 Linux内核大块内存申请:从场景到落地全解析
Linux内核大块内存申请:从场景到落地全解析

一、为什么需要“大块内核内存”?
先明确场景,避免盲目选择分配方式:
1.DMA传输场景:网卡、硬盘等外设的DMA控制器,要求内存物理地址连续(无法识别虚拟地址映射),且需一次性分配大尺寸缓冲区(如1GB网络帧缓存)。
2.大型内核缓存:文件系统(如EXT4)的索引缓存、数据库内核的内存池,需要持续占用GB级内存,且需虚拟地址连续(方便指针遍历)。
3.虚拟化场景:KVM虚拟机的内存分配、容器运行时的共享内存,需为Guest OS分配大块连续内存,保障运行性能。
4.高性能设备驱动:FPGA、GPU等加速卡的驱动程序,需分配大块内存用于数据批量传输,减少IO次数。
二、3种核心申请方法(附实操代码)
Linux内核提供3种大块内存分配接口,核心差异在于“物理连续与否”和“性能开销”,需按需选择:
1. alloc_pages ():物理连续,DMA首选
•核心特点:分配2^order页的物理连续内存,返回struct page指针(需手动转换为虚拟地址),适合DMA、高性能IO等场景。
•关键参数:
◦gfp_mask:分配标志(如GFP_KERNEL允许睡眠,GFP_ATOMIC不睡眠);
◦order:分配阶数(order=0→1页,order=1→2页,…,order=10→1GB,最大order由内核配置MAX_ORDER决定,默认11→2GB)。
•示例代码:
// 分配1GB物理连续内存(order=10,假设PAGE_SIZE=4KB)structpage*page =alloc_pages(GFP_KERNEL | __GFP_ZERO,10);if(!page) {pr_err("alloc_pages failedn");return-ENOMEM;}// 转换为虚拟地址(内核虚拟地址=物理地址+PAGE_OFFSET)void*virt_addr =page_address(page);// 释放内存(必须与alloc_pages配对)__free_pages(page,10);
2. __get_free_pages ():alloc_pages封装,简化使用
•核心特点:alloc_pages的封装接口,直接返回虚拟地址(无需手动转换struct page),功能与alloc_pages完全一致,物理连续。
•示例代码:
// 分配512MB物理连续内存(order=9,4KB*512=2GB?不:order=9→512页=2GB?哦,4KB*512=2MB?纠正:4KB*2^9=4KB*512=2048KB=2MB;order=19才是2GB,需注意order计算)void*virt_addr = (void*)__get_free_pages(GFP_KERNEL | __GFP_ZERO,9);if(!virt_addr) {pr_err("__get_free_pages failedn");return-ENOMEM;}// 释放内存(与free_pages配对)free_pages((unsignedlong)virt_addr,9);
•注意:__get_free_pages是宏定义,本质调用alloc_pages,仅简化地址转换。
3. vmalloc ():虚拟连续,物理离散
•核心特点:分配虚拟地址连续、物理地址离散的大块内存,通过内核页表映射实现,适合对物理连续性无要求、但需大尺寸内存的场景(如内核缓存、低访问频率缓冲区)。
•优势:支持更大尺寸(理论无上限,受内核虚拟地址空间限制),分配成功率高于物理连续方式。
•劣势:访问需经过页表转换,性能比alloc_pages低(延迟高~20%),且不支持DMA。
•示例代码:
// 分配2GB虚拟连续内存void*virt_addr =vmalloc(2*1024*1024*1024);if(!virt_addr) {pr_err("vmalloc failedn");return-ENOMEM;}// 可选:初始化内存(vmalloc不默认清零)memset(virt_addr,0,2*1024*1024*1024);// 释放内存(必须用vfree,不能用kfree)vfree(virt_addr);
三、关键注意事项(避坑核心)
1.物理连续内存“稀缺性”:
◦order越大,分配成功率越低(系统运行越久,物理内存越碎片化),建议尽量降低order(如拆分大内存为多个小order分配)。
◦避免在中断上下文申请物理连续大块内存(GFP_ATOMIC不允许睡眠,无法等待内存碎片整理)。
1.申请失败必须处理:
◦大块内存分配失败是常态(尤其物理连续方式),需返回错误码或降级处理(如改用vmalloc),不可直接使用NULL指针。
1.释放接口必须配对:
|
申请接口
|
释放接口
|
错误用法
|
|
alloc_pages()
|
__free_pages()
|
用vfree ()释放
|
|
__get_free_pages()
|
free_pages()
|
用kfree ()释放
|
|
vmalloc()
|
vfree()
|
用free_pages ()释放
|
1.性能与场景匹配:
◦高频访问的大块内存(如DMA传输)用alloc_pages(物理连续,无页表转换开销);
◦低频访问的大内存(如内核日志缓存)用vmalloc(分配成功率高,不浪费物理连续内存)。
1.NUMA架构优化:
◦多CPU节点服务器中,用alloc_pages_node(nid, gfp_mask, order)指定节点分配,避免跨节点访问(跨节点延迟是本地的2-3倍)。
1.内存泄漏风险:
◦内核内存无GC机制,申请后必须在模块卸载、设备注销时释放,建议用devres机制(如devm_alloc_pages)自动释放,减少泄漏风险。
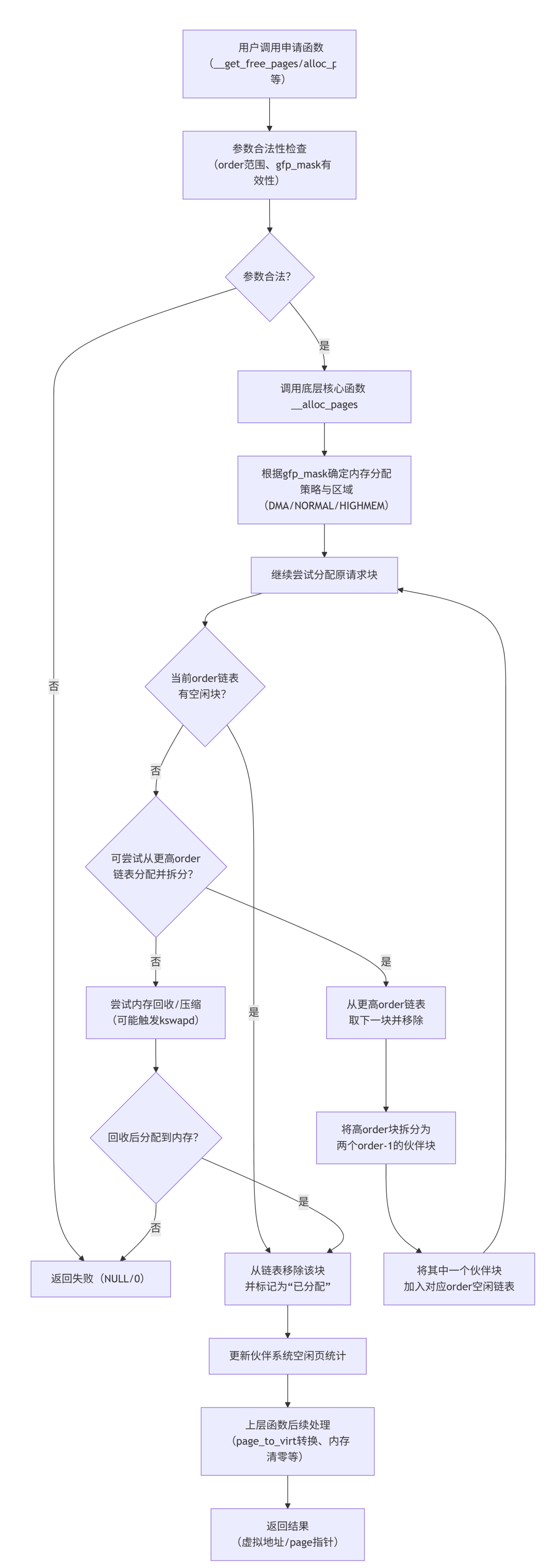
四、申请流程可视化(流程图)

五、知识脑图(快速梳理)

-
内核
+关注
关注
4文章
1479浏览量
43140 -
Linux
+关注
关注
88文章
11854浏览量
219820 -
内存
+关注
关注
9文章
3255浏览量
76590
发布评论请先 登录
Linux内核内存规整总结

Linux内核内存管理架构解析

Linux内核地址映射模型与Linux内核高端内存详解
全流程场景落地 在线测长仪多方位部署 满足各种检测需求
Linux内存系统: Linux 内存分配算法
Linux内存系统:内存使用场景
一文解析Linux内存系统
Linux内核中用GFP_ATOMIC申请内存意味着什么

Linux内核源码分析-进程的哪些内存类型容易引起内存泄漏?

Linux内核伙伴系统内存申请函数详解:从原理到实战
Linux内核三大核心模块深度解析:调度、内存与I/O




评论