 RISC-V架构下AI融合算力及其软件栈实践
RISC-V架构下AI融合算力及其软件栈实践

面对未来大模型(LLM)、AIGC等智能化浪潮的挑战,进迭时空在RISC-V方向全面布局,通过精心设计的RISC-V DSA架构以及软硬一体的优化策略,将全力为未来打造高效且易用的AI算力解决方案。目前,进迭时空已经取得了显著的进展,成功推出了第一个版本的智算核(带AI融合算力的智算CPU)以及配套的AI软件栈。
软件栈简介
AI算法部署旨在将抽象描述的多框架算法模型,落地应用至具体的芯片平台,一般采用CPU、GPU、NPU等相关载体。在目前的边缘和端侧计算生态中,大家普遍认为传统CPU相较于NPU有极大的成本劣势,并且缺少基于CPU定制AI算力的能力或者相关授权,导致在实际落地场景中,NPU的使用率很高。但是NPU有其致命的缺点,各家NPU都拥有独特的软件栈,其生态相对封闭,缺乏与其他平台的互操作性,导致资源难以共享和整合。对于用户而言,NPU内部机制不透明,使得基于NPU的二次开发,如部署私有的创新算子,往往需要牵涉到芯片厂商,IP厂商和软件栈维护方,研发难度较大。着眼于这些实际的需求和问题,我们的智算核在设计和生态上采取了开放策略。以通用CPU为基础,结合少量DSA定制(符合RISC-V IME扩展框架)和大量微架构创新,以通用CPU的包容性最大程度复用开源生态的成果,在兼容开源生态的前提下,提供TOPS级别的AI算力,加速边缘AI。这意味着我们可以避免低质量的重复开发,并充分利用开源资源的丰富性和灵活性,以较小的投入快速部署和使用智算核。这种开放性和兼容性不仅降低了部署大量现有AI模型的门槛,还为用户提供了更多的创新可能性,使得AI解决方案不再是一个专门的领域,而是每个程序员都可以参与和创新的领域。
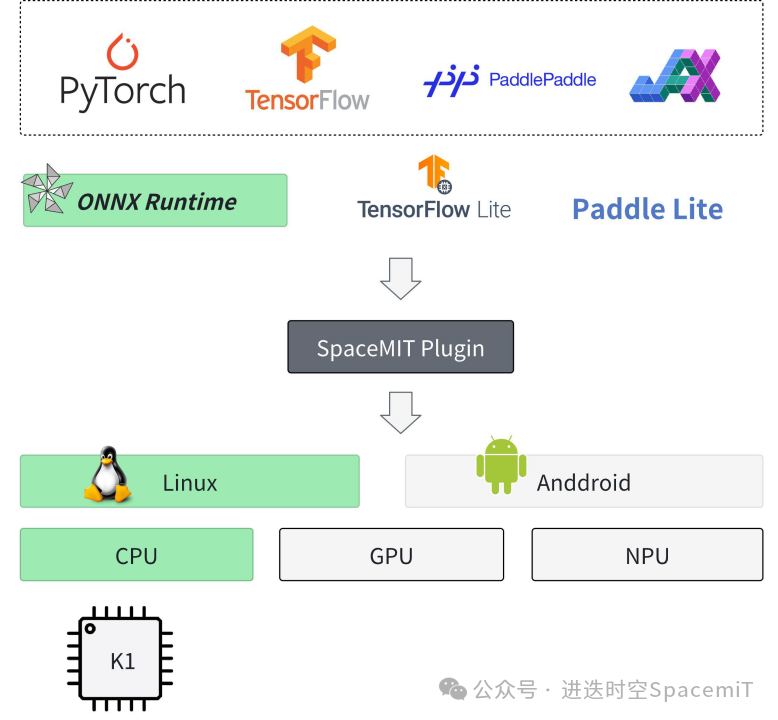
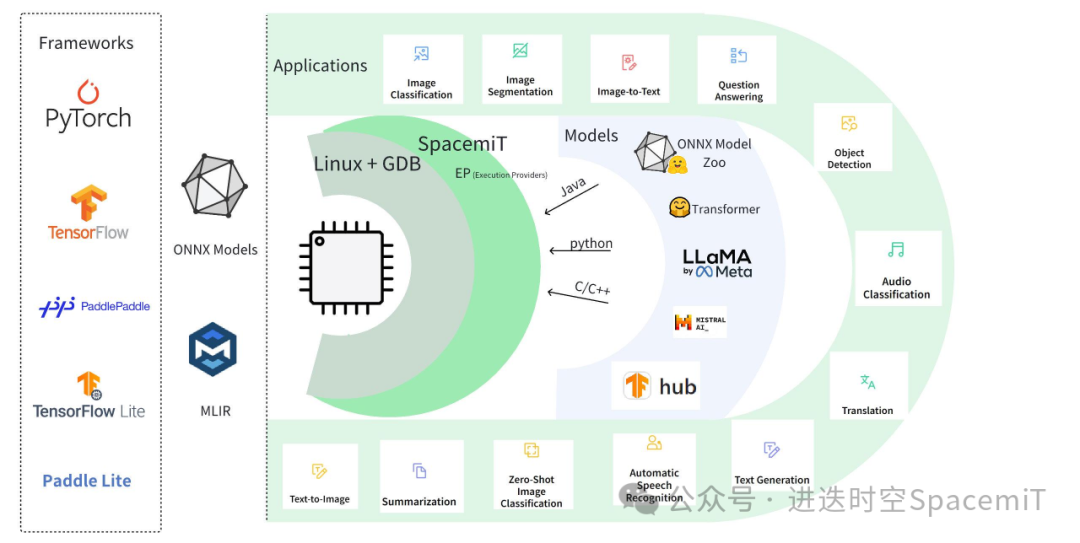
(图一:进迭时空AI软件栈架构)如上图所示,基于进迭时空的AI技术路线,我们能轻松的以轻量化插件的方式,无感融入到每一个AI算法部署框架中,目前我们以ONNXRuntime为基础,结合深度调优的加速后端,就可以成功的将模型高效的部署到我们的芯片上。对于用户来说,如果有ONNXRuntime的使用经验,就可以无缝衔接。加入进迭时空插件的使用方式如下:C/C++
C++ |
Python |
通过开放的软件栈,使得我们的芯片能够在短时间内支持大量开源模型的部署,目前已累计验证了包括图像分类、图像分割、目标检测、语音识别、自然语言理解等多个场景的约150个模型的优化部署,timm、onnx modelzoo、ppl modelzoo等开源模型仓库的支持通过率接近100%,而且理论上我们能够支持所有的公开onnx模型。智算核的软硬协同优化
在保证通用性和易用性的同时,我们利用智算核的特点,极大优化了模型推理效率。
离线优化
离线优化包含常见的等价计算图优化(如常量折叠、算子融合、公共子表达式消除等)、模型量化等,其中模型量化将浮点计算映射为低位定点计算,是其中效果最显著的优化方式。在智算核融合算力的加持下,算子可编程性很高,相较于NPU固化的量化计算方式,智算核能够根据模型应用特点,匹配更宽泛的数据分布,实现量化计算的精细化、多样化,以便于在更小的计算与带宽负载下,实现更高的推理效率。
运行时优化
区别于NPU系统中,AI算子会根据NPU支持与否,优先调度到NPU上执行,并以host CPU作为备选执行的方式。进迭时空的智算核采用了扩展AI指令的设计,以强大的vector算力和scalar算力作为支撑,确保任意算子都能够在智算核上得到有效执行,无需担心算子支持或调度问题。这种设计不仅简化了用户的操作流程,还大大提高了模型的执行效率和稳定性。
此外,进迭时空的智算核还支持多核协同工作,进一步提升了AI算力。用户只需在运行时通过简单的线程调度,即可灵活调整所使用的AI算力资源。
AI算力指令基础
智算核的AI算力主要来自扩展的AI指令。我们针对AI应用中算力占比最高的卷积和矩阵乘法,基于RISCV Vector 1.0 基础指令,新增了专用加速指令。遵从RISCV社区IME group的方式,复用了Vector寄存器资源,以极小的硬件代价,就能给AI应用带来10倍以上的性能提升。
AI扩展指令按功能分为点积矩阵乘累加指令(后面简称矩阵累加指令)和滑窗点积矩阵乘累加指令(后面简称滑窗累加指令)两大类,矩阵累加指令和滑窗累加指令组合,可以转化成卷积计算指令。
以256位的向量矩阵配合4*8*4的mac单元为例,量化后的8比特输入数据在向量寄存器中的排布,需要被看成是4行8列的二维矩阵;而量化后的8比特权重数据在寄存器中的排布,会被看成是8行4列的二维矩阵,两者通过矩阵乘法,得到4行4列输出数据矩阵,由于输出数据是32比特的,需要两个向量寄存器存放结果。
如图二所示,为矩阵累加指令,输入数据只从VS1中读取,权重数据从VS2中读取,两者进行矩阵乘法。
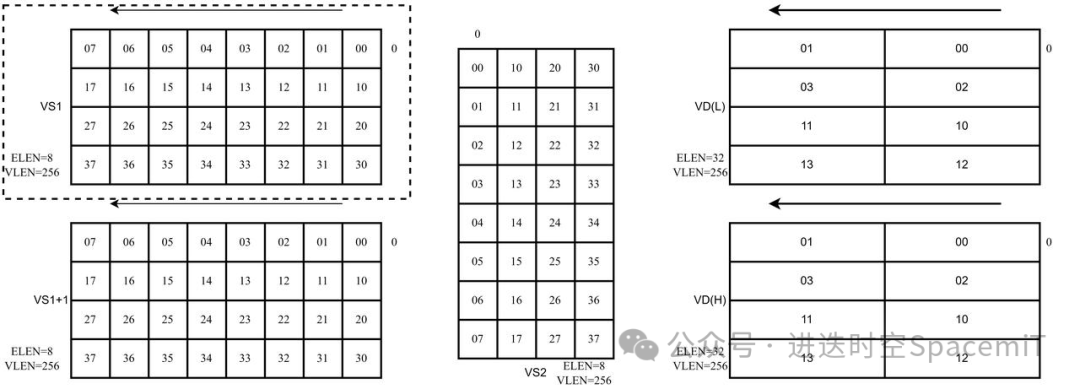
(图二:矩阵累加指令数据排布示例)
如图三所示,为滑窗累加指令,输入数据从VS1和VS1+1中读取,读取的数据,通过滑动的大小决定(大小为8的倍数),权重数据从VS2中读取,两者进行矩阵乘法。
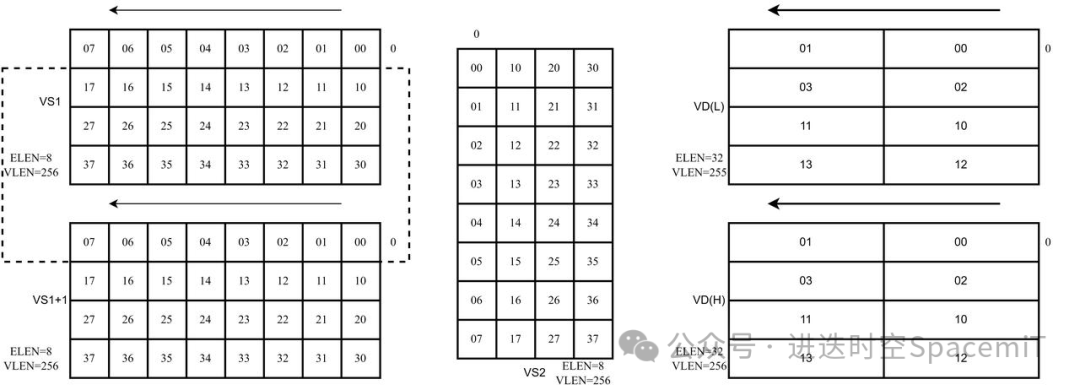
(图三:滑窗累加指令数据排布示例)
如下图所示,9个红点对应的9行输入数据(1*k维)和权重进行乘累加计算,就得到了一个卷积值。在做卷积计算的时候,可以把矩阵乘法看成是滑动为零的滑窗指令。通过滑动0,1,2三条指令的计算,就可以完成kernel size 为3x1的的卷积计算。然后通过h维度的三次循环,就可以得到kernel size 为3x3的卷积计算。
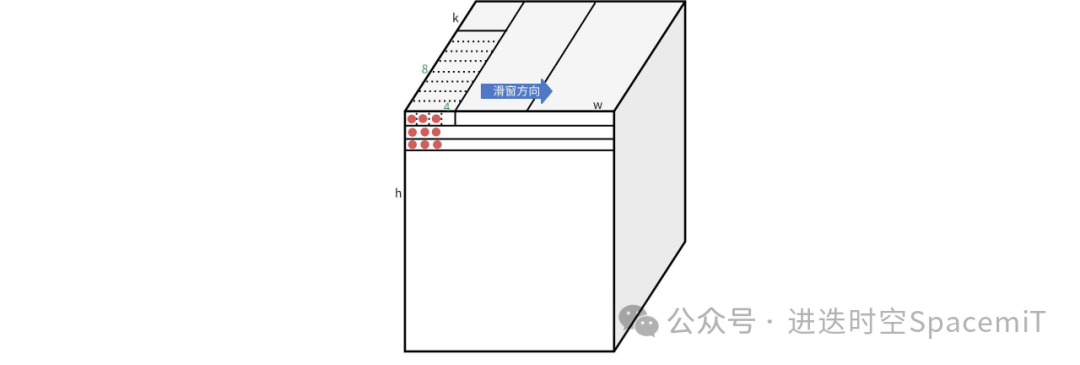
(图四:滑窗累加指令结合矩阵累加指令计算卷积示例)
同样通过滑动0,1,2,0,1五条指令的计算,和h维度五次循环,就可以完成kernel size为5x5的卷积计算,以此类推,可以得到任意kernel size的卷积计算。
效果演示视频
通过以上软硬件协同优化,我们在多任务推理时,也有非常高的性能。展望
前文提到,通过ONNX与ONNXRuntime的结合,我们能够便捷地接入开源生态,但这仅仅是实现接入的众多方式之一。实际上,我们还可以充分利用当前备受瞩目的MLIR生态,进一步融入开源的广阔天地。这种方式不仅充满想象力,而且具备诸多优势。
首先,它能够实现模型的直接原生部署。举例来说,当我们拥有一个PyTorch模型时,借助torch.compile功能,我们可以直接将模型部署到目标平台上,无需繁琐的转换和适配过程,极大地提升了部署的便捷性。
其次,MLIR生态与LLVM的紧密结合为我们提供了强大的codegen能力。这意味着我们可以利用LLVM丰富的生态系统和工具链,进行代码生成和优化,从而进一步降低AI软件栈的开发成本。通过codegen,我们可以将高级别的模型描述转化为底层高效的机器代码,实现性能的最优化。
(图五:进迭时空AI软件栈架构规划)
-
AI
+关注
关注
89文章
38153浏览量
296811 -
RISC-V
+关注
关注
48文章
2797浏览量
51929
发布评论请先 登录
Banana Pi BPI-F3 进迭时空RISC-V架构下,AI融合算力及其软件栈实践
risc-v多核芯片在AI方面的应用
RISC-V,即将进入应用的爆发期
关于RISC-V学习路线图推荐
科普RISC-V生态架构(认识RISC-V)
RISC-V架构简介
GPU,RISC-V的长痛
谈一谈RISC-V架构的优势和特点
阿里平头哥发布首个 RISC-V AI 软硬全栈平台
RISC-V强势崛起为芯片架构第三极
借势 RISC-V与 AI 浪潮,元石智算打造算力新范式






 工商网监
工商网监
评论