 能否在边缘进行训练(on-device training),使设备不断的自我学习?
能否在边缘进行训练(on-device training),使设备不断的自我学习?

该研究提出了第一个在单片机上实现训练的解决方案,并且系统协同设计(System-Algorithm Co-design)大大减少了训练所需内存。
说到神经网络训练,大家的第一印象都是 GPU + 服务器 + 云平台。传统的训练由于其巨大的内存开销,往往是云端进行训练而边缘平台仅负责推理。然而,这样的设计使得 AI 模型很难适应新的数据:毕竟现实世界是一个动态的,变化的,发展的场景,一次训练怎么能覆盖所有场景呢?
为了使得模型能够不断的适应新数据,我们能否在边缘进行训练(on-device training),使设备不断的自我学习?在这项工作中,我们仅用了不到 256KB 内存就实现了设备上的训练,开销不到 PyTorch 的 1/1000,同时在视觉唤醒词任务上 (VWW) 达到了云端训练的准确率。该项技术使得模型能够适应新传感器数据。用户在享受定制的服务的同时而无需将数据上传到云端,从而保护隐私。

网站:https://tinytraining.mit.edu/
论文:https://arxiv.org/abs/2206.15472
Demo: https://www.bilibili.com/video/BV1qv4y1d7MV
代码: https://github.com/mit-han-lab/tiny-training
背景
设备上的训练(On-device Training)允许预训练的模型在部署后适应新环境。通过在移动端进行本地训练和适应,模型可以不断改进其结果并为用户定制模型。例如,微调语言模型让其能从输入历史中学习;调整视觉模型使得智能相机能够不断识别新的物体。通过让训练更接近终端而不是云端,我们能有效在提升模型质量的同时保护用户隐私,尤其是在处理医疗数据、输入历史记录这类隐私信息时。
然而,在小型的 IoT 设备进行训练与云训练有着本质的区别,非常具有挑战性,首先, AIoT 设备(MCU)的 SRAM 大小通常有限(256KB)。这种级别的内存做推理都十分勉强,更不用说训练了。再者,现有的低成本高效转移学习算法,例如只训练最后一层分类器 (last FC),只进行学习 bias 项,往往准确率都不尽如人意,无法用于实践,更不用说现有的深度学习框架无法将这些算法的理论数字转化为实测的节省。最后,现代深度训练框架(PyTorch,TensorFlow)通常是为云服务器设计的,即便把 batch-size 设置为 1,训练小模型 (MobileNetV2-w0.35) 也需要大量的内存占用。因此,我们需要协同设计算法和系统,以实现智能终端设备上的训练。

方法与结果
我们发现设备上训练有两个独特的挑战:(1)模型在边缘设备上是量化的。一个真正的量化图(如下图所示)由于低精度的张量和缺乏批量归一化层而难以优化;(2)小型硬件的有限硬件资源(内存和计算)不允许完全反向传播,其内存用量很容易超过微控制器的 SRAM 的限制(一个数量级以上),但如果只更新最后一层,最后的精度又难免差强人意。
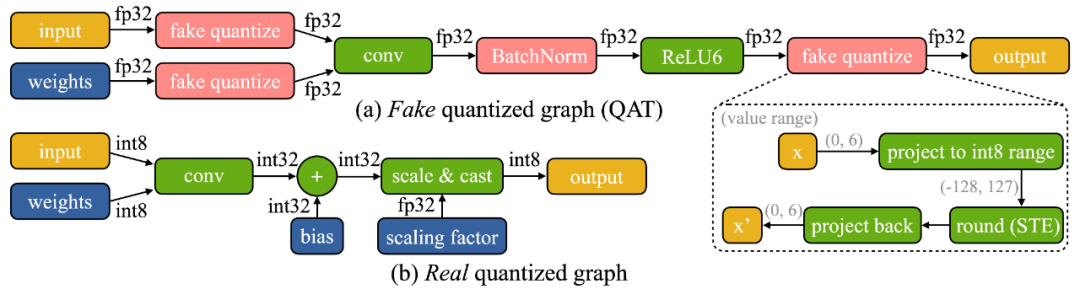
为了应对优化的困难,我们提出了 Quantization-Aware Scaling (QAS) 来自动缩放不同位精度的张量的梯度(如下左图所示)。QAS 在不需要额外超参数的同时,可以自动匹配梯度和参数 scale 并稳定训练。在 8 个数据集上,QAS 均可以达到与浮点训练一致的性能(如下右图)。

为了减少反向传播所需要的内存占用,我们提出了 Sparse Update,以跳过不太重要的层和子张的梯度计算。我们开发了一种基于贡献分析的自动方法来寻找最佳更新方案。对比以往的 bias-only, last-k layers update, 我们搜索到的 sparse update 方案拥有 4.5 倍到 7.5 倍的内存节省,在 8 个下游数据集上的平均精度甚至更高。
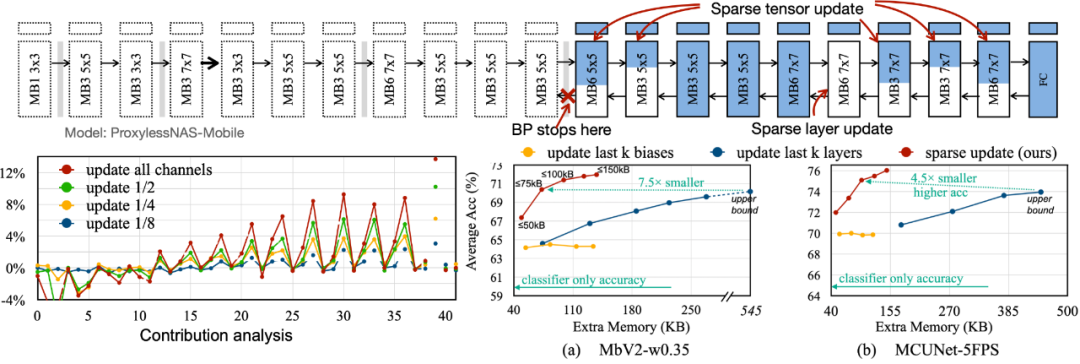
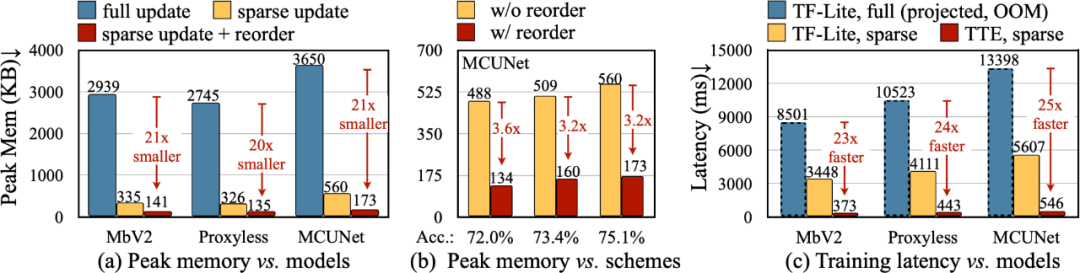
为了将算法中的理论减少转换为实际数值,我们设计了 Tiny Training Engine(TTE):它将自动微分的工作转到编译时,并使用 codegen 来减少运行时开销。它还支持 graph pruning 和 reordering,以实现真正的节省与加速。与 Full Update 相比,Sparse Update 有效地减少了 7-9 倍的峰值内存,并且可以通过 reorder 进一步提升至 20-21 倍的总内存节省。相比于 TF-Lite,TTE 里经过优化的内核和 sparse update 使整体训练速度提高了 23-25 倍。

结论
本文中,我们提出了第一个在单片机上实现训练的解决方案(仅用 256KB 内存和 1MB 闪存)。我们的算法系统协同设计(System-Algorithm Co-design)大大减少了训练所需内存(1000 倍 vs PyTorch)和训练耗时(20 倍 vs TF-Lite),并在下游任务上达到较高的准确率。Tiny Training 可以赋能许多有趣的应用,例如手机可以根据用户的邮件 / 输入历史来定制语言模型,智能相机可以不断地识别新的面孔 / 物体,一些无法联网的 AI 场景也能持续学习(例如农业,海洋,工业流水线)。通过我们的工作,小型终端设备不仅可以进行推理,还可以进行训练。在这过程中个人数据永远不会上传到云端,从而没有隐私风险,同时 AI 模型也可以不断自我学习,以适应一个动态变化的世界
审核编辑 :李倩
-
内存
+关注
关注
9文章
3173浏览量
76114 -
IOT
+关注
关注
189文章
4369浏览量
206574
原文标题:用少于256KB内存实现边缘训练,开销不到PyTorch千分之一
文章出处:【微信号:CVSCHOOL,微信公众号:OpenCV学堂】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
DDR training的产生原因

一文看懂AI训练、推理与训推一体的底层关系

超小型Neuton机器学习模型, 在任何系统级芯片(SoC)上解锁边缘人工智能应用.
打通边缘智能之路:面向嵌入式设备的开源AutoML正式发布----加速边缘AI创新
边缘计算中的机器学习:基于 Linux 系统的实时推理模型部署与工业集成!

什么是边缘盒子?一文讲透边缘计算设备在不同行业的真实应用






 工商网监
工商网监
评论