 预先训练的语言模型能像人类一样聪明地解释明喻吗?
预先训练的语言模型能像人类一样聪明地解释明喻吗?
前言
明喻是人们日常生活中一类常见的表述形式,解释明喻可以帮助机器更好地理解自然语言。因此,明喻解释(SimileInterpretation)是自然语言处理领域中一个重要的研究问题。如今,大规模预训练语言模型(Pre-trainedLanguage Models , PLMs)在各类自然语言处理任务上得到突出的表现效果。那预训练语言模型是否能像人一样解释明喻呢?
本文介绍了复旦大学知识工场实验室的最新工作《Can Pre-trained Language Models Interpret Similes as Smart as Human?》,该工作已经被ACL 2022录用。此工作创新性地提出了明喻属性探测任务(Simile Property Probing),也即让预训练语言模型推断明喻中的共同属性。此工作从通用语料文本、人工构造题目两个数据源构建明喻属性探测数据集,规模为1,633个题目,涵盖七个主要类别。基于构建的数据集,实验证明预训练语言模型具有一定推断明喻属性的能力,但是仍然不及人类的表现。为了进一步增强预训练语言模型的明喻解释能力,此工作借鉴知识表示方法设计优化目标,将明喻知识注入模型。实验证明,该优化目标在探测任务带来8.58%的提升、在情感分析下游任务上带来1.37%的提升。

paper: https://arxiv.org/abs/2203.08452
Datasets and Code:https://github.com/Abbey4799/PLMs-Interpret-Simile
研究背景
通过捕捉概念之间的共同属性,明喻将看似无关的两个概念联系起来,形成一段生动的表述。例如图1中虽然“老妇人”与“蜗牛”看似毫无关系,前者是人类,后者是动物。但是,由于二者的共同属性——“行走速度较慢”,明喻便在二者之间建立了联系,拓展了语言的表达能力,丰富了读者的想象力。
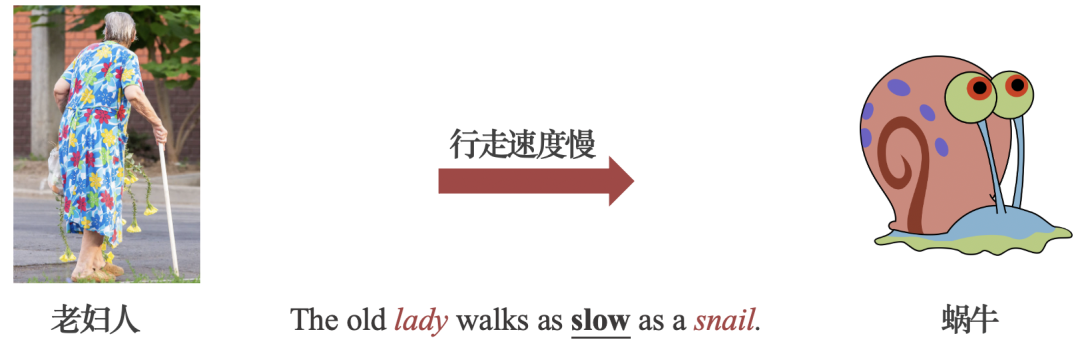
图1:明喻通过共同属性将两个概念联系起来的示例。
明喻主要分为两类:封闭式明喻(ClosedSimile),以及开放式明喻(OpenSimile)。如图2所示,二者区别在于是否显式地指明本体、喻体的共同属性,例如上例中的“速度慢”。
若属性显式出现(例如,The old lady walks as slow as a snail.),则是封闭式明喻;
若没有显式指出属性(例如,The old lady walks like a snail.),则是开放式明喻。
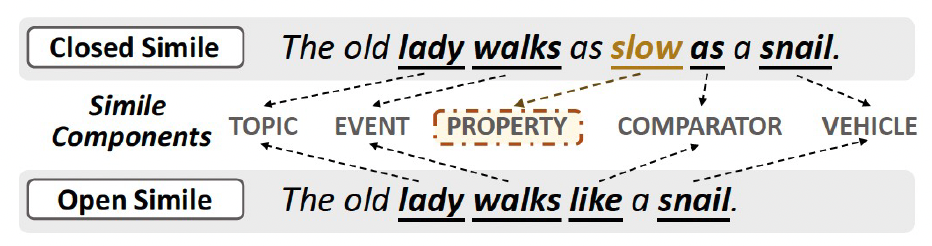
图2:两类明喻的示例。二者区别在于是否显式地指明共同属性。
明喻解释是自然语言处理领域中的一个重要研究问题,可以帮助许多下游任务,例如:理解更复杂的修辞手法、情感分析任务等。以明喻“这个律师像一条鲨鱼”为例,此句虽然用词中性,但当机器推断出“律师”和“鲨鱼”共同具有的“气势汹汹”这一属性后,便可判断这一句所表达的是消极情绪。
近年来,大规模预训练语言模型,例如BERT、RoBERTa,成为解决自然语言处理任务的新趋势。许多研究证明,大规模预训练语言模型在预训练过程中存储了一定知识在模型丰富的参数、精巧的结构中。然而,预训练语言模型解释明喻的能力却并未被关注。
因此,我们创新性地提出了明喻属性探测任务(SimileProperty Probing)。通过让预训练语言模型推断明喻中的共同属性,从而研究了预训练语言模型解释明喻的能力。
明喻属性探测任务
01
问题建模
为了研究预训练语言模型解释明喻的能力,我们遮盖(Mask)了封闭式明喻(ClosedSimile)中的属性,让语言模型根据上下文信息推断属性。由于本体和喻体可能同时拥有多个属性,因此,我们将任务设计为选择题(只有一个正确答案)而非填空题。
给定一个单词序列S={w1w2,,...,wi-1,[MASK],wi+1,...,wn},将本体和喻体共有属性wi遮盖为[MASK]符号。PLMs需要从四个选项中选择正确属性,剩余三个选项为错误干扰选项。
02
数据集构建
针对明喻属性探测任务,我们构建了评估数据集。我们首先从两个数据来源搜集封闭式明喻,并基于明喻组件设计干扰选项候选集合,接着我们利用余弦相似度筛选最具有挑战性的干扰选项得到最终选项,最后我们通过人工标注确保数据集的质量。整体数据集构建流程展示如图3。
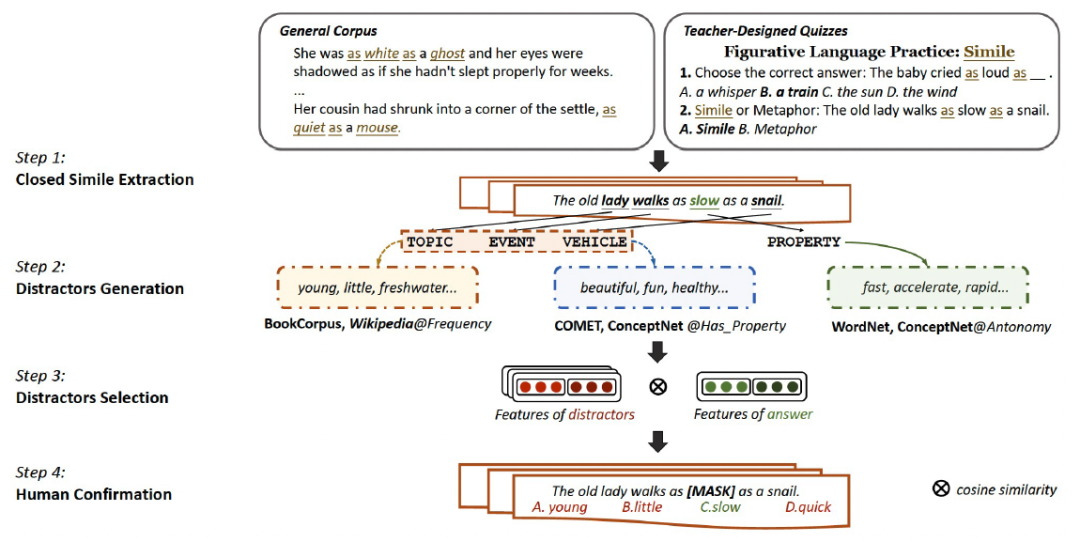
图3:构建明喻属性探测数据集流程图。
数据来源
我们选择两个数据来源以构建数据集:通用语料文本、人工构造题目。由于开放式明喻的属性没有被显式指出,若要用以构建明喻属性探测数据集,需要人工根据上下文标注正确属性。为了减少标注的成本,在构建数据集的过程中,我们选择显式指出属性的封闭式明喻作为数据来源。
通用语料文本。首先选取两个通用语料库:BNC以及iWeb,随后利用模版as ADJ as (a, an, the) NOUN匹配句子。
人工构造题目。老师为检验学生是否掌握明喻知识所制定的题目是合适的数据来源。因此,我们将在线测验的趣味学习平台Quizizz作为数据来源。选取一系列标题与明喻相关的测验,并基于测验中的问题和答案解析出封闭式明喻。
为了保证数据集的质量,三个标注者对句子是否为明喻进行判断,并标注每个句子的明喻组件。数据集中所有属性均为单符号的(single-token),原句中的多符号(multi-token)属性均被替换为它们在知识库WordNet和ConceptNet中的单符号同义词。
干扰选项构建
为了保证题目的质量,我们以两个原则设计了剩余的三个干扰选项:错误(true-negative)、具有挑战性(challenging)。也即,高质量的干扰选项应该违背上下文的逻辑(true-negative ),同时与正确答案语义相关(challenging)。
生成干扰选项。为了实现“具有挑战性(challenging)”的要求,我们基于明喻中四个语义相关的组件(本体topic、喻体vehicle、谓词event、属性property)设计干扰选项候选集合。
给定原有属性,我们首先从知识库WordNet和ConceptNet中获取反义词;
对于剩下的三个组件,我们首先利用ConceptNet的HasProperty和COMET分别获得每个组件相关属性。接着,通过统计频次,获得每个组件在Wikipedia和BookCorpus中共现次数最多的副词/形容词,选取共现频次排名前十的修饰词(并且频次大于1)作为候选选项。
通过以上策略,得到干扰选项候选集。
筛选干扰选项。我们利用句子的相似度,进一步从干扰选项候选集中获得最具有挑战性的干扰选项。整体流程如图4。给定原句以及将正确属性替换为的干扰选项的新句子,我们利用RoBERTaLARGE提取两类特征,从而衡量二者的相似度。
一个是上下文特征(Context Embedding),由[CLS]的嵌入向量表示;
一个是单词特征(Word Embedding),由正确选项或干扰选项的嵌入向量表示。
最后,拼接两个特征,利用余弦相似度(consinesimilarity)衡量正确答案和干扰选项之间在给定上下文中的关联性。最终,选取关联性最高的三个干扰选项与正确答案组成最终选项。
人工确认选项。为了确保干扰选项为“错误(true-negative)”的,由三个标注者对干扰选项进行清洗。
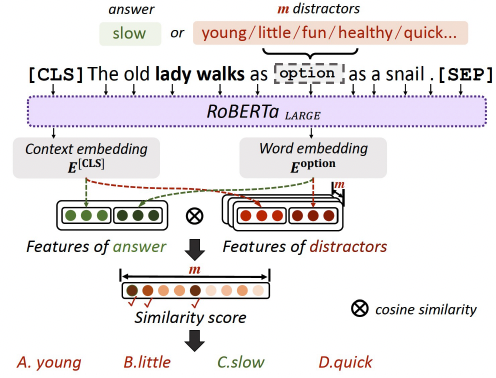
图4:筛选最具有挑战性的干扰选项的示意图。
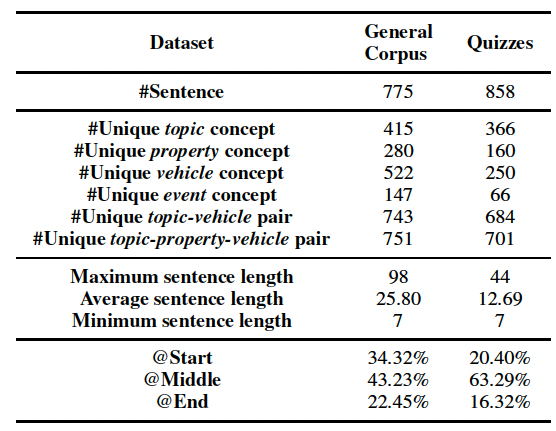
数据集统计指标
最终,我们从通用语料文本、人工构造题目两个数据源构建明喻属性探测数据集,规模为1,633个题目,涵盖七个类别。题目示例如表1。
表1:明喻属性探测数据集中各类题目的示例和占比。其中,“__”标示的选项是正确答案。每句中的斜体词分别代表本体、遮盖后的属性和喻体。

数据集统计指标如表2。整体而言,Quizzes数据集中的明喻更常见,GeneralCorpus数据集中的明喻上下文更丰富。
表2:明喻属性探测数据集统计指标。
03
有监督微调
除了评估预训练语言模型在零样本场景下直接表现的预测明喻属性能力,我们利用遮盖属性后的Masked Language Modeling (MLM)训练目标微调模型,探索微调是否能提升模型理解明喻的能力。我们利用来自StandardizedProject Gutenberg Corpus(SPGC)语料库4510条(Noun... as ADJ as ... NOUN)的句子作为微调数据。
主要实验结果
我们对比了模型在零样本、微调后的结果,并与前人工作、人类表现进行对比。实验结果如表3。
表3:各模型在明喻属性探测任务中的准确率。
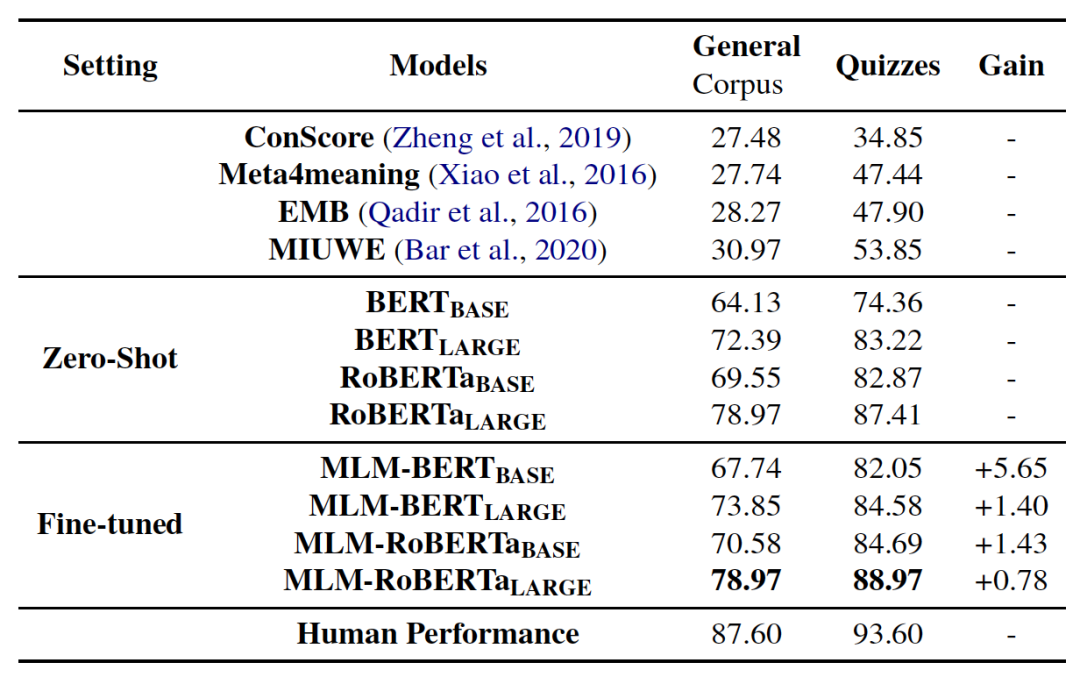
我们观察到:
模型在预训练阶段存储的知识可以帮助推断明喻属性;
利用MLM目标微调可以进一步提升模型预测明喻属性的能力;
微调后的模型仍然不及人类的表现。
总体而言,模型在Quizzes数据集上的表现好于在GeneralCorpus数据集上的表现效果,更丰富的上下文会增加推断明喻属性的难度。同时,RoBERTa的表现持续好于BERT,证明更大规模的预训练语料可以让模型建模更多的明喻文本。
我们还对明喻各个组件对解释明喻的贡献程度进行探究,从而进一步揭示模型解释明喻的机制。我们分别将明喻组件(本体、喻体、比较词)替换为[UNK]符号,将谓词替换为be动词从而在抹除语义的同时不影响语法。我们同时随机替换任一符号为[UNK]作为对照。实验结果如表4。
表4:未经微调的预训练语言模型在分别遮盖各组件的情况下预测明喻属性的结果。
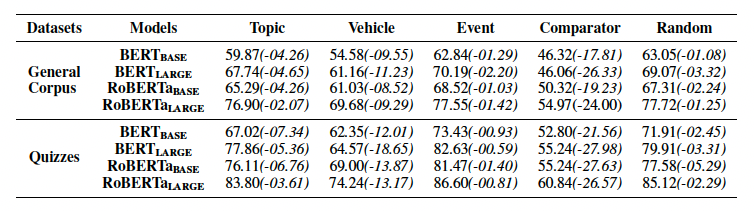
我们观察到:
喻体、本体和比较词较上下文能提供更关键的信息;
喻体能提供最丰富的语义信息,本体次之。
因此,我们认为有效利用喻体和本体的信息可以进一步提高模型的表现效果。
增强PLMs中的明喻知识
01
设计目标函数进行知识增强
根据实验分析,我们已知本体和喻体是推测明喻属性最重要的两个组件。因此,由知识表示相关方法(Knowledge Embedding, KE)启发,我们认为属性(property)可以看作本体(topic)和喻体(vehicle)的关系。受事实三元组的启发,我们将明喻看作三元组(本体topic,属性property,喻体vehicle)。如图5所示,在表示空间中,将属性看作从本体到喻体的平移向量。用知识表示方法的打分函数对属性予以评估和约束。
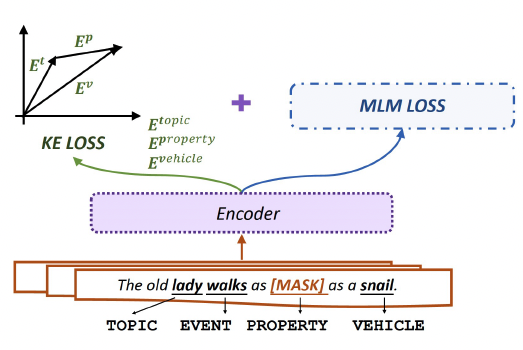
图5:我们设计的目标函数示意图
受经典的知识表示方法TransE启发,我们利用均方误差(MeanSquare Error, MSE)损失函数作为我们的知识表示损失函数(KE Loss)。
LKE= MSE(Et+ Ep, Ev)
其中,Et,Ep, Ev为本体、属性、喻体由语言模型编码的表示向量。我们也尝试了改进后的知识表示方法(例如TransH,TransD),我们将结果展示在附录中。
最终,我们的损失函数由MLMLoss和KE Loss共同组成:
LOurs =αLKE + LMLM
其中,α是平衡两个目标函数的超参数。
02
实验结果
我们分别基于MLM目标函数以及我们设计的目标函数进行微调,对比模型在明喻属性探测任务上的表现效果。实验结果如表5。
表5:利用MLM以及我们设计的目标函数在明喻属性探测任务上的准确率。
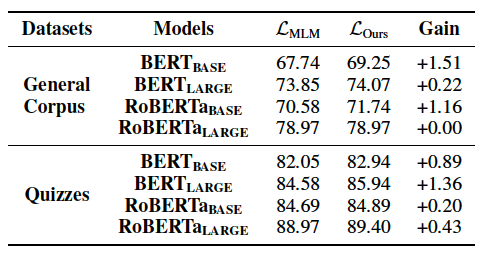
我们观察到我们设计的目标函数可以提高模型推测共同属性的能力,在明喻属性探测任务上验证了我们设计的目标函数的有效性。
研究表明,明喻往往带有情感极性。为了进一步揭示改进后目标函数的应用潜力,我们在情感分析下游任务上进行实验。我们选取Amazon评论情感分析数据集进行二分类任务,训练过程中仅更新MLP层的参数,预训练语言模型的参数保持不变。预训练语言模型的参数来自于明喻属性探测任务中的三个场景:零样本(Original)、基于MLM目标函数微调后(LMLM)、基于知识增强后的模板函数微调后(LOurs)。实验结果如表6。
表6:三个场景下的预训练语言模型在情感分析下游任务上的准确率。
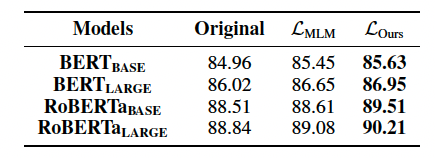
我们观察到,增强预训练语言模型推断明喻属性的能力可以提升模型分析文本情感极性的能力。同时在下游任务上也验证了我们设计的目标函数的有效性。并且,我们在论文中也通过实验分析了目标函数带来表现提升的原因。
总结
我们是第一篇通过设计明喻属性探测任务研究预训练语言模型解释明喻能力的文章。基于两个数据来源构建了两个明喻属性探测数据集,并进行了一系列实验。我们证明了预训练语言模型在预训练阶段已经掌握一定推断明喻属性的能力,同时该能力可以进一步在精调阶段提升,但是仍然与人的表现有所差距。特别地,我们提出的目标函数将明喻知识注入模型,进一步缩短了这一差距。我们的目标函数在明喻属性探测任务以及情感分析下游任务上都表现出有效性。在未来,我们将考虑探索如何让机器解释更复杂的修辞手法,例如隐喻和类比。
审核编辑 :李倩
-
模型
+关注
关注
1文章
2701浏览量
47658 -
语言模型
+关注
关注
0文章
426浏览量
10042 -
数据集
+关注
关注
4文章
1176浏览量
24340
原文标题:ACL'22丨预训练语言模型能否像人一样解释明喻
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何把外部SRAM像内部RAM一样分配变量?
盘点一下史上最全大语言模型训练中的网络技术
【书籍评测活动NO.31】大语言模型:原理与工程实践
【书籍评测活动NO.30】大规模语言模型:从理论到实践
二维图片框 在 鼠标处 滚轮 缩放 图片,像 CAD 一样,,
模型与人类的注意力视角下参数规模扩大与指令微调对模型语言理解的作用

2023年大语言模型(LLM)全面调研:原理、进展、领跑者、挑战、趋势
一种基于表征工程的生成式语言大模型人类偏好对齐策略
大语言模型简介:基于大语言模型模型全家桶Amazon Bedrock
大语言模型(LLM)预训练数据集调研分析


二维图片控制,鼠标 滚轮 缩放 图片 ,如何 像 CAD 一样 ,,位置 不变,
基于预训练模型和语言增强的零样本视觉学习






 工商网监
工商网监
评论