 NVIDIA在美国发布了 Quadro 系列和 DGX 系列的两款新品
NVIDIA在美国发布了 Quadro 系列和 DGX 系列的两款新品

3 月 28 日(北京时间),NVIDIA 在美国圣何塞召开了 GTC 2018(GPU Technology Conference 2018)大会,并发布了 Quadro 系列和 DGX 系列的两款新品。
Quadro GV 100 是 NVIDIA 「专业图形显卡」系列的最新成员,公司 CEO 黄仁勋称其为「世界上体积最大的 GPU」。
Quadro GV 100 拥有 5120 颗 CUDA 流处理器,640 颗 Tensor 处理器,最高可提供 14.8TFLOPS 的单精度浮点性能, 7.4TFLOPS 双精度浮点性能;采用 32GB HBM2 显存,显存带宽为 870GB/s;能够提供 118T 的深度学习性能。
接口方面,Quadro GV 100 配备 4 个 Display 1.4 接口,可以对接最多 4 个 4096 x 2160 分辨率,120Hz 刷新率的显示器;或 4 个 5120 x 2880 分辨率, 60Hz 刷新率的显示器;或 2 个 7680 x 4320 分辨率,60Hz 刷新率的显示器。
DGX-2 是一台专门用于人工智能训练和/或推理任务的桌面计算机,是 NVIDIA 的第二代 DGX「小型超级计算机」,采用新的 NVSwitch 技术并联 16 块 32GB 显存的 Tesla V100 计算卡,以及两枚英特尔 Xeon Platinum 处理器 ,拥有 1.5TB 系统内存,与 30TB 的 NVMe SSD 作为存储空间,显存容量则为 512GB HBM2,可以提供最高 2petaFLOPS 的浮点性能。
这是它的内部结构:
你可以看到,在图中 1 和 2 的位置看起来是很多块芯片。其实他们是英伟达的 Tesla V100 Volta 架构 GPGPU,单枚算力达到双精度 7.8 TFLOPS(万亿次浮点计算)、单精度 15.7TFLOPS、深度学习 125TFLOPS。
而DGX-2 单机箱安装了 16 枚 V100,总体性能达到了惊人的 2PFLOPS——业界第一台超过千万亿次浮点计算能力的单机箱计算机——称它为超算或许并不浮夸。
但 DGX-2 的算力并非靠堆叠出来,如果它们之间不能实现高带宽的数据互通则无意义。
时间倒回两年前,英伟达有意在深度学习的设备市场上对英特尔发起直接挑战,推出了 Pascal 架构的 P100 GPGPU。在当时,主流服务器 PCIe 总线接口的带宽和时延,已经无法满足英伟达的需求。于是它们开发出了一个新的设备内互联标准,叫做 NVLink,使得带宽达到了 300 GB/s。一个 8 枚 GPGPU 的系统里,NVLink 大概长这样:
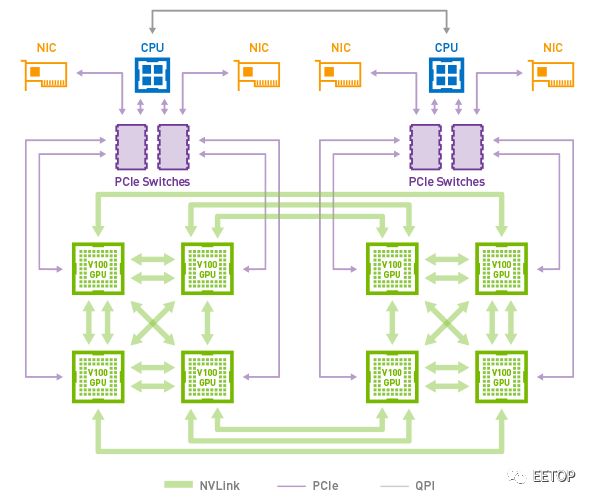
然而 NVLink 的标准拓扑结构在理论上最多支持 8 枚 显卡,仍不足以满足英伟达对于新系统内置更多显卡的需要。于是在 NVLink 的基础上,英伟达开发出了一个名专门在显卡之间管理 NVLink 任务的协处理器,命名为 NVSwitch。这个元件在 DGX-2 上,让 16 枚 GPGPU 中两两之间实现 NVLink 互通,总带宽超过了 14.4 TB。
这一数字创造了桌面级电脑内总线接口带宽的新高,但实现它的目的并非跑分,而在于 DGX-2 可以 1)更快速地训练一个高复杂度的神经网络,或 2)同时训练大量不同结构的神经网络。
N 卡之所以被称为核弹有一种另类的解释方式:它的多核心架构在这个依核心数量论高下的时代显得超凡脱俗——动辄几百、上千个 CUDA 核心,令人不明觉厉。而在 DGX-2 上,16 枚 V100 的 CUDA 核数达到了疯狂的 81,920 核心。这一事实,结合 NVSwitch 技术、512GB 现存、30TB NVMe 固态硬盘、两枚至强 Platimum CPU 和高达 1.5TB 的主机内存——
黄仁勋用 GPU 深度学习里程碑式的杰作 AlexNet 来举例。研究者 Alex Krizhevsk 用了 6 天,在英伟达 GPU 上训练 AlexNet,这个研究首次利用梯度下降法和卷积神经网络进行计算机图像识别,显著优于此前的手调参数法,拿下了 ImageNet 图像识别竞赛冠军。AlexNet 让 Alex 世界闻名,这 6 天可以说值了。
然而,“同样的 8 层卷积神经网络,我用 DGX-2 跑了一下,只用 18 分钟就达到了同样的结果,”黄仁勋说,“五年,500倍的进步。”
这说明了很多东西。其中有一条:在这五年里,英伟达的技术进步节奏已经无法用摩尔定律来描述了。
Nvidia DGX-2 可提供 10 倍于上一代 Nvidia DGX-1 的深度学习性能,整体功耗为为 10KW,重 350 磅,售价仅为 39.9 万美元(约合 250 万人民币)。
除了上述两款重磅产品外,在今天的GTC 2018上,黄仁勋还宣布了英伟达的以下进展:
1、推出光线追踪RTX技术(ray-tracing),能够提供电影级画质的实时渲染,渲染出逼真的反射、折射和阴影画面。这一技术由英伟达在前不久的GDC全球游戏开发者大会上展示过;
2、推出了第一款专用于医疗图像处理的超级电脑Clara;
3、推出新版机器学习应用平台TensorRT 4,支持INT8与FP16精度,并与谷歌合作,将其整合进AI开源框架谷歌TensorFlow 1.7中;
4、宣布打造下一代名为DRIVE Orin的自动驾驶芯片,但除了名字外没有透露更多信息;
5、正式推出3D仿真自动驾驶测试平台DRIVE Constellation,这一测试平台英伟达在CES上展示过,能够帮助自动驾驶系统提升“姿势水平”;
6、推出ISAAC机器人仿真训练平台SDK,将训练机器人的技术开放出去;
此外英伟达还宣布将把它的开源深度学习架构(NVDLA)带到ARM即将推出的项目 Trillium 平台上,NVDLA将帮助开发人员加速推理过程。英伟达通常依赖于自己的封闭平台,不过,要想在移动物联网设备方面发挥影响,英伟达有必要和在该领域占主导地位的ARM合作。
黄仁勋演讲内容:
重现照相质量的3D世界一直以来是3D图学的终极目标,真实世界中光线来自四面八方,为了要重现真实世界,就必须把各个光线的来源综合计算,复杂度极高,传统GPU可能一秒只能计算一格画面,但我们今天利用新技术,可以达到每秒60张画面,这是非常不可思议的突破。
我们过去利用了许多不同的图学技巧,不论是要降低计算负担,或者是加速执行,但仍然很难真实重现照片画质。
图丨黄仁勋演讲现场(图片来源:DT君)
但决定画面真实与否的最终条件,往往是画面中的小细节,比如说光线和物件之间的折射、散射、漫射、透射与反射等等,通过光线追踪技术,我们可以把真实世界的画面成像原理搬到3D图学当中,并且利用我们的GPU技术架构来完成。
要考虑到不同的物件会吸收光线、折射光线的程度不同,比如说玻璃、塑胶,甚至我们的皮肤,都会一定程度的吸收光线,因此我们利用了subsurface scattering来达到这样的效果,这在一般计算机图学中是非常难以达到的效果,但通过光线追踪技术,我们可以轻易的达到。
黄仁勋用一段星际大战影片来展示光线追踪的效果,其效果几乎和真实的电影画面毫无差异,用肉眼几乎看不出来是计算机计算的影片。尤其是在帝国士兵身上的铠甲效果,反射光源后,和周围环境进行多次折射和反射,以及光线的吸收,最终形成非常真实的画面,几乎和电影画面没有差别。
图丨黄仁勋用星际大战影片来展示光线追踪的效果(来源:DT君)
这样的画面是在DGX超级计算平台,通过2块Volta绘图卡达成。这是世界首次以实时呈现光线追踪的效果。
在电影产业中,其实相关与光线处理相关的图学技术都被使用,当你看到广告、影片中,很多凭空创造出来的产物,基本上都是利用GPU创造出来的,而GPU每年都创造了超过10亿张这些数字创作。通过GPU计算,我们让产生这些图像的成本和需要的时间降到最低,我们可以说,用越多GPU,你越省钱!
图丨The more GPU you buy,the more you save
如今,通过使用 Quadro GV100,我们可以在单一机架中取代传统庞大耗电的render farm,目前主要电影创作者都逐渐往这个方向前进,比如说 Pixar,就利用了这样的架构来产生他们的电影画面。
而考虑到世界上有多少电影工作室正在从事电影相关创作,我们可以考虑一下这个市场规模会有多大,牵涉到多大的金额,天文数字。
GPU推动了AI产业的发展,但AI产业也同时推动了GPU的进步,不只是GPU架构本身,还有相对应的开发环境与软件生态,考虑到目前AI生态越来越蓬勃发展,我们可以说现时是个最佳的时间点,是让产业改头换面,前进到AI的领域中。
图丨各种各样的AI Network正在涌现
而为了满足这些开发者的需求,超过800万个开发者下载了我们的CUDA工具,他们创造出来的计算效能超过370PETAFLOPS。
这些高性能计算很大程度都是要用来改变世界,包括研究疾病、医疗、气候变迁,甚至了解HIV的结构。
我们拿2013年的GPU架构和今年推出的最新产品相比,我们的GPU每隔五年就达到10倍的效能成长,传统半导体有摩尔定律,但是在CUDA GPU中,我们创造了不同的定律,不只是硬件本身,我们也针对算法不断的改善,总和以上的努力,我们才能达到这样的成就。
传统服务器的庞大、耗电,通过我们的GPU有了根本性的改变,我们可以说,你们在计算领域用了越多的GPU,其实就是越省钱!
在医疗图像方面,很多疾病是越早侦测就越有机会治愈,但如何侦测疾病,视觉化的身体扫描技术,包括超音波、断层扫描等,如果能够利用3D技术重建扫描结果,我们可以看到更真实的结果,而不是能依靠不明显的阴影来判断病征。
图丨英伟达在医疗上的合作伙伴
通过远端与医疗图像设备连线,这些设备产生的图形实时反馈到我们的CUDA服务器中,并实时产生这些清晰的动态图像,通过深度学习,我们可以轻易判读这些扫描的结果,并还原到我们肉眼可以简单判读的3D立体型态。通过把这些服务器虚拟化,利用AI来后处理这些医学图像,我们可以创造出更容易判读,且更不容易误判的医疗图像。
深度学习可以说重新塑造了我们现在的AI应用,从过去厚重、庞大、笨拙的印象,变呈现在轻巧、快速、聪明的结果。从芯片设计者,到互联架构,到软件设计者,再到OEM厂商等,不论你在供应链中的哪个环节,我们都可以全力支持。
客户想要达成不同的计算目标,不论是购买成品,或者是自行架设,我们都能满足客户的需求。
近十年从机器学习到深度学习,从最早的模型,衍生出无数种不同的神经网络、模型,随着应用的增加,也越来越复杂。
当然,为了要应付这些复杂的神经网络计算,现有的小型GPU其实很难以负担,但我们从不同的方向去思考,如果把个别的GPU通过高效能的互联结构结合起来,形成一个巨大的GPU,这个GPU上面可以创造出过去不可能达成的计算成果。
图丨用NVSwitch互聯16個GPU的DXG2 server
我们通过NVSwitch达成了这个目的,通过这个互联架构,我们在DXG-2 server中互联了16颗GPU,形成一个庞大的GPU架构,通过最新的NVLink,技术,GPU和GPU之间可以用比PCIE快20倍的效率互相沟通。这个互联结构不是网络状结构,而是速度更快的交换器结构,通过这样的互联设计,我们在单一结构中实现了2PETAFLOP的惊人效能。而且只需要2000W的功耗。其功耗性能比可说远远超出目前的超级计算机。
图丨黄仁勋和世界上最大的GPU合影
现在新的AI芯片把云计算、深度学习看得太简单,要考虑的因素太多,包括延迟、学习速率以及准确度等等,并不是在机架中塞进几个ASIC芯片就能够轻易解决的工作。我们要把尽可能快速的产生模型,尽可能让模型更小,尽可能确保正确的结果输出,背后的最大功臣就是开发工具。继去年针对推理大幅进化的TensorRT3之后,我们现在推出了最新的TensorRT 4,支持更多主流框架,也更能把不同的神经网络部署到云服务器当中。这个版本我们又更加强化了推理性能。
通过TensorRT、NCCL和cuDNN,以及面向机器人的全新Isaac软件开发套件,基于GPU的计算生态也更加完整。此外,通过与领先云服务提供商的密切合作,各大主流深度学习框架都在持续优化,以充分利用NVIDIA的GPU计算平台。
NVIDIA新推出的DGX-2系统通过借鉴NVIDIA为所有层级的计算堆栈开发的各种业界领先的技术优势,实现了每秒2千万亿次浮点运算的里程碑式突破。
图丨黄仁勋演讲
DGX-2是首款采用NVSwitch的系统,其中采用的16个GPU均共享统一的内存空间。这让开发者获得了相应的深度学习训练能力,以处理最大规模的数据集和最复杂的深度学习模型。
DGX-2能够在不到两天的时间内完成对FAIRSeq的训练,FAIRSeq是一种采用最新技术的神经网络机器翻译模型,其性能相较于去年9月份推出的基于Volta架构的DGX-1提高了10倍。
我们在此也要宣布推出DRIVE Constellation计算平台。该平台基于两个不同的服务器,第一台服务器运行DRIVE Sim软件来模拟自动驾驶汽车的传感器,例如摄像头、LiDAR和雷达,第二台则包括英伟达强大的Drive Pegasus自驾车AI计算机,运行完整的自驾车软件堆栈和处理过程,就像驾驶汽车的传感器一样。
通过虚拟仿真,人们可以通过测试数十亿英里的自定义场景和罕见的场景案例来增强算法的稳健性,最终所花的时间和成本只是在真实物理道路上需要的一小部分。
-
芯片
+关注
关注
462文章
53534浏览量
459098 -
神经网络
+关注
关注
42文章
4827浏览量
106796 -
NVIDIA
+关注
关注
14文章
5496浏览量
109090
原文标题:刚刚Nvidia发布仅售250万元的超级怪兽DGX-2|附黄仁勋演讲实录
文章出处:【微信号:eetop-1,微信公众号:EETOP】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
NVIDIA DGX Spark系统恢复过程与步骤

面向科学仿真的开放模型系列NVIDIA Apollo正式发布
NVIDIA DGX Spark助力构建自己的AI模型

在NVIDIA DGX Spark平台上对NVIDIA ConnectX-7 200G网卡配置教程
NVIDIA DGX Spark快速入门指南

奥比中光旗下新拓三维发布两款3D扫描双旗舰新品
Cadence 借助 NVIDIA DGX SuperPOD 模型扩展数字孪生平台库,加速 AI 数据中心部署与运营
紫光闪存推出两款PCIe 5.0固态硬盘
NVIDIA GTC2025 亮点 NVIDIA推出 DGX Spark个人AI计算机

NVIDIA 宣布推出 DGX Spark 个人 AI 计算机

LG UltraGear系列职业电竞显示器新品发布
华硕发布两款搭载骁龙X平台的全新AI PC
OPPO两款新机成功入网
鼎阳科技银河系列三款高端射频新品重磅发布






 工商网监
工商网监
评论