 视频占据过半流量,GPU还是首选的计算硬件吗?
视频占据过半流量,GPU还是首选的计算硬件吗?

根据谷歌统计的数据,由于去年疫情带来的增长加速,再加上视频会议、AR/VR与云游戏等应用的兴起,视频服务已经占据整个互联网60%以上的流量。而这也使得服务器端视频处理能力的要求在不断拔高,处理的对象已经不再是1080p 30帧的短视频了,而是对4K以上的HDR视频进行实时转码。
除了开发更高效的视频编码(VP9、AV1等)和媒体框架之外,硬件平台也是不可或缺的一环,市面上也涌现了不少大相径庭的硬件方案。传统的CPU在新编码上早已显得吃力,而GPU虽然性能优越,但计算流量过大,服务器的成本要高出一截,因此不少云服务厂商也开始推出专用硬件来进行视频处理。
传统GPU
GPU作为最常用的视频处理硬件,也理所当然地成为了数据中心视频转码的选择之一。目前常用于视频转码的最新英伟达GPU为T4。该卡包含320个图灵Tensor核心和2560个CUDA核心,单精度算力达到8.1 TFLOPS。英伟达称在独立的硬件转码引擎下,与前代GPU Tesla M60相比,其转码性能提升至2倍,同时支持38个1080p的视频流。

英伟达T4 / Nvidia
除了英伟达之外,AMD也有可用于视频编码的Radeon Pro V520 GPU,根据全球最大的云服务厂商亚马逊AWS公布的数据,其通用图形渲染性能要高出英伟达T4 40%,单卡最多支持6个1080p60的视频流同时编码。
赛灵思媒体加速卡
除了传统的通用GPU方案外,另一个常见的方案就是采用专门的视频处理加速卡,比如赛灵思于去年发布的数据中心媒体加速卡Alveo U30,专用于高密度的视频转码应用。该卡的APU采用了4核Arm Cortex-A53,RPU采用了双核Arm Cortex-R5F,而GPU采用了Arm Mali-400 MP2。U30支持到8路1080p60视频流的编码,而且在功耗和灵活性上优于CPU+GPU的传统方案。

Alveo U30加速卡 / Xilinx
今年9月,亚马逊AWS开放了新的EC2 VT1实例,该实例至多可以扩展至8张赛灵思Alveo U30加速卡。根据亚马逊AWS公布的数据,基于GPU(英伟达T4 GPU+英特尔Cascade Lake CPU)的G4dn实例相比,在H.264/AVC和H.265/HEVC的实时视频编码上,VT1所需的成本比后者低上60%,与基于CPU(AMD EPYC 7002)的C5实例相比,成本更是低上60%。
除此之外,赛灵思还会提供其视频转码SDK,不仅整合了FFMpeg,更有媒体加速API与U30上的编解码器直连,今年年末还会推出对于另一框架GStreamer的支持。
亚马逊不仅推出了基于这类加速卡的云服务,旗下的直播平台Twitch也在使用这类实例。Twitch称计划将VT1实例用于数百万计的直播转码,以此实现在更密集的串流和低延迟下,不牺牲视频的压缩或画质。
谷歌定制VPU
作为仅次于亚马逊AWS和微软Azure的云服务厂商,谷歌在其公共云服务上依然在使用传统的GPU方案。但坐拥全球最大的视频平台Youtube和成立不久的云游戏平台Stadia,谷歌决定在这些服务上采用自己的硬件来加速视频处理。

搭载了两个VCU芯片的PCBA / Google
作为视频编码标准VP9的开发者,谷歌想要同时实现H.264和VP9支持,以及多输出的转码,并在直播与离线转码中达到理想的速度与质量,还能全面控制软件算法进行调整,因此谷歌决定开发自己的硬件VCU芯片。
谷歌基于该硬件打造的系统具有两张VCU加速器,每个加速器内置了10个VCU编码器核心,每个核心都能够实时编码2160p的视频流,使用三个参考帧时可达60FPS。经过在H.264二次编码上的输出对比,8块VCU芯片的性能是4块英伟达T4性能的两倍以上,是英特尔Skylake CPU的8倍以上,在VP9编码上的性能差距更是可以拉到20倍。
结语
在视频处理方面,尤其是视频编码转码上,CPU+GPU的通用传统方案已经在失去其优势,专用的加速器方案明显在成本和性能突破上走的更快一些。这种趋势在数据中心的其他应用领域上也在慢慢显现,比如深度学习、AI等,专用加速器的方案更适合针对性更强的场景。随着云服务厂商不断推出更多的专用实例,GPU在视频处理上的地位很可能会被专用加速器给替代。
除了开发更高效的视频编码(VP9、AV1等)和媒体框架之外,硬件平台也是不可或缺的一环,市面上也涌现了不少大相径庭的硬件方案。传统的CPU在新编码上早已显得吃力,而GPU虽然性能优越,但计算流量过大,服务器的成本要高出一截,因此不少云服务厂商也开始推出专用硬件来进行视频处理。
传统GPU
GPU作为最常用的视频处理硬件,也理所当然地成为了数据中心视频转码的选择之一。目前常用于视频转码的最新英伟达GPU为T4。该卡包含320个图灵Tensor核心和2560个CUDA核心,单精度算力达到8.1 TFLOPS。英伟达称在独立的硬件转码引擎下,与前代GPU Tesla M60相比,其转码性能提升至2倍,同时支持38个1080p的视频流。
英伟达T4 / Nvidia
除了英伟达之外,AMD也有可用于视频编码的Radeon Pro V520 GPU,根据全球最大的云服务厂商亚马逊AWS公布的数据,其通用图形渲染性能要高出英伟达T4 40%,单卡最多支持6个1080p60的视频流同时编码。
赛灵思媒体加速卡
除了传统的通用GPU方案外,另一个常见的方案就是采用专门的视频处理加速卡,比如赛灵思于去年发布的数据中心媒体加速卡Alveo U30,专用于高密度的视频转码应用。该卡的APU采用了4核Arm Cortex-A53,RPU采用了双核Arm Cortex-R5F,而GPU采用了Arm Mali-400 MP2。U30支持到8路1080p60视频流的编码,而且在功耗和灵活性上优于CPU+GPU的传统方案。
Alveo U30加速卡 / Xilinx
今年9月,亚马逊AWS开放了新的EC2 VT1实例,该实例至多可以扩展至8张赛灵思Alveo U30加速卡。根据亚马逊AWS公布的数据,基于GPU(英伟达T4 GPU+英特尔Cascade Lake CPU)的G4dn实例相比,在H.264/AVC和H.265/HEVC的实时视频编码上,VT1所需的成本比后者低上60%,与基于CPU(AMD EPYC 7002)的C5实例相比,成本更是低上60%。
除此之外,赛灵思还会提供其视频转码SDK,不仅整合了FFMpeg,更有媒体加速API与U30上的编解码器直连,今年年末还会推出对于另一框架GStreamer的支持。
亚马逊不仅推出了基于这类加速卡的云服务,旗下的直播平台Twitch也在使用这类实例。Twitch称计划将VT1实例用于数百万计的直播转码,以此实现在更密集的串流和低延迟下,不牺牲视频的压缩或画质。
谷歌定制VPU
作为仅次于亚马逊AWS和微软Azure的云服务厂商,谷歌在其公共云服务上依然在使用传统的GPU方案。但坐拥全球最大的视频平台Youtube和成立不久的云游戏平台Stadia,谷歌决定在这些服务上采用自己的硬件来加速视频处理。
搭载了两个VCU芯片的PCBA / Google
作为视频编码标准VP9的开发者,谷歌想要同时实现H.264和VP9支持,以及多输出的转码,并在直播与离线转码中达到理想的速度与质量,还能全面控制软件算法进行调整,因此谷歌决定开发自己的硬件VCU芯片。
谷歌基于该硬件打造的系统具有两张VCU加速器,每个加速器内置了10个VCU编码器核心,每个核心都能够实时编码2160p的视频流,使用三个参考帧时可达60FPS。经过在H.264二次编码上的输出对比,8块VCU芯片的性能是4块英伟达T4性能的两倍以上,是英特尔Skylake CPU的8倍以上,在VP9编码上的性能差距更是可以拉到20倍。
结语
在视频处理方面,尤其是视频编码转码上,CPU+GPU的通用传统方案已经在失去其优势,专用的加速器方案明显在成本和性能突破上走的更快一些。这种趋势在数据中心的其他应用领域上也在慢慢显现,比如深度学习、AI等,专用加速器的方案更适合针对性更强的场景。随着云服务厂商不断推出更多的专用实例,GPU在视频处理上的地位很可能会被专用加速器给替代。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
gpu
+关注
关注
28文章
5099浏览量
134461 -
数据中心
+关注
关注
16文章
5515浏览量
74649
发布评论请先 登录
相关推荐
热点推荐
AI芯片市场鏖战,GPU与ASIC谁将占据主动?
本文转自:TechSugar随着人工智能技术在大模型训练、边缘计算、自动驾驶等领域的深度渗透,核心算力硬件的竞争进入白热化阶段。图形处理单元(GPU)与专用集成电路(ASIC)作为两大主流技术路线

请问InConnect 维护设备的流量大概是多少?
:需要根据实际视频流量计算
4、工业路由器产品每月的云平台连接流量+维护隧道建立流量约30MB-40MB,一年约360MB-480MB,单台设备每月InConnct链接心跳
发表于 08-06 08:17
aicube的n卡gpu索引该如何添加?
请问有人知道aicube怎样才能读取n卡的gpu索引呢,我已经安装了cuda和cudnn,在全局的py里添加了torch,能够调用gpu,当还是只能看到默认的gpu0,显示不了
发表于 07-25 08:18
AI芯片:加速人工智能计算的专用硬件引擎
处理等应用落地的关键硬件基础。 AI芯片的核心技术特点 AI芯片的设计重点在于提升计算效率,主要技术特点包括: 1. 并行计算架构 :AI任务(如矩阵乘法、卷积运算)需要高并行性,
如何计算孔板流量计和平衡流量计的流量?计算公式一样吗?
平衡流量计与孔板流量计作为差压式流量计的典型代表,虽均基于压力差与流量的数学关系进行计算,但是平衡流量
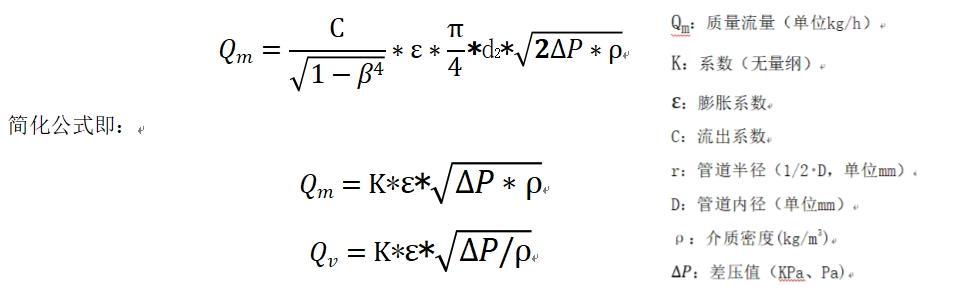
异构计算解决方案(兼容不同硬件架构)
异构计算解决方案通过整合不同类型处理器(如CPU、GPU、NPU、FPGA等),实现硬件资源的高效协同与兼容,满足多样化计算需求。其核心技术与实践方案如下: 一、
GPU架构深度解析
GPU架构深度解析从图形处理到通用计算的进化之路图形处理单元(GPU),作为现代计算机中不可或缺的一部分,已经从最初的图形渲染专用处理器,发展成为强大的并行
学硬件好还是学软件好?
学硬件好还是学软件好? 选择学习硬件还是软件取决于个人兴趣、职业目标以及对不同工作方式的偏好。以下是两者的一些比较,帮助你做出更合适的选择。 学习硬
发表于 04-07 15:27
GPU加速计算平台的优势
传统的CPU虽然在日常计算任务中表现出色,但在面对大规模并行计算需求时,其性能往往捉襟见肘。而GPU加速计算平台凭借其独特的优势,吸引了行业内人士的广泛关注和应用。下面,AI部落小编为
云 GPU 加速计算:突破传统算力瓶颈的利刃
在数字化时代,数据呈爆炸式增长,传统的算力已难以满足复杂计算任务的需求。无论是人工智能的深度学习、大数据的分析处理,还是科学研究中的模拟计算,都对算力提出了极高的要求。而云 GPU 加
GPU云计算服务怎么样
在当今数字化快速发展的时代,高性能计算需求日益增长。为满足这些需求,GPU云计算服务应运而生。那么,GPU云计算服务怎么样呢?接下来,AI部
GPU加速云服务器怎么用的
GPU加速云服务器是将GPU硬件与云计算服务相结合,通过云服务提供商的平台,用户可以根据需求灵活租用带有GPU资源的虚拟机实例。那么,
Triton编译器与GPU编程的结合应用
Triton编译器简介 Triton编译器是一种针对并行计算优化的编译器,它能够自动将高级语言代码转换为针对特定硬件优化的低级代码。Triton编译器的核心优势在于其能够识别并行模式,自动进行代码
《CST Studio Suite 2024 GPU加速计算指南》
的各个方面,包括硬件支持、操作系统支持、许可证、GPU计算的启用、NVIDIA和AMD GPU的详细信息以及相关的使用指南和故障排除等内容。
1.
发表于 12-16 14:25





 工商网监
工商网监
评论