大数据查询性能比较
大小:0.9 MB 人气: 2017-09-30 需要积分:1
我们看看小P在实时数据计算方面又有哪些卓越表现呢?
由于 Presto 卓越的性能表现,使得 Presto 可以弥补 Hive 无法满足的实时计算空白,因此可以将 Presto 与 Hive 配合使用:对于海量数据的批处理和计算由 Hive 来完成;对于大量数据(单次计算扫描数据量级在 GB 到 TB)的计算由 Presto 完成。 Presto 能够完成的实时计算实际上分为以下两种情况。
1. 快照数据实时计算
在这种情况下,可以基于某个时间点的快照数据进行计算,但是要求计算过程快速完成( 200ms~20min)。
2. 完全实时计算
要完成完全实时计算,需要满足以下两个条件。
( 1)使用的基准数据要实时更新,时刻保持与线上实际数据库中的数据完全一致。
( 2)计算过程要能够快速完成。
在某公司的实际使用场景中, Presto 被用于下述两种业务场景中。
基于 T+1 数据的实时计算
在这种业务场景中,用户并不要求基准数据的实时更新,但是要求每次查询数据都能够快速响应。需要 Presto 和 Hive 配合使用来满足实际的业务需求。每天凌晨通过azkaban 调度 Hive 脚本,根据前一天的数据计算生成中间结果表,生成完毕之后使用 Presto 查询中间结果表,得出用户最终所需要的数据。满足该业务场景的解决方案如图
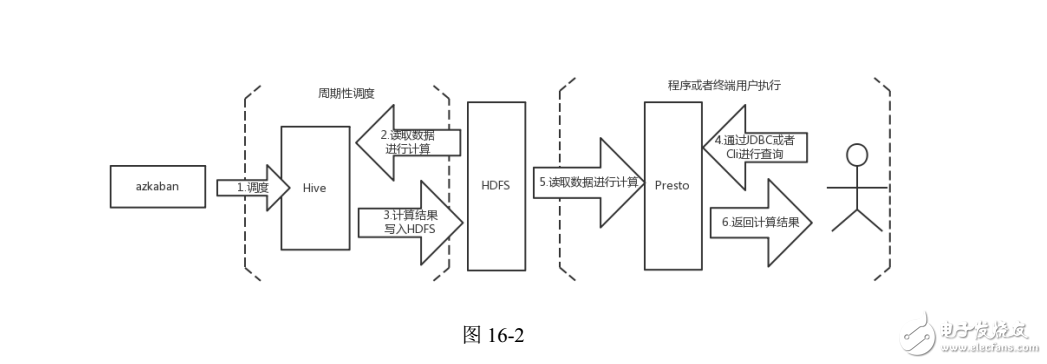
基于 RDBMS 的实时计算
在这种业务场景中,用户要求查询的数据完全实时,即只要业务库中的数据发生改变,通过 Presto 查询的时候,就可以查询到刚刚改变之后的数据。要达到这个效果,我们需要使用合理的机制保证数据实时同步,因此我们使用数据库复制技术,为线上的业务数据库建立实时同步的从库,然后用 Presto 查询数据库中的数据,进而进行计算(请注意:使用官方的 Presto 直接读取数据库的性能还太低,因此建议使用JD-Presto 中的 PDBO 从数据库中读取数据并进行计算)。满足该业务场景的解决方案如图
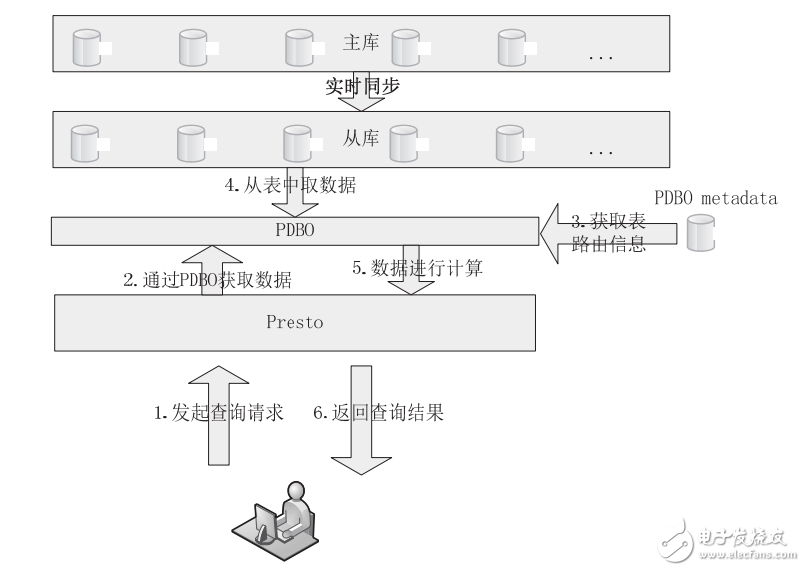
二、Ad-Hoc 查询
Ad-hoc 查询就是即席查询,即席查询允许用户根据自己的需求随时调整和选择查询条件,计算平台或者系统能够根据用户的查询条件返回查询结果或者生成相应的报表。由此可见,即席查询和普通应用查询的最大不同是:普通的应用查询是定制开发的,其查询语句是固定或者限制在一定的变动范围之内的;而即席查询允许用户随意指定或者改变查询语句或者查询条件。由于普通的应用查询都是定制开发的,其查询语句几乎是固定的,因此,在系统实施时就可以通过建立索引或者分区等技术来优化这些查询,从而提高查询效率。但是即席查询是用户在使用时临时产生的、系统无法预知的,因此也无法对这些查询进行有针对性的优化和改进。
某公司使用 Presto 完成 Ad-Hoc 查询,实际的 Ad-Hoc 使用场景包括以下两种。
( 1)使用 BI 工具进行报表展现
BI 工具通过 ODBC 驱动连接至 Presto 集群, BI 工程师使用 BI 工具进行不同维度的报表设计和展现。由于目前 Facebook 提供的 ODBC 驱动是使用 D 语言开发的,而且功能尚不完善,因此采用 Treasure Data 提供的基于 Presto-gres 中的 ODBC 驱动改造之后的 ODBC 驱动连接到 Presto 集群。
( 2)使用 Cli 客户端进行数据分析
Presto 使用 Hive 作为数据源,对 Hive 中的数据进行查询和分析。众所周知, Hive使用 Map-Reduce 框架进行计算,由于 Map-Reduce 的优势在于进行大数据量的批运算和提供强大的集群计算吞吐量,但是对稍小数据量的计算和分析会花费相当长的时间,因此在进行 GB~TB 级别数据量的计算和分析时, Hive 并不能满足实时性要求。
Presto 是专门针对基于 Ad-Hoc 的实时查询和计算进行设计的, 其平均性能Hive的 10 倍,因此 Presto 更适合于稍小数据量的计算和差异性分析等 Ad-Hoc 查询。
三、实时数据流分析
实时数据流分析主要是指通过 presto-kafka 使用 SQL 语句对 Kafka 中的数据流进行清洗、分析和计算。其在实际使用过程中有以下两种使用场景。
( 1)保留历史数据
在这种使用场景下, 由于 Presto 每次对 Kafka 中的数据进行分析时都需要从 Kafka 集群中将所有的数据都读取出来, 然后在 Presto 集群的内存中进行过滤、分析等操作, 若在 Kafka中保留了大量的历史数据, 那么通过 presto-kafka 使用 SQL 语句对 Kafka 中的数据进行分析就会在数据传输上花费大量的时间,从而导致查询效率的降低。因此我们应该避免在 Kafka中存储大量的数据,从而提高查询性能。
非常好我支持^.^
(180) 97.3%
不好我反对
(5) 2.7%
下载地址
大数据查询性能比较下载
相关电子资料下载
- R课堂 | 600V耐压Super Junction MOSFET PrestoMOS™产品阵容又增新品 214
- 虹科方案 | 虹科HiveMQ与MQTT:构建互联汽车的新架构 190
- 虹科案例 | 虹科HiveMQ支持平板电脑实现高效远程管理 160
- 虹科案例 | 虹科HiveMQ助力采埃孚推进零愿景战略 180
- 虹科案例 | 虹科HiveMQ助力实现百万辆汽车智能互联 182
- 虹科案例 | 虹科HiveMQ解决方案在奔驰汽车制造中的应用 244
- 虹科案例 | IAV 应用 HiveMQ 与汽车数据搭建城市山洪预警系统 248
- 虹科案例 | HiveMQ助力AGV小车与控制系统之间实现通信 180
- HiveMQ助力AGV小车与控制系统之间实现通信 316
- 虹科案例 | 宝马汽车共享应用程序依赖强大的HiveMQ实现可靠连接 119