 如何创建张量并实现张量类型转化
如何创建张量并实现张量类型转化

我们在 深度学习框架(3)-TensorFlow中张量创建和转化,妙用“稀疏性”提升效率 中讨论了如何创建张量并实现张量类型转化。今天我们一起在TensorFlow中执行张量的计算,并重点讨论一下不同的激活函数。
1、了解不同的激活函数,根据应用选择不同的激活函数
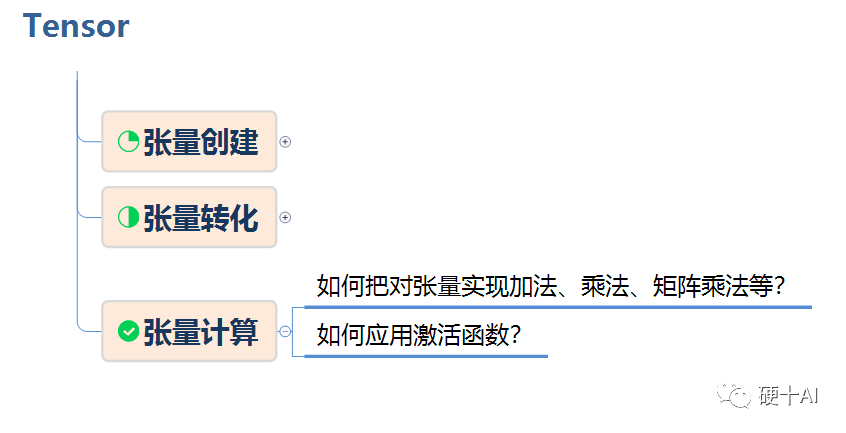
我们在 机器学习中的函数(1)-激活函数和感知机中讨论过 激活函数是在神经网络层间输入与输出之间的一种函数变换,目的是为了加入非线性因素,增强模型的表达能力。激活函数的作用类似于人类大脑中基于神经元的模型(参考下图),激活函数最终决定了要发射给下一个神经元的内容。
(1)激活函数有什么价值?
激活函数对于人工神经网络模型去学习、理解非常复杂和非线性的函数来说具有十分重要的作用。首先对于y=ax+b这样的函数,当x的输入很大时,y的输出也是无限大/小的,经过多层网络叠加后,值更加膨胀了,这显然不符合我们的预期,很多情况下我们希望的输出是一个概率,需要激活函数能帮助网络进行收敛。其次,线性变换模式相对简单(只是加权偏移),限制了对复杂任务的处理能力,没有激活函数的神经网络就是一个线性回归模型;激活函数做的非线性变换可以使得神经网络处理非常复杂的任务,如我们希望我们的神经网络可以对语言翻译和图像分类做操作,这就需要非线性转换。最后,激活函数也使得反向传播算法变得可能,因为这时候梯度和误差会被同时用来更新权重和偏移,没有可微分的线性函数,就不可能实现。
(2)有哪些常用的激活函数?
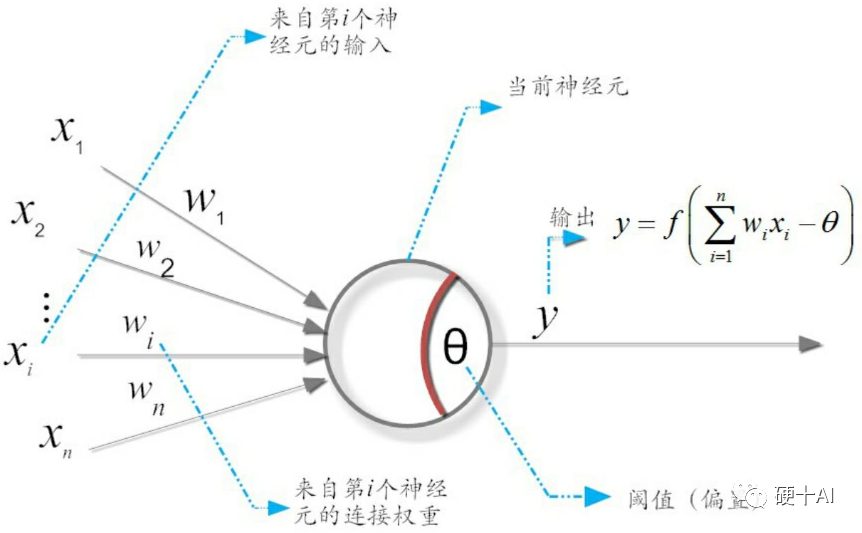
常用的激活函数有,Sigmoid激活函数,Tan/ 双曲正切激活函数,ReLU激活函数(还有改进后的LeakyReLU和PReLU),Softmax激活函数等。
(3)激活函数使用时有哪些问题?如何改进激活函数?
Sigmoid梯度消失问题可以通过Relu解决
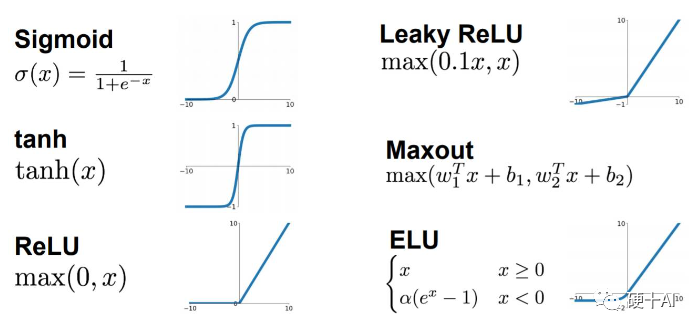
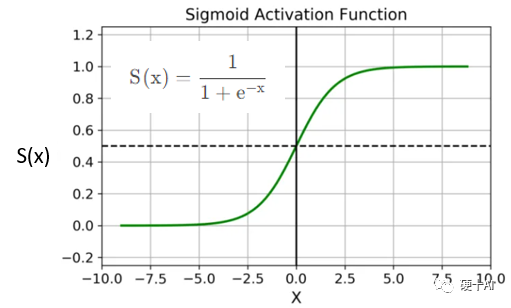
梯度、梯度下降、链式法则等概念可参考机器学习中的函数(3)-“梯度下降”走捷径,“BP算法”提效率 中的描述。我们以Sigmoid为例,看一下“梯度消失”是如何发生的?Sigmoid的函数公式和图像如下图,从图中可见函数两个边缘的梯度约为0,Sigmoid导数取值取值范围为(0,0.25)。
当我们求激活函数输出相对于权重参数W的偏导时,Sigmoid函数的梯度是表达式中的一个乘法因子。实际的神经网络层数少则数十多则数百层,由于神经网络反向传播时的“链式反应”,这么多范围在(0,0.25)的数相乘,将会是一个非常小的数字。而梯度下降算法更新参数W完全依赖于梯度值(如BP算法),极小的梯度值失去了区分度,无法让参数有效更新,该现象即为“梯度消失”(VanishingGradients)。
ReLU激活函数(Rectified Linear Unit,修正线性单元)的出现解决了梯度消失问题。如下图所示,ReLU的公式是R(z)=max(0,z)。假设这个神经元负责检测一个具体的特征,例如曲线或者边缘。若此神经元在输入范围内检测到了对应的特征,开关开启,且正值越大代表特征越明显;但此神经元检测到特征缺失,开关关闭,则不管负值的大小,如-6对比-2都没有区分的意义。
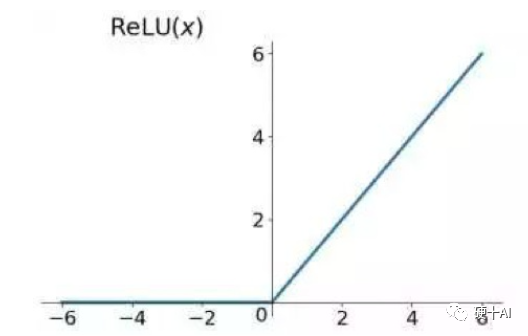
Relu的优势是求导后,梯度只可以取0或1,输入小于0时,梯度为0;输入大于0时,梯度为1。在多层神经网络中Relu梯度的连续乘法不会收敛到0,结果也只可以取0或1;若值为1则梯度保持值不变进行前向传播,若值为0则梯度从该位置停止前向传播。
Relu神经元死亡问题可以通过“小于0”部分优
ReLU也有缺点,它提升了计算效率,但同样可能阻碍训练过程。通常,激活函数的输入值有一项偏置项(bias),若bias太小,输入激活函数的值总是负的,那么反向传播过程经过该处的梯度总为0,对应的权重和偏置参数无法得到更新。如果对于所有的样本输入,该激活函数的输入都是负的,那么该神经元再也无法学习,称为神经元“死亡”问题(Dying ReLU Problem)。
Relu升级到LeakyReLU就是为了解决神经元“死亡”问题。LeakyReLU与ReLU很相似,仅在输入小于0的部分有差别,ReLU输入小于0的部分值都为0,而LeakyReLU输入小于0的部分,值为负,且有微小的梯度。使用LeakyReLU的好处就是:在反向传播过程中,对于LeakyReLU激活函数输入小于零的部分,也可以计算得到梯度,而不是像ReLU一样值为0,这样就避免了上述梯度方向锯齿问题。超参数α的取值也被研究过,有论文将α作为了需要学习的参数,该激活函数为PReLU(Parametrized ReLU)。
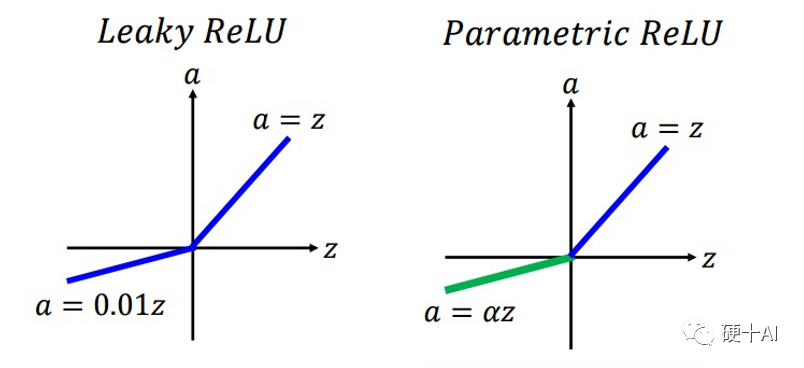
(4)如何选择激活函数?
每个激活函数都有自己的特点,Sigmoid和tanh的将输出限制在(0,1)和(-1,1)之间,适合做概率值的处理,例如LSTM中的各种门;而ReLU无最大值限制,则不适合做这个应用,但是Relu适合用于深层网络的训练,而Sigmoid和tanh则不行,因为它们会出现梯度消失。
选择激活函数是有技巧的,如“除非在二分类问题中,否则小心使用Sigmoid函数”;“如果你不知道应该使用哪个激活函数, 那么请优先选择ReLU”。尽管ReLU有一些缺点,但参考“奥卡姆剃刀原理”,如无必要、勿增实体,也就是优先选择最简单的方法,ReLU相较于其他激活函数,有着最低的计算代价和最简单的代码实现。如果使用了ReLU,要注意一下DeadReLU问题。如优化Learningrate,防止太高导致在训练过程中参数更新太大,避免出现大的梯度从而导致过多的神经元“Dead”;或者针对输入为负值时,ReLU的梯度为0造成神经元死亡,更换激活函数,尝试一下leakyReLU等ReLU变体,说不定会有很好效果。
实际应用时还是要看具体场景,甚至结合具体模型。比如LSTM中用到Tanh、Transfromer中用到的ReLU、Bert中用到的GeLU,YoLo中用到的LeakyReLU等。不同的激活函数,根据其特点,应用各不相同。
3、如何让张量执行计算?
(1)导入TensorFlow,并建立矩阵a、矩阵b、矩阵c,参考如下代码
import tensorflow as tf
import numpy as np
a = tf.constant([[1, 2], [3, 4]])
b = tf.constant([[1, 1], [1, 1]])
c = tf.constant([[4.0,5.0], [10.0,1.0]])
(2)执行张量的运算
张量的基本运算包括加法、乘法、获取最大最小值等,常用函数有tf.add()、tf.multiply()、tf.matmul()、tf.reduce_max()等。乘法相关的两个函数,tf.multiply()是两个矩阵中对应元素各自相乘,而tf.matmul()执行的是矩阵乘法,两者有区别。
add
print(tf.add(a, b), “
”)
打印结果 》》》
tf.Tensor(
[[2 3]
[4 5]], shape=(2, 2), dtype=int32)
multiply
print(tf.multiply(a, b), “
”)
打印结果 》》》
tf.Tensor(
[[1 2]
[3 4]], shape=(2, 2), dtype=int32)
matrix multiply
print(tf.matmul(a, b), “
”)
打印结果 》》》
tf.Tensor(
[[3 3]
[7 7]], shape=(2, 2), dtype=int32)
max/min:find the largest/smallest value
print(tf.reduce_max(c))
打印结果 》》》
tf.Tensor(10.0, shape=(), dtype=float32)
(3)应用激活函数
我们以tf.nn.sigmoid()、tf.nn.relu()等常用的激活函数为例,大家可以参考上文分享的公式验计算验证一下,看一下激活效果。
sigmoidprint(tf.nn.sigmoid(c))
打印结果 》》》
tf.Tensor(
[[0.98201376 0.9933072 ]
[0.9999546 0.7310586 ]], shape=(2, 2), dtype=float32)
reluprint(tf.nn.relu(c))
打印结果 》》》
tf.Tensor(
[[ 4. 5.]
[10. 1.]], shape=(2, 2), dtype=float32)
今天我们一起学习了如何在TensorFlow中执行张量的计算,并重点讨论一下不同的激活函数,下一步我们继续学习如何使用TensorFlow
审核编辑:郭婷
-
神经网络
+关注
关注
42文章
4827浏览量
106797 -
深度学习
+关注
关注
73文章
5590浏览量
123905
原文标题:深度学习框架(4)-TensorFlow中执行计算,不同激活函数各有妙用
文章出处:【微信号:Hardware_10W,微信公众号:硬件十万个为什么】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
如何将训练好的神经网络模型部署到蜂鸟e203开发板上
京东:调用用户画像API实现千人千面推荐,提升转化率

如何移植 RT-Thread Nano 并创建 2 个线程?
SQL 通用数据类型
奇异摩尔亮相2025中国AI算力大会
光刻图形转化软件免费试用
TPU处理器的特性和工作原理
使用Python API在OpenVINO™中创建了用于异步推理的自定义代码,输出张量的打印结果会重复,为什么?
获取具有三个输出的自定义模型的输出张量,运行时错误是怎么回事?
解析DeepSeek MoE并行计算优化策略






 工商网监
工商网监
评论