 自动驾驶环境感知——激光雷达物体检测(chapter4)
自动驾驶环境感知——激光雷达物体检测(chapter4)

1. 基本概念
相比于视觉间接地获取3D信息,激光雷达可以直接获取目标及场景的3D信息,但是激光雷达不能获取纹理、颜色等特征,因此激光雷达和相机是互补的

调频连续波是毫米波雷达测距的原理。
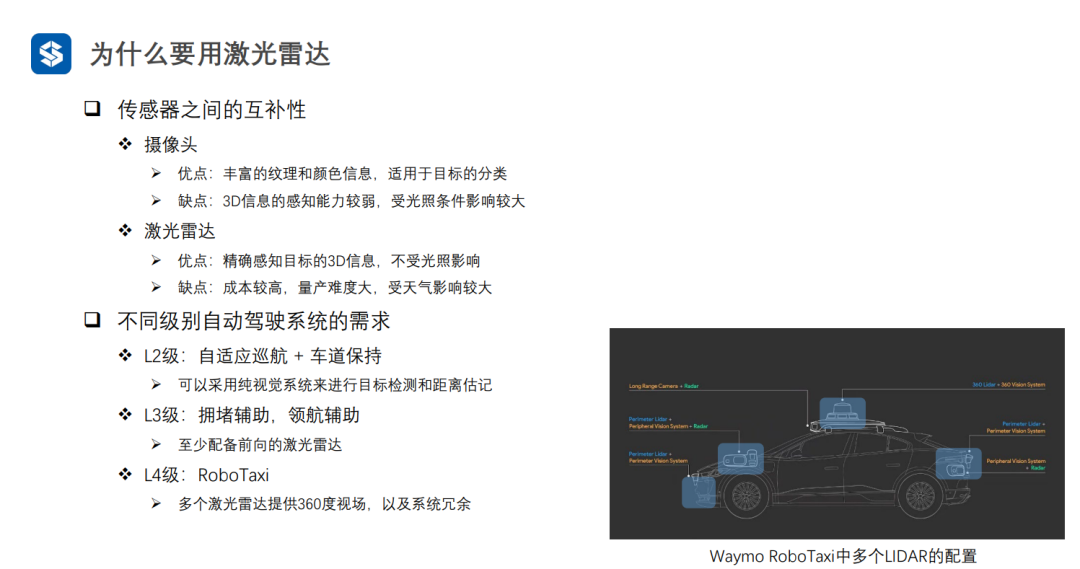
随着自动驾驶级别的提高,对于激光雷达的需求也逐渐提高。


激光雷达不仅可以做到多视图融合,还能进行多传感器融合(此时是一个状态估计问题,将不同传感器的感知结果看成是观测)。
2. 点云数据库
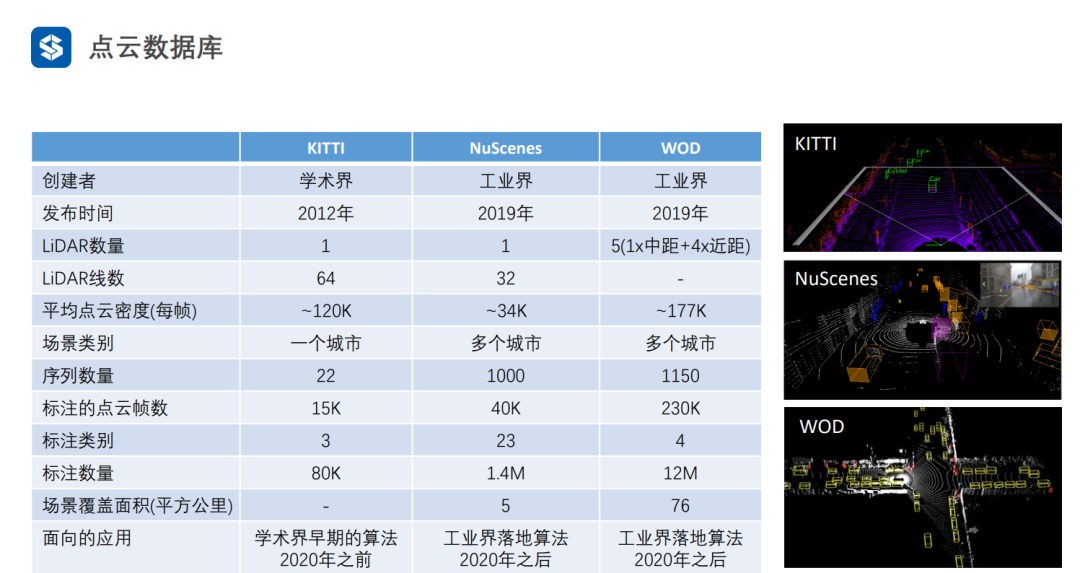
随着工业界落地需求的增加,数据集的规模也越来越大。
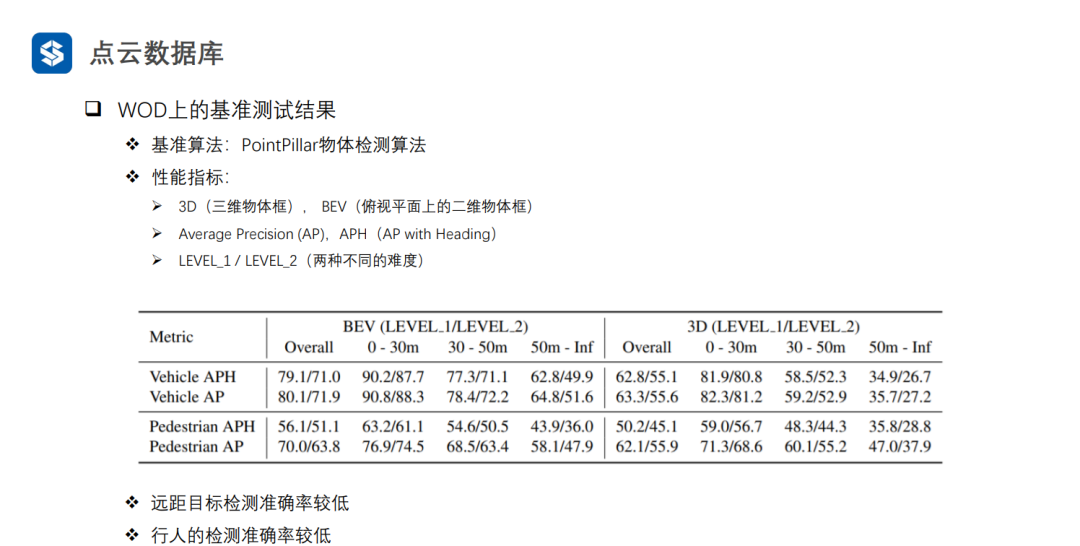
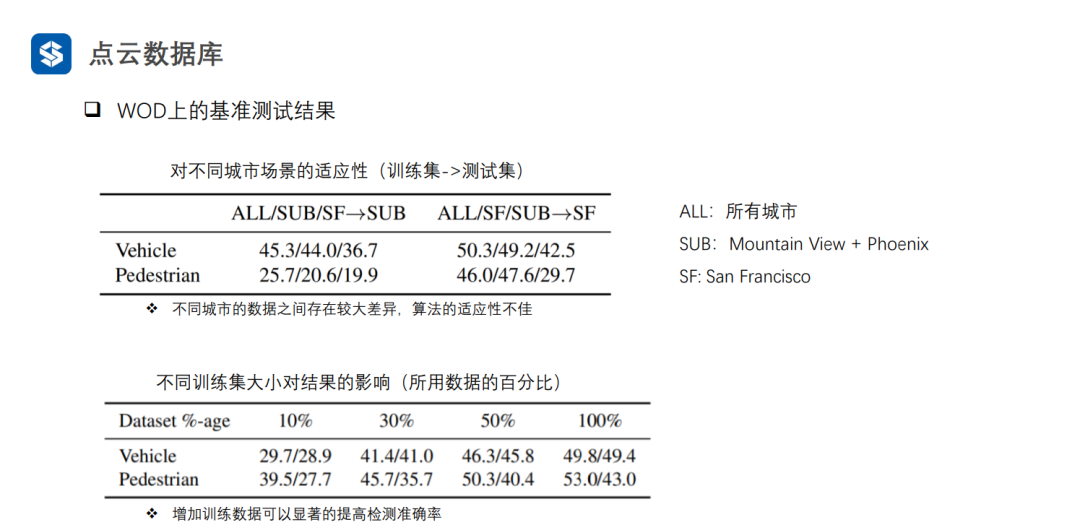
3. 物体检测算法

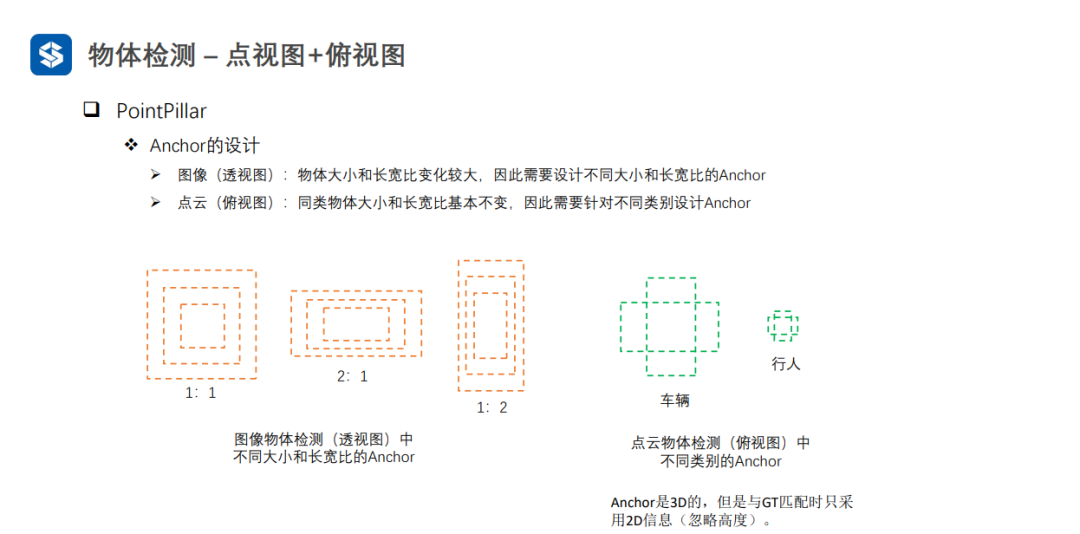
3.1点视图
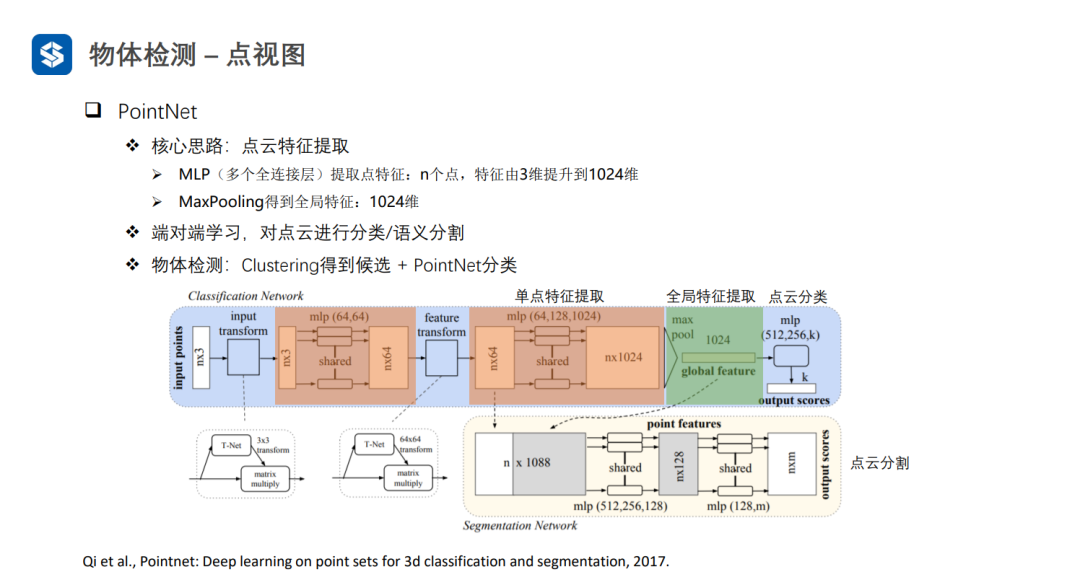

PointNet直接处理无序点云,因此在最后需要借助一个操作(例如max_poolingaverage_pooling)来消除最终的结果与点云输入顺序间的关联
PointNet++逐层提取特征扩大感受野。PointNet++可以将聚类结果作为候选框生成的依据:对聚类结果中的每个点关联一组锚框,并且进行分类与回归的操作(类似RPN网络)

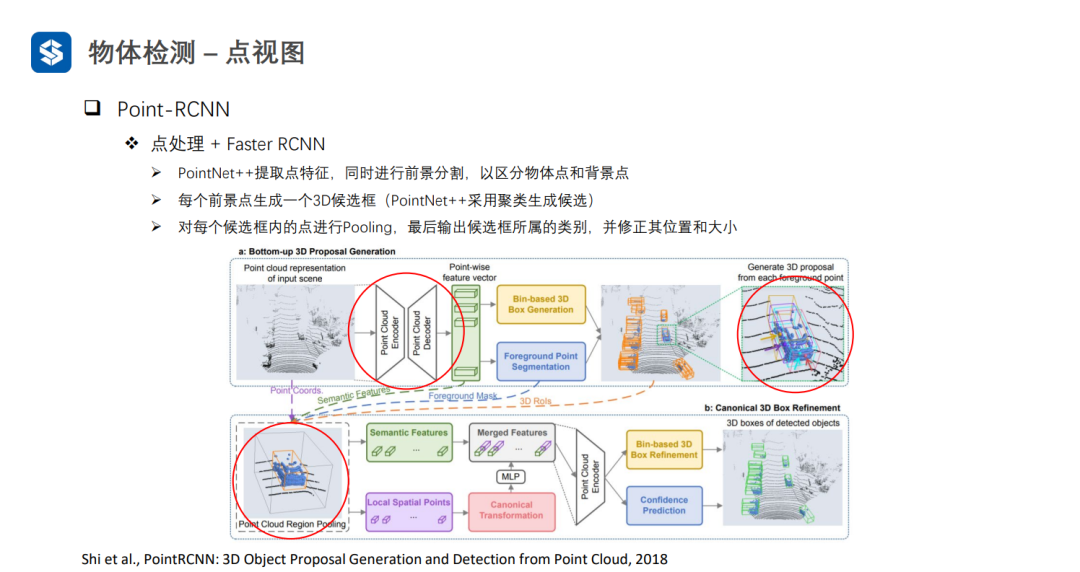
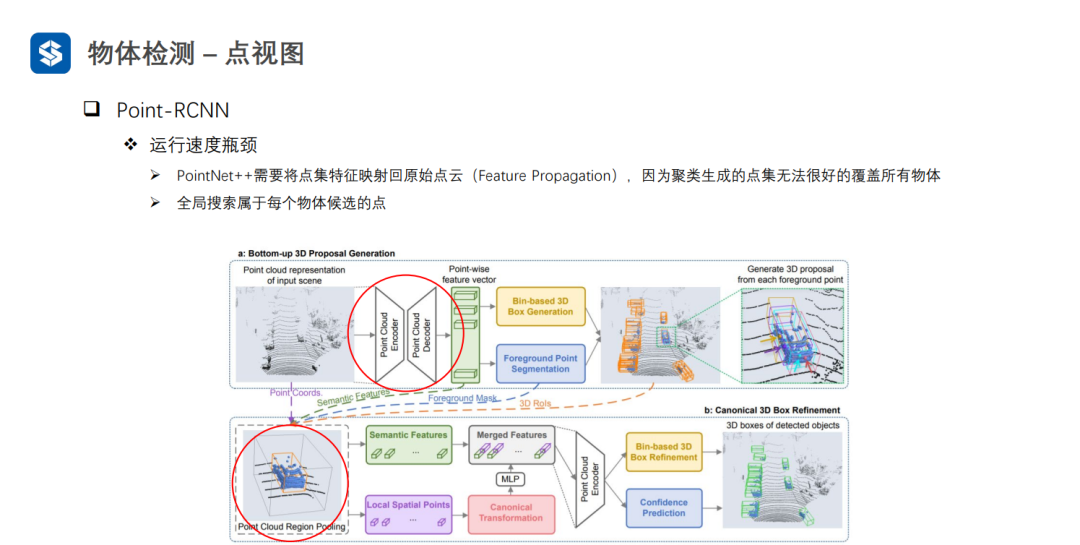
Point-RCNN通过前景分割的方式来避免耗时的聚类过程,但是也会存在较为耗时的全局搜索过程。

3D-SSD通过改进聚类的质量,直接在聚类结果上生成候选框。
3.2俯视图
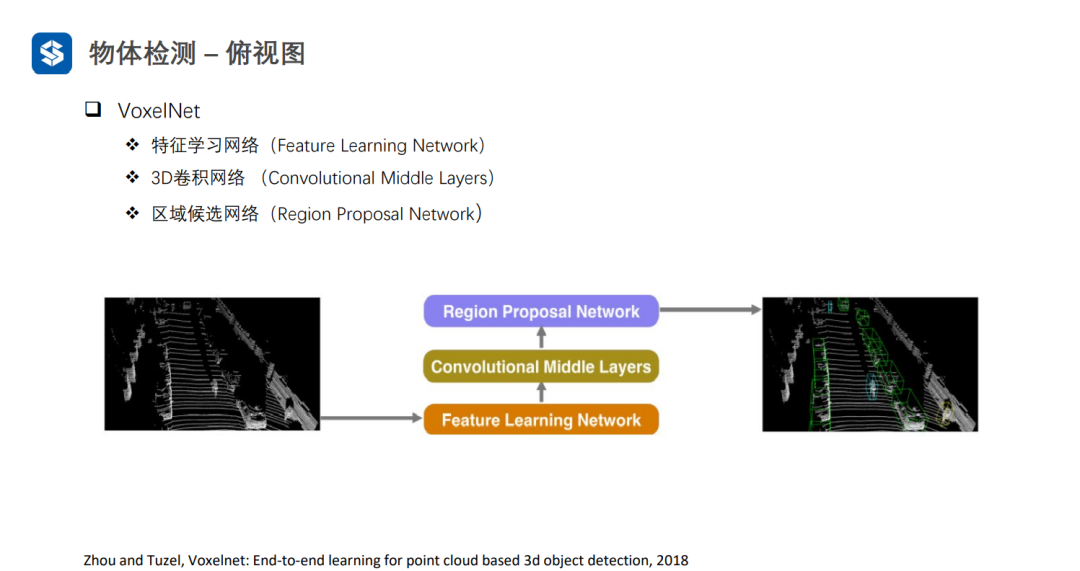
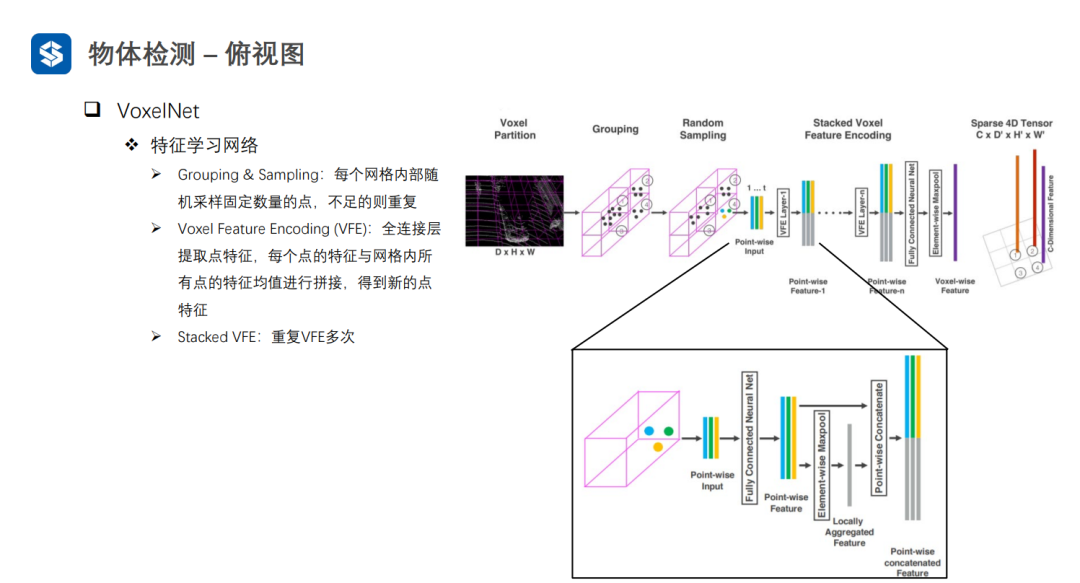
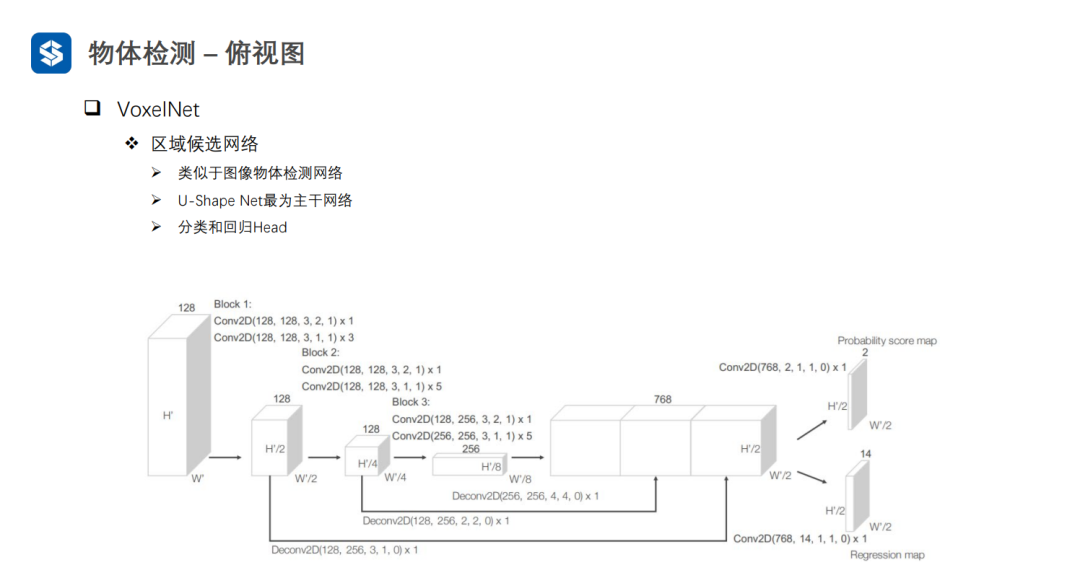
VoxelNet通过将三维空间划分成体素,并在每个体素内进行特征提取,形成四维张量(D, H, W, C)。
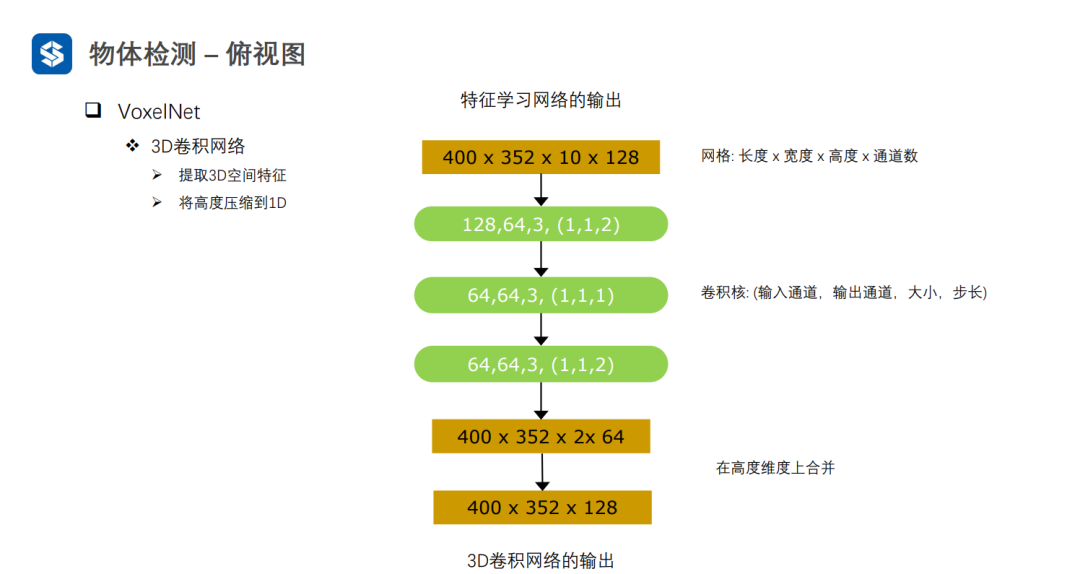
利用3D-CNN对四维张量进行特征提取,并将高度方向上压缩为1D,得到三维张量(H', W', C')。最后,利用2D视觉感知算法进行检测任务。

VoxelNet在划分体素时,由于点云是稀疏的,会导致大量体素是空白的,这样在进行3D卷积时会造成很多无效计算。
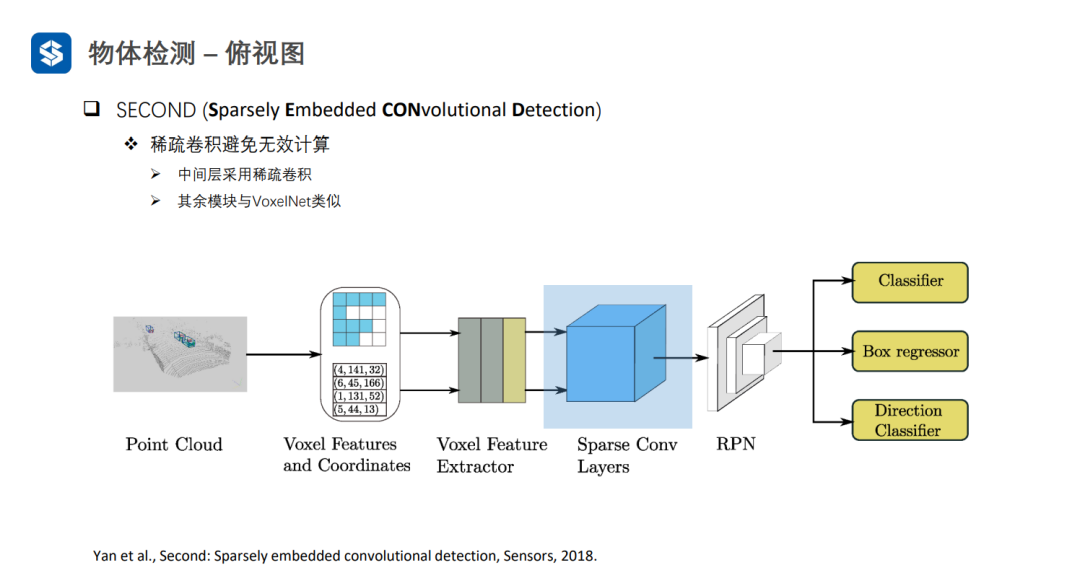
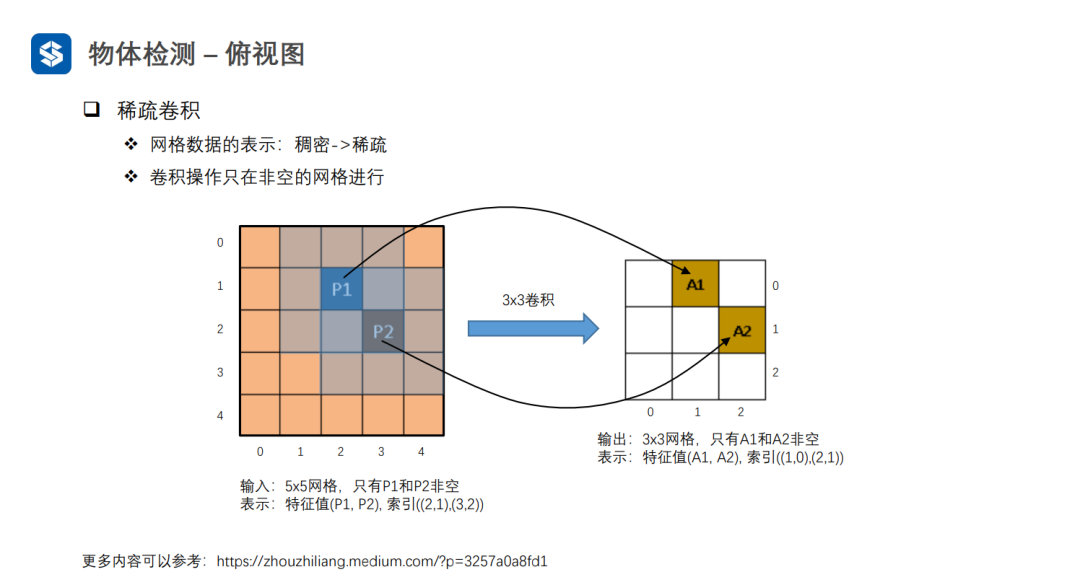
SECOND采用稀疏卷积避免空白体素区域的无效计算
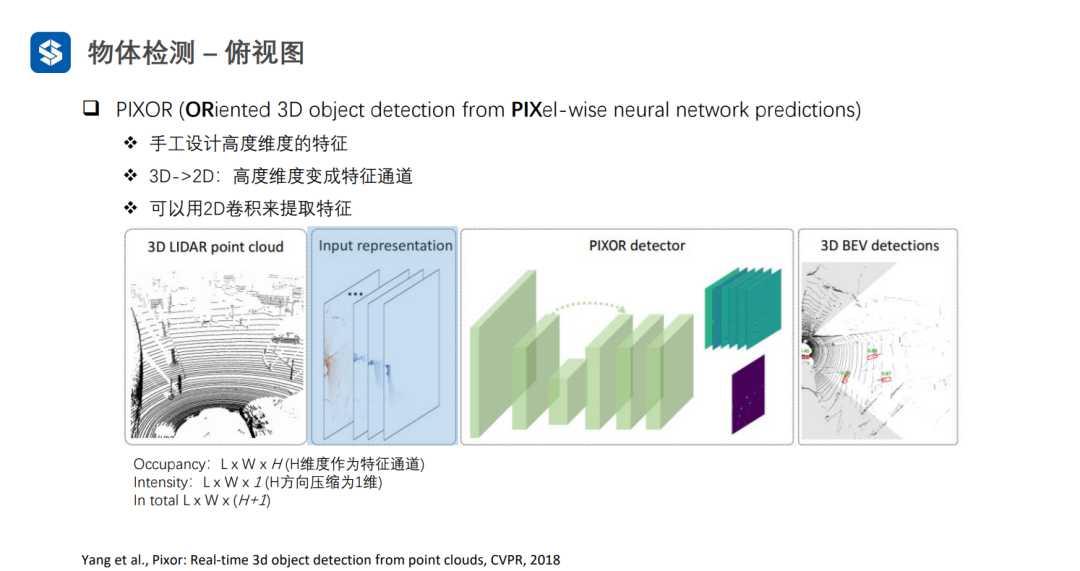
PIXOR将高度方向划分为H个等级,如果有点云落在某个格子里,此处的Occupancy为1,且Intensity为格子里点云强度的均值。
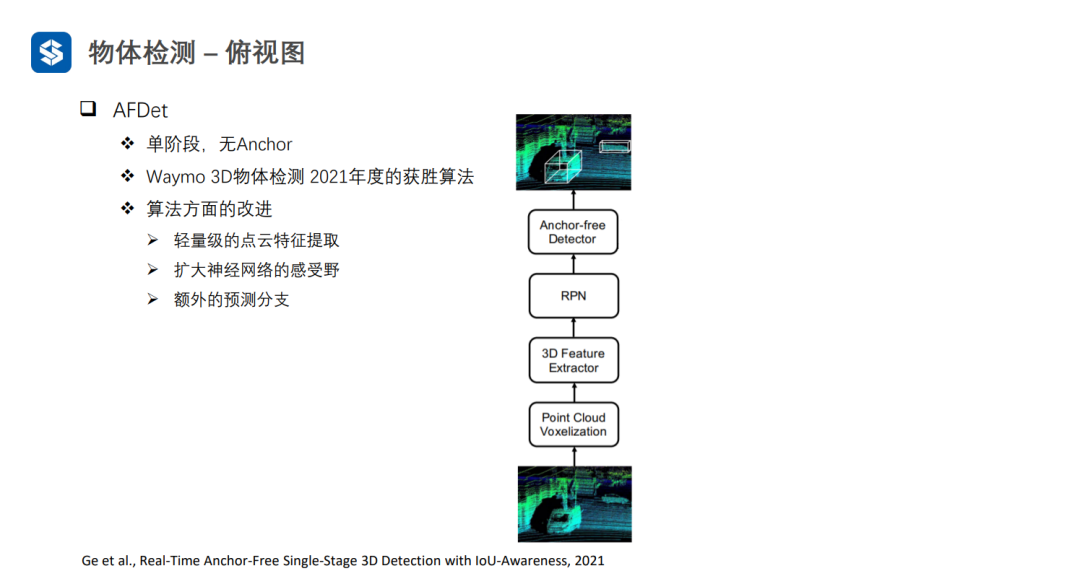
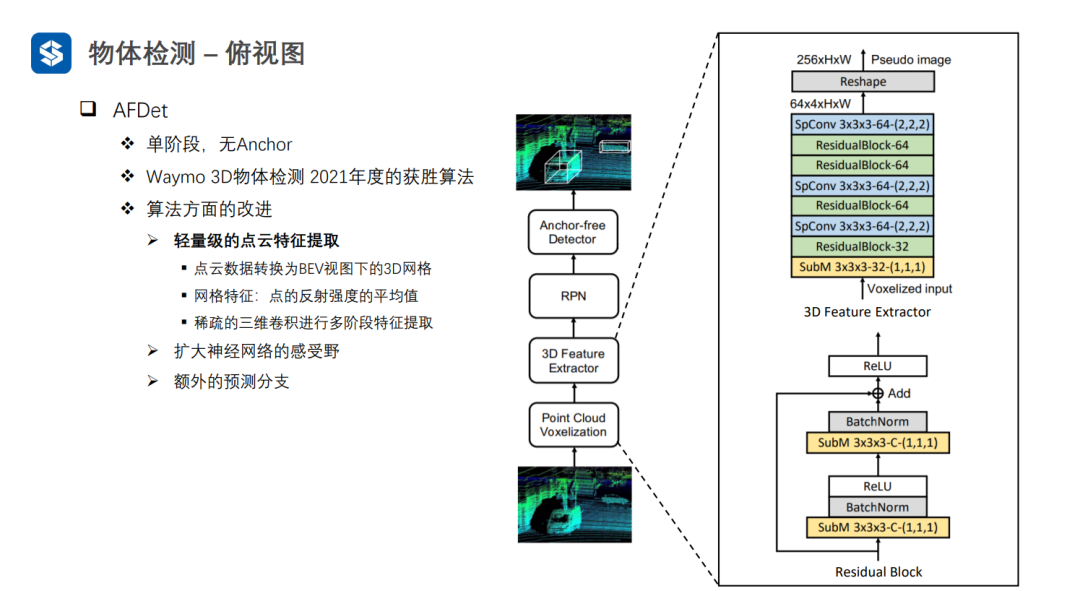
AFDet经过轻量级的点云特征提取,首先将点云体素化,并且每个体素的特征为点云反射强度的均值,再用稀疏3D卷积进行特征提取。这样,可以将四维张量变为伪图像的三维张量。
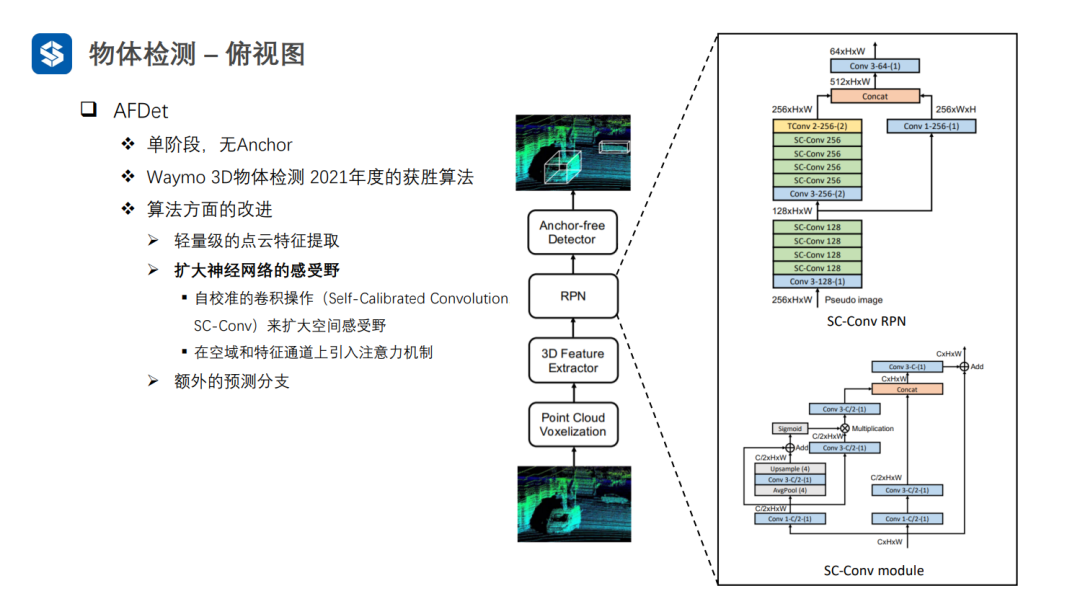
AFDet中的自校准卷积其实就是对三维张量施加了注意力机制。
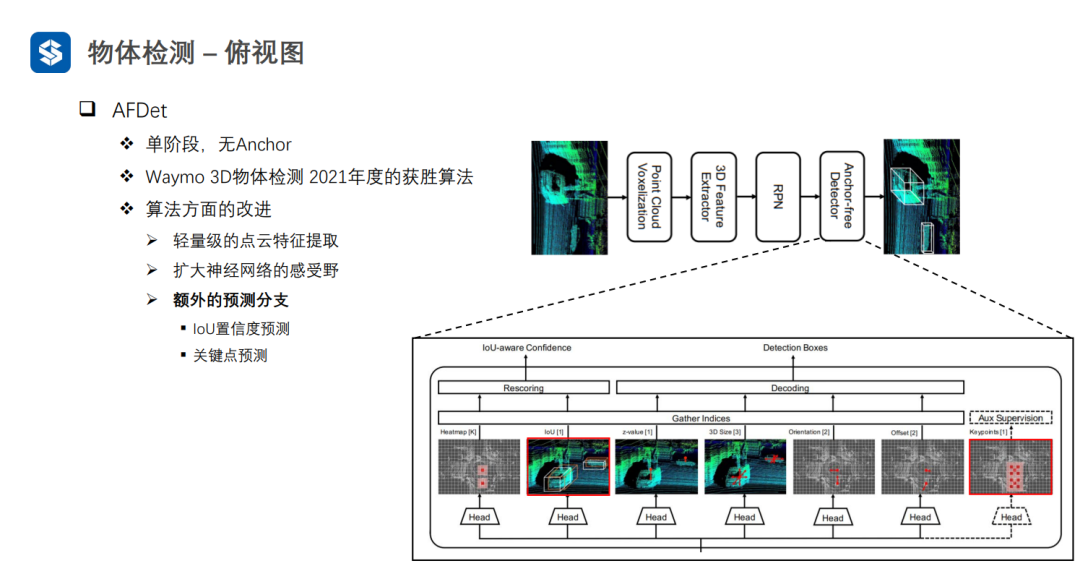
AFDet与CenterNet比较类似:先预测中心点的objectiveness,然后结合z轴方向的预测,可以得到物体在三维坐标系中的位置;接着预测物体框的大小和朝向,以及物体中心点的偏移;同时,会加入物体框的IOU置信度预测(衡量框的质量好坏,因为中心点objectiveness不包含框质量的信息)和关键点预测
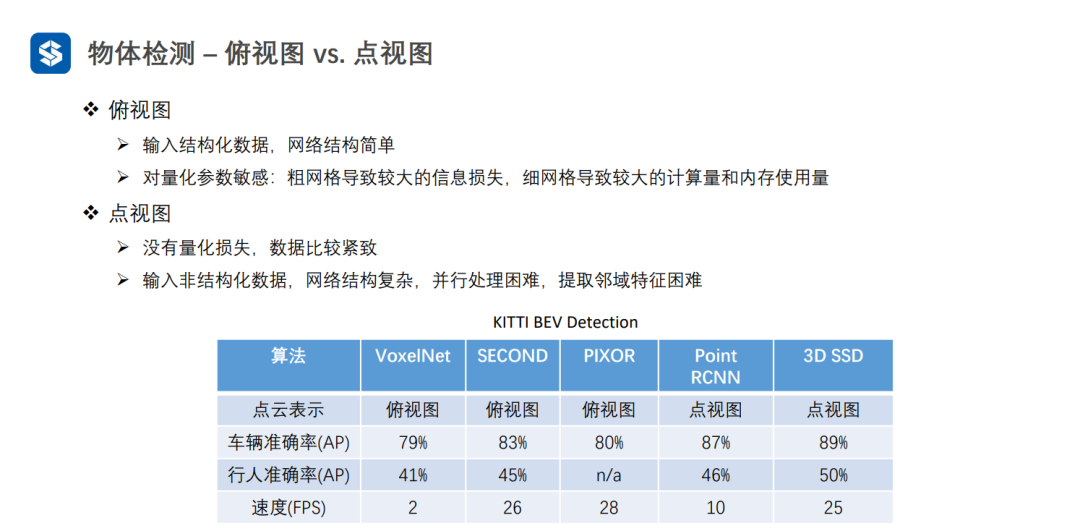
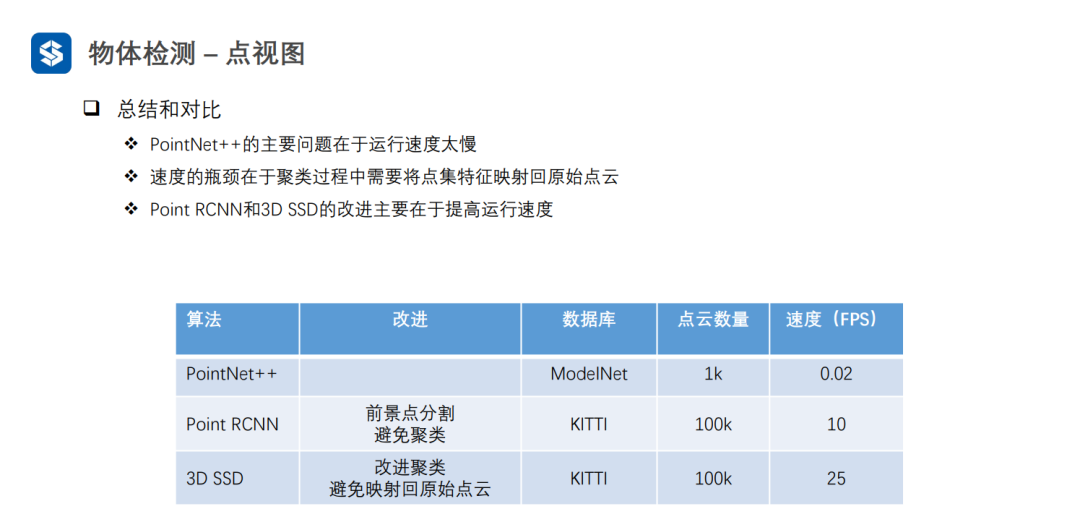
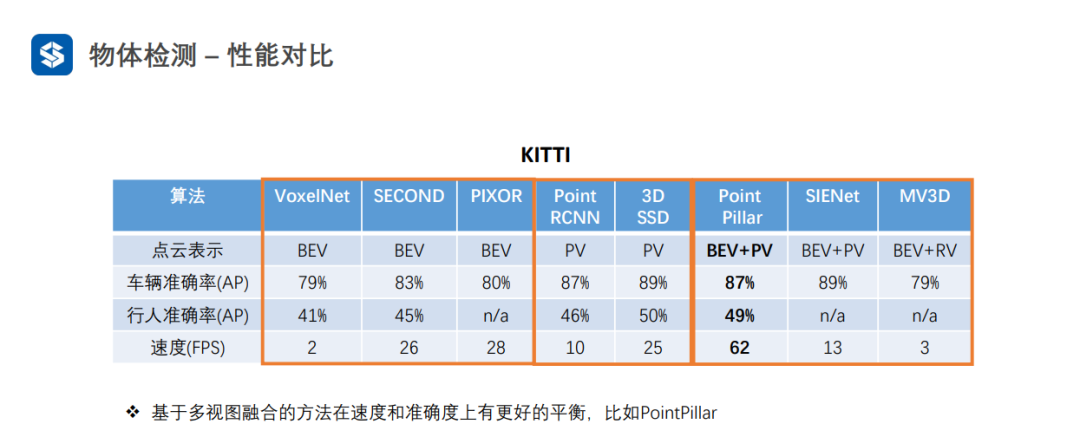
点视图的精度一般较高,因为没有量化损失
俯视图可以并行优化,一般速度较快
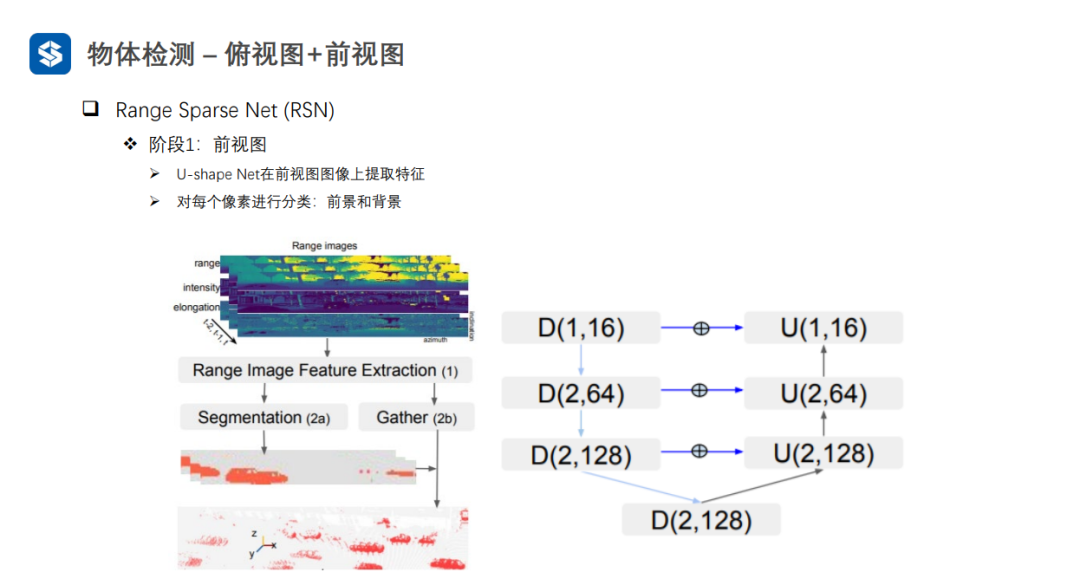
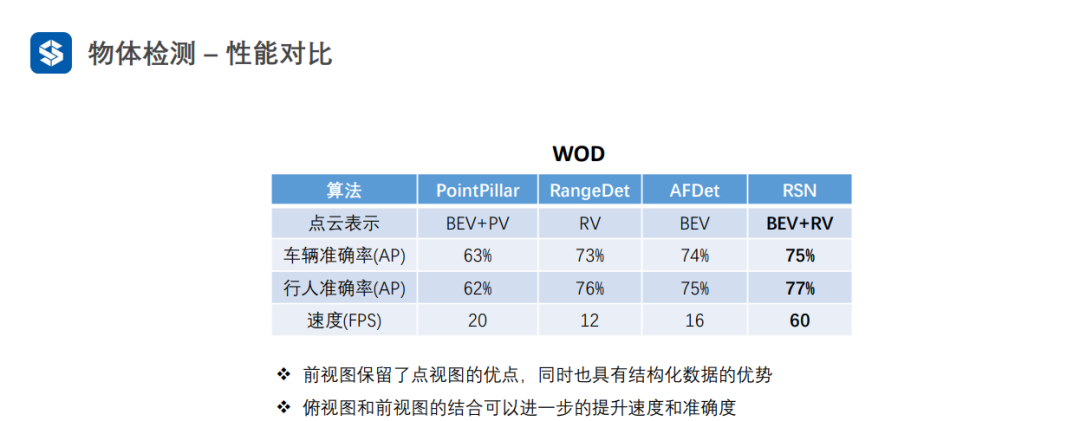
3.3 前视图

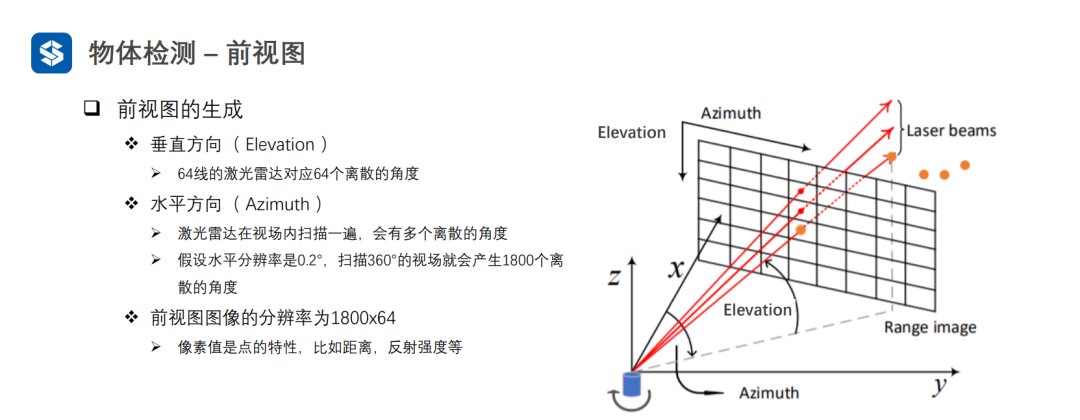
前视图虽然是网格结构,但是编码了三维空间信息,因此需要设计额外的操作来提取空间信息。


采用普通卷积提取特征,会损失空间信息
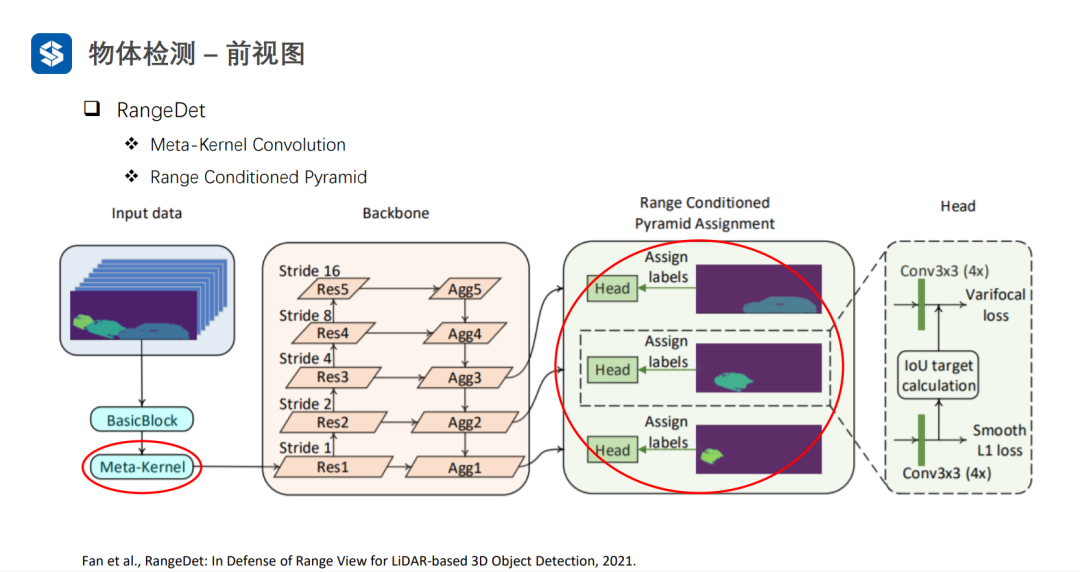

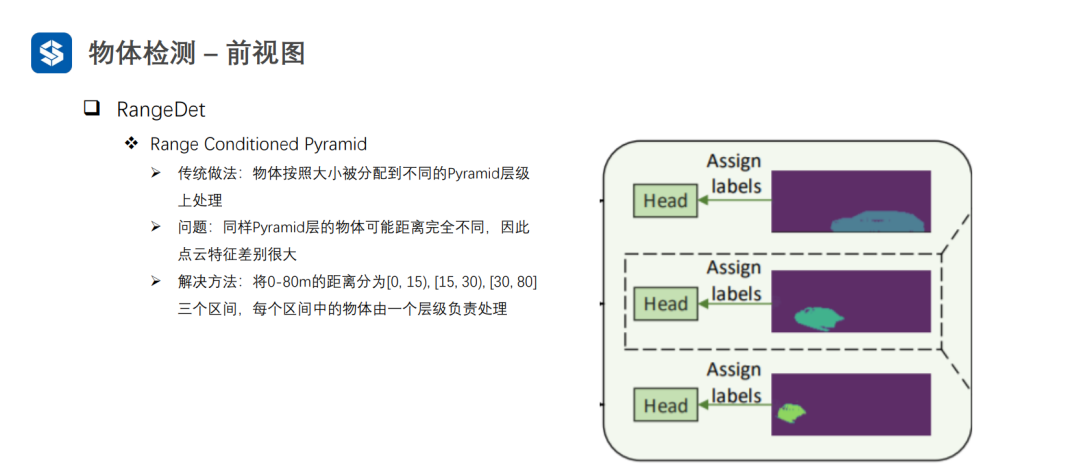
Meta-Kernel是动态变化的:1)对于同一样本的不同位置是不同的;2)对于不同样本相同位置也是不同的。普通卷积对于不同样本的相同位置都是一样的。因此,Meta-Kernel可以看作是对样本和位置的一种注意力机制。
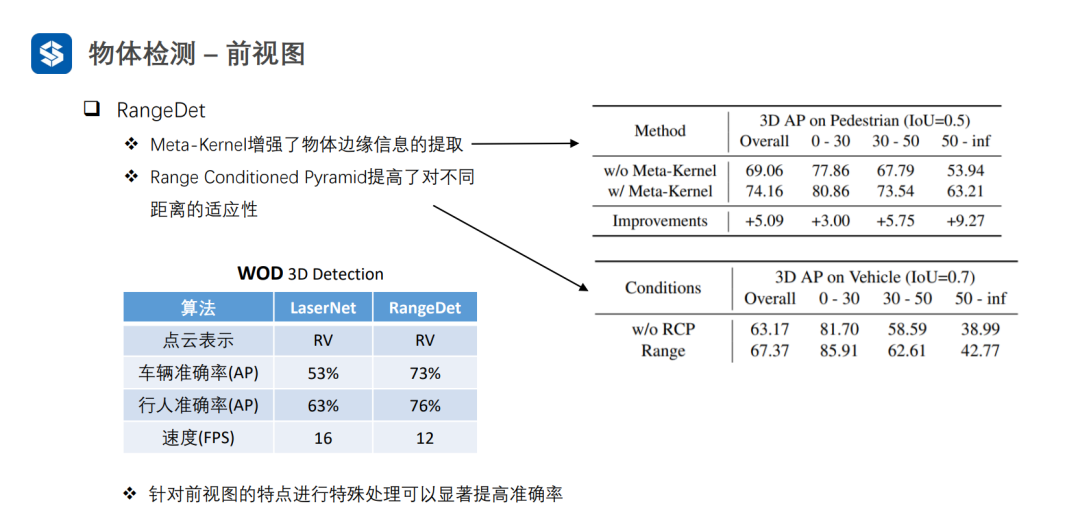
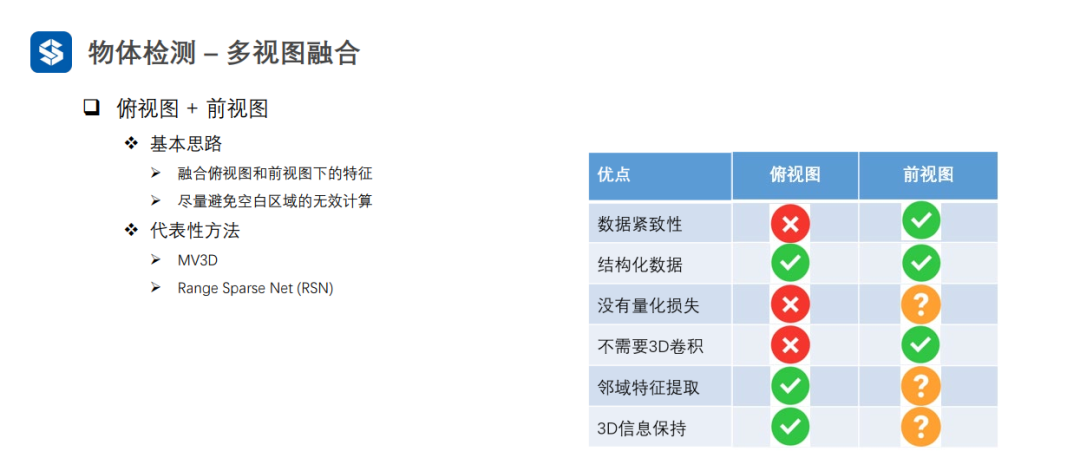
3.4 多视图融合

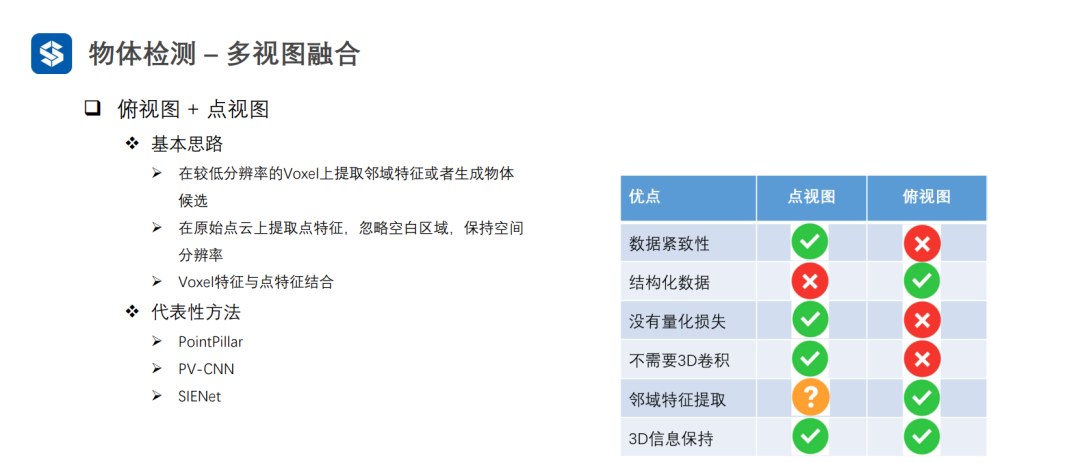
Voxel特征可看作粗粒度的特征,而点特征可看作细粒度特征
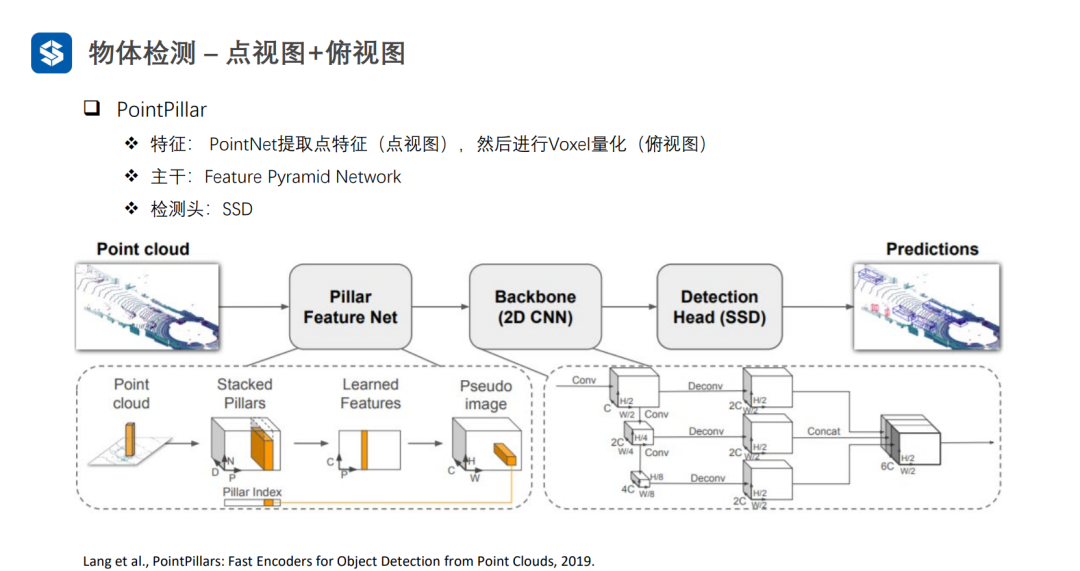
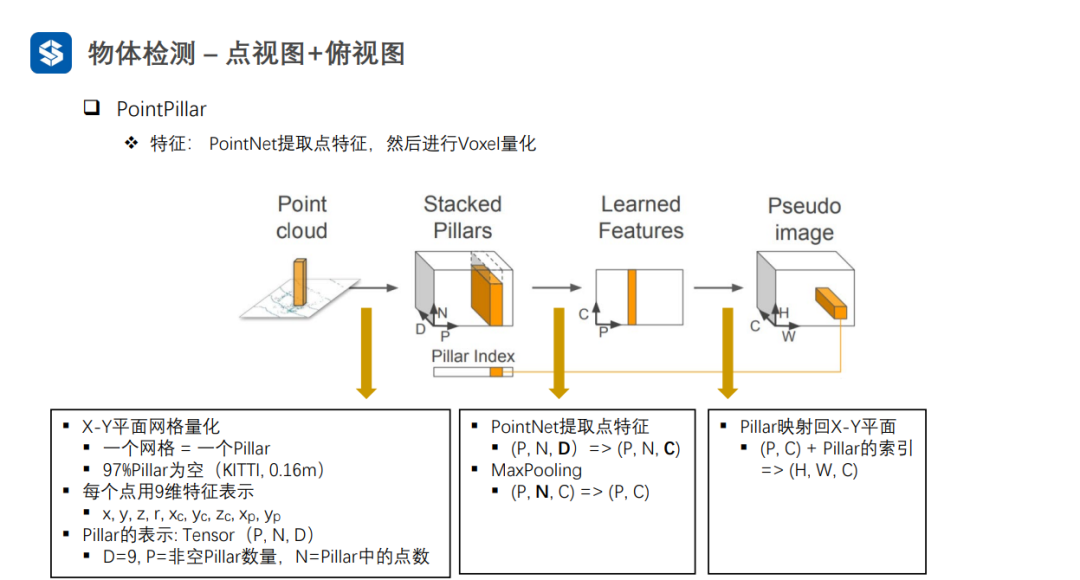
每个Pillar内部采用PointNet进行特征提取,并采用MaxPooling将同一个Pillar内部多个点的特征压缩成一个全局特征,从而形成伪图像
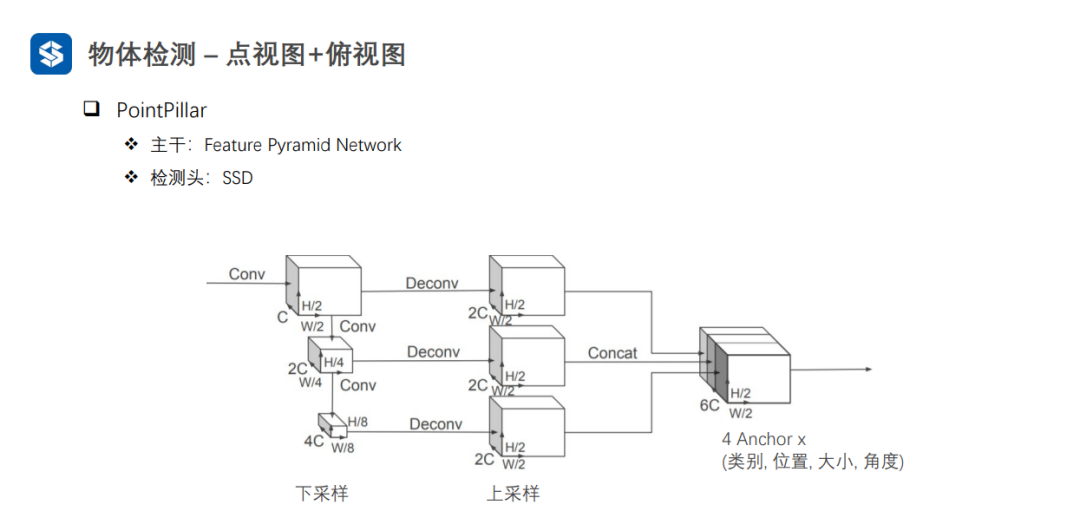

当预测的角度与真实的角度相差180°时,Δθ的损失值一样,因此加入L_dir弥补这一缺点,但是权重要小一点。





粗粒度与细粒度特征的融合

对候选框中的稀疏点集进行扩展
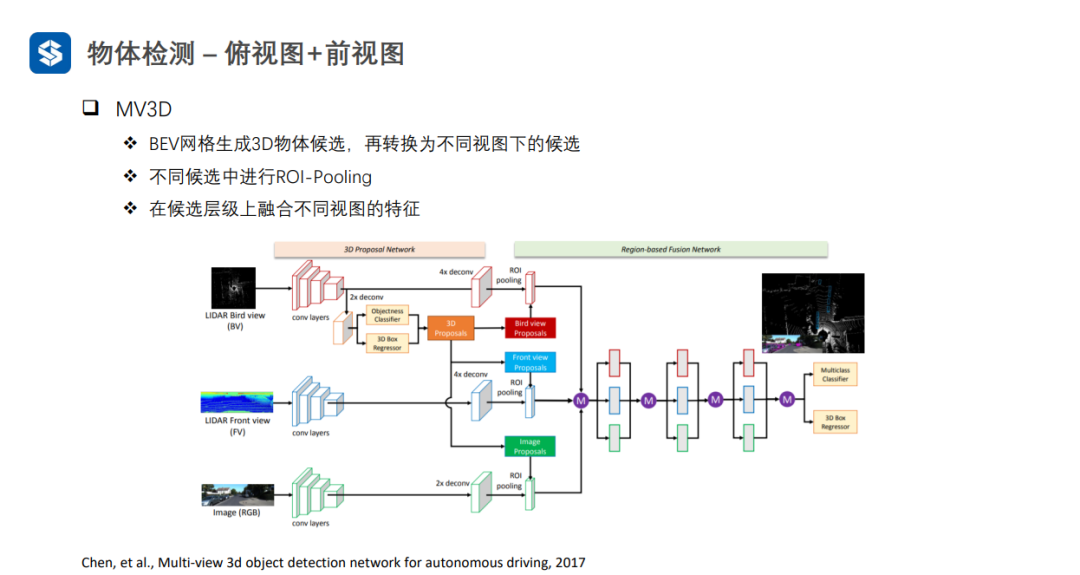
将3D proposal分别向bevfront viewimage上投影


在俯视图上通过自车运动的补偿,融合多帧信息进行检测(可以将多帧图像拼接在一起送入检测网络提取特征,并进行检测)



-
激光雷达
+关注
关注
983文章
4595浏览量
197408 -
自动驾驶
+关注
关注
795文章
15056浏览量
181992 -
毫米波雷达
+关注
关注
110文章
1185浏览量
66463
原文标题:自动驾驶环境感知——激光雷达物体检测(chapter4)
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
为啥自动驾驶不使用1550纳米激光雷达?

自动驾驶激光雷达无法识别反光背心吗?
4D点云加持,FMCW激光雷达助力自动驾驶更安全可靠

调频连续波(FMCW)为什么是自动驾驶激光雷达的未来?

FMCW和ToF激光雷达,哪种更适合自动驾驶?
自动驾驶激光雷达会伤害人体吗?
如何设计自动驾驶传感器失效检测与容错策略?
如何为自动驾驶汽车选择一款合适的激光雷达?

自动驾驶里的激光雷达有何作用?

如何确保自动驾驶汽车感知的准确性?

决定自动驾驶激光雷达感知质量的因素有哪些?




评论