 单个CNN就能够在多个数据集上实现SOTA
单个CNN就能够在多个数据集上实现SOTA

在 VGG、U-Net、TCN 网络中... CNN 虽然功能强大,但必须针对特定问题、数据类型、长度和分辨率进行定制,才能发挥其作用。我们不禁会问,可以设计出一个在所有这些网络中都运行良好的单一 CNN 吗? 本文中,来自阿姆斯特丹自由大学、阿姆斯特丹大学、斯坦福大学的研究者提出了 CCNN,单个 CNN 就能够在多个数据集(例如 LRA)上实现 SOTA !

- 论文地址:https://arxiv.org/pdf/2206.03398.pdf
- 代码地址:https://github.com/david-knigge/ccnn
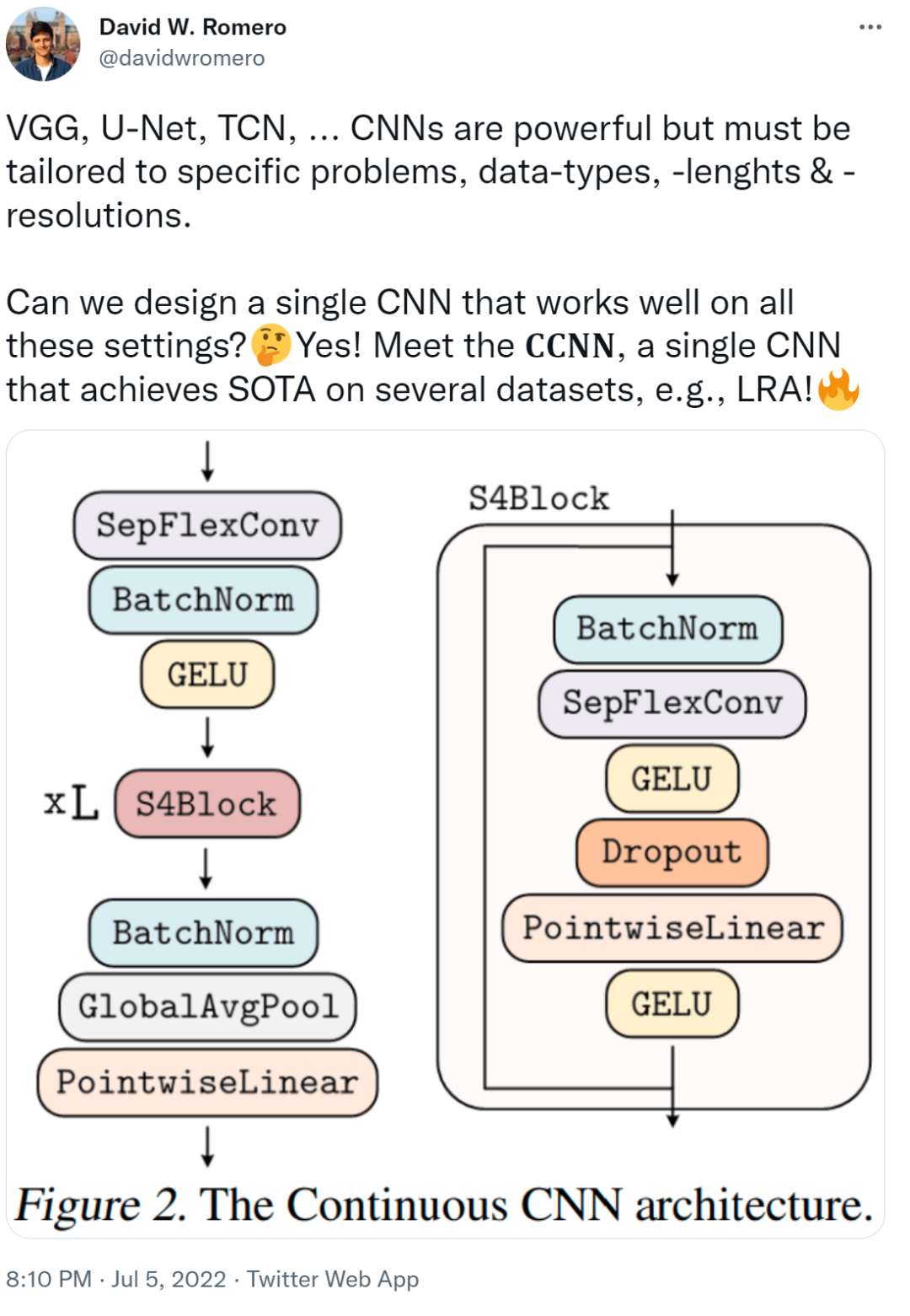
- 该研究提出 Continuous CNN(CCNN):一个简单、通用的 CNN,可以跨数据分辨率和维度使用,而不需要结构修改。CCNN 在序列 (1D)、视觉 (2D) 任务、以及不规则采样数据和测试时间分辨率变化的任务上超过 SOTA;
- 该研究对现有的 CCNN 方法提供了几种改进,使它们能够匹配当前 SOTA 方法,例如 S4。主要改进包括核生成器网络的初始化、卷积层修改以及 CNN 的整体结构。
 作为核生成器网络,同时将卷积核参数化为连续函数。该网络将坐标
作为核生成器网络,同时将卷积核参数化为连续函数。该网络将坐标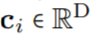 映射到该位置的卷积核值:
映射到该位置的卷积核值: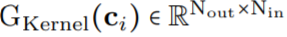 (图 1a)。通过将 K 个坐标
(图 1a)。通过将 K 个坐标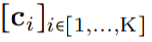 的向量通过 G_Kernel,可以构造一个大小相等的卷积核 K,即
的向量通过 G_Kernel,可以构造一个大小相等的卷积核 K,即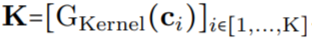 。随后,在输入信号
。随后,在输入信号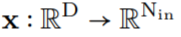 和生成的卷积核
和生成的卷积核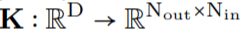 之间进行卷积运算,以构造输出特征表示
之间进行卷积运算,以构造输出特征表示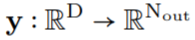 ,即
,即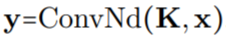 。
。
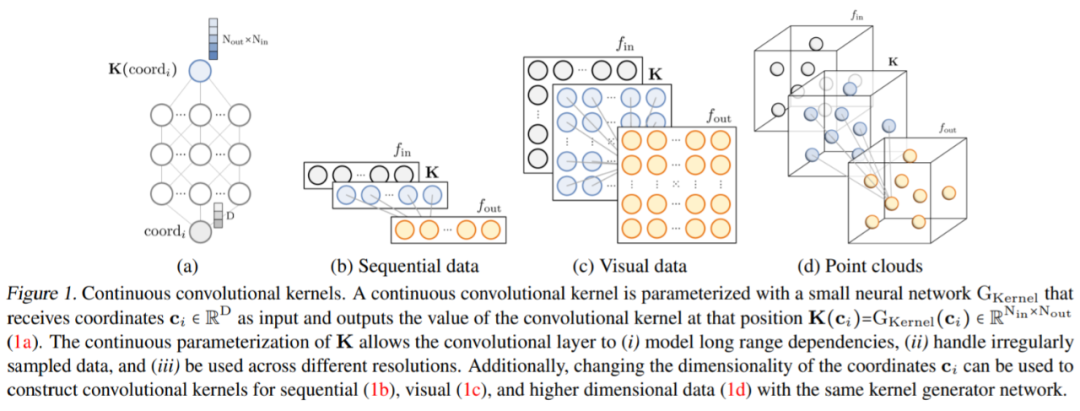
任意数据维度的一般操作。通过改变输入坐标 c_i 的维数 D,核生成器网络 G_Kernel 可用于构造任意维数的卷积核。因此可以使用相同的操作来处理序列 D=1、视觉 D=2 和更高维数据 D≥3。 不同输入分辨率的等效响应。如果输入信号 x 有分辨率变化,例如最初在 8KHz 观察到的音频现在在 16KHz 观察到,则与离散卷积核进行卷积以产生不同的响应,因为核将在每个分辨率下覆盖不同的输入子集。另一方面,连续核是分辨率无关的,因此无论输入的分辨率如何,它都能够识别输入。 当以不同的分辨率(例如更高的分辨率)呈现输入时,通过核生成器网络传递更精细的坐标网格就足够了,以便以相应的分辨率构造相同的核。对于以分辨率 r (1) 和 r (2) 采样的信号 x 和连续卷积核 K,两种分辨率下的卷积大约等于与分辨率变化成比例的因子:
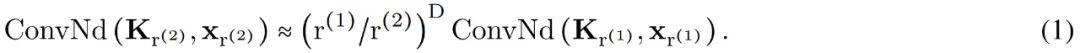
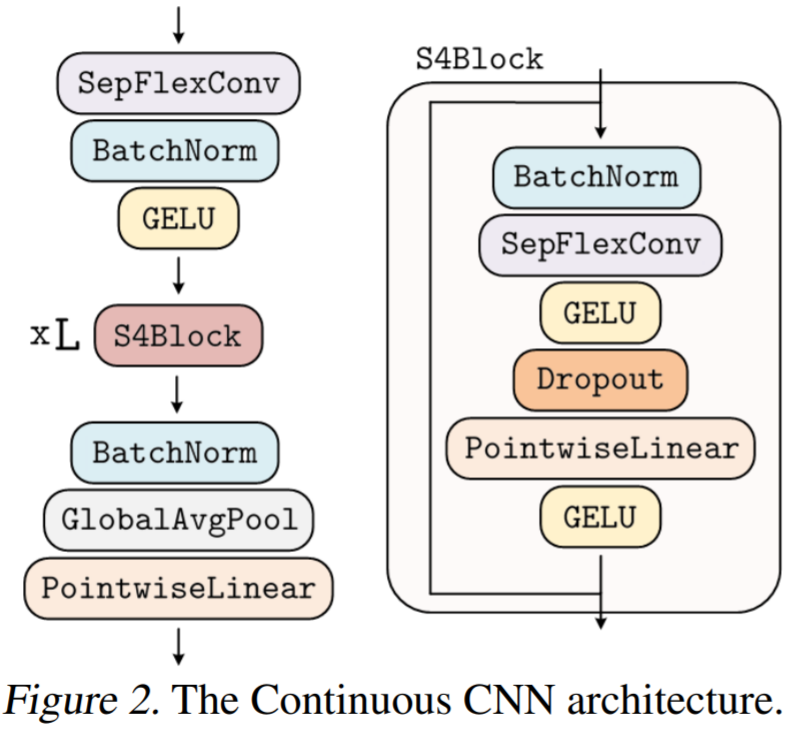
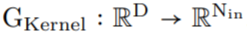 生成的核计算的,之后是从 N_in 到 N_out 进行逐点卷积。这种变化允许构建更广泛的 CCNN—— 从 30 到 110 个隐藏通道,而不会增加网络参数或计算复杂度。
生成的核计算的,之后是从 N_in 到 N_out 进行逐点卷积。这种变化允许构建更广泛的 CCNN—— 从 30 到 110 个隐藏通道,而不会增加网络参数或计算复杂度。正确初始化核生成器网络 G_Kernel。该研究观察到,在以前的研究中核生成器网络没有正确初始化。在初始化前,人们希望卷积层的输入和输出的方差保持相等,以避免梯度爆炸和消失,即 Var (x)=Var (y)。因此,卷积核被初始化为具有方差 Var (K)=gain^2 /(in channels ⋅ kernel size) 的形式,其增益取决于所使用的非线性。 然而,神经网络的初始化使输入的 unitary 方差保留在输出。因此,当用作核生成器网络时,标准初始化方法导致核具有 unitary 方差,即 Var (K)=1。结果,使用神经网络作为核生成器网络的 CNN 经历了与通道⋅内核大小成比例的特征表示方差的逐层增长。例如,研究者观察到 CKCNNs 和 FlexNets 在初始化时的 logits 大约为 1e^19。这是不可取的,这可能导致训练不稳定和需要低学习率。 为了解决这个问题,该研究要求 G_Kernel 输出方差等于 gain^2 /(in_channels⋅kernel_size)而不是 1。他们通过、
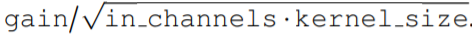 重新加权核生成器网络的最后一层。因此,核生成器网络输出的方差遵循传统卷积核的初始化,而 CCNN 的 logits 在初始化时呈现单一方差。
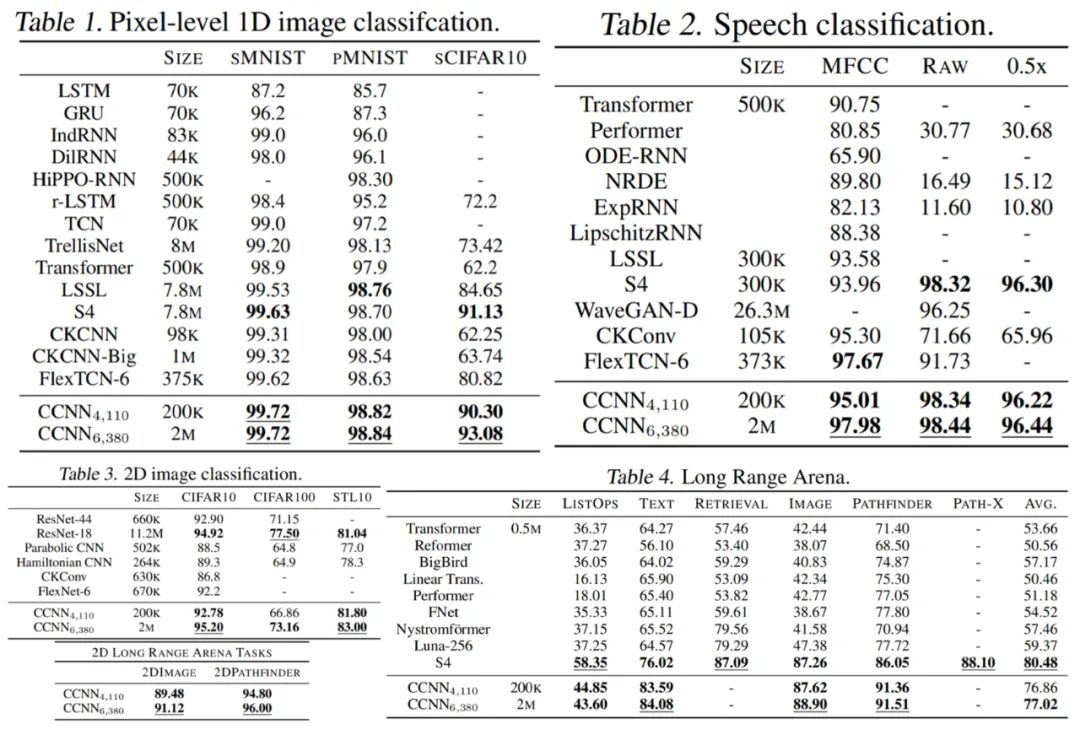
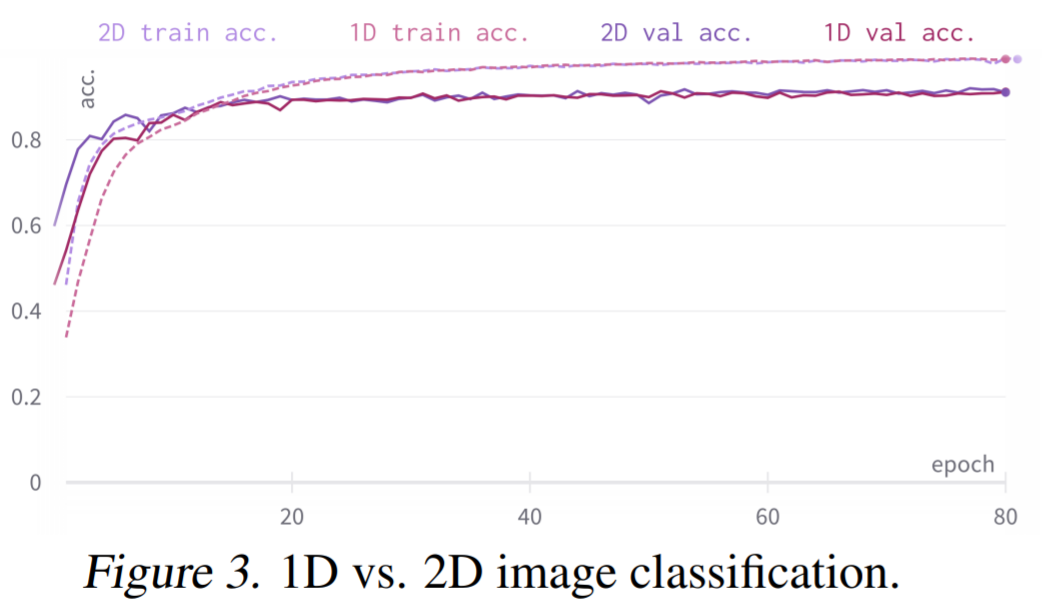
重新加权核生成器网络的最后一层。因此,核生成器网络输出的方差遵循传统卷积核的初始化,而 CCNN 的 logits 在初始化时呈现单一方差。实验结果 如下表 1-4 所示,CCNN 模型在所有任务中都表现良好。 首先是 1D 图像分类 CCNN 在多个连续基准上获得 SOTA,例如 Long Range Arena、语音识别、1D 图像分类,所有这些都在单一架构中实现的。CCNN 通常比其他方法模型更小架构更简单。 然后是 2D 图像分类:通过单一架构,CCNN 可以匹配并超越更深的 CNN。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
架构
+关注
关注
1文章
533浏览量
26506 -
深度学习
+关注
关注
73文章
5590浏览量
123903 -
cnn
+关注
关注
3文章
355浏览量
23248
原文标题:解决CNN固有缺陷, CCNN凭借单一架构,实现多项SOTA
文章出处:【微信号:CVSCHOOL,微信公众号:OpenCV学堂】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
热点推荐
CNN卷积神经网络设计原理及在MCU200T上仿真测试
数的提出很大程度的解决了BP算法在优化深层神经网络时的梯度耗散问题。当x>0 时,梯度恒为1,无梯度耗散问题,收敛快;当x<0 时,该层的输出为0。
CNN
发表于 10-29 07:49
构建CNN网络模型并优化的一般化建议
整个模型非常巨大。所以要想实现轻量级的CNN神经网络模型,首先应该避免尝试单层神经网络。
2)减少卷积核的大小:CNN神经网络是通过权值共享的方式,利用卷积运算从图像中提取线性纹理。在
发表于 10-28 08:02
蜂鸟E203的浮点指令集F的一些实现细节
蜂鸟E203的浮点指令集F的一些实现细节
既然E203不是多发射,且为了节省面积,一些指令使用FPU内的同一个子模块来执行,即FPU同时只能进行一种计算,我们只在FPU内部署了11个子模块,每种
发表于 10-24 08:57
指令集P扩展的主要内容
;SIMD指令扩展,SIMD指令可以在单个指令中执行多个相同或类似的操作,可以提高处理器的运算速度,通过添加SIMD指令,可以提高处理器的计算能力。
2. 指令集P扩展的主要代码
/
发表于 10-21 10:50
宏集HMI-4G套装,轻松搞定“数据上云+异地远程运维”
工业现场设备分散、环境复杂、网络难部署?宏集 HMI-4G 套装一站搞定!轻松打破数据孤岛,实现数据上云与远程运维。文末附有真实客户案例,欢
AURIX tc367通过 MCU SOTA 更新逻辑 IC 闪存是否可行?
你好专家:我的用例是 MCU 通过 SPI 连接到逻辑 IC,逻辑 IC 连接到 8MB 闪存,但 MCU PFLASH 大小为 2MB,通过 MCU SOTA 更新逻辑 IC 闪存是否可行?
发表于 08-11 06:36
求助,关于TC387使能以及配置SOTA 中一些问题求解
设置写保护密码, 而设置为CONFIRMED则必须有密码,设置密码后,后续对UCB的操作是否每次都要有解锁操作 ,
问题3:
在调试UCB去使能SOTA的过程中,出现debug口无法调试刷写
发表于 08-08 07:31
【高云GW5AT-LV60 开发套件试用体验】基于开发板进行深度学习实践,并尽量实现皮肤病理图片的识别
可以多看看。*附件:fpga_cnn.rar
相关文件都在里面了
探索了一阵子cnn,并且也跟着网上的一些开源的方案学习一些
比如这里的:# 一起学习用Verilog在FPGA上
发表于 06-11 22:35
STM32H747I DSI模块采用一个数据通道无法显示图片怎么解决?
,但是显示屏黑屏。可以确定的是D0P/D0N有数据输出,但是无法在显示屏上显示。
下面是我在官方例程中修改的地方,其实就是把两个数据通道改为
发表于 03-07 08:11
想选择一款能够实现多个通道数据采集的ADC,求推荐
各位专家好!这边想选择一款能够实现多个通道数据采集的ADC,由于对通道间的幅度和相位一致性要求较高,最好可以严格控制各通道之间的同步,要求单个
发表于 01-24 08:28
Hadoop 生态系统在大数据处理中的应用与实践
基础。它将大文件分割成多个数据块,存储在不同节点上,实现高容错性和高扩展性。NameNode 负责管理文件系统命名空间和元数据,DataNo
Chart FX图表类型:条形图(上)
类别(多序列),以便进行更深入的分析。 将数据传输给条形图非常简单,只需传输一个或多个数据序列以及每个数据序列附带的标记或标签即可。这些标签将显示在分类或时间轴(X 轴)

Mamba入局图像复原,达成新SOTA
MambaIRv2,更高性能、更高效率!另外还有ACM MM 2024上的Freqmamba方法,在图像去雨任务中取得了SOTA性能! 显然,这种基于Mamba的方法在图像复原领域,比





 工商网监
工商网监
评论