 检索增强的语言模型方法的详细剖析
检索增强的语言模型方法的详细剖析

本篇内容是对于ACL‘23会议上陈丹琦团队带来的Tutorial所进行的学习记录,以此从问题设置、架构、应用、挑战等角度全面了解检索增强的语言模型,作为对后续工作的准备与入门,也希望能给大家带来启发。
1 简介:Retrieval-based LMs = Retrieval + LMs
首先对于一个常规的(自回归)语言模型,其任务目标为通过计算
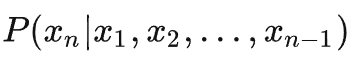
并加以采样来预测句子中的下一个token,以此来完成对于整个句子的生成。
掩码语言模型/编码器-解码器语言模型的概率计算方式与此不同,但在此不做过多讨论。
而检索增强的语言模型通过给语言模型挂载一个外部知识库,在语言模型进行生成的同时也在知识库中检索相关文档,以此来对语言模型的生成进行辅助。
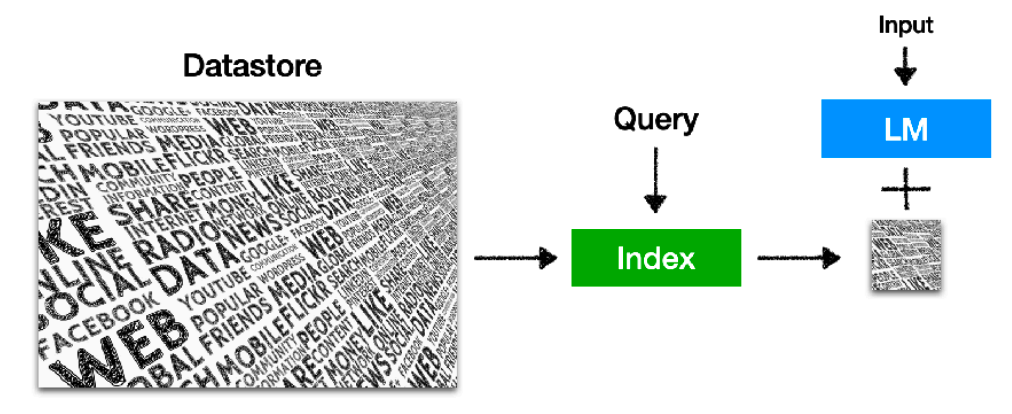
Retrieval-based LMs概念图
然而,现有的(全参数)大语言模型已经展现出了强劲的性能。我们为什么要使用检索增强的语言模型?以及检索增强的语言模型能够解决常规语言模型怎样的缺陷?
1. LLMs不能够仅通过参数来记忆全部的长尾(long-tail)知识。
所谓长尾知识,即为不热门不常用的知识(e.g. 河北省2020年的总人口数有多少)。现有工作[1]也已指出,仅遵循scaling law扩大模型规模,对于长尾知识也只能够提供较小的性能提升,实际的性能提升仍为较为常用和热门的知识所提供的。这证明语言模型本身对于长尾知识的记忆及应用能力仍然较差,而这种“较差”与模型的规模并无直接关联。通过对知识库的检索可以对这方面知识有更好的“回忆”作用。
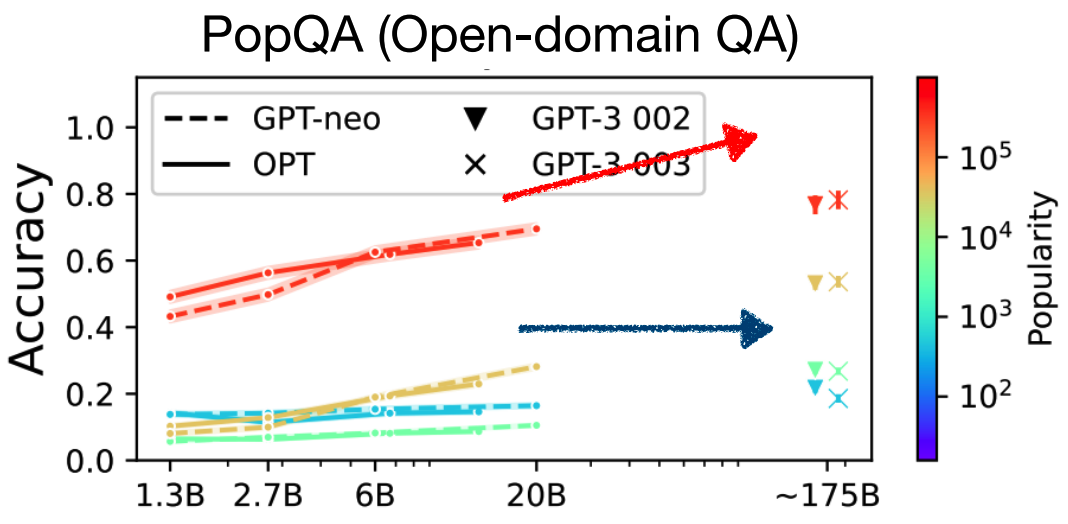
Performance on less popular questions (blue) doesn’t improve over scale
2. LLMs通过参数所记忆的知识很容易过时,并且难以更新。
如今互联网的信息呈爆炸式增长,知识更新速度极快,而语言模型通过参数所记忆的知识只能够保证是当时数据收集时的最新,而无法与时俱进,且语言模型预训练的消耗量极大,无法完成对于知识的频繁更新。虽然现有的所提出的一些“知识编辑”的方法可以对此问题有一定的缓解作用,但是可扩展性不佳。而对于检索增强的语言模型来说,仅需要对于外部的知识库进行更新即可解决此类问题,且更新知识库的花费相比于重新训练一个语言模型甚至是可以忽略不计的,并且对外部知识库内的知识可以很容易地实现规模的扩张。
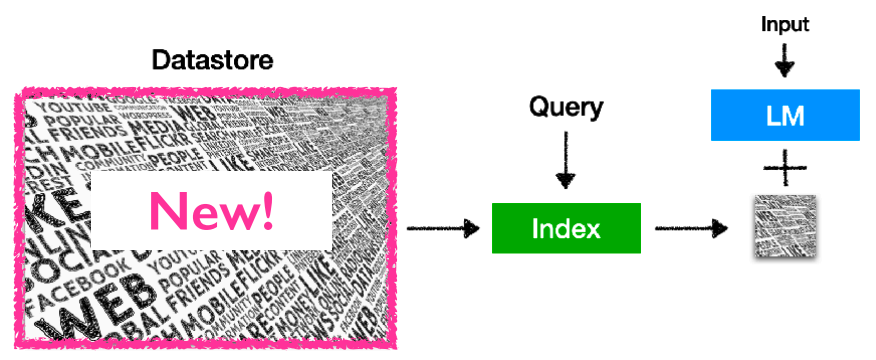
Retrieval-based LMs仅通过更新外部知识库实现对于知识的更新
3. LLMs的输出难以解释和验证。
我们通常很难对于语言模型所给出答案的原因以及依靠来源进行分析,这便导致我们很难去判断语言模型这个“黑箱”内部的真实运行逻辑,也使得我们无法完全相信其所给出的答案(即使通常情况下是正确的,但也是不可解释的)。而检索增强的语言模型通过返回检索得到的外部文档作为依靠,我们可以很容易地知道模型正在依靠怎样的文本知识去进行当前内容的生成,通过分析及验证其检索到的相关文档,来理解模型生成当前内容的运行逻辑。
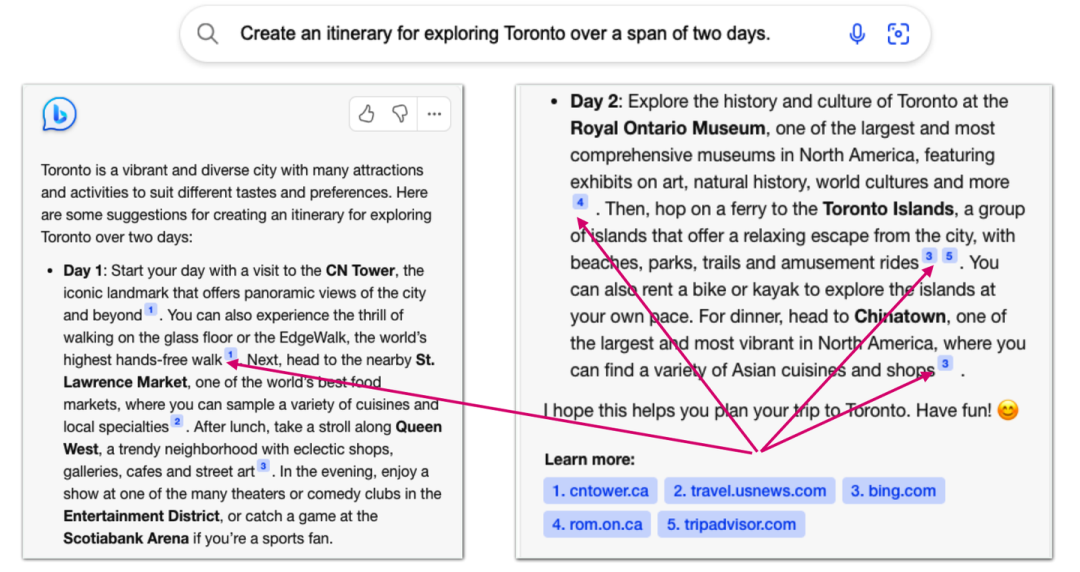
NewBing给出文档来源的示例
4. LLMs很容易泄露隐私训练数据。
如果将隐私数据(e.g. 用户住址、联系方式等)加入语言模型的预训练阶段,则使用语言模型的所有人均能够接触到这部分数据,显然这会造成用户隐私数据的泄露(OpenAI的ChatGPT也曾经面临过此类问题),并且此类问题难以通过指令微调或者偏好对齐的方式进行彻底解决。而检索增强的语言模型允许我们将隐私数据存储在外部的知识库中,而与语言模型本身参数没有关系,语言模型可以通过访问知识库中的这部分数据来为我们提供更为个性化的服务,保护隐私的同时也能够提高其个性化定制的能力。
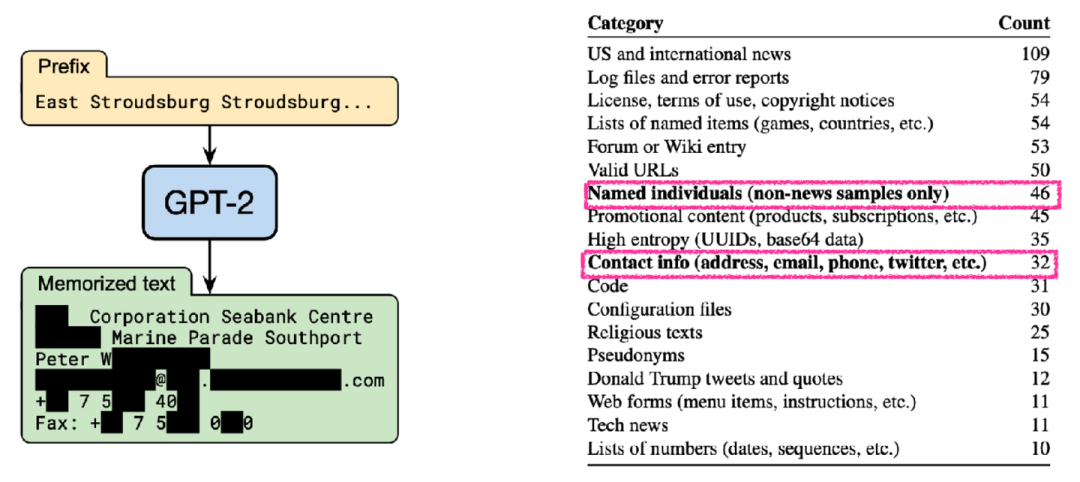
部分隐私数据被包含在了预训练语料之中
5. LLMs规模极大,训练和运行均极其昂贵。
不光是训练一个大语言模型,将其部署且运行推理的花费也极其昂贵。而我们尝试通过检索增强的语言模型来减少语言模型本身的规模,实现一个较小的语言模型也能够达到与大语言模型相媲美的性能。这显然更加经济,长期效果来看无论是对于学术界还是小规模的公司也更加友好。(现有检索增强的语言模型工作[2]以25倍的参数缩减,实现了与GPT-3所匹配的性能)。
检索增强的语言模型已然成为了目前较为关键的研究问题,值得深入探索。
2 问题定义:一个在测试阶段使用外部知识存储的语言模型
对于该定义,我们可以分为两个部分来看:1)语言模型;2)在测试阶段使用外部知识存储。
而对于1)语言模型,则无需过多解释,无论是目前性能较为work的自回归Decoder-only语言模型,还是几乎同期出现的Encoder-only/Encoder-Decoder语言模型均可以被考虑在内。
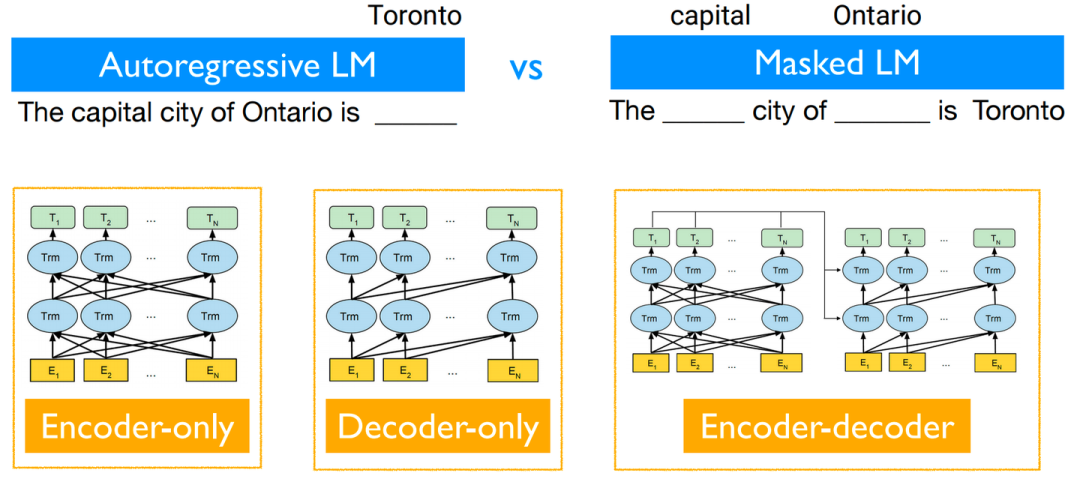
不同解码方式/架构的语言模型
而预训练+Prompting是目前对于语言模型较为常用且十分work的训练范式,使语言模型能够适配较多的下游任务,以达到通用化需求,其中可以适配的常见下游任务如下图所示(不完全):

语言模型通过Prompting后适配的多种常见下游任务
且对于训练好的模型,我们通常可以通过两种评估手段来判断模型性能的好坏,分别为:困惑度(Perplexity)和下游任务准确度(Downstream Accuracy)。
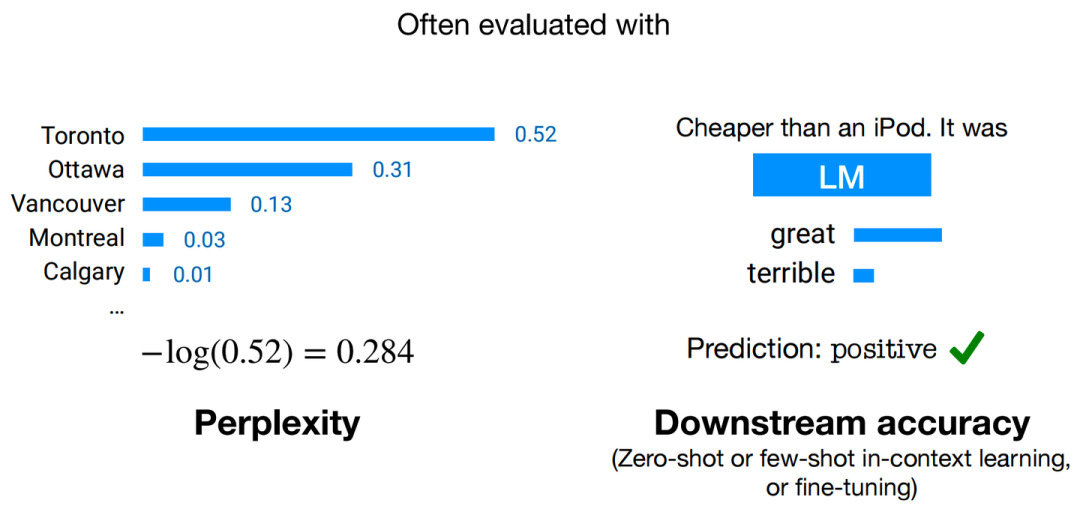
两种常用评估手段
其中,Perplexity的计算方式为:
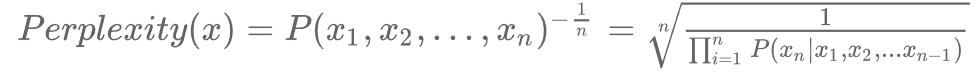
为方便计算,语言模型的实际评估过程中常使用log-perplexity进行计算(与上图示例中相同),即只需要外套一个log,计算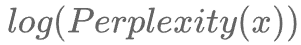 即可。
即可。
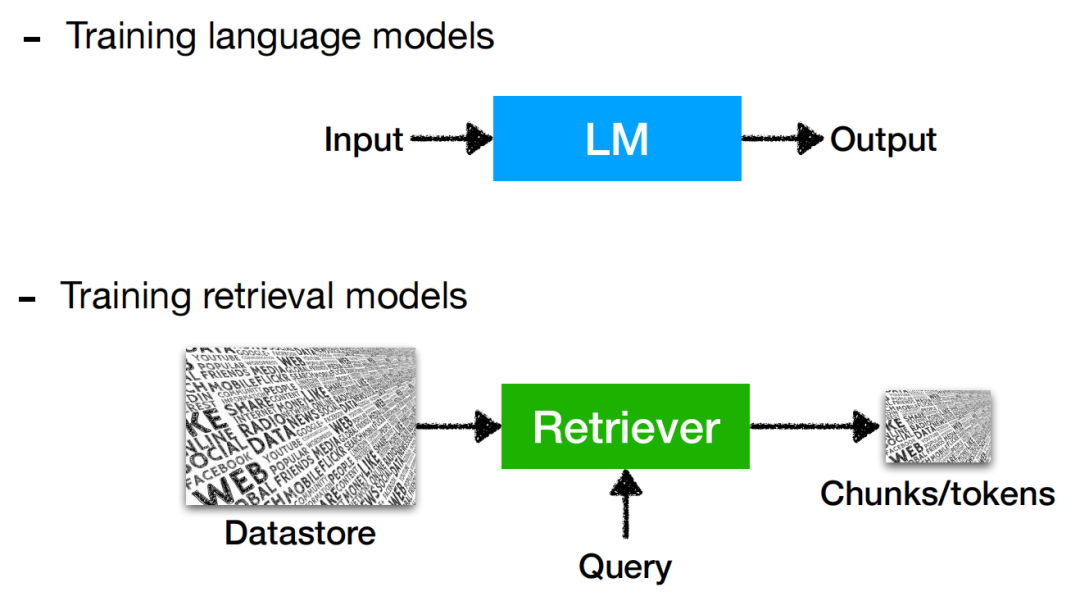
进一步的,对于2)在测试阶段使用外部知识存储,具体形式如下图所示:
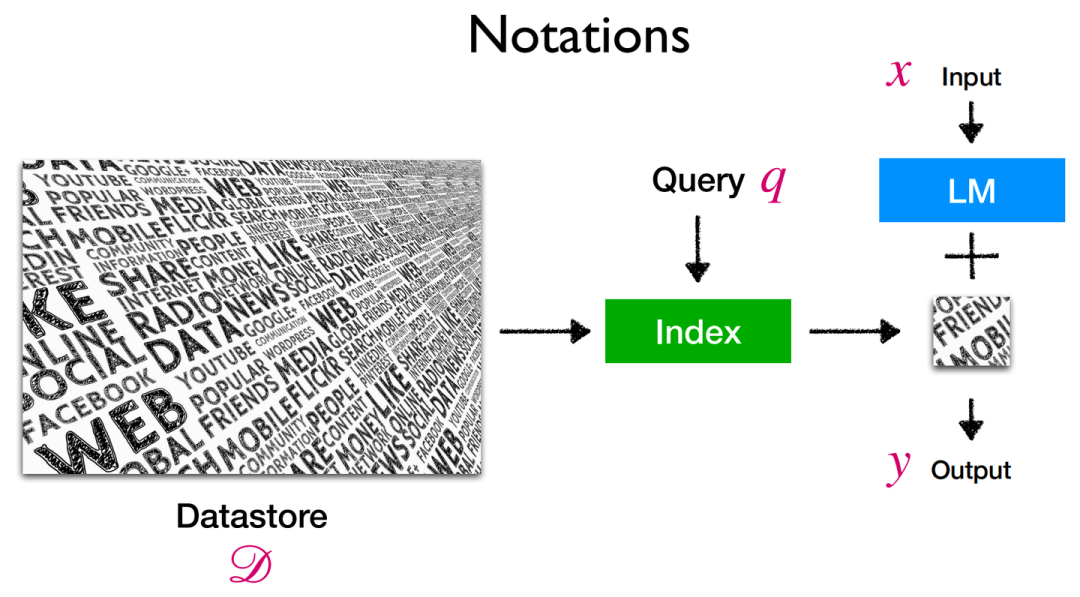
Retrieval-based LMs推理阶段示意图
首先对于Datastore,其内部组成大多为原始文本语料,即包含至少1-10B token的无标签且非结构化数据(也有部分的知识库为向量存储形式)。而上图中的Query即代表用于检索的查询,该检索查询q与输入语言模型的x并不一定相同。Index即为在知识库D中查找得到的与检索查询q最相似的一小部分(Top-k个)元素子集,这也是我们在知识库中的查询目标。
在此涉及到了相似度的计算,则便衍生出多种可选的相似度度量方式,可以是类似于TF-IDF的传统计算方式,也可以是对嵌入向量间的点乘计算方式等等。同时检索的方式也包含了精确检索/近似检索,此即为检索开销与检索精度间的trade-off了。

两种文本间相似度计算方式示例
而对于上述全部的定义,我们提出三点需要解答的问题以供后续展开:
(When)检索查询是怎样的 & 何时执行检索操作?
(What)检索何种形式的内容?
(How)如何去利用检索得到的内容?
3 架构:What & How & When
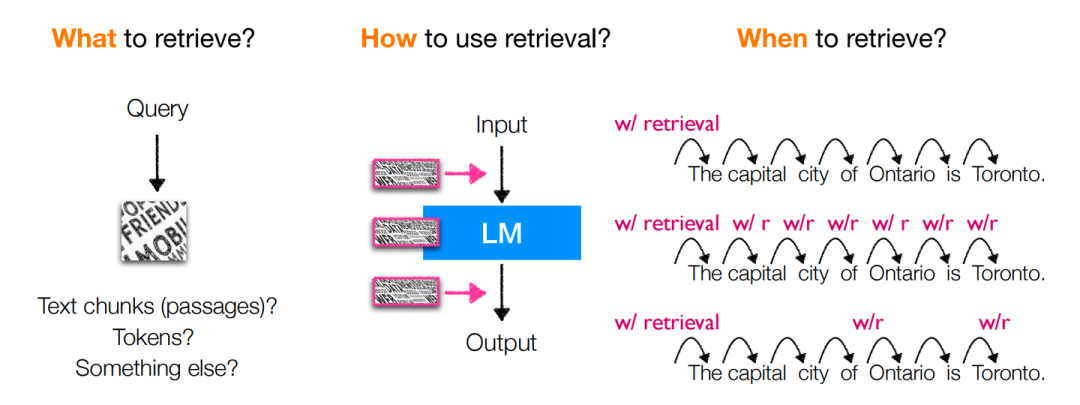
上图即为对于以上所提出的三个问题的回答,可总结为下表:

分别对于各个情况进行对比讨论,则我们可以从具体性能与经验上可以得到下述结论:
1)对于“What to retrieve?”:
直接检索chunks能够降低检索难度(因为原始语料中多数文本也正以大段的形式存在),且空间上更加友好。
相比于检索chunks,检索更细粒度的tokens可以更好地利用罕见模式(e.g. 检索表示深度学习算法包的“torch”,而非火把“torch”)以及领域外知识(OOD),并且检索也会非常高效(kNN搜索本身即十分高效),但会导致数据存储在空间上开销更大(e.g. Wikipedia:chunks-13M v.s. tokens-4B),并且语言模型输出结果与检索结果之间并无交叉注意力计算,性能因此会受到部分损害。
除这二者之外,检索entity mention同样为一种可行方式,其思想可归纳为“One vector per entity mention”,即去知识库中检索查询中所出现的实体对象,在以实体为中心的任务中更加有效,相比于检索token,在存储空间上也更加友好,但同时也需要增加额外的实体检测操作。
2)对于“How to use retrieval?”:
在input layer直接加入检索到的文档显然十分简单直观,在面对大量、频繁的文档检索场景时是十分低效的。
而在intermediate layer应用检索到的信息,相比于直接在input layer添加检索到的文档,可以利用语言模型的更多块(block),以支持更频繁的检索,使计算更加高效,但同时也会引入较多的复杂度,使得整个模型无法不经训练直接使用。
在Output layer应用检索信息则是对于语言模型预测token与检索得到的token概率进行的加权聚合(以kNN-LM为代表),同样可以不经训练便可以直接使用,关键更多在于存储各种token上下文时的空间开销。
3)对于“When to retrieve?”:
上表中所提及的三种检索频率,应用上更多是根据剩余两个问题所决定的架构而调整的,但我们可以发现上述三种选择大多数情况下均为固定的检索频率。当前也正有工作向着自适应的检索频率进行发展,即当语言模型对给出答案置信度较高时,不执行检索或降低检索频率,反之更加频繁地执行检索操作。抑或是在Output layer进行对于预测token的概率加权聚合时,将各个组件的权重视作与输入x有关的函数,以动态调整检索与语言模型预测结果对于最终输出结果的作用权重。自适应的检索频率能够提高效率,但最终的结果可能不是最优的。
由于所涉及到的各个工作实现细节过于繁多,在此并不展开来讲,可根据下方总结图表进行对应索引:
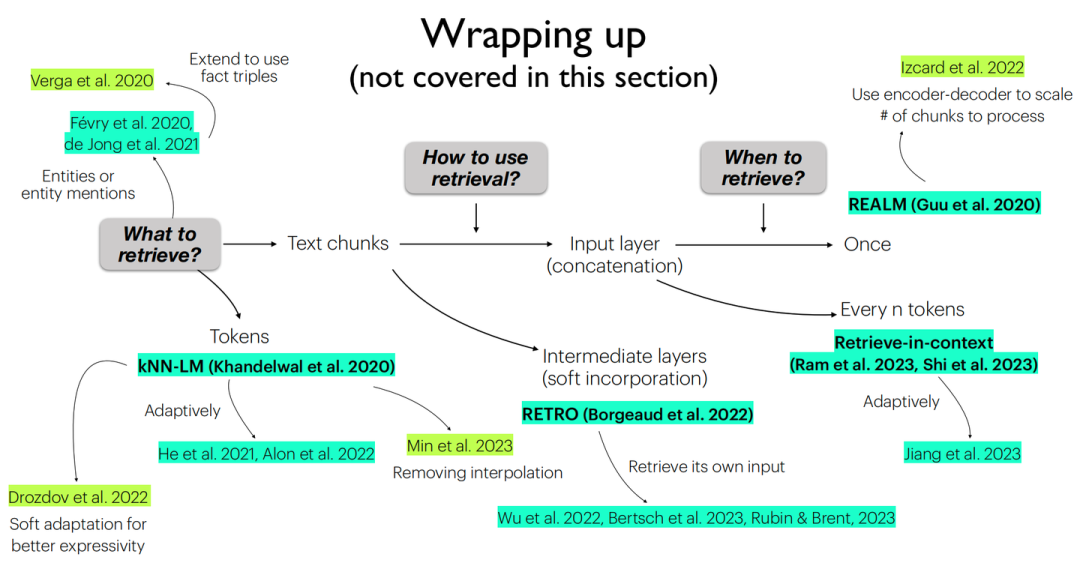
当前各工作所采取的不同架构总结图
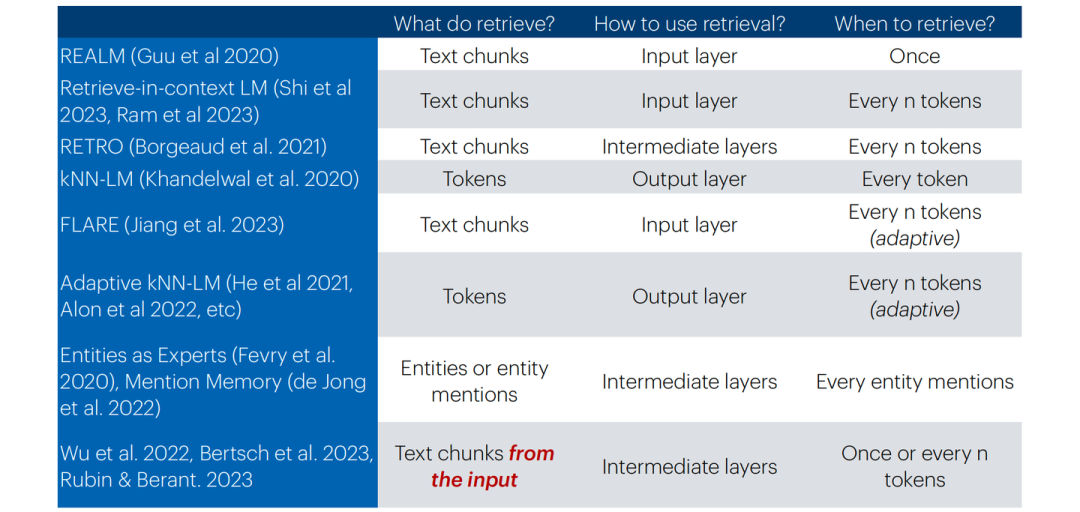
当前各工作所采取的不同架构总结表
上表中最后一行也提及了一类不同的检索增强的语言模型,相比于其他种类,此类并不从外部的知识库中进行信息的检索,而是从自身生成的历史信息中进行“自检索”,其目标是为了处理超长文本或实现自身的长期记忆,这样的架构设计也是为了实现这样的下游任务而设计的。
4 训练:(To train and how to train) or not to train
检索增强的语言模型的训练同样是最关键的一点,简单地同时去训练语言模型以及更新索引显然无论在空间上还是在时间上都是复杂度极高的。现有工作中对于检索增强的语言模型被证实的比较work的训练方式可划分为以下四类:
Independent training:语言模型与检索器均是独立训练的。
Sequential training:独立训练单个组件后将其固定,另一个组件根据此组件任务目标进行训练。
Joint training w/ asynchronous index update:允许索引是“过时”的,即每隔T步才重新更新检索索引。
Joint training w/ in-batch approximation:使用“批内索引”,而不是完整知识库中的全部索引。
以上提及的四类训练方式各有优缺点:
Independent training:可以使用现成的模型(大型索引和强大的LM)而无需额外的训练,每个部分都可以独立改进;但语言模型没有被训练如何利用检索,且检索模型没有针对语言模型的任务/域进行优化。
Independent training
Sequential training:可以使用现成的单个组件(大型索引或强大的LM),并且可以训练语言模型以更加有效地利用检索结果,或者可以训练检索器以更好地提供帮助语言模型的检索结果;然而有一个组件仍然是固定没有经过训练的。

Sequential training
Joint training w/ asynchronous index update:此方法存在索引更新频率的选取难题,频率过高会导致开销昂贵,频率过低会导致索引“过时”而影响性能。
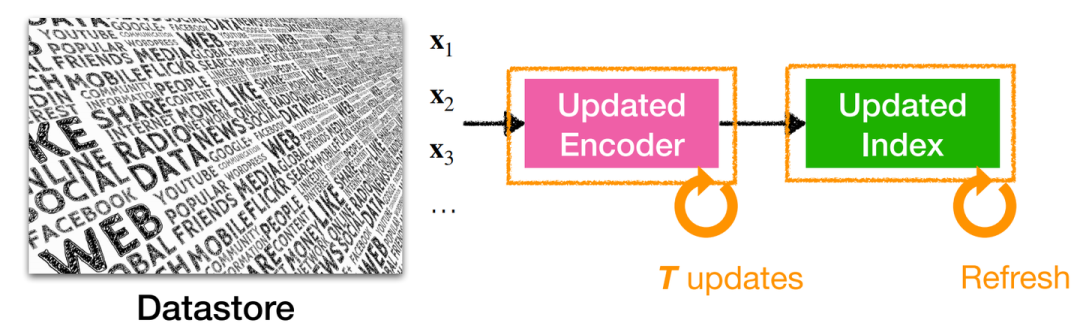
Joint training w/ asynchronous index update
Joint training w/ in-batch approximation:因在整个知识库中实现重新索引会产生巨量的计算开销,此方法只在批内进行重新索引的更新计算,以更小的计算开销去近似整体重新索引的效果。
!Joint training w/ in-batch approximation
对于Joint training,其均能够获取更加良好的性能,但训练更为复杂(异步更新、计算开销、数据批处理等),并且训练-测试的差异仍然存在。
整体看来,上述的四类训练方式除了与模型的设计架构直接相关,还主要为训练开销与模型性能之间的trade-off,后续研究工作的开展也同样应该是围绕这种思路构建的,以寻求最佳的开销-性能平衡点。以上所提到的四类训练方式的全部相关信息可以被总结为下表:

训练方式优/劣势总结表
5 应用:What & How & When
首先,我们需要明确的是:What are the tasks?我们可以从下图中得到一个全面的了解:
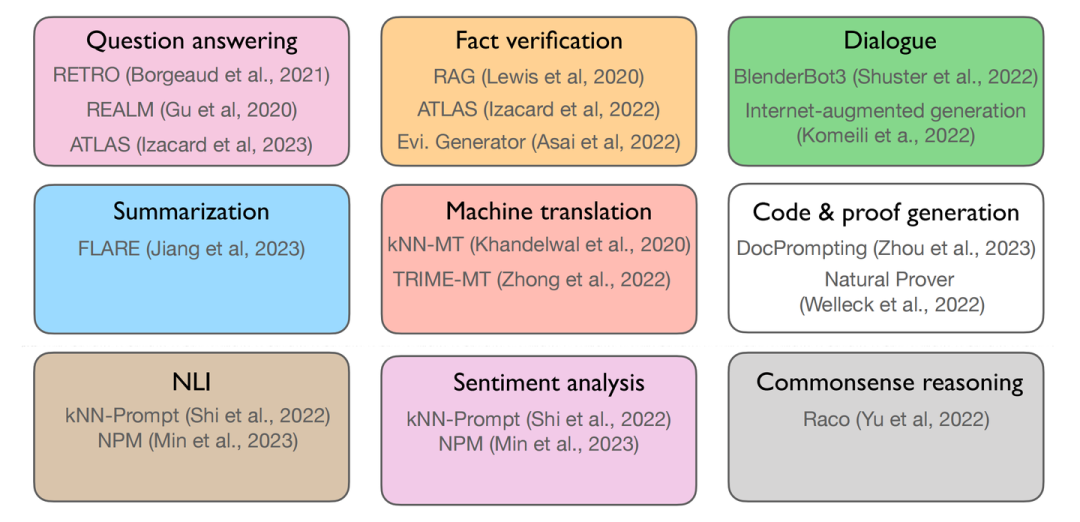
检索增强的语言模型可应用的各类下游任务
其中第一行的三个任务所代表的是知识密集型任务(knowledge-intensive),第二行所表示的是More generations类型的任务,最下面一行所表示的是More classifications型任务。
同时我们还需要回答下列问题:
How can we adapt a retrieval-based LM for a task?
When should we use a retrieval-based LM?
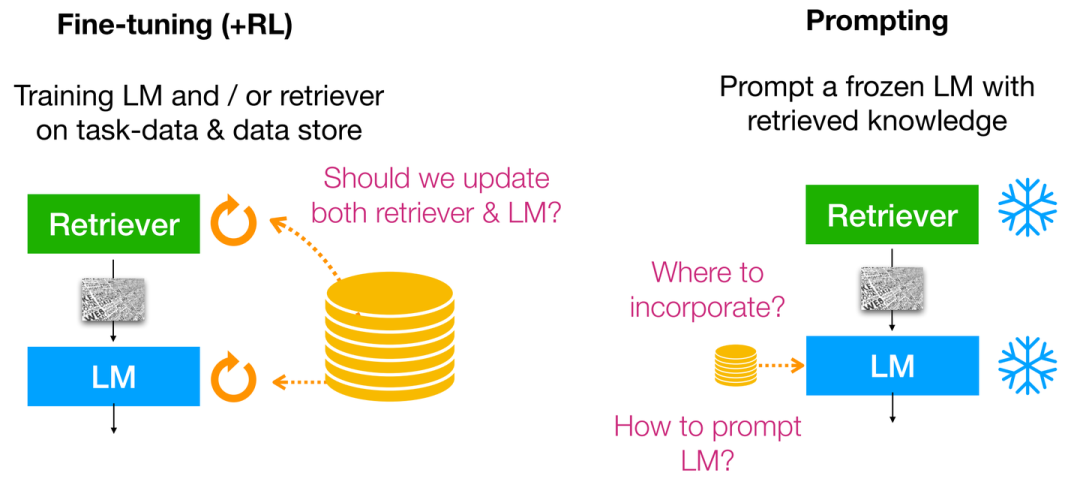
针对How,目前主要的求解范式可以被分为:Fine-tuning,Reinforcement learning,Prompting;并且这三者可同时出现并利用,具体形式如下所示:
How can we adapt a retrieval-based LM for a task?
虽然Fine-tuning与Reinforcement learning(RLHF)的结合使得语言模型能够更好地与人类偏好对齐,但需要额外的训练以及收集额外的偏好/对齐数据。但如果我们不能为下游任务训练语言模型时(e.g. 缺乏计算资源/专有未开源的语言模型等),此时我们便应该诉诸于Prompting,此时便无法从语言模型的中间层进行改进,而只能去操作语言模型的输入/输出层(输入合并检索上下文/输出token概率插值聚合)。
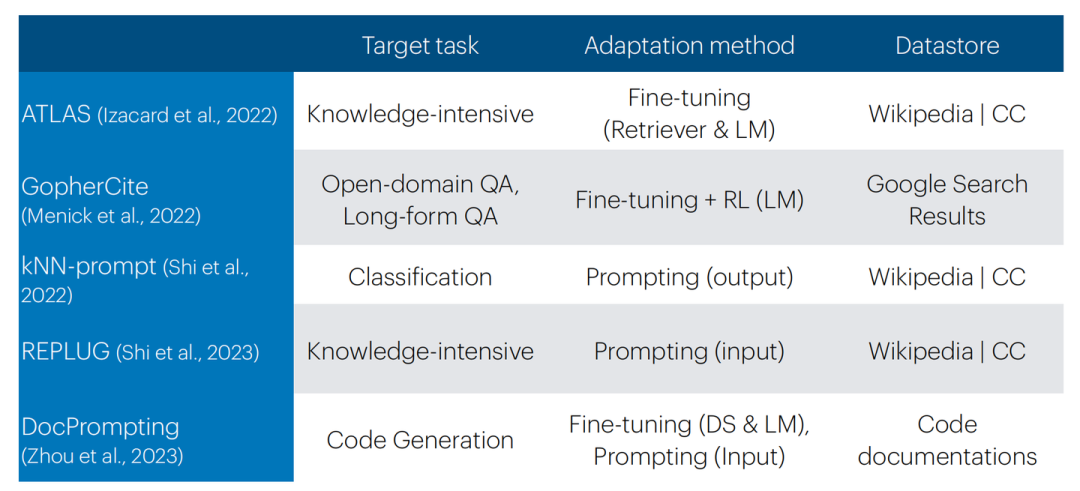
各类模型What & How & When分类总结
总结而言,Retrieval-based prompting实现起来非常简单,无需训练;但结果/性能上有更高的方差。Fine-tuning(+RL)需要额外训练但结果/性能上方差较小,且需要收集更多的额外数据。并且需要注意的是,在下游任务上训练检索器会很有帮助。
并且我们需要明确知识库的类型,这可以是多样化的,大致可分为:Wikipedia,训练数据,代码文档。但在OOD检索上仍然具有挑战。
而针对When,我们可以通过下图进行总结:
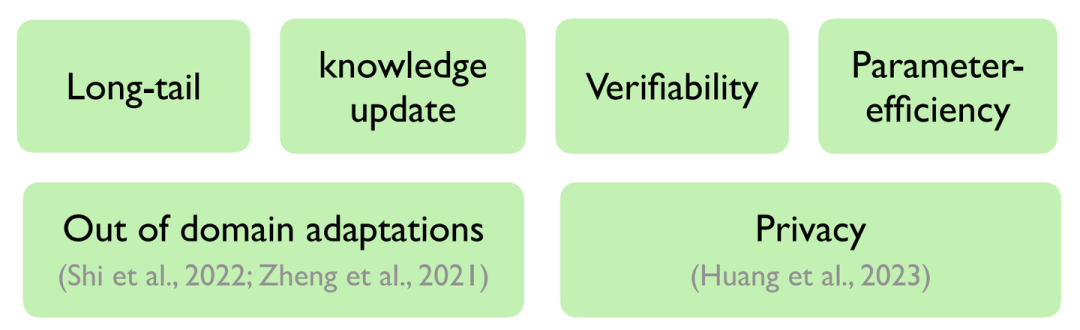
When should we use a retrieval-based LM?
其中上述六方面概念我们在前文中也有所总结,故在此不过多赘述。
在此需要注意的是,多数工作证实检索增强的语言模型在MMLU数据集(Multiple-choice NLU任务)上表现不佳,联想到先前也有工作表示通过向量相似度计算的方式无法很好地完成多词条召回(Multi-tag recall)任务,故笔者猜测可能多选任务上性能不佳的原因也与此有关联,此部分仍有很大的提升空间。
6 扩展:Multilingual & Multimodal
此类扩展均是面向了更加多样化的知识库形式,从而能够使语言模型从更多种类的存储形式中获取知识。
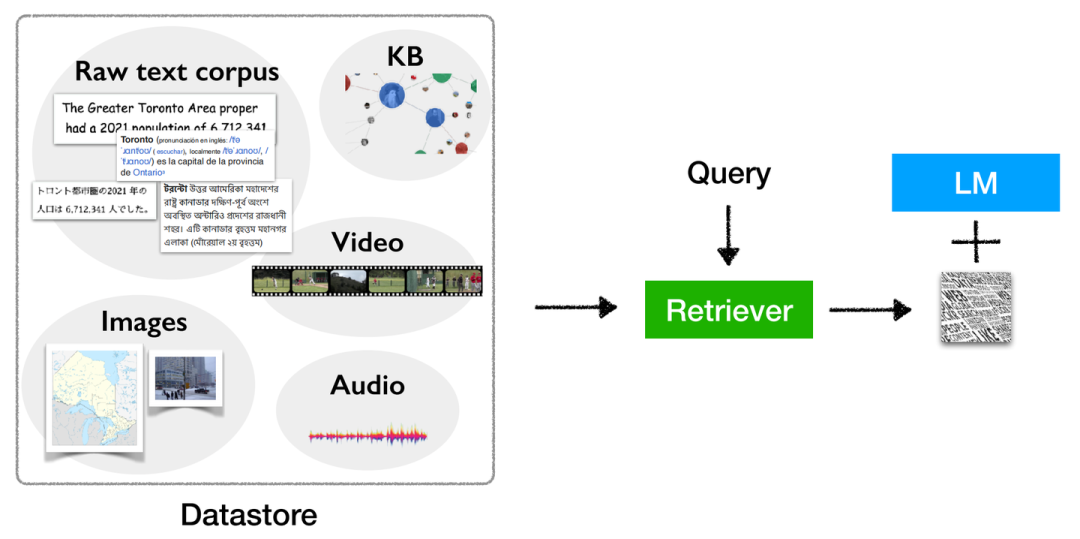
不限形式的检索增强的语言模型
除了报告中介绍的具备代表性的多语言检索增强的语言模型[3]外,更多此类工作总结如下:

多语言检索增强的语言模型——现有工作
除了报告中所介绍的Meta最新多模态检索增强的语言模型工作[4]外,更多此类工作总结如下:

多模态检索增强的语言模型——现有工作
总结而言,扩展到多语言检索:可以实现通过跨语言检索和生成来克服许多世界语言中数据存储的稀缺性(e.g. 中文互联网数据中缺少的知识可以从英文互联网数据中寻求补充);而扩展到多模态检索:为了使输入(输出)适配更多的模态,从而可以将模型更加灵活通用地部署在各类下游任务上。
审核编辑:彭菁
-
解码器
+关注
关注
9文章
1226浏览量
43898 -
存储
+关注
关注
13文章
4964浏览量
90496 -
参数
+关注
关注
11文章
1871浏览量
34120 -
数据收集
+关注
关注
0文章
73浏览量
11786 -
语言模型
+关注
关注
0文章
576浏览量
11401
原文标题:陈丹琦 ACL'23 Tutorial - 基于检索的大语言模型 学习笔记
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
一文详解知识增强的语言预训练模型
【大语言模型:原理与工程实践】大语言模型的应用
RAG(检索增强生成)原理与实践
详解剖析Go语言调度模型的设计
介绍几篇EMNLP'22的语言模型训练方法优化工作
检索增强LLM的方案全面的介绍
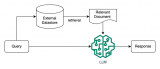
虹科分享 | 谷歌Vertex AI平台使用Redis搭建大语言模型
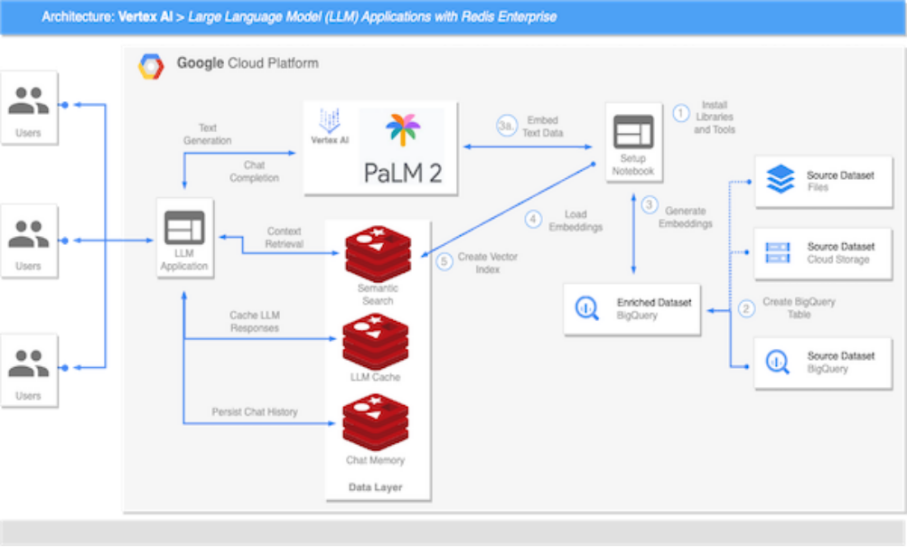

什么是检索增强生成?




评论