 将浅层神经网络作为“弱学习者”的梯度Boosting框架
将浅层神经网络作为“弱学习者”的梯度Boosting框架

1. 简介
本文提出了一种新的梯度Boosting框架,将浅层神经网络作为“弱学习者”。在此框架下,我们考虑一般的损失函数,并给出了分类、回归和排序的具体实例。针对经典梯度boosting决策树贪婪函数逼近的缺陷,提出了一种完全修正的方法。在多个数据集的所有三个任务中,该模型都比最新的boosting方法都得了来更好的结果。
2. 背景
尽管在理论上和实践中都有着无限的可能性,但由于其固有的复杂性,为新应用领域开发定制的深度神经网络仍然是出了名的困难。为任何给定的应用程序设计架构都需要极大的灵活性,往往需要大量的运气。
在本文中,我们将梯度增强的能力与神经网络的灵活性和多功能性相结合,引入了一种新的建模范式GrowNet,它逐层建立DNN。代替决策树,我们使用浅层神经网络作为我们的弱学习者,在一个通用的梯度增强框架中,可以应用于跨越分类、回归和排名的各种任务。
我们做了进一步创新,比如在训练过程中加入二阶统计数据,同时还引入了一个全局校正步骤,该步骤已在理论和实际评估中得到证明,对提高效果并对特定任务进行精确微调。
我们开发了一种现成的优化算法,比传统的深度神经网络更快、更容易训练。
我们引入了新的优化算法,相较于传统的NN,它更快也更加易于训练;此外我们还引入了二阶统计和全局校正步骤,以提高稳定性,并允许针对特定任务对模型进行更细粒度的调整。
我们通过实验评估证明了我们的技术的有效性,并在三种不同的ML任务(分类、回归和学习排名)中的多个真实数据集上显示了优异的结果。
3. 相关工作
3.1 Gradient Boosting Algorithms
Gradient Boosting算法是一种使用数值优化的函数估计方法,决策树是梯度提升框架中最常用的函数(predictive learner)。梯度提升决策树(GBDT),其中决策树按顺序训练,每棵树通过拟合负梯度来建模。本文中,我们将XGBoost作为基线。和传统的GBDT不一样,本文提出了Gradient Boosting Neural Network,使用千层的NN来训练gradient boosting。
我们认为神经网络给我们一种优于GBDT模型的策略。除了能够将信息从先前的预测器传播到下一个预测器之外,我们可以在加入新的层时纠正之前模型(correct step)。
3.2 Boosted Neural Nets
尽管像决策树这样的弱学习者在boosting和集成方法中很受欢迎,但是将神经网络与boosting/集成方法相结合以获得比单个大型/深层神经网络更好的性能已经做了大量的工作。在之前开创性工作中,全连接的MLP以一层一层的方式进行训练,并添加到级联结构的神经网络中。他们的模型并不完全是一个boosting模型,因为最终的模型是一个单一的多层神经网络。
在早期的神经网络设计中,集成的策略可以带来巨大的提升,但是早期都是多数投票,简单的求均值或者加权的均值这些策略。在引入自适应的boosting算法之后(Adaboost),就有一些工作开始将MLP和boosting相结合并且取得了很棒的效果。
在最新的一些研究中,AdaNet提出自适应地构建神经网络层,除了学习网络的权重,AdaNet调整网络的结构以及它的增长过程也有理论上的证明。AdaNet的学习过程是boosting式的,但是最终的模型是一个单一的神经网络,其最终输出层连接到所有的底层。与AdaNet不同的是,我们以梯度推进的方式训练每一个弱学习者,从而减少了entangled的训练。最后的预测是所有弱学习者输出的加权和。我们的方法还提供了一个统一的平台来执行各种ML任务。
最近有很多工作来解释具有数百层的深度残差神经网络的成功,表明它们可以分解为许多子网络的集合。
4. 模型
在每一个boosting步骤中,我们使用当前迭代倒数第二层的输出来增强原始输入特性。
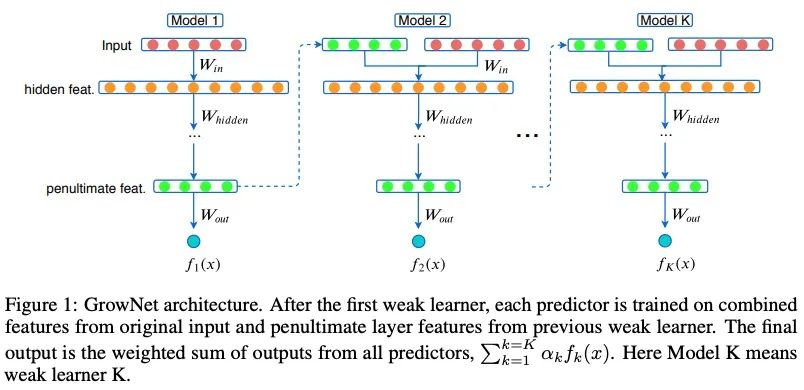
通过使用当前残差的增强机制,将增强后的特征集作为输入来训练下一个弱学习者。模型的最终输出是所有这些顺序训练模型的得分的加权组合。
4.1 Gradient Boosting Neural Network: GrowNet
我们假设有一个数据集,里面有个维度的特征空间,,GrowNet使用个加法函数来预测最终的输出:
其中是多层感知机的空间,是步长,每个函数表示一个独立的,浅层的网络,对于一个给定的样本,模型在GrowNet中计算的加权和。
我们令是一个可微的凸损失函数,我们的目标是学习一个函数集合(浅层的网络),我们的目标就是学习一个函数的集合来最小化下面的等式:
和GBDT很像,此处我们采用加法的形式对其进行训练,我们令:
为GrowNet关于样本在第步输出,我们贪心地搜索下一个弱学习器,,即:
此外,采用了损失函数的泰勒展开,来降低计算复杂度。由于二阶优化技术优于一阶优化技术,收敛步骤少,因此,我们用Newton-Raphson步长对模型进行了训练。因此,无论ML任务如何,通过对GrowtNet输出的二阶梯度进行回归,优化各个模型参数。关于弱学习器的目标函数可以简化为:
其中,和分别是目标函数在处的一阶和二阶梯度。
4.2 Corrective Step (C/S)
传统的boosting框架,每个弱学习器都是贪心学习的,这意味着只有第个弱学习器是不变的。
短视学习过程可能会导致模型陷入局部极小,固定的增长率会加剧这个问题。因此,我们实施了一个纠正步骤来解决这个问题。
在纠正步骤中,我们允许通过反向传播更新先前t-1弱学习者的参数,而不是修复先前t-1弱学习者。
此外,我们将boosting rate 纳入模型参数,并通过修正步骤自动更新。
除了获得更好的性能之外,这一举措可以让我们避免调整一个微妙的参数。
C/S还可以被解释为一个正则化器,以减轻弱学习器之间的相关性,因为在纠正步骤中,我们主要的训练目标变成了仅对原始输入的特定任务损失函数。这一步的有用性在论文《Learning nonlinear functions using regularized greedy forest》中对梯度提升决策树模型进行了实证和理论研究。
5. 模型应用
5.1 回归的GrowNet
此处我们以MSE为案例。
我们对数据集 通过最小平方回归训练下一个弱分类器,在Corrective Step,在GrowNet中对所有模型参数都可以使用MSE损失进行优化。
5.2 分类的GrowNet
为了便于说明,让我们考虑二元交叉熵损失函数;注意,可以使用任何可微损失函数。我们选择标签,这样我们的一阶和二阶的梯度和就是:
下一个弱学习器使用二阶梯度统计通过使用最小平方回归进行拟合。在 corrective step,所有叠加的预测函数的参数通过使用二元交叉熵损失函数在整个模型重新训练。这一步根据手上任务的主要目标函数,即在这种情况下的分类,稍微修正权重。
5.3 LTR的GrowNet
假设对于某个给定的query,一对文件和被选择。假设我们对于每个文档和有一个特征向量,我们令和表示对于样本和的模型输出,一个传统的pairwise loss可以被表示为下面的形式:
其中表示文件相关性的差值。是sigmoid函数。因为损失函数是堆成的,它的梯度可以通过下面的方式计算得到:
我们用表示下标对的集合,其中对于某个query,我们希望排名不同于,对于某个特定的文件,损失函数以及它的一阶以及二阶统计函数可以通过下面的形式获得。
6. 实验
6.1 实验效果
模型中加入的预测函数都是具有两个隐层的多层感知器。我们将隐藏层单元的数量设置为大约输入特征维数的一半或相等。当模型开始过拟合时,更多的隐藏层会降低效果。我们实验中采用了40个加法函数对三个任务进行测试,并根据验证结果选择了测试时间内的弱学习器个数。Boosting rate最初设置为1,并在校正步骤中自动调整。我们只训练了每个预测函数一个epoch,整个模型在校正过程中使用Adam optimizer也训练了一个epoch。epoch的个数在ranking任务中被设置为2;
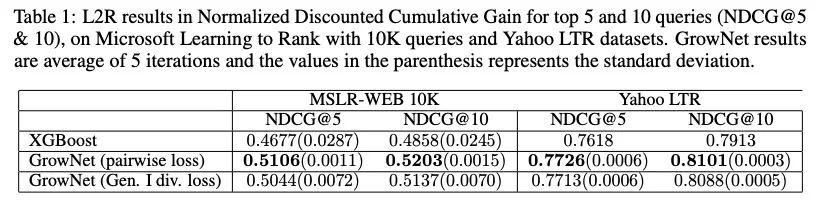
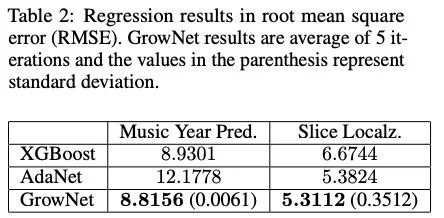
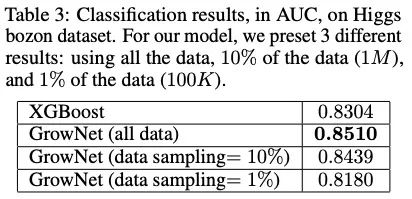
该方法在诸多方案上都取得了好于XGBoost的效果。
6.2 消融实验
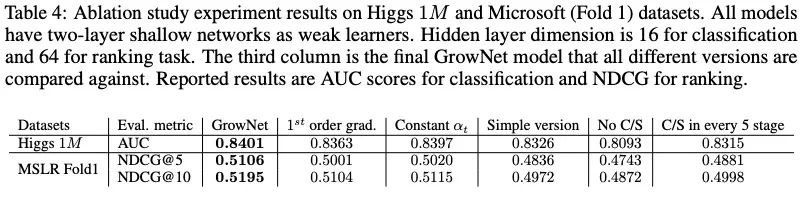
C/S的影响非常大;C/S模式缓解了learner之间潜在的相关性;
二阶导数是有必要的;
自动化学习是有价值的;我们加了boosting rate ,它是自动调整的,不需要任何调整;
6.3 隐藏单元的影响
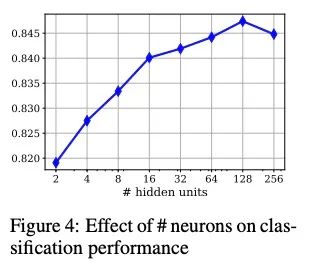
改变隐藏单元的数量对效果的影响较小。
测试了具有不同隐藏单元的最终模型(具有两个隐藏层的弱学习者)。Higgs数据有28个特征,我们用2、4、8、16、32、64、128和256个隐藏单元对模型进行了测试。隐层维度越小,弱学习者获得的信息传播越少。另一方面,拥有大量的单元也会导致在某个点之后过度拟合。
上图显示了这个实验在Higgs 1M数据上的测试AUC分数。最高的AUC为0.8478,只有128个单元,但当数量增加到256个单元时,效果会受到影响。
6.4 GrowNet versus DNN
如果我们把所有这些浅层网络合并成一个深神经网络,会发生什么?
这种方法存在几个问题:
对DNN参数进行优化非常耗时,如隐藏层数、每个隐藏层单元数、总体架构、Batch normalization、dropout等;
DNN需要巨大的计算能力,总体运行速度较慢。我们将我们的模型(30个弱学习器)与DNN进行了5、10、20和30个隐藏层配置的比较。
在1000个epoch,在Higgs的1M数据上,最好的DNN(10个隐藏层)得到0.8342,每个epoch花费11秒。DNN在900个epoch时取得了这一成绩(最好)。GrowtNet在相同的配置下取得了0.8401 AUC;
7. 小结
本文提出了GrowNet,它可以利用浅层神经网络作为梯度推进框架中的“弱学习者”。这种灵活的网络结构使我们能够在统一的框架下执行多个机器学习任务,同时结合二阶统计、校正步骤和动态提升率,弥补传统梯度提升决策树的缺陷。
我们通过消融研究,探讨了神经网络作为弱学习者在boosting范式中的局限性,分析了每个生长网络成分对模型性能和收敛性的影响。结果表明,与现有的boosting方法相比,该模型在回归、分类和学习多数据集排序方面具有更好的性能。我们进一步证明,GrowNet在这些任务中是DNNs更好的替代品,因为它产生更好的性能,需要更少的训练时间,并且更容易调整。
原文标题:【前沿】Purdue&UCLA提出梯度Boosting网络,效果远好于XGBoost模型!
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
神经网络
+关注
关注
42文章
4845浏览量
108373 -
框架
+关注
关注
0文章
404浏览量
18524
原文标题:【前沿】Purdue&UCLA提出梯度Boosting网络,效果远好于XGBoost模型!
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
自动驾驶中常提的卷积神经网络是个啥?

CNN卷积神经网络设计原理及在MCU200T上仿真测试
NMSIS神经网络库使用介绍
构建CNN网络模型并优化的一般化建议
在Ubuntu20.04系统中训练神经网络模型的一些经验
CICC2033神经网络部署相关操作
人工智能工程师高频面试题汇总:循环神经网络篇(题目+答案)
液态神经网络(LNN):时间连续性与动态适应性的神经网络

神经网络的并行计算与加速技术
如何在机器视觉中部署深度学习神经网络

无刷电机小波神经网络转子位置检测方法的研究
神经网络专家系统在电机故障诊断中的应用
神经网络RAS在异步电机转速估计中的仿真研究
基于FPGA搭建神经网络的步骤解析




评论