 虚拟内存管理API提供管理统一虚拟地址空间的方法
虚拟内存管理API提供管理统一虚拟地址空间的方法

E.1. Introduction
虚拟内存管理 API 为应用程序提供了一种直接管理统一虚拟地址空间的方法,该空间由 CUDA 提供,用于将物理内存映射到 GPU 可访问的虚拟地址。在 CUDA 10.2 中引入的这些 API 还提供了一种与其他进程和图形 API(如 OpenGL 和 Vulkan)进行互操作的新方法,并提供了用户可以调整以适应其应用程序的更新内存属性。
从历史上看,CUDA 编程模型中的内存分配调用(例如 cudaMalloc)返回了一个指向 GPU 内存的内存地址。这样获得的地址可以与任何 CUDA API 一起使用,也可以在设备内核中使用。但是,分配的内存无法根据用户的内存需求调整大小。为了增加分配的大小,用户必须显式分配更大的缓冲区,从初始分配中复制数据,释放它,然后继续跟踪新分配的地址。这通常会导致应用程序的性能降低和峰值内存利用率更高。本质上,用户有一个类似 malloc 的接口来分配 GPU 内存,但没有相应的 realloc 来补充它。虚拟内存管理 API 将地址和内存的概念解耦,并允许应用程序分别处理它们。 API 允许应用程序在他们认为合适的时候从虚拟地址范围映射和取消映射内存。
在通过 cudaEnablePeerAccess 启用对等设备访问内存分配的情况下,所有过去和未来的用户分配都映射到目标对等设备。这导致用户无意中支付了将所有 cudaMalloc 分配映射到对等设备的运行时成本。然而,在大多数情况下,应用程序通过仅与另一个设备共享少量分配进行通信,并且并非所有分配都需要映射到所有设备。使用虚拟内存管理,应用程序可以专门选择某些分配可从目标设备访问。
CUDA 虚拟内存管理 API 向用户提供细粒度控制,以管理应用程序中的 GPU 内存。它提供的 API 允许用户:
将分配在不同设备上的内存放入一个连续的 VA 范围内。
使用平台特定机制执行内存共享的进程间通信。
在支持它们的设备上选择更新的内存类型。
为了分配内存,虚拟内存管理编程模型公开了以下功能:
分配物理内存。
保留 VA 范围。
将分配的内存映射到 VA 范围。
控制映射范围的访问权限。
请注意,本节中描述的 API 套件需要支持 UVA 的系统。
E.2. Query for support
在尝试使用虚拟内存管理 API 之前,应用程序必须确保他们希望使用的设备支持 CUDA 虚拟内存管理。 以下代码示例显示了查询虚拟内存管理支持:
int deviceSupportsVmm; CUresult result = cuDeviceGetAttribute(&deviceSupportsVmm, CU_DEVICE_ATTRIBUTE_VIRTUAL_MEMORY_MANAGEMENT_SUPPORTED, device); if (deviceSupportsVmm != 0) { // `device` supports Virtual Memory Management }
E.3. Allocating Physical Memory
通过虚拟内存管理 API 进行内存分配的第一步是创建一个物理内存块,为分配提供支持。 为了分配物理内存,应用程序必须使用 cuMemCreate API。 此函数创建的分配没有任何设备或主机映射。 函数参数 CUmemGenericAllocationHandle 描述了要分配的内存的属性,例如分配的位置、分配是否要共享给另一个进程(或其他图形 API),或者要分配的内存的物理属性。 用户必须确保请求分配的大小必须与适当的粒度对齐。 可以使用 cuMemGetAllocationGranularity 查询有关分配粒度要求的信息。 以下代码片段显示了使用 cuMemCreate 分配物理内存:
CUmemGenericAllocationHandle allocatePhysicalMemory(int device, size_t size) {
CUmemAllocationProp prop = {};
prop.type = CU_MEM_ALLOCATION_TYPE_PINNED;
prop.location.type = CU_MEM_LOCATION_TYPE_DEVICE;
prop.location.id = device;
cuMemGetAllocationGranularity(&granularity, &prop, CU_MEM_ALLOC_GRANULARITY_MINIMUM);
// Ensure size matches granularity requirements for the allocation
size_t padded_size = ROUND_UP(size, granularity);
// Allocate physical memory
CUmemGenericAllocationHandle allocHandle;
cuMemCreate(&allocHandle, padded_size, &prop, 0);
return allocHandle;
}
由 cuMemCreate 分配的内存由它返回的 CUmemGenericAllocationHandle 引用。 这与 cudaMalloc风格的分配不同,后者返回一个指向 GPU 内存的指针,该指针可由在设备上执行的 CUDA 内核直接访问。 除了使用 cuMemGetAllocationPropertiesFromHandle 查询属性之外,分配的内存不能用于任何操作。 为了使此内存可访问,应用程序必须将此内存映射到由 cuMemAddressReserve 保留的 VA 范围,并为其提供适当的访问权限。 应用程序必须使用 cuMemRelease API 释放分配的内存。
E.3.1. Shareable Memory Allocations
使用 cuMemCreate 用户现在可以在分配时向 CUDA 指示他们已指定特定分配用于进程间通信或图形互操作目的。应用程序可以通过将 CUmemAllocationProp::requestedHandleTypes 设置为平台特定字段来完成此操作。在 Windows 上,当 CUmemAllocationProp::requestedHandleTypes 设置为 CU_MEM_HANDLE_TYPE_WIN32 时,应用程序还必须在 CUmemAllocationProp::win32HandleMetaData 中指定 LPSECURITYATTRIBUTES 属性。该安全属性定义了可以将导出的分配转移到其他进程的范围。
CUDA 虚拟内存管理 API 函数不支持传统的进程间通信函数及其内存。相反,它们公开了一种利用操作系统特定句柄的进程间通信的新机制。应用程序可以使用 cuMemExportToShareableHandle 获取与分配相对应的这些操作系统特定句柄。这样获得的句柄可以通过使用通常的 OS 本地机制进行传输,以进行进程间通信。接收进程应使用 cuMemImportFromShareableHandle 导入分配。
用户必须确保在尝试导出使用 cuMemCreate 分配的内存之前查询是否支持请求的句柄类型。以下代码片段说明了以特定平台方式查询句柄类型支持。
int deviceSupportsIpcHandle; #if defined(__linux__) cuDeviceGetAttribute(&deviceSupportsIpcHandle, CU_DEVICE_ATTRIBUTE_HANDLE_TYPE_POSIX_FILE_DESCRIPTOR_SUPPORTED, device)); #else cuDeviceGetAttribute(&deviceSupportsIpcHandle, CU_DEVICE_ATTRIBUTE_HANDLE_TYPE_WIN32_HANDLE_SUPPORTED, device)); #endif
用户应适当设置CUmemAllocationProp::requestedHandleTypes,如下所示:
#if defined(__linux__)
prop.requestedHandleTypes = CU_MEM_HANDLE_TYPE_POSIX_FILE_DESCRIPTOR;
#else
prop.requestedHandleTypes = CU_MEM_HANDLE_TYPE_WIN32;
prop.win32HandleMetaData = // Windows specific LPSECURITYATTRIBUTES attribute.
#endif
memMapIpcDrv 示例可用作将 IPC 与虚拟内存管理分配一起使用的示例。
E.3.2. Memory Type
在 CUDA 10.2 之前,应用程序没有用户控制的方式来分配某些设备可能支持的任何特殊类型的内存。 使用 cuMemCreate 应用程序还可以使用 CUmemAllocationProp::allocFlags 指定内存类型要求,以选择任何特定的内存功能。 应用程序还必须确保分配设备支持请求的内存类型。
E.3.2.1. Compressible Memory
可压缩内存可用于加速对具有非结构化稀疏性和其他可压缩数据模式的数据的访问。 压缩可以节省 DRAM 带宽、L2 读取带宽和 L2 容量,具体取决于正在操作的数据。 想要在支持计算数据压缩的设备上分配可压缩内存的应用程序可以通过将 CUmemAllocationProp::allocFlags::compressionType 设置为 CU_MEM_ALLOCATION_COMP_GENERIC 来实现。 用户必须通过 CU_DEVICE_ATTRIBUTE_GENERIC_COMPRESSION_SUPPORTED 查询设备是否支持计算数据压缩。 以下代码片段说明了查询可压缩内存支持 cuDeviceGetAttribute。
int compressionSupported = 0; cuDeviceGetAttribute(&compressionSupported, CU_DEVICE_ATTRIBUTE_GENERIC_COMPRESSION_SUPPORTED, device);
在支持计算数据压缩的设备上,用户需要在分配时选择加入,如下所示:
prop.allocFlags.compressionType = CU_MEM_ALLOCATION_COMP_GENERIC;
由于硬件资源有限等各种原因,分配的内存可能没有压缩属性,用户需要使用cuMemGetAllocationPropertiesFromHandle查询回分配内存的属性并检查压缩属性。
CUmemAllocationPropPrivate allocationProp = {};
cuMemGetAllocationPropertiesFromHandle(&allocationProp, allocationHandle);
if (allocationProp.allocFlags.compressionType == CU_MEM_ALLOCATION_COMP_GENERIC)
{
// Obtained compressible memory allocation
}
E.4. Reserving a Virtual Address Range
由于使用虚拟内存管理,地址和内存的概念是不同的,因此应用程序必须划出一个地址范围,以容纳由 cuMemCreate 进行的内存分配。保留的地址范围必须至少与用户计划放入其中的所有物理内存分配大小的总和一样大。
应用程序可以通过将适当的参数传递给 cuMemAddressReserve 来保留虚拟地址范围。获得的地址范围不会有任何与之关联的设备或主机物理内存。保留的虚拟地址范围可以映射到属于系统中任何设备的内存块,从而为应用程序提供由属于不同设备的内存支持和映射的连续 VA 范围。应用程序应使用 cuMemAddressFree 将虚拟地址范围返回给 CUDA。用户必须确保在调用 cuMemAddressFree 之前未映射整个 VA 范围。这些函数在概念上类似于 mmap/munmap(在 Linux 上)或 VirtualAlloc/VirtualFree(在 Windows 上)函数。以下代码片段说明了该函数的用法:
CUdeviceptr ptr; // `ptr` holds the returned start of virtual address range reserved. CUresult result = cuMemAddressReserve(&ptr, size, 0, 0, 0); // alignment = 0 for default alignment
E.5. Virtual Aliasing Support
虚拟内存管理 API 提供了一种创建多个虚拟内存映射或“代理”到相同分配的方法,该方法使用对具有不同虚拟地址的 cuMemMap 的多次调用,即所谓的虚拟别名。 除非在 PTX ISA 中另有说明,否则写入分配的一个代理被认为与同一内存的任何其他代理不一致和不连贯,直到写入设备操作(网格启动、memcpy、memset 等)完成。 在写入设备操作之前出现在 GPU 上但在写入设备操作完成后读取的网格也被认为具有不一致和不连贯的代理。
例如,下面的代码片段被认为是未定义的,假设设备指针 A 和 B 是相同内存分配的虚拟别名:
__global__ void foo(char *A, char *B) {
*A = 0x1;
printf(“%d\n”, *B); // Undefined behavior! *B can take on either
// the previous value or some value in-between.
}
以下是定义的行为,假设这两个内核是单调排序的(通过流或事件)。
__global__ void foo1(char *A) {
*A = 0x1;
}
__global__ void foo2(char *B) {
printf(“%d\n”, *B); // *B == *A == 0x1 assuming foo2 waits for foo1
// to complete before launching
}
cudaMemcpyAsync(B, input, size, stream1); // Aliases are allowed at
// operation boundaries
foo1<<<1,1,0,stream1>>>(A); // allowing foo1 to access A.
cudaEventRecord(event, stream1);
cudaStreamWaitEvent(stream2, event);
foo2<<<1,1,0,stream2>>>(B);
cudaStreamWaitEvent(stream3, event);
cudaMemcpyAsync(output, B, size, stream3); // Both launches of foo2 and
// cudaMemcpy (which both
// read) wait for foo1 (which writes)
// to complete before proceeding
E.6. Mapping Memory
前两节分配的物理内存和挖出的虚拟地址空间代表了虚拟内存管理 API 引入的内存和地址区别。为了使分配的内存可用,用户必须首先将内存放在地址空间中。从 cuMemAddressReserve 获取的地址范围和从 cuMemCreate 或 cuMemImportFromShareableHandle 获取的物理分配必须通过 cuMemMap 相互关联。
用户可以关联来自多个设备的分配以驻留在连续的虚拟地址范围内,只要他们已经划分出足够的地址空间。为了解耦物理分配和地址范围,用户必须通过 cuMemUnmap 取消映射的地址。用户可以根据需要多次将内存映射和取消映射到同一地址范围,只要他们确保不会尝试在已映射的 VA 范围保留上创建映射。以下代码片段说明了该函数的用法:
CUdeviceptr ptr; // `ptr`: address in the address range previously reserved by cuMemAddressReserve. // `allocHandle`: CUmemGenericAllocationHandle obtained by a previous call to cuMemCreate. CUresult result = cuMemMap(ptr, size, 0, allocHandle, 0);
E.7. Control Access Rights
虚拟内存管理 API 使应用程序能够通过访问控制机制显式保护其 VA 范围。 使用 cuMemMap 将分配映射到地址范围的区域不会使地址可访问,并且如果被 CUDA 内核访问会导致程序崩溃。 用户必须使用 cuMemSetAccess 函数专门选择访问控制,该函数允许或限制特定设备对映射地址范围的访问。 以下代码片段说明了该函数的用法:
void setAccessOnDevice(int device, CUdeviceptr ptr, size_t size) {
CUmemAccessDesc accessDesc = {};
accessDesc.location.type = CU_MEM_LOCATION_TYPE_DEVICE;
accessDesc.location.id = device;
accessDesc.flags = CU_MEM_ACCESS_FLAGS_PROT_READWRITE;
// Make the address accessible
cuMemSetAccess(ptr, size, &accessDesc, 1);
}
使用虚拟内存管理公开的访问控制机制允许用户明确他们希望与系统上的其他对等设备共享哪些分配。 如前所述,cudaEnablePeerAccess 强制将所有先前和将来的 cudaMalloc 分配映射到目标对等设备。 这在许多情况下很方便,因为用户不必担心跟踪每个分配到系统中每个设备的映射状态。 但是对于关心其应用程序性能的用户来说,这种方法具有性能影响。 通过分配粒度的访问控制,虚拟内存管理公开了一种机制,可以以最小的开销进行对等映射。
关于作者
Ken He 是 NVIDIA 企业级开发者社区经理 & 高级讲师,拥有多年的 GPU 和人工智能开发经验。自 2017 年加入 NVIDIA 开发者社区以来,完成过上百场培训,帮助上万个开发者了解人工智能和 GPU 编程开发。在计算机视觉,高性能计算领域完成过多个独立项目。并且,在机器人和无人机领域,有过丰富的研发经验。对于图像识别,目标的检测与跟踪完成过多种解决方案。曾经参与 GPU 版气象模式GRAPES,是其主要研发者。
审核编辑:郭婷
-
gpu
+关注
关注
28文章
5100浏览量
134473 -
API
+关注
关注
2文章
2158浏览量
66247 -
CUDA
+关注
关注
0文章
125浏览量
14405
发布评论请先 登录
FLASH中的代码是如何得到运行的呢
请问e203定义的地址空间是虚拟地址还是物理地址?
Perforce QAC 2025.2版本更新:虚拟内存优化、100%覆盖CERT C规则、CI构建性能提升等

产品分类管理API接口

如何通过API优化电商库存管理,减少缺货风险
TECS OpenStack资源池虚拟机网络二层地址无法互通的问题处理
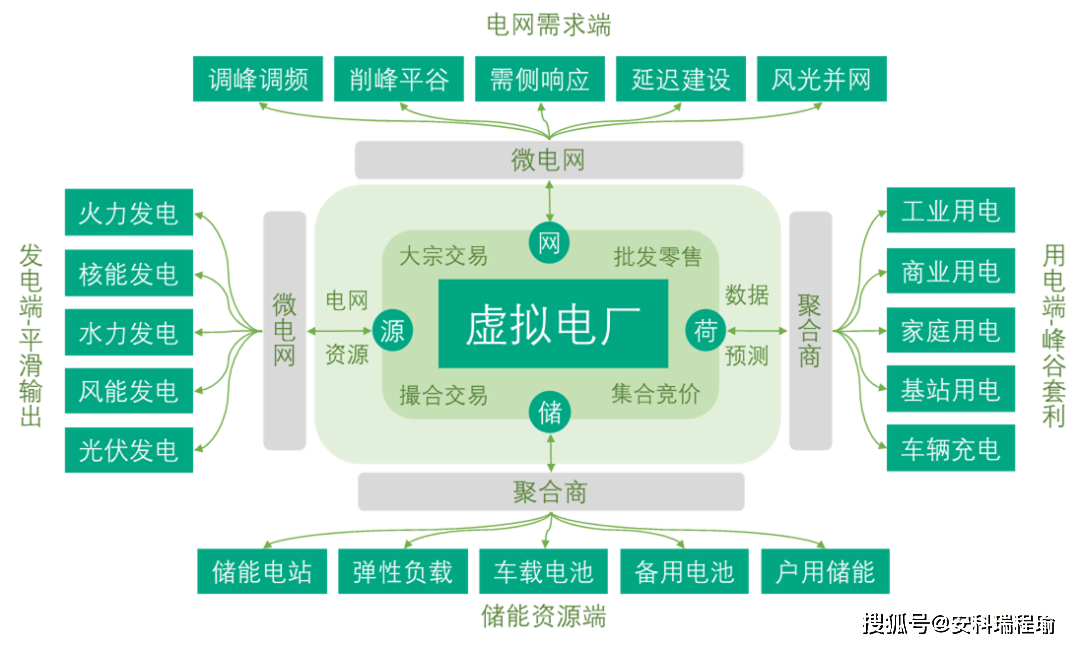
虚拟电厂接入新型电力微电网管理系统
Linux 5.15.52_2.1.0 (Yocto) 是否支持Xen虚拟机管理程序?
hyper 备份,Hyper备份:虚拟机备份与恢复
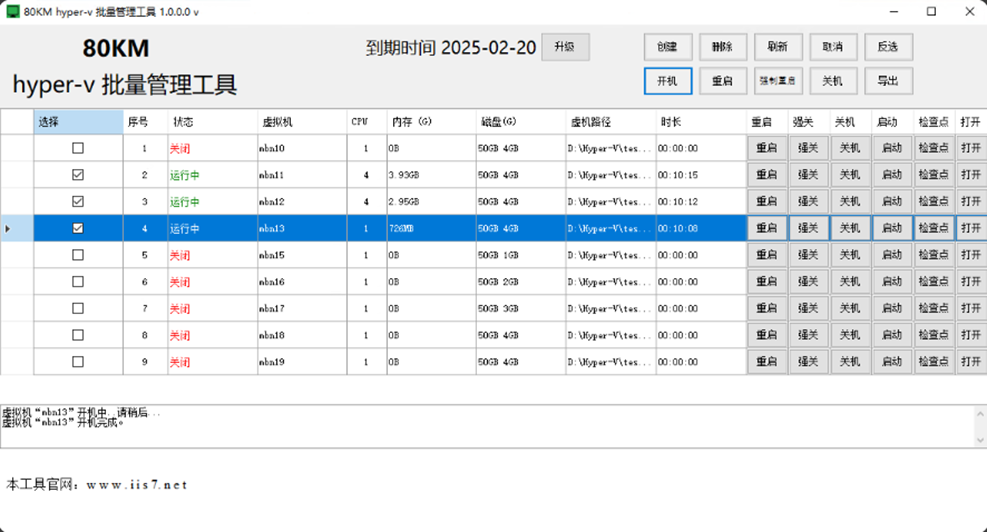
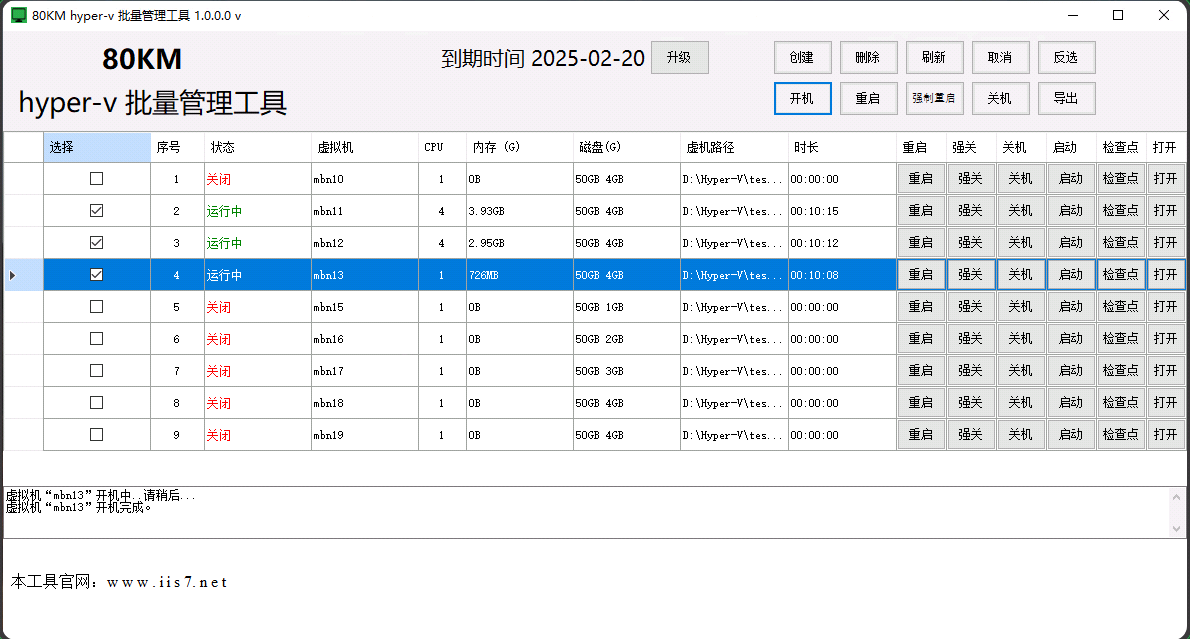
hyper 显卡,hyper 显卡的实操流程,hyper-v批量管理工具的使用指南
hyper v 内存,hyper v 内存设置的操作步骤和方法是什么?

hyper v 虚拟化,hyper-v虚拟化:企业级虚拟化解决方案的全面解析
hyper 内存,Hyper内存:如何监控与优化hyper-v虚拟机的内存使用
了解虚拟电厂的基本概念
虚拟电厂如何接入新型电力微电网管理系统?





 工商网监
工商网监
评论