 如何使用xilinx的HLS工具进行算法的硬件加速
如何使用xilinx的HLS工具进行算法的硬件加速

【引言】
本系列教程演示如何使用xilinx的HLS工具进行算法的硬件加速。分为三个部分,分别为HLS端IP设计,vivado硬件环境搭建,SDK端软件控制。在HLS端,要将进行硬件加速的软件算法转换为RTL级电路,生成便于嵌入式使用的axi控制端口,进行数据的传输和模块的控制。【HLS介绍】
HLS可以将算法直接映射为RTL电路,实现了高层次综合。vivado-HLS可以实现直接使用 C,C++ 以及 System C 语言对Xilinx的FPGA器件进行编程。用户无需手动创建 RTL,通过高层次综合生成HDL级的IP核,从而加速IP创建。HLS的官方参考文档主要为:ug871( ug871-vivado-high-level-synthesis-tutorial.pdf )和ug902(ug902-vivado-high-level-synthesis.pdf)。 对于Vivado Hls来说,输入包括Tesbench,C/C++源代码和Directives,相应的输出为IP Catalog,DSP和SysGen,特别的,一个工程只能有一个顶层函数用于综和,这个顶层函数下面的子函数也是可以被综合的,会生成相应的VHDL和Verilog代码,所以,C综合后的RTL代码结构通常是跟原始C描述的结构是一致的,除非是子函数功能很简单,所需要的逻辑量很小。并不是所有的C/C++都可以被综合,动态内存分配和涉及到操作系统层面的操作不可以被综合。Vivado HLS 的设计流程如下:
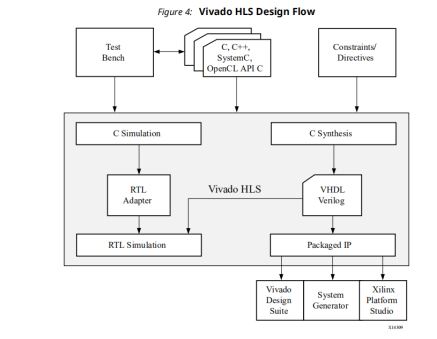
在整个流程中,用户先创建一个设计 C、C++ 或 SystemC 源代码,以及一个C的测试平台。通过 Vivado HLS Synthesis 运行设计,生成 RTL 设计,代码可以是 Verilog,也可以是 VHDL。有了 RTL 后,随即可以执行设计的 Verilog 或 VHDL 仿真,或使用工具的C封装器技术创建 SystemC 版本。然后可以进行System C架构级仿真,进一步根据之前创建的 C 测试平台,验证设计的架构行为和功能。设计固化后,就可以通过 Vivado 设计套件的物理实现流程来运行设计,将设计编程到器件上,在硬件中运行和/或使用 IP 封装器将设计转为可重用的 IP。
Step 1: 新建一个工程
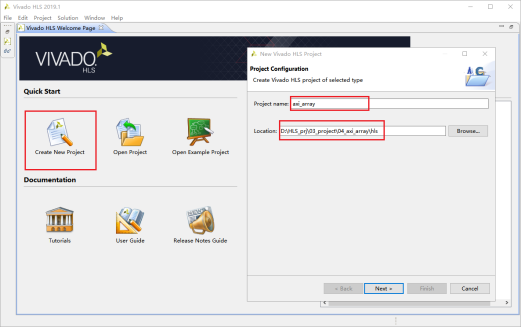
1,Creat New Project新建文档,输入工程名称和工程路径。完成后点击Next。
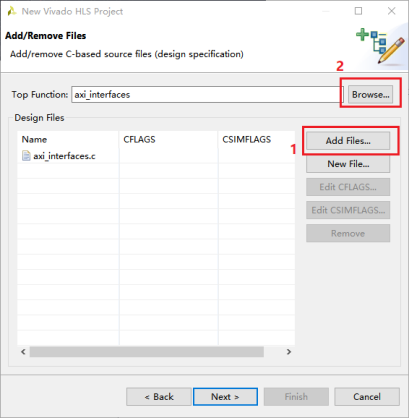
2,添加设计文件,并制定顶层函数。完成后点击Next。
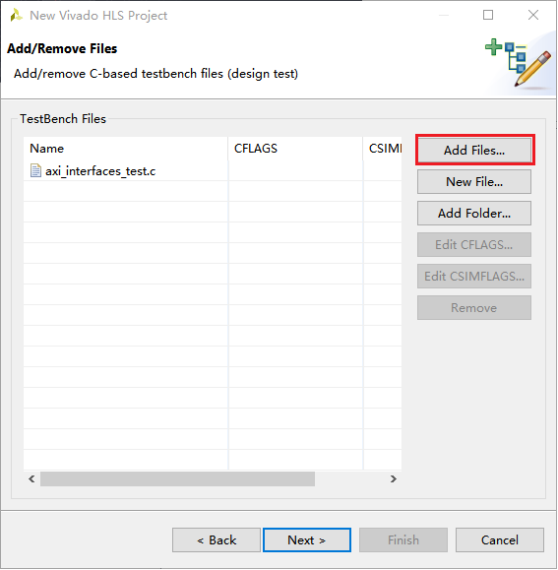
3,添加C语言仿真文件。完成后点击Next。
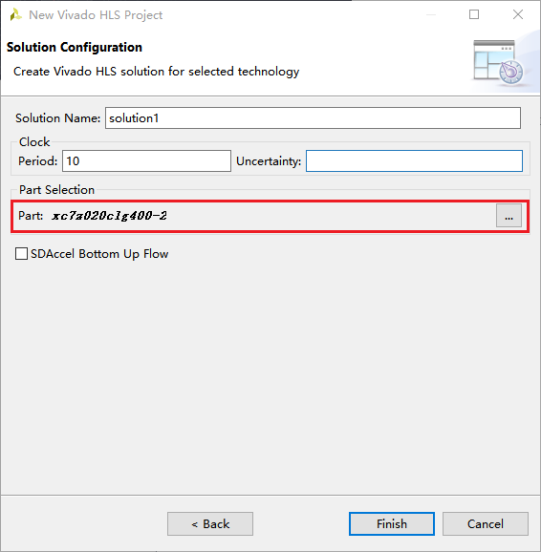
4,:配置Solution Name,一般默认即可。配置Clock Period,单位是ns。配置Uncertainty,默认为空。选择产品型号。完成后点击Finish。
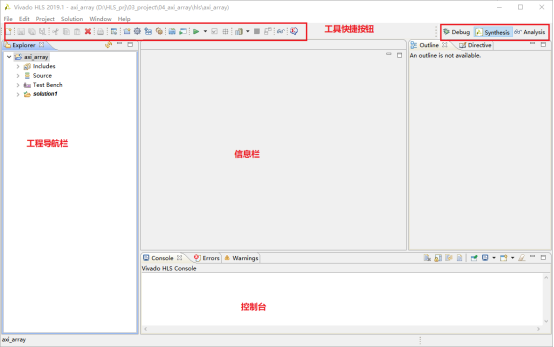
5,工程新建成功后进入的开发界面,HLS是典型的Eclipse界面,和SDK的界面十分相似。
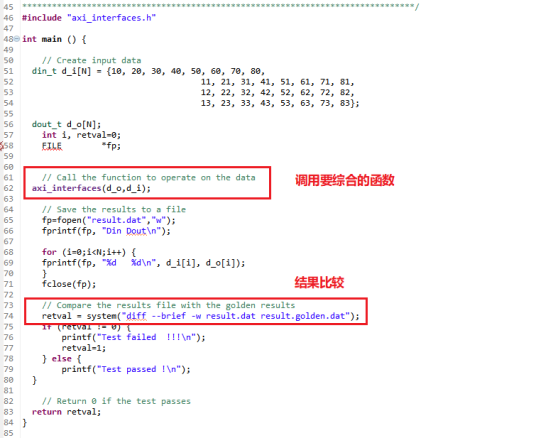
导入的文件的代码如下:1,源文件。axi_interfaces.c
2,头文件。axi_interfaces.htypedef int din_t; typedef int dout_t; typedefintdacc_t; voidaxi_interfaces(dout_td_o[N],din_td_i[N]); int main () { // Create input data din_t d_i[N] = {10, 20, 30, 40, 50, 60, 70, 80, 11, 21, 31, 41, 51, 61, 71, 81, 12, 22, 32, 42, 52, 62, 72, 82, 13, 23, 33, 43, 53, 63, 73, 83}; dout_t d_o[N]; int i, retval=0; FILE*fp; // Call the function to operate on the data axi_interfaces(d_o,d_i); // Save the results to a file fp=fopen("result.dat","w"); fprintf(fp, "Din Dout "); for(i=0;i fprintf(fp, "%d %d ", d_i[i], d_o[i]); } fclose(fp); // Compare the results file with the golden results retval = system("diff --brief -w result.dat result.golden.dat"); if (retval != 0) { printf("Test failed !!! "); retval=1; } else { printf("Test passed ! "); } // Return 0 if the test passes return retval; }
4,测试数据。result.golden.datDin Dout 10 10 20 20 30 30 40 40 50 50 60 60 70 70 80 80 11 21 21 41 31 61 41 81 51 101 61 121 71 141 81 161 12 33 22 63 32 93 42 123 52 153 62 183 72 213 82 243 13 46 23 86 33 126 43 166 53 206 63 246 73 286 83 326
Step 2: C源代码验证
本步骤是对功能代码的逻辑验证,相当于功能前仿。1,测试程序的代码入下图。该程序先调用综合的函数,得到计算结果,再和预先的数据集进行比较,最后返回计较的结果。计算结果和预先的数据集一致时,测试通过,不一致时,测试失败。需要查看代码,寻找错误。
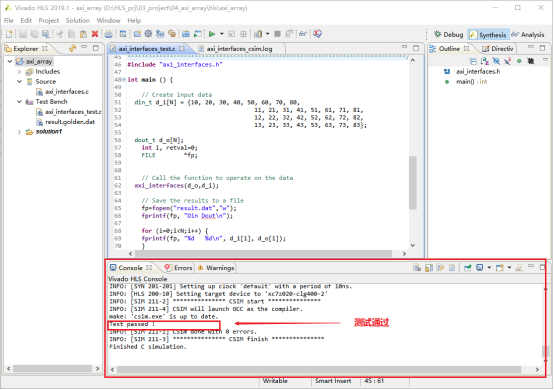
2,点击红框中的按钮,开始C源代码验证。
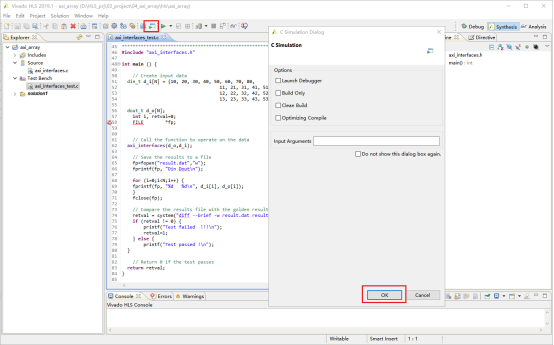
3,验证的结果显示在控制栏中。如图显示,测试通过。
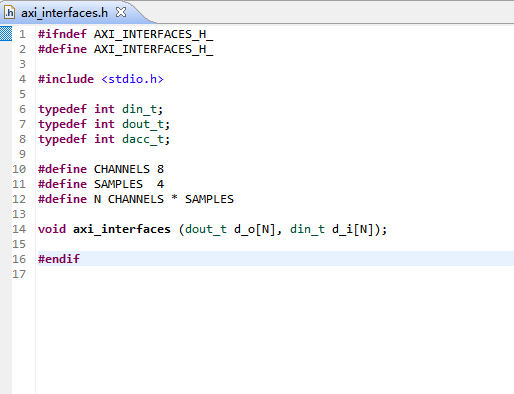
4,在头文件中,重定义了数据类型,参数,并进行了函数声明。
Step 3: 高层次综合
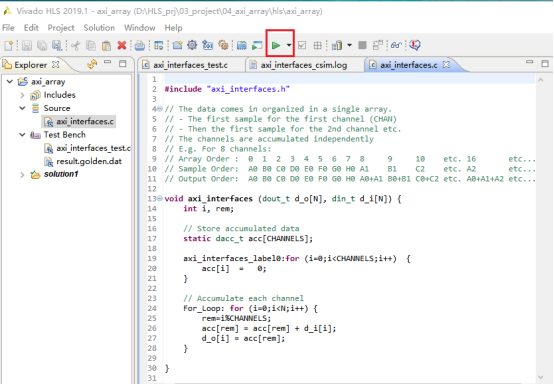
本步骤是把功能代码的综合成RTL逻辑。1,点击红框中的按钮,将C代码综合成RTL。综合完成后,查看结果。
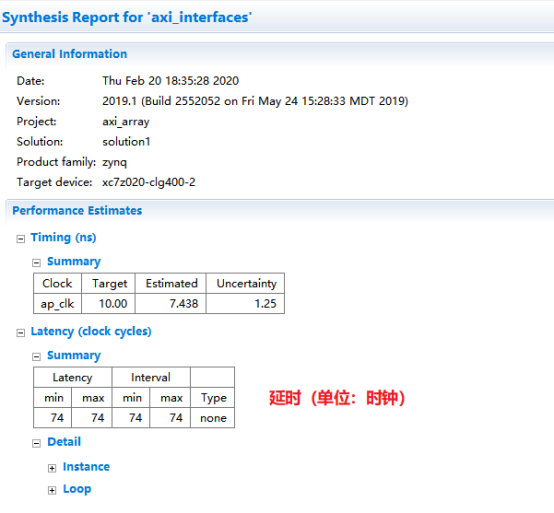
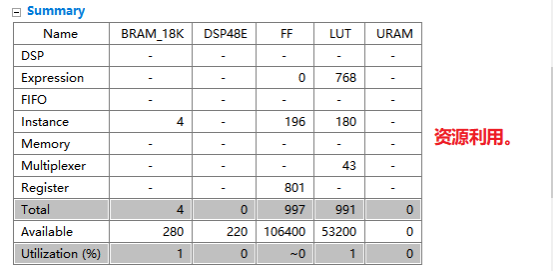
2,综合完成后,查看综合报告。包括时序,延时,资源占用,端口信息等。
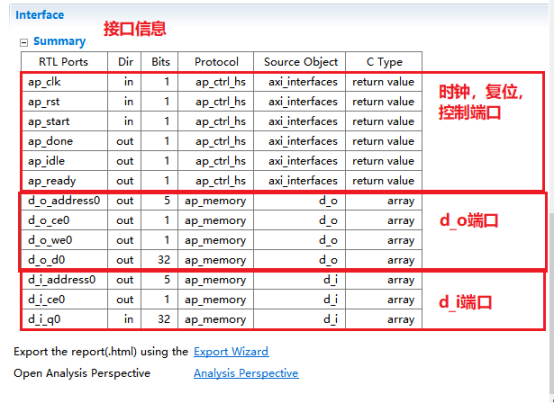
3,端口分析。(1)控制端口用于控制和显示该模块的工作状态。各个端口的功功能如下,默认情况下会生成下面四个控制端口。lap_start(in):为高时,该模块开始处理数据。lap_done(out):为高时,表示模块处理数据完成。lap_idle(out):表明模块是否处于空闲态。高电平有效。为高时,该处于空闲态。lap_ready(out):为高时,表示模块可以接受新的数据。(2)数据端口用于传递模块的输入输出参数。参数d_o,d_i 为数组类型,故默认状态下回生成内存接口。内存接口 (数组类型参数)数据来自外部的memory,通过地址信号读取相应的数据,输入到该模块中。输入数组从外部内存中读源数据,输出数组从向外部内存写入结果数据。各个端口的定义如下。laddress:地址信号lce0:片选信号lwe0:写使能信号ld0 :数据信号4,综合结果分析。在分析界面,可以看到模块的运行情况。包括数据依赖关系和各个周期执行的操作,IO口的读写,内存端口的访问等等。
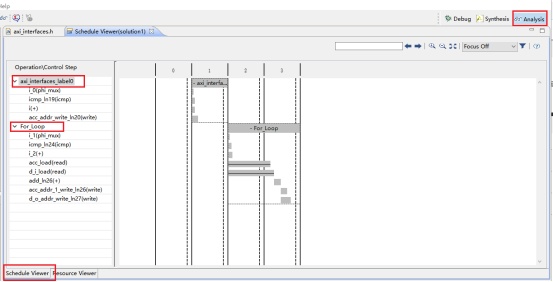
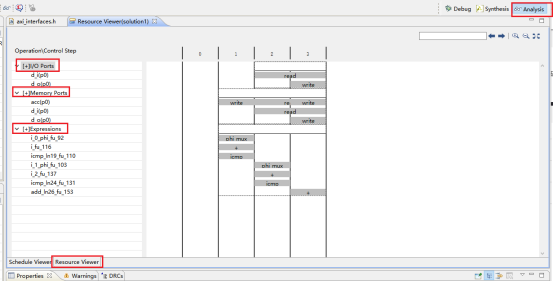
Step 4: 综合优化
在使用高层次综合,创造高质量的RTL设计时,一个重要部分就是对C代码进行优化。Vivado HLS拥有自动优化的功能,试图最小化loop(循环)和function(函数)的latency。除了自动优化,我们可以手动进行程序优化,即用在不同的solution中添加不同的directive(优化指令)的方法,进行优化和性能对比。其中,对同一个工程,可以建立多个不同的solution(解决方案),为不同的solution添加directive可以达到如下目的。优化的类型可分为如下类别:l端口优化。指定不同类型的模块端口。l函数优化。加快函数的执行速度,减小执行周期。l循坏优化。利用展开和流水线形式,减小循环的执行周期。1,点击下面红框的图标,新建solution。
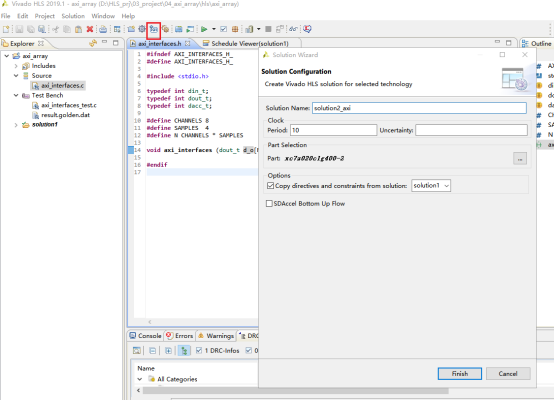
2,不同solution位于不同的文件夹中。
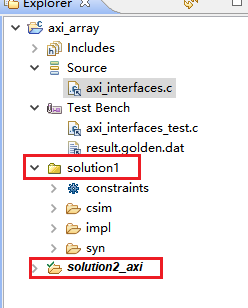
3,选中综合文件。可以在direct框中看可进行优化的标签。
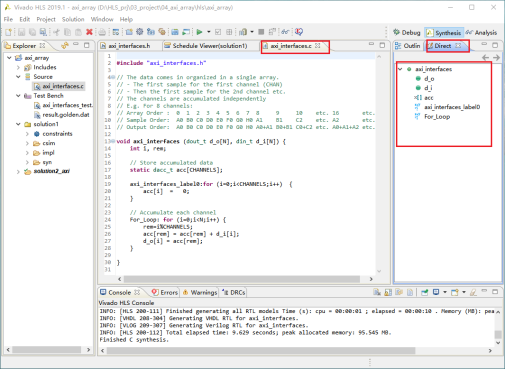
4,双击选择d_o,选择interface,s_axilite。点击ok。将d_o的端口类型设置为s_axilite类型。
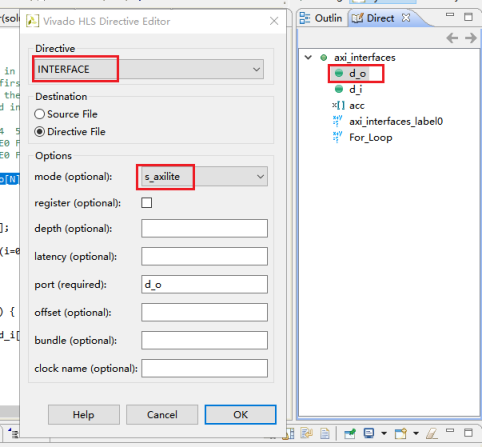
5,参考d_o,将d_i的接口类型也设置为s_axilite。将d_i的端口类型设置为s_axilite类型。
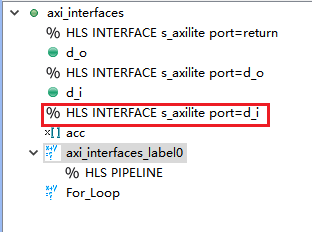
6,双击选择函数名称axi_interface,选择interface,s_axilite。点击ok。将控制端口的端口类型设置为s_axilite类型。
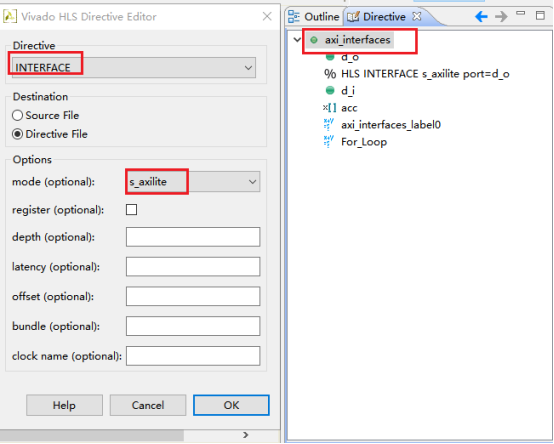
7,双击循环标签,选择流水线优化(pipeline),点击ok。
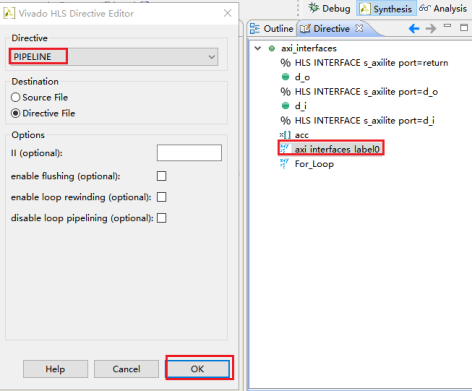
8,双击循环标签,选择循环展开优化(unroll),点击ok。
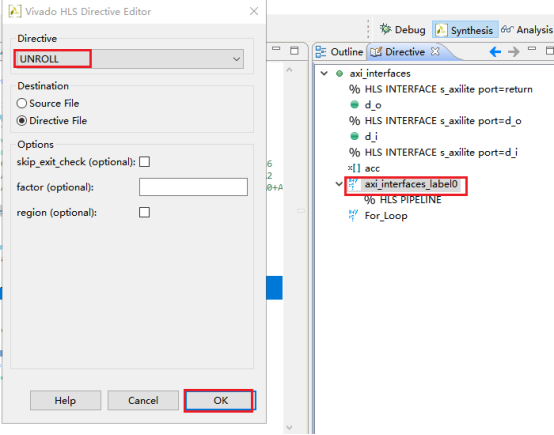
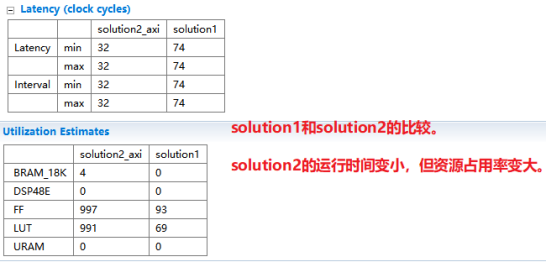
9,同上,也将标签为for_loop的循环进行流水线和展开优化。10,最终的优化情况总结如下。
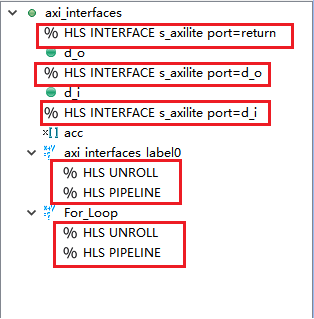
11,重新进行函数综合,查看综合报告如下。

Step 5: 综合结果文件
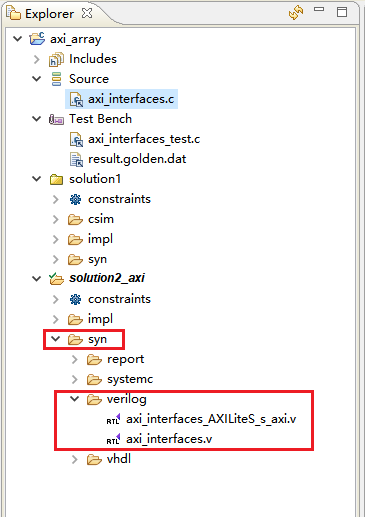
综合完成后,在各个solution的syn文件夹中可以看到综合器生成的RTL代码。包括systemc,VHDL,Verilog。
Step 6: 导出IP
在菜单里Solution>Export TL,设置如下,点击ok。
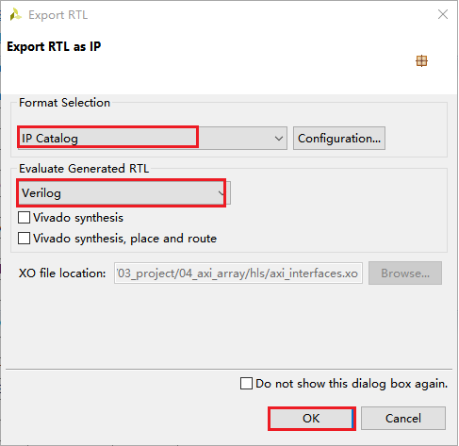
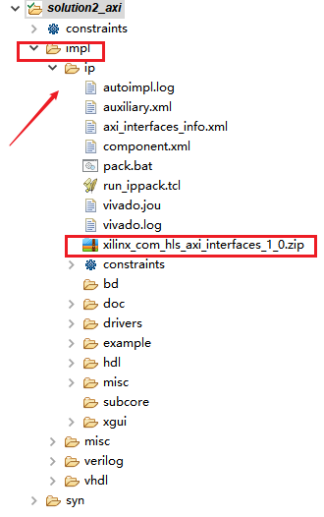
IP封装完成后,会在impl文件夹中输出ip文件夹,其中包含了RTL代码(hdl),模块驱动(drivers),文档(doc)等信息,其中包含一个压缩包文件,是用于建立vivado工程所用的IP压缩包。
Step 7: 总结
本文重点讲解了hls软件的使用方法和优化方法,在C语言模块设计上没有重点讲解。在掌握了hls软件的基本用法和优化方法后,接下来就可以设计更加复杂的C语言模块,进行rtl综合,加快设计开发的速度。审核编辑 :李倩
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
算法
+关注
关注
23文章
4760浏览量
97144 -
Xilinx
+关注
关注
73文章
2192浏览量
129929 -
Vivado
+关注
关注
19文章
846浏览量
70474
原文标题:Vivado-hls使用实例
文章出处:【微信号:zhuyandz,微信公众号:FPGA之家】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
热点推荐
Camellia算法的实现(基于开源蜂鸟E203协处理器)
硬件加速器的效果。
Camellia算法的介绍
Camellia 算法由 NTT 公司和 Mitsubishi 电子公司与 2000 年联合开发,是一种Feistel 结构的分组密码(分组长度为
发表于 10-30 07:04
复杂的软件算法硬件IP核的实现
硬件加速 IP 核 HDL 文件的生成分为两个步骤,首先根据将要接入的 SOPC 系统的总线的特性,将算法做适当的包装、暴露相关的接口以及调用方法,即适配总线接口。不同的 SOPC 总线有不同的时序以及
发表于 10-30 07:02
常用硬件加速的方法
之前总结了一些常用硬件加速方法
1)面积换速度:也就是串转并运算,可以多个模块同时计算;
2)时间换空间:时序收敛下通过频率提高性能,虽然面积可能稍微加大点;
3)流水线操作:流水线以面积换性能,以
发表于 10-29 06:20
软硬件协同技术分享 - 任务划分 + 自定义指令集
开发技术。分文将分享介绍硬件加速器与软件结合的协同开发方式
软硬件任务划分
我们的硬件设计涉及到MFCC模块。直接交由CPU的一次指令的五级流水线处理在麦克风数据取入上的资源耗费可以说是
发表于 10-28 08:03
硬件加速模块的时钟设计
的每一个操作赋予一个时间片,每一个操作都会在这个时间片内完成,这个时间片的时长为clk_l的时钟周期,在整个硬件加速模块中最为重要。
clk_r : 硬件加速模块的每一层在每一次进行运算之前,都去先读
发表于 10-23 07:28
睿擎SDK V1.5.0重磅升级:EtherCAT低抖动,AMP虚拟网卡,LVGL硬件加速,多核调试等性能大幅提升|产品动态
)。AMP模式下虚拟网卡驱动支持,双系统通信更加便利,更完善的Perfetto多核性能调试工具,AIUVC人脸识别示例,优化LVGL支持硬件加速等。并提供对应的教

如何验证硬件加速是否真正提升了通信协议的安全性?
验证硬件加速是否真正提升通信协议的安全性,需从 安全功能正确性、抗攻击能力增强、安全性能适配、合规一致性 等核心维度展开,结合实验室测试与真实场景验证,避免 “硬件参与即安全提升” 的表面判断。以下

有哪些方法可以确保硬件加速与通信协议的兼容性?
确保硬件加速与通信协议的兼容性,核心是从 硬件选型、协议标准匹配、软硬件接口适配、全场景测试验证 四个维度建立闭环,避免因硬件功能缺失、接口不兼容或协议特性支持不全导致的性能损耗、
如何利用硬件加速提升通信协议的安全性?
产品实拍图 利用硬件加速提升通信协议安全性,核心是通过 专用硬件模块或可编程硬件 ,承接软件层面难以高效处理的安全关键操作(如加密解密、认证、密钥管理等),在提升性能的同时,通过硬件级

基于FPGA的压缩算法加速实现
本设计中,计划实现对文件的压缩及解压,同时优化压缩中所涉及的信号处理和计算密集型功能,实现对其的加速处理。本设计的最终目标是证明在充分并行化的硬件体系结构 FPGA 上实现该算法时,可以大大提高该
如何使用AMD Vitis HLS创建HLS IP
本文逐步演示了如何使用 AMD Vitis HLS 来创建一个 HLS IP,通过 AXI4 接口从存储器读取数据、执行简单的数学运算,然后将数据写回存储器。接着会在 AMD Vivado Design Suite 设计中使用此 HLS

Vivado HLS设计流程
为了尽快把新产品推向市场,数字系统的设计者需要考虑如何加速设计开发的周期。设计加速主要可以从“设计的重用”和“抽象层级的提升”这两个方面来考虑。Xilinx 推出的 Vivado HLS
FPGA+AI王炸组合如何重塑未来世界:看看DeepSeek东方神秘力量如何预测......
降低。这种趋势使得更多AI开发者能够利用FPGA进行硬件加速。
4.市场与产业的推动• 市场规模增长:随着5G、AI和物联网等新兴技术的快速发展,FPGA市场正在经历显著增长。预计到2025年,中国
发表于 03-03 11:21
算法加速的概念、意义、流程和应用
运算通常需要高并行度或专门逻辑。算法加速就是把这些计算密集、规律性高的部分从通用 CPU 中“提取”出来,交给一个专门设计的硬件模块来完成。 类比:如果把 CPU 想象成一位“通才”工人,什么都能做但速度有限;那么
数据中心中的FPGA硬件加速器
再来看一篇FPGA的综述,我们都知道微软包括国内的云厂商其实都在数据中心的服务器中部署了FPGA,所以这篇论文就以数据中心的视角,来看下FPGA这个硬件加速器。 还是一样,想要论文原文的可以私信





 工商网监
工商网监
评论