过程的收敛。而价值网络则是在仿真那一步时直接根据当前局势给出收益的估值。 需要注意的是在 AlphaGo 中,价值网络并不是取代了随机走棋方法,而是与随机走棋并行(随机走棋在 CPU 上而价值网络在 GPU 上运行)。 然后将两者的结果进行加权 (系数为 0.5)。当然 AlphaGo 的随机走棋也应该是做了大量的优化工作,可能借鉴了之前的一些围棋人工智能的工作。摘自 AlphaGo 论文的图 3 清晰展示了策略网络和价值网络如何将围棋人工智能的水平从业余水平提升到职业水平(Rollouts 就是随机走棋)。因此 AlphaGo 的精髓就是在策略网络和价值网络上。
策略网络可以抽象为, 其中 s 为当前局势,a 为走法,其实就是在当前局势下每一个合法走法的条件概率函数。为了得到这个函数,AlphaGo 采用的监督学习的办法,从 KGS Go Server 上拿到的三千万个局势训练了深达 13 层的深度神经网络。这一网络能将走法预测准确度提高到 57%。如果将这一问题看成一个多分类问题,在平均类别约为 250 个的情况下取得 57%的精确度是十分惊人的。在这个训练过程中,其目标是更看重走法对最后的胜负影响而不仅仅是对人类走法的预测精度。 这个深度学习网络的预测耗时也是相当大的(需要 3 毫秒)。为此 AlphaGo 又用更简单的办法训练了一个快速策略函数作为备份,其预测精度只有 24.2%但是预测耗时仅为 2 微秒,低 1000 个数量级。需要注意的是,AlphaGo 实际使用的策略网络就是从人类棋谱中学到的策略网络,而并没有使用通过自我对弈来强化学习获得的策略网络。这是因为在实际对战中,监督学习网络比强化学习网络效果要好。
价值网络是个当值函数,可以抽象为, 即当前局势下的收益期望函数。价值网络有 14 个隐层,其训练是通过采用强化学习策略网络 AlphaGo 的自我对弈过程中产生的局势和最终的胜负来训练这个函数。
强化学习或者说自我学习这个过程是大家对 AlphaGo 最着迷的部分,也是药丸党最忧心的部分。这个过程甚至被解读成了养蛊,无数个 AlphaGo 自我拼杀,最后留下一个气度无比的。但读完论文发现,强化学习的作用其实并没有那么大。首先是强化学习是在之前学习人类棋谱的监督学习网络的基础上进一步来学习的,而不是从 0 基础开始。其次,强化学习网络的并没有用在实际博弈中,而是用在训练价值网络中。而且在训练价值网络中,并不是只使用那条最强的蛊狗,而是会随机使用不同的狗。个人认为,强化学习在 AlphaGo 中主要是用来创造具有不同风格的狗,然后通过这些不同风格的狗训练价值网络,从而避免价值网络的过拟合。这可能是因为目前人类棋谱的数量不够用来训练足够多的水平高的策略网络来支持价值网络的训练。
二、AlphaGo 到底从人类经验中学到了什么?
个人认为,AlphaGo 有某种程度的超强学习能力,能够轻松的学习人类有史以来所有下过的棋谱(只要这些棋谱能够数字化),并从这些人类的经验中学到致胜的秘诀。但显然,AlphaGo 下围棋的逻辑从人类看起来肯定是不优美的。MCTS 框架与人类棋手的布局谋篇完全没有相同的地方,只是冷冰冰的暴力计算加上概率的权衡。策略网络学习了大量人类的策略经验,可以非常好的判断应该走哪一步,但并不是基于对围棋的理解和逻辑推理。如果你要问为什么要选择这一步,策略网络给出的回答会是历史上这种情况 90%的人都会走这一步。而策略网络呢,学习的是当前局面的胜负优势的判断,但是它同样无法给出一个逻辑性的回答,而只能回答根据历史经验,这种局面赢的概率是 60%这样的答案。有些人说,这种能力近乎人的直觉,但我觉得人类直觉的机制应该比这复杂得多,我们的直觉无法给出判断的概率, 或者说人类的思维核心并不是概率性的。AlphaGo 从大量人类经验中学到了大量的相关性的规律(概率函数),但是确没有学习到任何的因果性规律。这应该是 AlphaGo 和人类棋手最本质的区别了。
三、AlphaGo 超越了人类的智能了吗?
要回答这个问题,首先要明确超越的定义。如果说能打败人类顶尖棋手,那 AlphaGo 在围棋上的智能确实是超越了人类。 但是假设,人类再也不玩围棋了,没有更新的人类棋谱,AlphaGo 的围棋智能还能提高吗? 从前面的分析看, AlphaGo 的自我学习过程作用并不是那么大,这点我是表示怀疑的。也许人类沉淀的经验决定了 AlphaGo 能力的上界,这个上界可能会高于人类自身顶尖高手。但是当人类不能继续发展围棋,AlphaGo 的能力也就会止步不前。
从理论上来说围棋可能发生的变化数量是个 170 位数, 这是人类和计算机的能力都无法穷尽的。无论是人类的逻辑推理,还是人工智能的搜索策略,陷入局部最优是无法避免的命运。而目前 AlphaGo 的机制,决定了其肯定是跟着人类掉进坑里(某些局部最优)。如果人类不能不断的挖掘新坑(新的局部最优,或者围棋新的风格和流派),AlphaGo 能跳出老坑的可能性并不是太大。从这个意义上来说,AlphaGo 在围棋上超越人类智能应该还没有实现。
四、AlphaGo 会故意输给李世石吗?
12号这一局有人认为是 AlphaGo 故意输给李世石,或者为了保存实力,或者为了能够进入排名。但是从 Google 公开的原理来看,其显然不具备做这样决策的机制。AlphaGo 的机制就是追求当局取胜,完全没有考虑各局之间的关系,更没有人工智能伟大崛起的战略目标。 AlphaGo 故意输只是句玩笑而已。真要说故意,那也只可能是 DeepMind 中的人干的事情。
五、人类能否战胜 AlphaGo?
李世石赢了一局,围棋吧不少人都认为人类找到了克制 AlphaGo 的打狗棒法。就是不要把狗当人,不要用人的思维对待狗,我们需要大胆跳出以往的经验,去寻找神之一手。结合前面的分析,我觉得这个思路是对的。本质上 AlphaGo 是在追随人类围棋的发展,如果人类不能跳出自己的窠臼,则只会被在这个窠臼中算无遗策的 AlphaGo 碾压。人类棋手可以通过自己的逻辑推理,寻找跳出当前局部最优的方法。但这也不是一件容易的事情,跳出经验思维,更多的可能性是陷入更大的逆势,这对人的要求太高了,也只有顶尖棋手才有可能做到。而且 AlphaGo 也能够不段的学习新的经验,神之一手可能战胜 AlphaGo 一次,但下一次就不见得有机会了。AlphaGo 就如同练就了针对棋力的吸星大法,人类对他的挑战只会越来约困难。
六、AlphaGo 能干什么以及不能干什么?
DeepMind 的目标肯定不只是围棋,围棋只是一个仪式,来展示其在人工智能上的神迹。看公开报导,下一步可能是星际争霸,然后是医疗,智能手机助手,甚至是政府,商业和战争决策等领域。
Demis Hassabis 在接受 The Verge 采访时透露 DeepMind 接下来关注的核心领域将会是个人手机助手。Hassabis 认为目前的个人手机助手都是预编程的,过于脆弱,无法应变各种情况, 而 DeepMind 想通过人工智能技术,特别是无监督的自我学习方式具有真正智能的真正智能手机助手。这是因为智能手机的输入变化太多,需要巨量的训练样本才能学到有用的东西。而这正是 AlphaGo 目前主要依赖的方法。为此,Hassabis 想挑战让机器的自我学习成为主要的学习方式, 他对此充满了信心。但我认为这个问题可能不是那么好解决的,因为在 AlphaGo 中自我学习的作用是相对有限的。如果在围棋这种相对简单的环境中,自我学习的作用都相对有限,在更加复杂的环境中要能有很好的自我学习效果其挑战会更加巨大。不过从我们 TalkingData 的角度来看,把我们的海量移动端数据和监督学习技术相结合,可能更容易实现 Hassabis 的设想。
我个人期待 AlphaGo 能够创造更大的神迹,但同时也认为其应用还是有一定局限性的。因为并不是所有的实际问题都能找到这么多的训练数据。尤其在政府,商业和战争决策上,穷尽人类历史也找不到多少精确的训练集,而问题本身的复杂性又是超过围棋这种完全信息博弈的。在这种情况下,恐怕很难学到足够准确的策略网络和价值网络。这就使得 AlphaGo 的方法面对这些问题,可能是完全无法解决的。
七、AlphaGo 到底意味着什么?
虽然在围棋这一被人类自认为是智能圣杯的特定领域, AlphaGo 取得了巨大成就,但其基本机制并没有什么颠覆性的东西。要实现强人工智能的星辰大海,目前的计算机理论和技术可能只算得上工质火箭。但是 AlphaGo 所代表的人工智能突破性的发展也不能被低估,工质火箭毕竟把人类带入了太空时代。目前的人工智能在某些领域已经能够更好的学习全人类的经验的能力。也许人工智能很难创造出什么,但是至少能把人类已经达到的高度推向更高,将人类从更多的重复性劳动中解放出来,也为我们创造更好的生活,更好的环境。 AlphaGo 是人类进步史上的一个重要台阶,但是它可能并不是人工智能崛起的黑色方碑。
作者介绍:张夏天TalkingData首席数据科学家,曾在IBM中国研究院,腾讯数据平台部,华为诺亚方舟实验室任职。对大数据环境下的机器学习,数据挖掘有深入的研究和实践经验。在TalkingData负责数据挖掘和机器学习工作,为TalkingData各个产品线和服务线提供支持。
非常好我支持^.^
(0) 0%
不好我反对
(0) 0%
下载地址
深度解读AlphaGo下载
相关电子资料下载
- 碾压GPT-4!谷歌DeepMind CEO自曝:下一代大模型将与AlphaGo合体 143
- ChatGPT到底有何不同 537
- Google研发人工智能机器人AlphaGo以4即将诞生 2113
- DeepMind宣布将研发更智能的AlphaGo算法 744
- 浅谈嵌入式人工智能的发展趋势 4086
- 李世石输给谷歌AlphaGoh后,AI人工智能让自己不再是顶尖 2315
- DeepMind阿尔法被打脸,华为论文指出多项问题 2799
- 樊麾再次负于AlphaGo,以0:5完败于人工智能 3498
- 人工智能发展近70年来背后的故事 4634
- AlphaGo的横空出世让“人工智能”成为街头巷尾人人讨论的话题 971