TensorFlow模型介绍
模型定义
定义wide and deep模型是比较简单的,tutorial中提供了比较完整的模型构建实例:
获取输入
模型的输入是一个python的dataframe。如tutorial的实例代码,可以通过pandas.read_csv从CSV文件中读入数据构建data frame。
定义feature columns
tf.contrib.layers中提供了一系列的函数定义不同类型的feature columns:
tf.contrib.layers.sparse_column_with_XXX构建低维离散特征
sparse_feature_a = sparse_column_with_hash_bucket(…)
sparse_feature_b = sparse_column_with_hash_bucket(…)
tf.contrib.layers.crossed_column构建离散特征的组合
sparse_feature_a_x_sparse_feature_b = crossed_column([sparse_feature_a, sparse_feature_b], …)
tf.contrib.layers.real_valued_column构建连续型实数特征
real_feature_a = real_valued_column(…)
tf.contrib.layers.embedding_column构建embedding特征
sparse_feature_a_emb = embedding_column(sparse_id_column=sparse_feature_a, )
定义模型
定义分类模型:
m = tf.contrib.learn.DNNLinearCombinedClassifier( n_classes = n_classes, // 分类数目 weight_column_name = weight_column_name, // 训练实例的权重 model_dir = model_dir, // 模型目录 linear_feature_columns = wide_columns, // 输入线性模型的feature columns linear_optimizer = tf.train.FtrlOptimizer( 。。.), // 线性模型权重更新的optimizer dnn_feature_columns = deep_columns, // 输入DNN模型的feature columns dnn_hidden_units=[ 100, 50], // DNN模型的隐藏层单元数目 dnn_optimizer=tf.train.AdagradOptimizer( 。。.) // DNN模型权重更新的optimizer )
需要指出的是:模型的model_dir同下面会提到的export模型的目录是2个不同的目录,model_dir存放模型的graph和summary数据,如果model_dir存放了上一次训练的模型数据,训练时会从model_dir恢复上一次训练的模型并在此基础上进行训练。我们用tensorboard加载显示的模型数据也是从该目录下生成的。模型export的目录则主要是用于tensorflow server启动时加载模型的servable实例,用于线上预测服务。
如果要使用回归模型,可以如下定义:
m = tf.contrib.learn.DNNLinearCombinedRegressor( weight_column_name = weight_column_name, linear_feature_columns = wide_columns, linear_optimizer = tf.train.FtrlOptimizer( 。。.), dnn_feature_columns = deep_columns, dnn_hidden_units=[ 100,50], dnn_optimizer=tf.train.AdagradOptimizer( 。。.) ) 训练评测
训练模型可以使用fit函数:m.fit(input_fn=input_fn(df_train)),评测使用evaluate函数:m.evaluate(input_fn=input_fn(df_test))。Input_fn函数定义如何从输入的dataframe构建特征和标记:
def input_fn(df) // tf.constant构建constant tensor,df[k].values是对应feature column的值构成的listcontinuous_cols = {k: tf.constant(df[k].values) fork inCONTINUOUS_COLUMNS} // tf.SparseTensor构建sparse tensor,SparseTensor由indices,values, dense_shape三// 个dense tensor构成,indices中记录非零元素在sparse tensor的位置,values是// indices中每个位置的元素的值,dense_shape指定sparse tensor中每个维度的大小// 以下代码为每个category column构建一个[df[k].size,1]的二维的SparseTensor。categorical_cols = { k: tf.SparseTensor( indices=[[i, 0] fori inrange(df[k]。 size)], values=df[k].values, dense_shape=[df[k]。 size, 1]) fork inCATEGORICAL_COLUMNS } // 可以用以下示意图来表示以上代码构建的sparse tensor// label是一个 constanttensor,记录每个实例的labellabel= tf. constant(df[LABEL_COLUMN].values) // features是continuous_cols和categorical_cols的union构成的dict // dict中每个entry的key是feature column的name,value是feature column值的tensor returnfeatures, label输出
模型通过export输出到一个指定目录,tensorflow serving从该目录加载模型提供在线预测服务:m.export(export_dir=export_dir,input_fn = export._default_input_fn
use_deprecated_input_fn=True,signature_fn=signature_fn)
input_fn函数定义生成模型servable实例的特征,signature_fn函数定义模型输入输出的signature。
由于在tensorflow1.0之后export已经deprecate,需要用export_savedmodel来替代,所以本文就不对export进行更多讲解,只在文末给出我们是如何使用它的,建议所有使用者以后切换到最新的API。
模型详解
wide and deep模型是基于TF.learn API来实现的,其源代码实现主要在tensorflow.contrib.learn.python.learn.estimators中。以分类模型为例,wide与deep结合的分类模型对应的类是DNNLinearCombinedClassifier,实现在源文件dnn_linear_combined.py。 我们先看看DNNLinearCombinedClassifier的初始化函数的完整定义,看构造一个wide and deep模型可以输入哪些参数:
def __init__( self, model_dir =None, n_classes =2, weight_column_name =None, linear_feature_columns =None, linear_optimizer =None, joint_linear_weights =False, dnn_feature_columns =None, dnn_optimizer =None, dnn_hidden_units =None, dnn_activation_fn =nn .relu, dnn_dropout =None, gradient_clip_norm =None, enable_centered_bias =False, config =None, feature_engineering_fn =None, embedding_lr_multipliers =None):
我们可以将类的构造函数中的参数分为以下几组
基础参数
model_dir
我们训练的模型存放到model_dir指定的目录中。如果我们需要用tensorboard来DEBUG模型,将tensorboard的logdir指向该目录即可:tensorboard –logdir=$model_dir
n_classes
分类数。默认是二分类,》2则进行多分类。
weight_column_name
定义每个训练样本的权重。训练时每个训练样本的训练误差乘以该样本的权重然后用于权重更新梯度的计算。如果需要为每个样本指定权重,input_fn返回的features里需要包含一个以weight_column_name为列名的列,该列的长度为训练样本的数目,列中每个元素对应一个样本的权重,数据类型是float,如以下伪代码:
weight = tf .constant(df[WEIGHT_COLUMN_NAME] .values, dtype=float32);features[weight_column_name] = weight
config
指定运行时配置参数
eature_engineering_fn
对输入函数input_fn输出的(features, label)进行后处理生成新的(features’, label’)然后输入给模型训练函数model_fn使用。
call_model_fn(): feature, labels = self._feature_engineering_fn(feature, labels) 线性模型相关参数
linear_feature_columns
线性模型的输入特征
linear_optimizer
线性模型的优化函数,定义权重的梯度更新算法,默认采用FTRL。所有默认支持的linear_optimizer和dnn_optimizer可以在optimizer.py的OPTIMIZER_CLS_NAMES变量中找到相关定义。
join_linear_weights
按照代码中的注释,如果join_linear_weights= true, 线性模型的权重会存放在一个tf.Variable中,可以加快训练,但是linear_feature_columns中的特征列必须都是sparse feature column并且每个feature column的combiner必须是“sum”。经过自己线下的对比试验,对模型的预测能力似乎没有太大影响,对训练速度有所提升,最终训练模型时我们保持了默认值。
DNN模型相关参数
dnn_feature_columns
DNN模型的输入特征
dnn_optimizer
DNN模型的优化函数,定义各层权重的梯度更新算法,默认采用Adagrad。
dnn_hidden_units
每个隐藏层的神经元数目
dnn_activation_fn
隐藏层的激活函数,默认采用RELU
dnn_dropout
模型训练中隐藏层单元的drop_out比例
gradient_clip_norm
定义gradient clipping,对梯度的变化范围做出限制,防止gradient vanishing 或gradient explosion。wide and deep中默认采用tf.clip_by_global_norm。
embedding_lr_multipliers
embedding_feature_column到float的一个mapping。对指定的embedding feature column在计算梯度时乘以一个常数因子,调整梯度的变化速率。
看完模型的构造函数后,我们大概知道wide和deep端的模型各对应什么样的模型,模型需要输入什么样的参数。为了更深入了解模型,以下我们对wide and deep模型的相关代码进行了分析,力求解决如下疑问: (1) 分别用于线性模型和DNN模型训练的特征是如何定义的,其内部如何实现;(2) 训练中线性模型和DNN模型如何进行联合训练,训练误差如何反馈给wide模型和deep模型?下面我们重点针对特征和模型训练这两方面进行解读。
特征
wide and deep模型训练一般是以多个训练样本作为1个批次(batch)进行训练,训练样本在行维度上定义,每一行对应一个训练样本实例,包括特征(feature column),标注(label)以及权重(weight),如图2。特征在列维度上定义,每个特征对应1个feature column,feature column由在列维度上的1个或者若干个张量(tensor)组成,tensor中的每个元素对应一个样本在该feature column上某个维度的值。feature column的定义在可以在源代码的feature_column.py文件中找到,对应类为_FeatureColumn,该类定义了基本接口,是wide and deep模型中所有特征类的抽象父类。
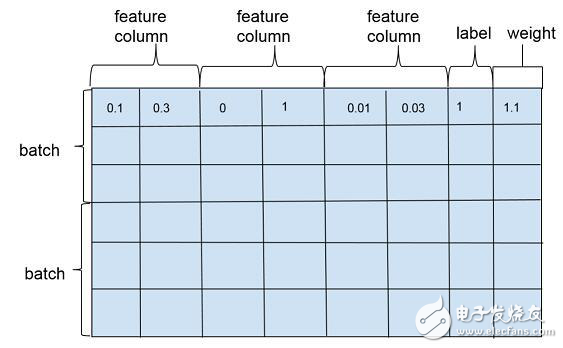
wide and deep模型中使用的特征包括两大类: 一类是连续型特征,主要用于deep模型的训练,包括real value类型的特征以及embedding类型的特征等;一类是离散型特征,主要用于wide模型的训练,包括sparse类型的特征以及cross类型的特征等。
非常好我支持^.^
(0) 0%
不好我反对
(0) 0%
下载地址
TensorFlow模型介绍下载
相关电子资料下载
- 【风火轮YY3568开发板免费体验】第六章:在Solus上运行自定义模型并迁移到YY3 411
- 深度学习框架tensorflow介绍 480
- 深度学习框架pytorch介绍 454
- 【米尔MYC-JX8MPQ评测】+ 运行 TensorFlow Lite(CPU和NPU对比) 524
- 手把手带你玩转—i.MX8MP开发板移植官方NPU TensorFlow例程 444
- 在树莓派64位上安装TensorFlow 505
- TensorFlow Lite for MCUs - 网络边缘的人工智能 339
- 2023年使用树莓派和替代品进行深度学习 1506
- 用TensorFlow2.0框架实现BP网络 1849
- 那些年在pytorch上踩过的坑 571