 如何使用框架训练网络加速深度学习推理
如何使用框架训练网络加速深度学习推理

从 TensorRT 7.0 开始, Universal Framework Format( UFF )被弃用。在本文中,您将学习如何使用新的 TensorFlow -ONNX- TensorRT 工作流部署经过 TensorFlow 培训的深度学习模型。图 1 显示了 TensorRT 的高级工作流。

图 1 。 TensorRT 是一种推理加速器。
首先,使用任何框架训练网络。网络训练后,批量大小和精度是固定的(精度为 FP32 、 FP16 或 INT8 )。训练好的模型被传递给 TensorRT 优化器,优化器输出一个优化的运行时(也称为计划)。。 plan 文件是 TensorRT 引擎的序列化文件格式。计划文件需要反序列化才能使用 TensorRT 运行时运行推断。
要优化在 TensorFlow 中实现的模型,只需将模型转换为 ONNX 格式,并使用 TensorRT 中的 ONNX 解析器解析模型并构建 TensorRT 引擎。图 2 显示了高级 ONNX 工作流。

图 2 。 ONNX 工作流。
在本文中,我们将讨论如何使用 ONNX 工作流创建一个 TensorRT 引擎,以及如何从 TensorRT 引擎运行推理。更具体地说,我们演示了从 Keras 或 TensorFlow 中的模型到 ONNX 的端到端推理,以及使用 ResNet-50 、语义分段和 U-Net 网络的 TensorRT 引擎。最后,我们将解释如何在其他网络上使用此工作流。
下载 TensorFlow -onnx- TensorRT 后 – 代码 tar 。 gz 文件,您还应该从 Cityscapes dataset scripts repo 下载 labels.py ,并将其与其他脚本放在同一个文件夹中。
ONNX 概述
ONNX 是机器学习和深度学习模型的开放格式。它允许您将不同框架(如 TensorFlow 、 PyTorch 、 MATLAB 、 Caffe 和 Keras )的深度学习和机器学习模型转换为单一格式。
它定义了一组通用的运算符、深入学习的通用构建块集和通用文件格式。它提供计算图的定义以及内置运算符。可能有一个或多个输入或输出的 ONNX 节点列表形成一个无环图。
ResNet ONNX 工作流示例
在这个例子中,我们展示了如何在两个不同的网络上使用 ONNX 工作流并创建一个 TensorRT 引擎。第一个网络是 ResNet-50 。
工作流包括以下步骤:
将 TensorFlow / Keras 模型转换为。 pb 文件。
将。 pb 文件转换为 ONNX 格式。
创建 TensorRT 引擎。
从 TensorRT 引擎运行推断。
将模型转换为。 pb
第一步是将模型转换为。 pb 文件。以下代码示例将 ResNet-50 模型转换为。 pb 文件:
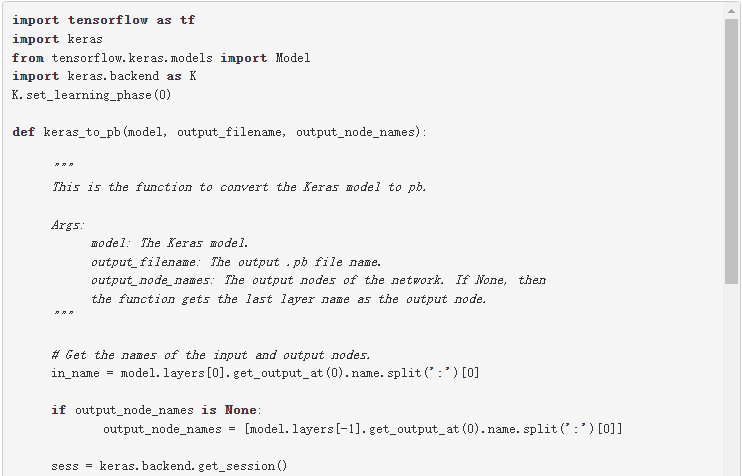

除了 Keras ,您还可以从以下位置下载 ResNet-50 :
深度学习示例 GitHub 存储库:提供最新的深度学习示例网络。您还可以看到 ResNet-50 分支,它包含一个脚本和方法来训练 ResNet-50v1 。 5 模型。
NVIDIA NGC 型号 :它有预训练模型的检查点列表。例如,在 ResNet-50v1 。 5 上搜索 TensorFlow ,并从 Download 页面获取最新的检查点。
将。 pb 文件转换为 ONNX
第二步是将。 pb 模型转换为 ONNX 格式。为此,首先安装 tf2onnx 。
安装 tf2onnx 后,有两种方法可以将模型从。 pb 文件转换为 ONNX 格式。第二种方法是使用命令行。运行以下命令:

从 ONNX 创建 TensorRT 引擎
要从 ONNX 文件创建 TensorRT 引擎,请运行以下命令:
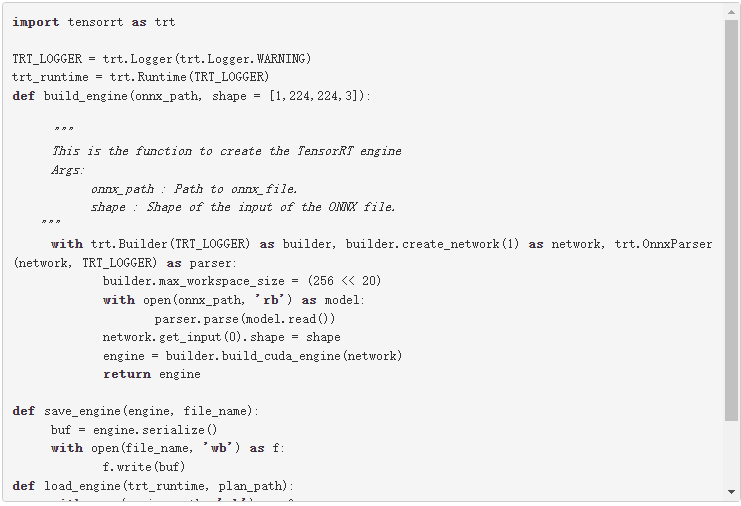

此代码应保存在引擎。 py 文件,稍后在文章中使用。
此代码示例包含以下变量:
最大工作区大小: 在执行时 ICudaEngine 可以使用的最大 GPU 临时内存。
构建器创建一个空网络( builder.create_network() ), ONNX 解析器将 ONNX 文件解析到网络( parser.parse(model.read()) )。您可以为网络( network.get_input(0).shape = shape )设置输入形状,然后生成器将创建引擎( engine = builder.build_cuda_engine(network) )。要创建引擎,请运行以下代码示例:
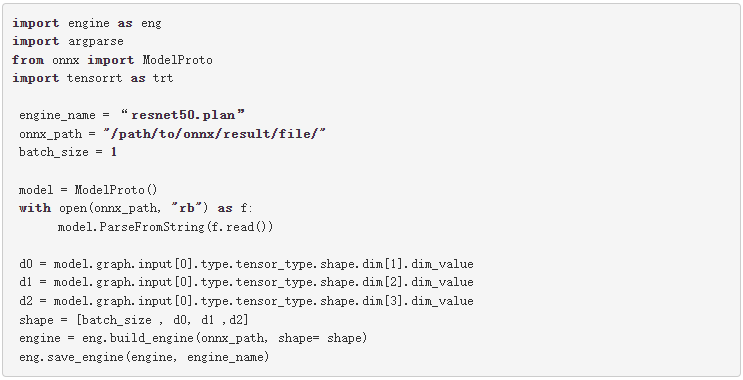
在这个代码示例中,首先从 ONNX 模型获取输入形状。接下来,创建引擎,然后将引擎保存在。 plan 文件中。
运行来自 TensorRT 引擎的推理:
TensorRT 引擎在以下工作流中运行推理:
为 GPU 中的输入和输出分配缓冲区。
将数据从主机复制到 GPU 中分配的输入缓冲区。
在 GPU 中运行推理。
将结果从 GPU 复制到主机。
根据需要重塑结果。
下面的代码示例详细解释了这些步骤。此代码应保存在推理。 py 文件,稍后将在本文中使用。


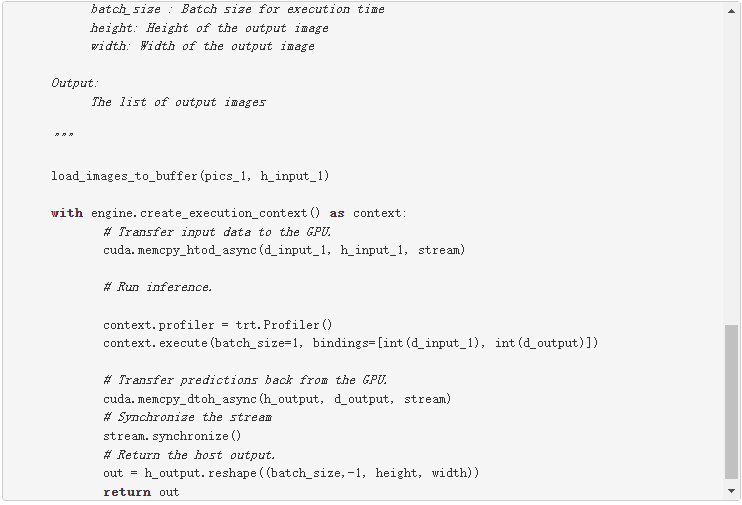
为第一个输入行和输出行确定两个维度。您可以在主机( h_input_1 、 h_output )中创建页锁定内存缓冲区。然后,为输入和输出分配与主机输入和输出相同大小的设备内存( d_input_1 , d_output )。下一步是创建 CUDA 流,用于在设备和主机分配的内存之间复制数据。
在这个代码示例中,在 do_inference 函数中,第一步是使用 load_images_to_buffer 函数将图像加载到主机中的缓冲区。然后将输入数据传输到 GPU ( cuda.memcpy_htod_async(d_input_1, h_input_1, stream) ),并使用 context.execute 运行推理。最后将结果从 GPU 复制到主机( cuda.memcpy_dtoh_async(h_output, d_output, stream) )。
ONNX 工作流语义分割实例
在本文 基于 TensorRT 3 的自主车辆快速 INT8 推理 中,作者介绍了一个语义分割模型的 UFF 工作流过程。
在本文中,您将使用类似的网络来运行 ONNX 工作流来进行语义分段。该网络由一个基于 VGG16 的编码器和三个使用反褶积层实现的上采样层组成。网络在 城市景观数据集 上经过大约 40000 次迭代训练
有多种方法可以将 TensorFlow 模型转换为 ONNX 文件。一种方法是 ResNet50 部分中解释的方法。 Keras 也有自己的 Keras 到 ONNX 文件转换器。有时, TensorFlow -to-ONNX 不支持某些层,但 Keras-to-ONNX 转换器支持这些层。根据 Keras 框架和使用的层类型,您可能需要在转换器之间进行选择。
在下面的代码示例中,使用 Keras-to-ONNX 转换器将 Keras 模型直接转换为 ONNX 。下载预先训练的语义分段文件 semantic_segmentation.hdf5 。

图 3 显示了网络的体系结构。

图 3 。基于 VGG16 的语义分割模型。
与前面的示例一样,使用下面的代码示例创建语义分段引擎。

要测试模型的输出,请使用 城市景观数据集 。要使用城市景观,必须具有以下功能: sub_mean_chw 和 color_map 。这些函数也用于 post , 基于 TensorRT 3 的自主车辆快速 INT8 推理 。
在下面的代码示例中, sub_mean_chw 用于从图像中减去平均值作为预处理步骤, color_map 是从类 ID 到颜色的映射。后者用于可视化。
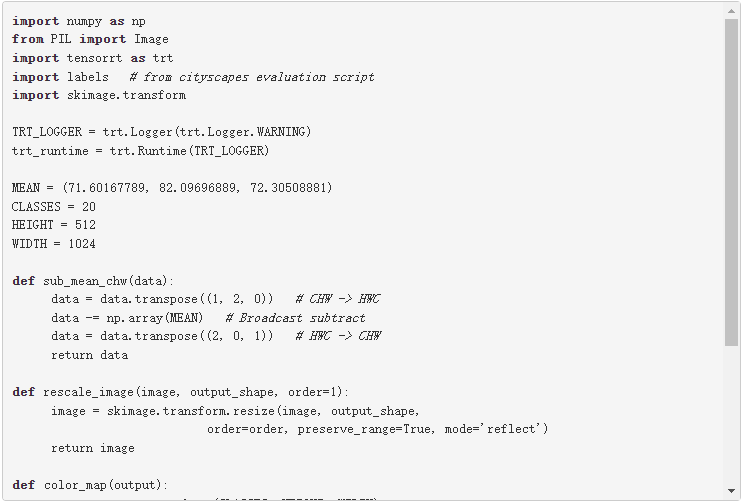

下面的代码示例是上一个示例的其余代码。必须先运行上一个块,因为需要定义的函数。使用这个例子比较 Keras 模型和 TensorRT 引擎 semantic 。 plan 文件的输出,然后可视化这两个输出。根据需要替换占位符 /path/to/semantic_segmentation.hdf5 和 input_file_path 。
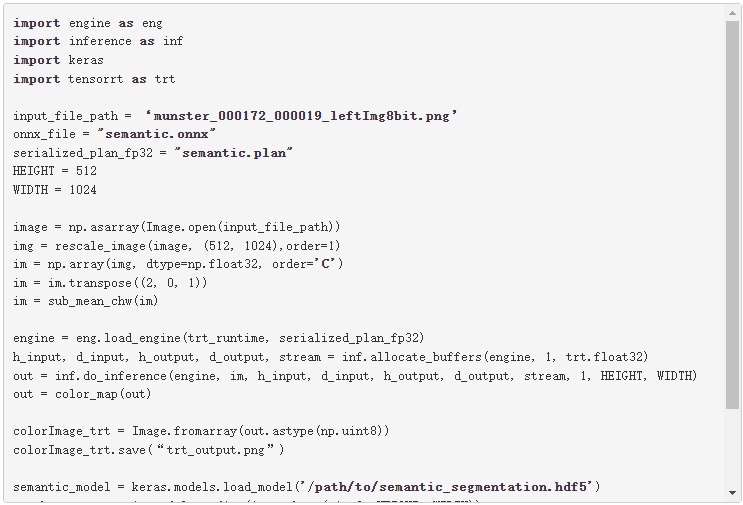

图 4 显示了实际图像和实际情况,以及 Keras 的输出与 TensorRT 引擎的输出的对比。如您所见, TensorRT 发动机的输出与 Keras 的类似。

图 4a 原始图像 。

图 4b 地面真相标签。

图 4c 。 TensorRT 的输出。

图 4d : Keras 的输出。
在其他网络上试试
现在您可以在其他网络上尝试 ONNX 工作流。有关分段网络的好例子的更多信息,请参阅 GitHub 上的 具有预训练主干的分割模型 。
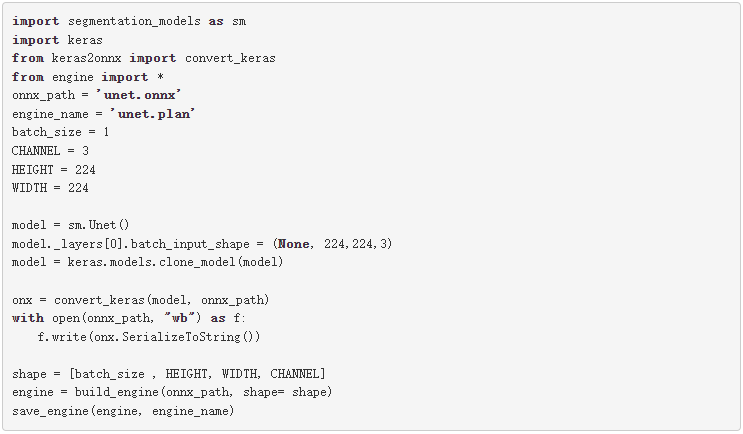
作为一个例子,我们用一个 ONNX 网络来说明如何使用。本例中的网络是来自 segmentation_models 库的 U-Net 。在这里,我们只加载模型,而没有对其进行训练。您可能需要在首选数据集上训练这些模型。
关于这些网络的一个重要点是,当您加载这些网络时,它们的输入层大小如下所示:( None , None , None , 3 )。要创建一个 TensorRT 引擎,您需要一个输入大小已知的 ONNX 文件。在将此模型转换为 ONNX 之前,请通过为其输入指定大小来更改网络,然后将其转换为 ONNX 格式。
例如,从这个库( segmentation _ models )加载 U-Net 网络并为其输入指定大小( 244 、 244 、 3 )。在为推理创建了 TensorRT 引擎之后,做一个与语义分段类似的转换。根据应用程序和数据集的不同,可能需要使用不同的颜色映射。
我们之前提到的另一种下载方式是从 vz6 下载。它有一个预先训练模型的检查点列表。例如,您可以在 TensorFlow 中搜索 UNet ,然后转到 Download 页面以获取最新的检查点。
总结
在这篇文章中,我们解释了如何使用 TensorFlow-to-ONNX-to-TensorRT 工作流来部署深度学习应用程序,并给出了几个示例。第一个例子是 ResNet-50 上的 ONNX- TensorRT ,第二个例子是在 Cityscapes 数据集上训练的基于 英伟达数据中心深度学习产品性能 的语义分割。
关于作者
Houman 是 NVIDIA 的高级深度学习软件工程师。他一直致力于开发和生产 NVIDIA 在自动驾驶车辆中的深度学习解决方案,提高 DNN 的推理速度、精度和功耗,并实施和试验改进 NVIDIA 汽车 DNN 的新思想。他在渥太华大学获得计算机科学博士学位,专注于机器学习
About Yu-Te Cheng
Yu-Te Cheng 是 NVIDIA 自主驾驶组高级深度学习软件工程师,从事自驾领域的各种感知任务的神经结构搜索和 DNN 模型训练、压缩和部署,包括目标检测、分割、路径轨迹生成等。他于 2016 年获得卡内基梅隆大学机器人学硕士学位。
About Josh Park
Josh Park 是 NVIDIA 的汽车解决方案架构师经理。到目前为止,他一直在研究使用 DL 框架的深度学习解决方案,例如在 multi-GPUs /多节点服务器和嵌入式系统上的 TensorFlow 。此外,他一直在评估和改进各种 GPUs + x86 _ 64 / aarch64 的训练和推理性能。他在韩国大学获得理学学士和硕士学位,并在德克萨斯农工大学获得计算机科学博士学位
审核编辑:郭婷
-
代码
+关注
关注
30文章
4941浏览量
73154 -
深度学习
+关注
关注
73文章
5591浏览量
123914
发布评论请先 登录
在Ubuntu20.04系统中训练神经网络模型的一些经验
NVIDIA TensorRT LLM 1.0推理框架正式上线
如何在机器视觉中部署深度学习神经网络

如何在RK3576开发板上运行TinyMaix :超轻量级推理框架--基于米尔MYD-LR3576开发板

信而泰×DeepSeek:AI推理引擎驱动网络智能诊断迈向 “自愈”时代
大模型推理显存和计算量估计方法研究
百度飞桨框架3.0正式版发布

壁仞科技支持DeepSeek-V3满血版训练推理
DeepSeek推出NSA机制,加速长上下文训练与推理
BP神经网络与深度学习的关系
昆仑芯率先完成Deepseek训练推理全版本适配






 工商网监
工商网监
评论