 通过Logit调整的长尾学习
通过Logit调整的长尾学习

1. 论文信息
标题:Long-Tail Learning via Logit Adjustment
作者:Aditya Krishna Menon, Sadeep Jayasumana, Ankit Singh Rawat, Himanshu Jain, Andreas Veit, Sanjiv Kumar (Google Research)
原文链接:https://arxiv.org/abs/2007.07314
代码链接:https://github.com/google-research/google-research/tree/master/logit_adjustment
2. 介绍
在传统的分类和识别任务中,训练数据的分布往往都受到了人工的均衡,即不同类别的样本数量无明显差异,如最有影响力的ImageNet,每种类别的样本数量就保持在1300张左右。
在实际的视觉相关任务中,数据都存在如上图所示的长尾分布,少量类别占据了绝大多少样本,如图中Head部分,大量的类别仅有少量的样本,如图中Tail部分。解决长尾问题的方案一般分为4种:
重采样 (Re-sampling):采样过程中采样不同的策略,如对tail中的类别样本进行过采样,或者对head类别样本进行欠采样。
重加权 (Re-weighting):在训练过程中给与每种样本不同的权重,对tail类别loss设置更大的权重,这样有限样本数量。
新的学习策略 (Learning strategy):有专门为解决少样本问题涉及的学习方法可以借鉴,如:meta-learning、transfer learning。另外,还可以调整训练策略,将训练过程分为两步:第一步不区分head样本和tail样本,对模型正常训练;第二步,设置小的学习率,对第一步的模型使用各种样本平衡的策略进行finetune。
其实就笔者喜欢的风格而言,我对重加权这一方向的工作更为喜欢,因为通过各种统计学上的结论,来设计很好的loss改进来解决长尾/不均衡分布问题,我喜欢这类研究的原因是,他们(大部分)实现简单,往往只需几行代码修改下loss,就可以取得非常有竞争力的结果,因为简单所以很容易运用到一些复杂的任务中。
而从“奥卡姆剃刀”来看,我觉得各种迁移模型的理念虽然非常好,从头部常见类中学习通用知识,然后迁移到尾部少样本类别中,但是往往会需要设计复杂的模块,有增加参数实现过拟合的嫌疑,我认为这其实是把简单问题复杂化。我觉得从统计方面来设计更加优美,因此本文来介绍一篇我非常喜欢的从统计角度出发的工作。这篇论文来自Google Research,他们提供了一种logit的调整方法来应对长尾分布的问题。由于研究风格更偏向 machine learning, 所以论文风格更偏向统计类。
本文首先总结了对于logit的调整方法:
聚焦于测试阶段:对学习完的logit输出进行处理(post-hoc normalization),根据一些先验假设进行调整。
聚焦于训练阶段:在学习中调整loss函数,相对平衡数据集来说,调整优化的方向。
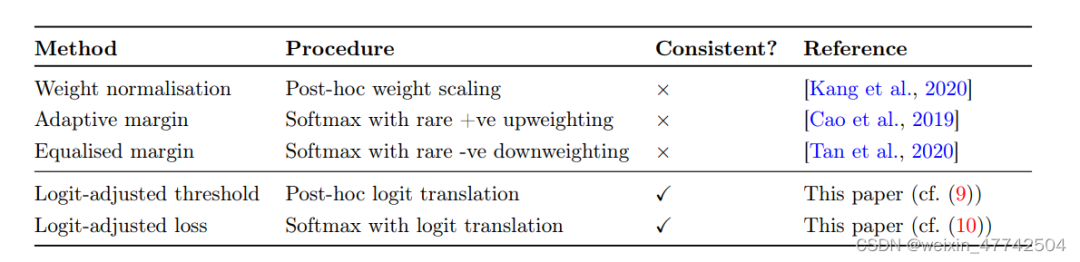
如上图,这两种方法都有许多较为优秀的工作,但是文中描述了这两种方法的几种限制:
weight normalization非常依赖于weight的模长会因为class的data数量稀少而变小,然而这种假设非常依赖于优化器的选择
直接修改loss进行重加权,也会影响模型的表征学习,从而导致优化过程不稳定,同时模型可能对尾部类过拟合,伤害了模型表征学习能力。
论文的motivation就是克服这些缺点,让不同类(head and tail classed)之间的logit能有一个相对较大的margin,设以一个consistent的loss,来让模型的性能更好。
3. 问题设定和过往方法回顾
3.1 Problem Settings
论文先从统计学的角度定义了一下这个problem settings,其实就是训练一个映射,让这个scorer的误分类损失最小:
但是类别不平衡的学习的setting导致P(y)分布是存在高度地skewed,使得许多尾部类别标签出现的概率很低。在这里,错误分类的比例就不是一个合适的metric: 因为模型似乎把所有的尾部类别都分类成头部类别也更够取得比较好的效果。所为了解决这个问题,一个自然的选择是平衡误差,平均每个类的错误率,从而让测试计算出的metric不是有偏的。
论文总结出了一个比较general的loss形式:
这里 是类别 yy 的权重;是另一个超参, 用来控制 margin 的大小。
3.2Post-hoc weight normalization
由于头部类别多,容易过拟合,自然会对头部类别overconfidence,所以我们需要通过一定的映射来调整logit。具体到调整的策略,自然是让大类置信度低一点,小类置信度高一点。
for , where and . Intuitively, either choice of upweights the contribution of rare labels through weight normalisation. The choice is motivated by the observations that tends to correlate with . Further to the above, one may enforce during training.
这里引用了一些其他做long-tail learning的论文,可以参考以便更好地对这一块进行理解。
3.3 Loss modification
至于对于loss的修改,就是很直接了在前面加一个权重,对于的取值,自然就是各个工作重点关注和改进的地方。
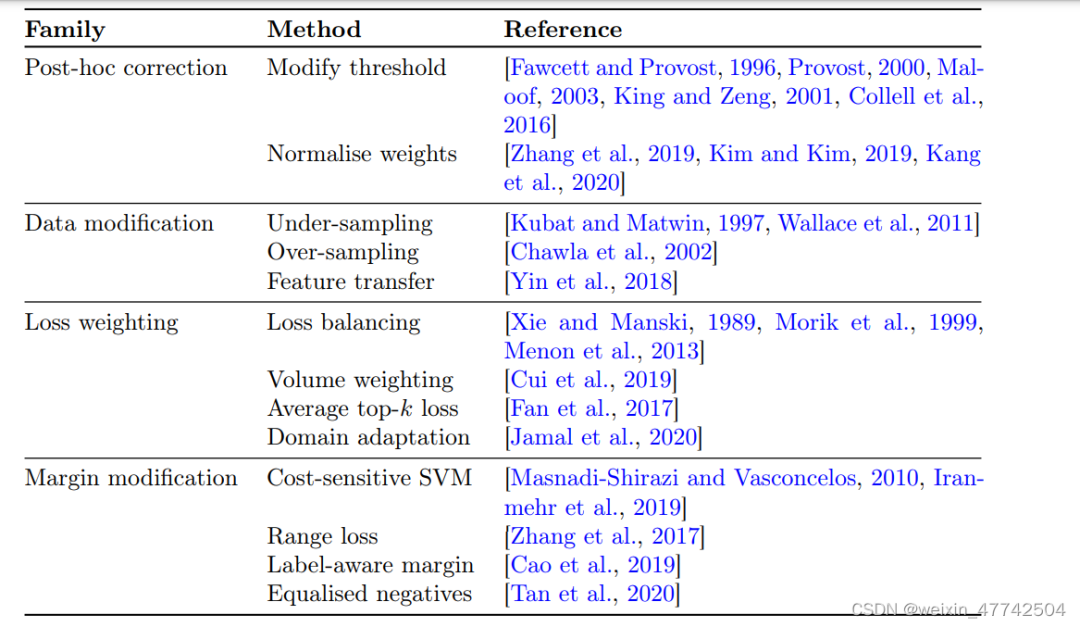
论文给予原有的各种方法各种比较全面的总结。
4. 方法
首先进行Post-hoc logit adjustment:
其实等号左边就是一个根据类别的样本数进行re-weighting。但是为了在exp的线性变换加上temperature时候不影响排序问题,所以把等号右边变成上式,通过这种方式放缩不会导致原本的排序出现问题。从而使得重加权仍能够给尾部类更高的权重。
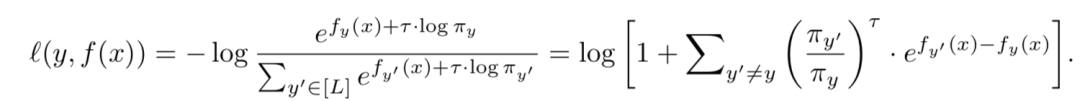
把loss改写成易于理解的方式就如下:
下面这个更为直接的loss被成为为pairwise margin loss,它可以把 y 与 y' 之间的margin拉大。
然后就是实现结合:
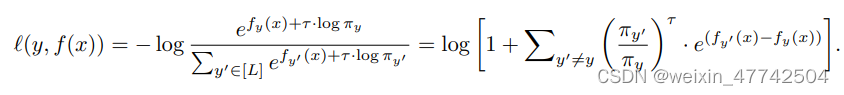
通过一些特殊的取值和另外的trick,可以实现两者的结合。
5. 实验结果
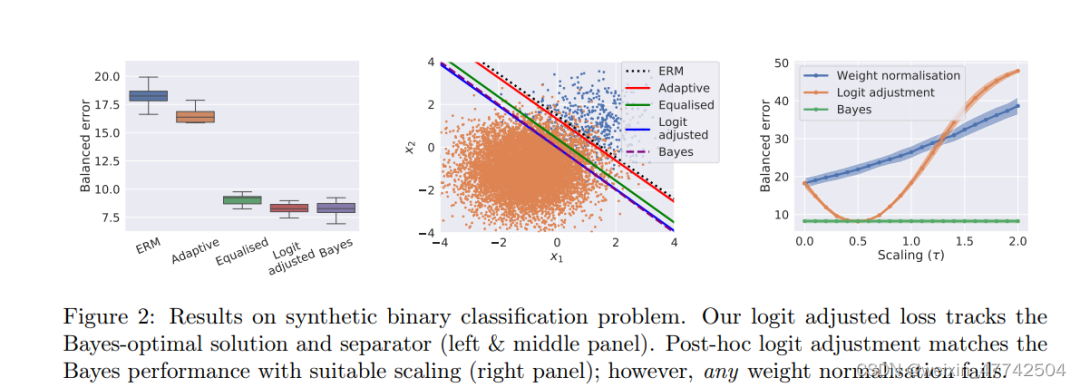
这张图非常有意思,可以看出两个设计理念非常有效果。
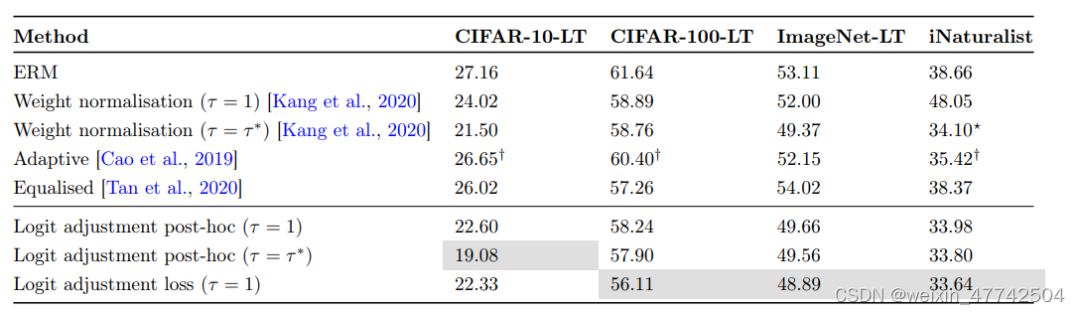
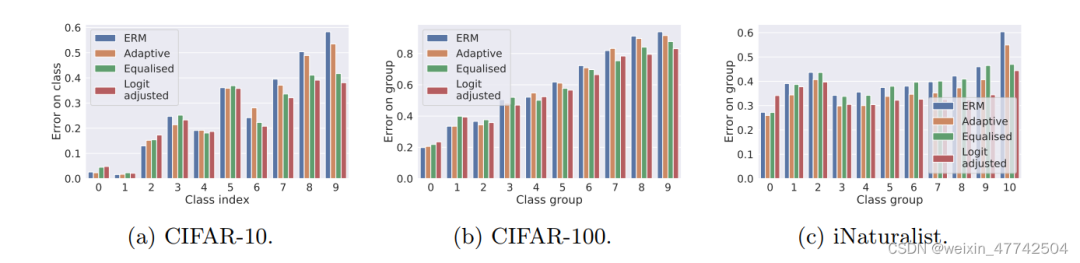
可以发现该方法在头部类和尾部类的性能都有所提升。
6. 结论
摘要:这篇写得很好的论文重新审视了logit调整的想法,以解决长尾问题。本文首先建立了一个统计框架,并以此为基础提出了两种有效实现对数平差的方法。他们通过在合成和自然长尾数据集上使用几个相关基线对其进行测试,进一步证明了这种方法的潜力。
审核编辑 :李倩
-
线性
+关注
关注
0文章
218浏览量
26141 -
模型
+关注
关注
1文章
3649浏览量
51716 -
数据集
+关注
关注
4文章
1230浏览量
26047
发布评论请先 登录
如何测试DC-DC电源模块的负载调整率?

学习物联网怎么入门?
如何避免传感器故障报警阈值调整不当的问题?

传感器故障报警的阈值可以调整吗?
常用伺服参数的调整
如何分析负载特性来调整报警阈值?

ANSA人体模型姿态调整工具介绍

变频器的频率怎么调整?

电源管理芯片U3205A拥有良好的线性调整率和负载调整率






 工商网监
工商网监
评论