 如何在基于Arm Neoverse平台的Google Axion处理器上构建RAG应用
如何在基于Arm Neoverse平台的Google Axion处理器上构建RAG应用

作者:Arm 基础设施事业部 AI 解决方案架构师 Na Li 等
你是否好奇如何防止人工智能 (AI) 聊天机器人给出过时或不准确的答案?检索增强生成 (Retrieval-Augmented Generation, RAG) 技术提供了一种强大的解决方案,能够显著提升答案的准确性和相关性。
本文将探讨 RAG 的性能优势,并分享如何在基于 Arm Neoverse 平台的 Google Axion 处理器上构建 RAG 应用,以优化 AI 工作负载。在本文的测试中,Google Axion 处理器相较于 x86 架构处理器,性能提升了 2.5 倍,并节省了 64% 的成本。Google Axion 处理器通过更好的 RAG 性能加速推理过程,从而实现更快的知识检索、更低的响应延迟和更高效的 AI 推理,这对于实时、动态 AI 应用至关重要。
了解 RAG:高效的 AI 文本生成方法
RAG 是一款主流 AI 框架,能够实时检索相关外部知识,从而提升大语言模型 (LLM) 生成文本的质量和相关性。与仅依赖静态预训练数据集的方法不同,RAG 动态集成了最新外部资源信息,能够生成更精确且贴近上下文的输出结果。这使得 RAG 在实际应用场景中表现出色,例如客服聊天机器人、智能体工具和动态内容生成等场景。
何时选择 RAG 而非微调或重新训练?
基础 LLM 通过类似人类的文本生成功能彻底改变了 AI 领域,但其有效性取决于模型是否拥有企业所需的最新信息。对经过预训练的 LLM 模型进行重新训练和微调是集成额外知识的两种常用方法。重新训练 LLM 是一个资源密集型的复杂过程;而微调则能够使用特定数据集对 LLM 进行训练,调整模型的权重,以更好地完成目标任务。不过,模型仍然需要定期重新部署,以保持与时俱进。
通常,在将 LLM 纳入 AI 战略时,必须评估 LLM 的能力和局限性。主要考虑因素包括:
训练数据集的局限性:对于训练数据集未包含的主题,LLM 可能难以提供准确或最新的信息。
资源需求高:重新训练这些大模型需要大量的算力和工程资源,使得频繁更新难以实施。
对内部知识的访问受到限制:由于企业的主要业务数据受到防火墙的保护,因此 LLM 无法通过定期重新训练纳入专有信息,这可能会限制 LLM 在企业内部使用时的相关性。
RAG 的优势
RAG 无需修改 LLM,只需利用外部数据源更新知识库,将动态信息检索与语言模型的生成能力相结合。如果你所在的领域知识经常变化,那么 RAG 是保持准确性和相关性,并减少 LLM 幻觉的理想解决方案。
RAG 的实际应用:对比分析
在以下所举的例子中,比较了通用 LLM(左)和经过 RAG(右)增强的聊天机器人。左图中,由于信息过时或缺乏特定领域的知识,聊天机器人难以准确回答用户的询问;而 RAG 增强型聊天机器人能够从上传的文件中检索最新信息,提供准确且相关的回复。
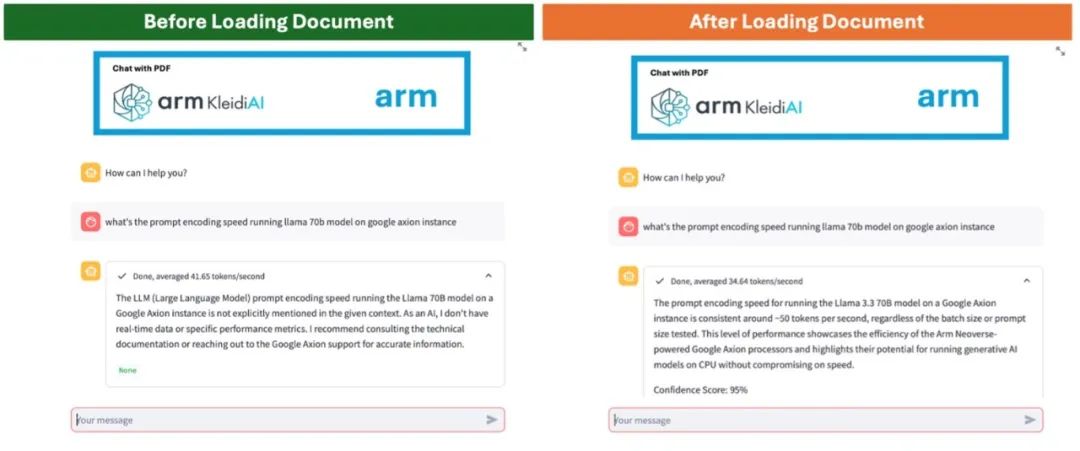
图 1:通过 LLM 实现的聊天机器人(左)
和经过 RAG 增强的聊天机器人(右)
为何选择 Axion 来实现 RAG 解决方案
基于 Arm Neoverse 平台的 Google Axion 处理器为运行 LLM 的 AI 推理功能提供了理想平台,该处理器能够以高性能和高效率支持 RAG 应用的运行。
优化 AI 加速:基于 Neoverse 平台的 CPU 具有高吞吐量向量处理和矩阵乘法功能,这对于高效处理 RAG 至关重要。
云计算的效率和可扩展性:基于 Neoverse 平台的 CPU 可最大限度地提高每瓦性能,在高速处理和能效之间取得平衡。因此,特别适用于需要在云端快速推理并兼顾成本效益的 RAG 应用。基于 Neoverse 的处理器还可用于扩展 AI 工作负载,确保无缝集成各种 RAG 用例。
面向 AI 开发者的软件生态系统:对于希望在基于 Arm 架构的基础设施上利用最新 AI 功能的开发者,Arm Kleidi 技术能够显著提升 RAG 应用的性能和效率。Arm Kleidi 已经集成到 PyTorch、TensorFlow 和 llama.cpp 等开源 AI 和机器学习 (ML) 框架中,使开发者能够实现开箱即用的默认推理性能,而无需使用供应商插件或进行复杂的优化。
这些特性的结合带来了显著的性能提升,首个基于 Google Axion 的云虚拟机 C4A 与 x86 同类方案相比,大幅提升了基于 CPU 的 AI 推理和通用云工作负载的性能,使 C4A 虚拟机成为在 Google Cloud 上运行 RAG 应用的理想选择。
Google Axion 性能基准测试
使用 RAG 系统进行推理涉及两个关键阶段:信息检索和生成响应。
信息检索:系统搜索向量数据库,根据用户的查询找到相关内容。
生成响应:检索到的内容与用户查询相结合,生成与上下文相关的准确回复。
一般来说,检索速度取决于数据库的大小和搜索算法的效率。在基于 Neoverse 平台的 CPU 上运行时,经优化的算法可在几毫秒内返回结果。然后,将检索到的信息与用户的输入相结合,构建新的提示词,并将其发送给 LLM 进行推理和生成响应。相较于检索阶段,生成响应阶段耗时更长,RAG 系统的整体推理延迟在很大程度上受 LLM 推理速度的影响。
本次测试使用 llama.cpp 基准和 Llama 3.1 8B 模型(Q4_0 量化方案)评估了多个 Google Cloud 虚拟机的 RAG 推理性能。使用 48 个线程进行了所有测试,输入词元 (token) 大小为 2058,输出词元大小为 256。以下是测试配置:
Google Axion (C4A, Neoverse V2): 在 c4a-standard-48 实例上进行了评估。
Intel Xeon (C4, Emerald Rapids): 在 c4-standard-48 上进行了性能测试。
AMD EPYC (C3D, Genoa): 在启用 48 个核心的 c3d-standard-60 上进行了测试。
Axion 处理器实现更快处理与更高效率
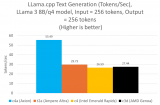
推理性能根据提示词处理速度和词元生成速度来测定。图表 1 的基准测试结果表明,与当前一代 x86 实例相比,基于 Google Axion 的 C4A 虚拟机在提示词处理和词元生成方面实现了高达 2.5 倍的性能提升。
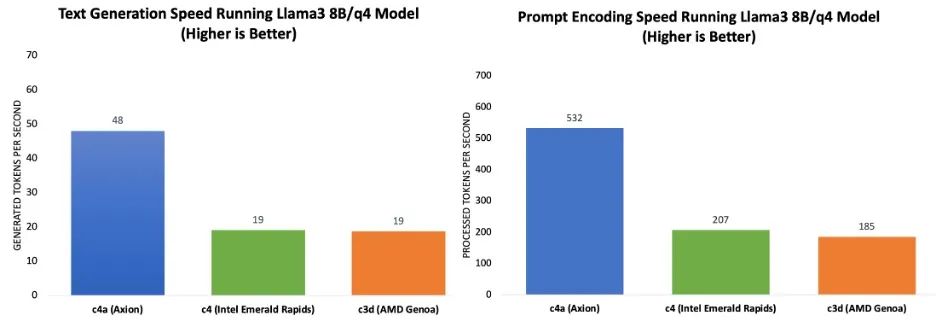
图表 1:运行 Llama 3.1 8B/Q4 模型时,提示词处理(左)
和词元生成(右)与当前一代 x86 实例的性能比较
成本效益:降低 RAG 推理成本
为了评估推理任务的实例成本,还测量了从提交提示词到生成响应的延迟。有几个因素会影响延迟,包括检索速度、提示处理效率、词元生成速率、输入和输出词元大小以及用户批处理规模。由于信息检索延迟通常在毫秒级,与其他因素相比可以忽略不计,因此未纳入计算。批次大小选择为 1,以确保在单个用户级别进行公平的比较。为了与基准测试保持一致,测试中将输入和输出词元大小分别设置为 2048 和 256。首先通过提示词编码速度和词元生成速度计算提示词处理和词元生成的延迟,然后根据 Google Cloud 上的实例定价图表[3]计算每次请求的成本,再将这些数字归一化为所有三个实例的最大成本。
图表 2 中的结果表明,基于 Axion 的虚拟机可节省高达 64% 的成本,处理每次请求所需的成本仅为当前一代 x86 实例的三分之一左右。
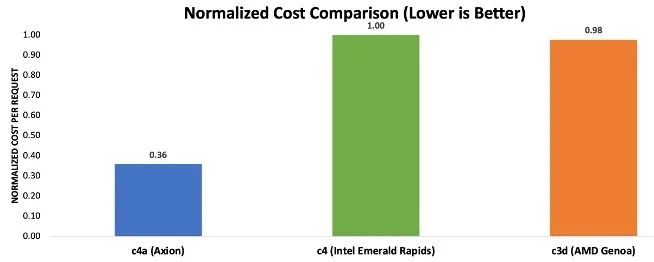
图表 2:使用 RAG 处理推理请求的归一化成本对比注
注:成本计算基于截至 2025 年 3 月 5 日公布的实例定价,可参见
https://cloud.google.com/compute/vm-instance-pricing
快速入门:基于 Arm 平台构建 RAG 应用
以 Neoverse 平台为核心,Google Axion 赋能的实例能以更低的成本提供高性能,助力企业构建可扩展且高效的 RAG 应用,同时与 x86 方案相比显著降低了基础设施开支。
为了帮助开发者快速入门,Arm 开发了分步演示和 Learning Path 教程,以便开发者使用自己选择的 LLM 和数据源构建基本的 RAG 系统。
以下资源能够帮助刚接触 Arm 生态系统的开发者顺利踏上开发旅程:
通过 Arm Learning Path 迁移到 Axion:依照详细的指南和最佳实践,简化向 Axion 实例的迁移进程。
Arm Software Ecosystem Dashboard:及时了解 Arm 平台上支持的最新软件信息。
Arm 开发者中心:无论你是刚接触 Arm 平台,还是正在寻找资源来开发高性能软件解决方案,Arm 开发者中心应有尽有,可以帮助开发者构建更好的软件,为数十亿设备提供丰富的体验。在 Arm 不断壮大的全球开发者社区中,开发者可以访问资源、交流学习和提问探讨。
还等什么?即刻开启你的迁移之旅,利用 Arm Neoverse 平台释放云和 AI 工作负载的全部潜力!
-
处理器
+关注
关注
68文章
20149浏览量
247226 -
ARM
+关注
关注
135文章
9499浏览量
388770 -
Google
+关注
关注
5文章
1801浏览量
60270 -
人工智能
+关注
关注
1813文章
49741浏览量
261572
原文标题:利用基于 Arm 平台的 Google Axion,解锁 RAG 技术的强劲实力
文章出处:【微信号:Arm社区,微信公众号:Arm社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
向Intel发起重型计算挑战 ARM发布Neoverse 处理器
Arm Neoverse V1的AWS Graviton3在深度学习推理工作负载方面的作用
Arm Neoverse N1软件优化指南
ARM处理器Google系统让华硕踌躇不已
如何在芯片的PL上构建软核处理器?

Arm推出Neoverse处理器家族 大有对标Intel之势
ARM推出新一代Neoverse处理器平台,面向5nm及3nm工艺性能提升30%以上
Arm推出新一代平台 Neoverse V2 平台

Arm发布新一代Neoverse数据中心计算平台,AI负载性能显著提升
Google Cloud推出基于Arm Neoverse V2定制Google Axion处理器
谷歌自主研发:Google Axion处理器亮相
如何在基于Arm Neoverse平台的CPU上构建分布式Kubernetes集群





 工商网监
工商网监
评论