 OpenAI开放模拟机器人环境和HER算法,让机器人从失败中学习
OpenAI开放模拟机器人环境和HER算法,让机器人从失败中学习

从错误中吸取教训是人类能长久保持优势的原因之一,即使我们做了失败的尝试,但至少有一部分是正确的,总结经验后也能成功。
机器人也可以使用类似的试错法学习新任务。通过强化学习,机器人尝试用不同的方法做一件事,如果尝试的方法有效则会获得奖励。给予奖励生成的强化,机器人会不断尝试直到成功到达目标。
人与机器的不同之处在于我们如何从失败和成功中学习,从中我们不仅知道哪些东西对实现目标没有帮助,而且能了解为什么失败以及之后如何避免。这就使我们能比机器人更有效地学习。
今天,位于美国旧金山的人工智能研究机构OpenAI发布了一款开源算法,名为Hindsight Experience Replay(HER),该算法将失败作为成功的手段,让机器人像人类一样学习。
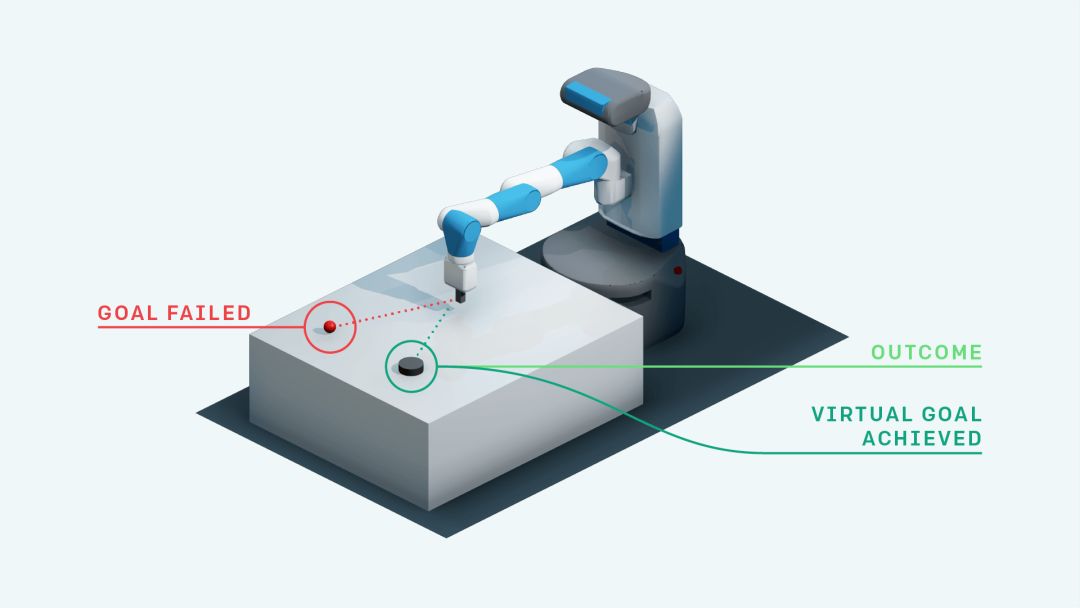
HER的重要特征是它能像人类一样,即使没有达到预期目标,但至少收获了其他成果。那么为什么不假装这就是最初想实现的目标呢?
Spectrum IEEE的编辑Evan Ackerman用比喻具体形容了HER的原理:想像一下你正要击打棒球,目标是全垒打。但是在第一次击球时,球出界了,虽然没有做到全垒打,但是你却知道了一种打出界球的方法。事后通过总结,你可以这么想:“如果我的目标就是打个出界球,那么刚刚的那一记击球就是完美的!”虽然没有打出全垒打,但仍然有了进步。
HER的另一个优点是它使用了研究人员所称的“稀疏奖励”来指导学习。奖励是我们如何告诉机器人它们的所作所为对强化学习是好事还是坏事。大多数强化学习算法使用的是“密集奖励”,机器人根据完成目标的程度获得不同大小的cookies。这些cookies可以单独奖励任务的一个方面,并在某种程度上帮助指导机器人按照指示的方式学习。
密集奖励很有效,但是部署起来却有些麻烦,并且在有些情况下并不是那么实用。大多数应用非常关注结果,并且出于实用的目的,你可以从中取得成功,也可能不成功。稀疏奖励是指,机器人在成功后只得到一个cookie,这样一来,该程序就更容易测量、编程和实施。但另一方面,这种方法可能会降低学习速度,因为机器人没有获得增量反馈,它只是被一遍又一遍地告诉“没有cookie”,除非它非常幸运地偶然成功了。
这就是HER的基本原理:它让机器人通过分散奖励学习,改变原本的目标,把每次尝试行为都看做成功,所以机器人每次都能学到一些东西。
通过这种方法,强化学习算法可以获得学习信号,因为它已经实现了一些目标;即使它不是你原本想达到的目标,如果重复这个过程,最终机器人也会实现任意一种目标,包括最初真正的目标。
下面的视频是HER方法与其他深度学习方法在实践中的对比,左边是新开发的HER方法,右边是T. Lillicrap等人于2015年提出的深度决定性策略梯度(DDPG)方法:
最终的结果对比差别非常大:
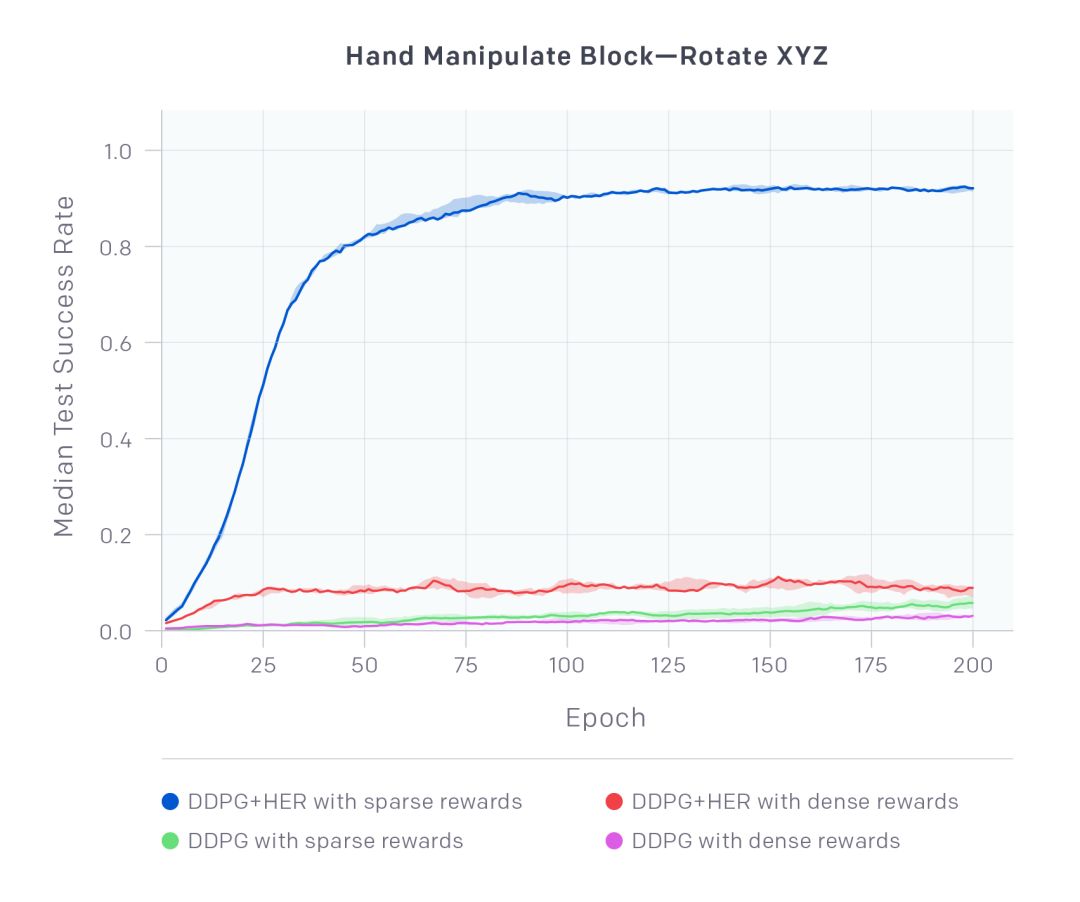
HandManipulateBlockRotateXYZ-v0上四个不同配置下的中位测试成功率(曲线)和四分位范围(阴影部分)。数据绘制于训练时期,每种配置下每隔五个随机种子就进行总结
带有稀疏奖励的DDPG+HER明显优于其他所有配置,并且只从稀疏奖励中学习了成功策略来完成这项具有挑战性的任务。有趣的是,带有密集奖励的DDPG+HER能够学习,但表现得却不好。而Vanilla DDPG的两种配置均不能学习。完整的实验结果可以在论文中查看。
OpenAI此次发布了八个Gym模拟机器人环境(Gym是OpenAI用于开发和比较强化学习算法的工具包,它能教智能体各种任务,比如走路、打乒乓球或玩弹球等),其中四个用于Fetch研究平台,四个用于ShadowHand机器人,使用的是MuJoCo物理模拟引擎。
Fetch上的四个环境

将机械臂末端以最快速度移动到目标位置

击中灰色目标,使其滑动到桌上一固定位置

用机械臂末端推动正方体使其到达目标位置

机械臂抓取桌上的正方体,并停留在桌子上方某固定位置
ShadowHand上的四个环境

将拇指和另一个手指移动到指定位置

在手上翻转正方体直到达到预期位置

在手上翻转彩蛋直到达到预期位置

在手上转笔直到达到预期位置
HER的问题
虽然HER对于学习稀疏奖励的复杂任务是很有前景的方式,但它仍存在改进的空间。和OpenAI最近发布的Request for Research 2.0相似,研究人员针对HER的进步提出了一下几条想法:
事后自动创建目标。目前的HER使用硬编码策略选择目标,如果算法可以自动学习应该会很有趣。
无偏差HER。替换目标以无原则的方式改变了经验的分布。这种偏差在理论上会导致不稳定,尽管在实践中还没有遇到这种情况。
HER+HRL。将HER与最近推出的层次强化学习(HRL)结合起来一定很有趣。这样一来,HER不仅仅可以应用到目标上,还能应用到较高层次的策略生成的动作上。例如,如果较高层次命令低层次实现目标A,结果实现了目标B,那么我们可以假设高层次原本命令的是目标B。
更丰富的价值函数。扩展最近的研究,并在额外的输入上调整价值函数,例如折扣因子或成功阈值。
更快的信息传播。大多数off-policy深度强化学习算法使用目标网络来稳定训练。然而,由于改变需要时间传播,就会限制训练的速度。我们注意到在我们的实验中,这是决定DDPG+HER学习速度最重要的因素。
HER+多步骤回报。由于我们更换了目标,HER上的实验是off-policy的。所以用多步骤回报使用它就变得困难了。然而,多步骤回报能让信息传播的速度更快,所以也是可行的。
On-policy HER。目前,HER只能与off-policy算法一起使用。但是,最近的算法如PPO的稳定性非常好。所以我们可以研究一下HER能否与on-policy算法一起使用。
高频动作的强化学习。目前的强化学习算法对动作过多的案例十分敏感,这就是为什么跳帧技术经常用于雅达利游戏。在连续控制领域,动作频率越趋近于无穷,性能则越趋近于零。这是由两个因素造成的:不一致的探索,和需要多次引导来传播信息。
将HER与强化学习的最近进展相结合。最近,强化学习在多个方面都有了很大进步,它可以和优先经验回放(Prioritized Experience Replay)、分布强化学习(distributional RL)以及entropy-regularized RL或反向课程生成相结合。
在论文中你可以找到关于新Gym环境应用的更多信息。
使用基于目标的环境
引入“目标”概念需要对现有Gym的API进行一些反向兼容更改:
所有基于目标的环境使用gym.spaces.Dict观察空间。环境需要包含一个智能体尝试达到的预期目标(desired_goal)、一个目前已经达到的目标(achieved_goal)、以及实际观察(observation),例如机器人的状态。
我们公开环境的奖励函数以重新计算更换目标之后的奖励。
下面是在新的基于目标的环境中,执行目标替换时的简单例子:
import numpy as np
import gym
env = gym.make('FetchReach-v0')
obs = env.reset()
done = False
def policy(observation, desired_goal):
# Here you would implement your smarter policy. In this case,
# we just sample random actions.
return env.action_space.sample()
whilenotdone:
action = policy(obs['observation'], obs['desired_goal'])
obs, reward, done, info = env.step(action)
# If we want, we can substitute a goal here and re-compute
# the reward. For instance, we can just pretend that the desired
# goal was what we achieved all along.
substitute_goal = obs['achieved_goal'].copy()
substitute_reward = env.compute_reward(
obs['achieved_goal'], substitute_goal, info)
print('reward is {}, substitute_reward is {}'.format(
reward, substitute_reward))
新的环境可以使用与Gym兼容的强化学习算法,如Baselines。用gym.wrappers.FlattenDictWrapper将基于字典的观察空间压缩成一个数组。
import numpy as np
import gym
env = gym.make('FetchReach-v0')
# Simply wrap the goal-based environment using FlattenDictWrapper
# and specify the keys that you would like to use.
env = gym.wrappers.FlattenDictWrapper(
env, dict_keys=['observation', 'desired_goal'])
# From now on, you can use the wrapper env as per usual:
ob = env.reset()
print(ob.shape) # is now just an np.array
-
算法
+关注
关注
23文章
4816浏览量
98800 -
AI
+关注
关注
91文章
41976浏览量
303077 -
人工智能
+关注
关注
1821文章
50511浏览量
267745
原文标题:OpenAI开放模拟机器人环境和HER算法,让机器人从失败中学习
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
它人机器人深度参与机器人移动算法测评规范国标制定
六维力传感器:当机器人拥有“真实触觉”,未来会发生什么?
基于米尔RK3576核心板的国产割草机器人解决方案
为什么说关节扭矩传感器是高端机器人的“触觉神经”?
再谈低温烧结银的应用:从春晚四家机器人出镜的幕后推手说起
探索RISC-V在机器人领域的潜力
高精度机器人控制的核心——基于 MYD-LT536 开发板的精密运动控制方案
RK3576机器人核心:三屏异显+八路摄像头,重塑机器人交互与感知
小萝卜机器人的故事
自制巡线解迷宫机器人(上)
什么是机器人?追溯机器人技术的演变和未来



评论