 半导体缺陷检测升级:机器学习(ML)攻克类别不平衡难题,小数据也能精准判,降本又提效!
半导体缺陷检测升级:机器学习(ML)攻克类别不平衡难题,小数据也能精准判,降本又提效!

一、引言
机器学习(ML)在半导体制造领域的应用,正面临传统算法难以突破的核心瓶颈。尽管行业能产生海量生产数据,但两大关键问题始终未能有效解决:一是极端类别不平衡,二是初始生产阶段训练数据集匮乏。这两个问题在半导体测试环节尤为突出 —— 该环节芯片故障率常低于 0.5%,且新产品需在历史数据极少的情况下,实现实时质量预测。
这一问题的影响极为深远:若有缺陷的芯片(die)在早期晶圆分选测试中未被检出,会流入后续高成本加工流程(封装、最终测试),最终仍会失效,不仅造成巨额成本损失,还会导致工期延误,而更高效的早期检测算法本可完全规避此类问题;反之,若合格芯片在晶圆分选阶段被误判为不合格,也会直接造成成本浪费与产能损耗。
近期研究表明,专用机器学习方法已能突破上述限制 ——即便训练数据严重不足,仍能实现显著的性能提升。其核心在于两点:一是选择专为制造场景设计的算法,二是采用贴合实际部署场景的评估方法。
二、类别不平衡挑战深度解析
(一)制造数据不平衡的极端性
在工业领域,半导体制造是类别不平衡问题最严峻的场景之一。高良率生产环境下,芯片故障率通常低于 1%,部分产品甚至低至 0.5%;若通过软分箱(soft bin)分类法分析特定失效模式,不平衡问题会进一步加剧 —— 部分失效类型在初始数据集中完全没有样本记录。
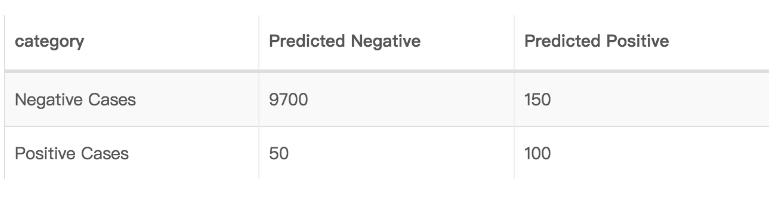
这种极端的数据偏差会直接导致传统机器学习算法 “失效”:传统模型以 “整体准确率” 为核心优化目标,若分类器对所有样本一概预测 “合格”,虽能实现 99% 以上的准确率,但二类错误(Type II Error,俗称 “漏检缺陷”)率会飙升至 100%,这类模型对实际缺陷识别毫无实用价值。
(二)制造时序的制约
半导体数据收集的 “时序性”,进一步放大了类别不平衡问题。生产数据需数月时间才能逐步积累(积累速度取决于生产爬坡率与实际产量),而在初始生产阶段,制造商亟需预测模型支撑质量决策,但此时往往缺乏足够的历史数据,根本无法训练传统机器学习系统。
这便形成了典型的 “鸡生蛋” 困境:制造商需要预测模型优化早期生产流程,而传统机器学习方法又依赖大规模均衡数据集 —— 但这类数据集在早期关键阶段完全不存在。
三、制造场景专用算法方案
(一)算法选择标准
研究团队针对 59 个生产批次(每批次含 25 片晶圆,单颗芯片的测试参数约 17500 项),开展了系统评估,最终锁定 3 类算法方案。选择核心聚焦两点:一是能有效处理类别不平衡问题,二是具备适配制造环境的计算效率。
评估框架采用双重方法设计:一是 “时间验证法”(模拟真实生产场景下的模型重训过程,贴合实际运维需求),二是传统的 5 折交叉验证(用于客观评估模型基准性能)。这种双重评估模式既确保了算法的落地实用性,又保障了评估方法的科学严谨性。
(二)现有基准分类器特性
作为基准的现有分类器(Incumbent Classifier),通过集成提升(boosting)技术,能够高效应对大规模数据集、数据缺失值与异常值问题。该方法能有效降低模型偏差,并支持增量学习 —— 这一特性对数据持续积累的制造环境至关重要(毕竟生产数据是实时新增的)。
但 boosting 算法也存在明显短板:在小数据集上极易出现过拟合现象,且训练过程需消耗大量计算资源,对制造场景的硬件配置有一定要求。
其核心性能指标如下:
具备分布式计算能力,可随生产规模扩展
支持增量学习,能实时整合新增生产数据
对数据缺失值和异常值的处理能力较强
训练阶段的计算成本相对较高
(三)基于采样的高级分类器(Classifier-A)
专用算法(分类器 A,Classifier-A)在核心架构中,创新性整合了对多数类(合格芯片样本)的随机下采样策略与少数类(缺陷芯片样本)的过采样策略。该设计专门针对半导体测试数据的极端类别不平衡问题,同时还能保持对数据异常值的鲁棒性,无需额外增加数据预处理步骤。
其核心性能优势具体体现在:
通过自动化采样实现训练数据内部平衡,全程无需人工干预,降低运维成本
借助随机特征选择降低模型方差,减少 “个别异常数据影响整体预测” 的情况
内置正则化机制,增强对数据异常值的抗干扰能力,适配制造场景的复杂数据环境
大幅减少人工超参数调优工作量,从 “反复试错” 变为 “开箱即用”,加速部署节奏
该算法通过集成技术聚焦方差优化,能显著提升模型整体准确率,尤其适配制造早期阶段的小数据集场景 —— 正好解决了 “初始生产没数据” 的痛点。
(四)传统局部信息分类器(Classifier-B)
传统机器学习方法(分类器 B,Classifier-B)依赖数据点周围的局部信息做预测决策。尽管这类方法训练速度快,且支持增量学习,但存在两大致命局限:一是处理高维测试数据时性能明显下滑(半导体测试参数多达上万项,正好命中短板),二是对数据噪声和异常值高度敏感—— 这些缺陷在制造环境中会直接导致测试准确率大幅下降,难以落地实用。
四、性能分析与实验结果
(一)AUC-ROC 性能对比
在模拟小数据集的时序验证场景下(还原初始生产阶段的数据状态),基于采样的专用分类器(Classifier-A)表现始终最优:当使用前 10 个批次的数据训练时,其中位 AUC-ROC 得分比现有基准分类器高约 2 个百分点,缺陷识别能力显著更强。
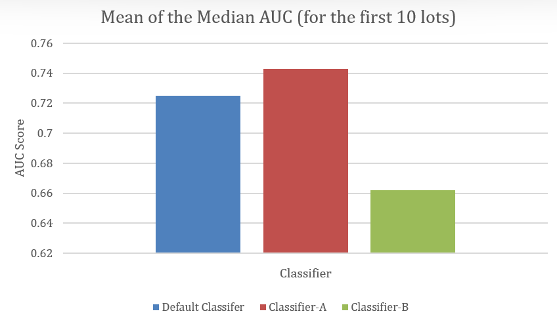
前 10 批次中位 AUC 值均值对比表(数据来源:研究实验)
更关键的是,在训练初期(数据量最少的时候),专用算法的性能优势更为显著 —— 正好匹配 “初始生产阶段最缺数据、最需要精准模型” 的场景。随着训练数据逐步增加,各算法的性能差距会有所缩小,但专用算法的优势始终稳定保持,不会出现 “数据多了反而不准” 的情况。
(二)计算效率权衡
运行时间分析结果显示,算法的训练速度与推理性能之间存在明显的权衡关系,具体表现为:
Classifier-B:训练速度最快,但推理速度最慢(每秒处理的芯片测试量少),难以适配半导体测试的实时性需求(生产线不能等模型“慢慢算”);
现有基准分类器:推理速度略优于Classifier-A,在对实时性要求极高的场景(如高速晶圆测试线)中具备一定优势;
Classifier-A:推理耗时约为现有基准分类器的 3 倍,但从实际价值看,2个百分点的 AUC 提升能大幅减少漏检缺陷,避免的下游成本损失,远超过推理环节的计算开销。
简单说:多花一点计算时间,能省一大笔返工成本,这笔 “账” 对制造商来说很划算。
(三)统计显著性与稳定性
为了验证算法性能的可靠性,时序验证过程中,研究团队通过多组不同随机种子的实验,量化了算法性能的波动性。结果显示:无论数据划分方式、模型初始化条件如何变化,Classifier-A 的性能优势均保持一致—— 这说明其性能提升是算法本身的稳健性优化带来的,不是 “碰巧选对了数据集”,落地到不同产线、不同产品时,效果都能稳定复现。
五、制造场景实施要点
(一)特征工程与筛选
半导体测试数据具有典型的高维特性(每颗芯片约 17500 个测试参数),其中很多参数对缺陷预测毫无意义,因此必须构建稳健的特征筛选流程。有效的实施需满足两大核心目标:一是精准筛选出具有强预测信号的特征(留下 “有用的”),二是严格控制模型计算复杂度(去掉 “没用的”),避免在小数据集场景下出现过拟合。
在平衡模型复杂度与可用训练数据时,参数筛选尤为关键。专用算法(如 Classifier-A)通过内置的特征选择机制,能自主处理高维特征空间,不用工程师手动 “一个个试参数”,大幅减轻人工特征工程的工作量,降低部署难度。
(二)超参数优化
传统机器学习算法需要大量人工调优超参数(比如学习率、正则化系数),往往要试几十组甚至上百组参数才能找到最优解,耗时耗力。而专用分类器(如 Classifier-A)内置了方差控制与自动化采样策略,大部分超参数能 “自动适配”,不用工程师反复调试,显著降低部署复杂度,实现 “快速上线、快速用”。
更重要的是,其内置的正则化机制能同时实现 “防止过拟合” 与 “保留少数类(缺陷样本)模式敏感性”——这一平衡是半导体缺陷检测的核心需求:既不能 “把合格的判成缺陷”(过拟合导致误判),也不能 “把缺陷的当成合格”(对少数类不敏感导致漏检)。
(三)与现有系统集成
现代制造场景不是 “重新建一套系统”,而是 “在现有基础上升级”,因此算法必须能与现有数据处理、决策系统无缝衔接。专用算法支持增量学习:随着生产数据的持续积累,模型能实现动态迭代优化,不用 “推倒重来” 做全量重训,完全适配制造运营的时序需求。
这种特性带来的好处是:从生产爬坡期到满产期,模型能跟着数据 “一起成长”,不用工程师频繁停机更新模型,为 “从生产爬坡到满产” 的全阶段,提供了可持续的模型维护方案,不会影响生产线正常运行。
六、业务价值与成本影响
(一)早期缺陷检测的核心价值
专用算法的核心价值,在于 “把缺陷检测的时间点提前”—— 在晶圆分选阶段(而非最终测试阶段)就精准识别潜在失效芯片,避免对失效芯片进行后续高成本加工(封装、组装的成本比晶圆测试高 10 倍以上)。
考虑到封装和最终测试环节的高昂成本,即便早期检测准确率仅实现小幅提升(比如 2 个百分点),也能为企业带来显著的成本节约,相当于 “花小钱,省大钱”。
(二)缩短投资回报周期
采用专用类别不平衡算法后,制造商从生产第一天起就能获得可用的预测模型,不用像传统方法那样,等数月积累均衡训练数据 ——这一特性可即时为质量决策提供支撑,显著缩短 AI/ML 项目的投资回报周期(比如从 6 个月缩短到 1 个月),让技术投入更快看到收益。
对制造商来说,这意味着 “新产品一投产,AI 就能用”,不用承担 “等待数据期间的质量风险”,还能加速技术价值转化。
(三)减少下游浪费
晶圆分选到最终测试的预测准确率提升,能直接减少下游加工浪费:避免缺陷芯片流入高成本制造环节,不用再做 “无用功”。Classifier-A 等专用算法能精准识别 “难判样本”(比如参数接近合格线的芯片),同时降低一类错误(误拒合格芯片)与二类错误(漏检缺陷芯片)的发生率 ——既不浪费好芯片,也不放走坏芯片,工程实用价值显著。
七、未来方向与可扩展性
(一)数据增长与模型演进
随着制造产量的提升、生产数据的持续积累,专用算法的增量学习能力可支持模型实现动态迭代优化,不用全量重训—— 这种模式既能以低成本实现模型维护(不用每次都花大量计算资源训模型),又能保留早期学习成果,确保模型性能随数据积累稳步提升,不会出现 “数据多了性能反而倒退” 的情况。
(二)集成方法探索
当前单一专用算法(如 Classifier-A)已展现出显著的性能优势,未来可进一步探索 “多专用分类器集成” 方案(比如让 Classifier-A 与其他算法 “协同工作”)。但需要注意的是:Classifier-A 等专用算法已内置集成技术,外部集成策略可能难以带来额外的性能增益,后续需要结合实际制造场景(如不同芯片类型、不同测试设备)开展验证,不能盲目 “为了集成而集成”。
(三)制造场景 AI 部署优化
八、结论
半导体行业的独特约束 ——数据收集的时效性(数据慢积累)、极端类别不平衡(缺陷太少)、对预测模型的即时需求(投产就要用)—— 要求行业必须采用超越传统算法的专用机器学习方法。研究结果明确表明:精心选择的专用算法,即便在训练数据严重不足的情况下,仍能实现显著的性能提升,不是 “纸上谈兵”,而是 “能落地用”。
专用类别不平衡算法带来的 2 个百分点 AUC 提升,可直接转化为三大核心价值:制造成本降低(少返工、少浪费)、质量控制改善(漏检少、误判少)、AI 投资回报加速(早用早收益)。随着行业持续扩大人工智能应用规模,这类专用方法将成为突破制造环境固有数据局限性的核心工具,不是 “可选方案”,而是 “必选方案”。
从工程实践角度看,半导体制造场景的 AI 应用,不能 “照搬互联网行业的模型”,必须跳出传统机器学习的固有框架,采用专为制造约束设计的算法。大量研究证据表明,在半导体测试场景中应用专用类别不平衡技术,既能快速创造业务价值(投产就能省成本),又能为后续数据积累后的模型优化筑牢基础,实现 “短期见效、长期向好” 的目标。
-
半导体
+关注
关注
339文章
31474浏览量
267634 -
检测
+关注
关注
5文章
4970浏览量
94395 -
机器学习
+关注
关注
67文章
8570浏览量
137421
发布评论请先 登录
如何理解矢量测量中“平衡”与“不平衡
三相不平衡的原因、危害以及解决措施
三相不平衡治理装置的应用优势
天线与馈线匹配中的平衡与不平衡变换有什么区别?
怎么解决变频器电流不平衡的问题
基于主动学习不平衡多分类AdaBoost改进算法
不平衡类别的机器学习
三相电压不平衡产生原因_三相电压不平衡的治理措施
机器学习中样本比例不平衡应该怎样去应付
基于有效样本的类别不平衡损失




评论