 如何实现跨平台部署嵌入式智能应用的部署?
如何实现跨平台部署嵌入式智能应用的部署?

这几年我们在日常工作生活中看到越来越多的智能终端设备的出现,如智能家电、商城客服机器人、物流配送无人小车、智能监控等等,它们可以为我们生活带来各种各样的便利。因此,边缘智能与 AIoT 已成为不少国内外企业发展的一个重要方向。边缘智能是一项以嵌入式设备应用开发为基础的前沿技术,我们需要在一些资源紧张的嵌入式设备,如 MCU、SOC,部署如人脸识别、物体检测、音频分类等智能应用。
然而,我们又看到现实的嵌入式智能应用开发面正临着一些软硬件生态兼容方面的挑战。例如,芯片厂商提供推荐的板载系统往往是定制的,使用不同的编译工具,而且大多不会有 Python 解释器。所以,当我们打算将自己的智能应用部署到嵌入式设备时,我们绕不开 AI 推理框架跨平台的问题。
TensorFlow Lite 应用 C++ 作为框架底层的基础实现可以天然保证跨平台扩展特性,但由于它的这项技术的比较前沿,在嵌入式 Linux 设备上以 Python 接口为主,有些开发者不太适应,认为不易上手。为此,我们开发 Edge Brain 方便开发者以其熟悉的交叉编译方式部署 TensorFlow Lite 智能应用,让他们的嵌入式应用走向智能化。
交叉编译
交叉编译是指,一种在某个系统平台下可以产生另一个系统平台的可执行文件的编译方式。这种方式的优点是,当程序在目标运行系统平台进行编译比较困难时,它通过解耦编译和运行两个过程来实现更高效的程序调试。比如,在资源紧张的 Linux ARM 嵌入式系统平台调试应用程序,其编译过程往往有着很高的 CPU 占用率,更不用说我们其实希望程序的编译与运行调试工作能并行开展。因此,交叉编译在嵌入式智能开发有着重要的应用场景。
后面的篇幅,我们将参考官方文档以跨平台交叉编译树莓派的 TensorFlow Lite C++ 应用为例,介绍如何实现跨平台部署嵌入式智能应用的部署。因为,树莓派是 Linux ARM 嵌入式系统平台的其中一种,所以我们希望本文能够起到抛砖引玉的效果,读者未来遇到类似的问题时,能举一反三完成业务平台的部署,甚至分享心得与我们一起为开源社区做贡献。
准备 Docker 编译环境
本文选用的交叉编译工具为 Google 开源推出的 Bazel。其由于具有易用性的特点,已经在大量开源 AI 项目中得到应用。在本章节,我们将手把手的带领您一步一步搭建编译环境。首先,我们不希望开发者由于环境安装的兼容性问题,遇到系统软件版本冲突的状况。所以,我们建议大家将程序的编译环境配置在 docker 中。这样不仅可以保证本地环境的安全,还能方便后续环境迁移。
本文选用 ubuntu04 作为我们的基础镜像,并在其中采用 Bazel 官网中 Binary Installer 的安装方式。具体步骤如下:
1. 创建 Dockerfile 内容如下
From ubuntu:18.04
RUN apt update -y
&& apt install -y curl gnupg git vim python python3 python3-distutils python3-pip g++ unzip zip openjdk-11-jdk wget cmake make -y
&& pip3 install numpy
&& wget https://github.com/bazelbuild/bazelisk/releases/download/v1.7.5/bazelisk-linux-amd64
&& chmod +x bazelisk-linux-amd64
&& mv bazelisk-linux-amd64 /usr/bin/bazel
&& echo ‘export PATH=$PATH:$HOME/bin’ 》》 ~/.bashrc
&& apt-get purge -y --auto-remove
2. 在 Dockerfile 所在目录中执行下面的命令生成我们需要的 Docker 镜像实现编译环境的配置。
~$ docker build -t bazel-build-env:v0.01 。
Bazel TensorFlow Lite
Bazel 可以轻松完成交叉编译,互联网有许多教程介绍 toolchain 的配置原理,我们不再赘述。这里我们主要介绍交叉编译 TensorFlow Lite 的实战步骤。因为我们希望最终程序在树莓派上使用,所以我们直接使用 TensorFlow 的 toolchain 配置即可。具体步骤如下:
1. 导入 TensorFlow 库
TensorFlow 的 toolchain 以及 TFLite 相关的源码均存在 github 的仓库之中,于是我们需要使用 Bazel 将其自动下载下来,并继承其配置文件。Bazel 提供了非常简单的实现方式,即在项目根目录下配置 WORKSPACE 文件中追加如下内容即可:
load(“@bazel_tools//tools/build_defs/repo:http.bzl”, “http_archive”)
load(“@bazel_tools//tools/build_defs/repo:git.bzl”, “git_repository”, “new_git_repository”)
# Needed by TensorFlow
http_archive(
name = “io_bazel_rules_closure”,
sha256 = “e0a111000aeed2051f29fcc7a3f83be3ad8c6c93c186e64beb1ad313f0c7f9f9”,
strip_prefix = “rules_closure-cf1e44edb908e9616030cc83d085989b8e6cd6df”,
urls = [
“http://mirror.tensorflow.org/github.com/bazelbuild/rules_closure/archive/cf1e44edb908e9616030cc83d085989b8e6cd6df.tar.gz”,
“https://github.com/bazelbuild/rules_closure/archive/cf1e44edb908e9616030cc83d085989b8e6cd6df.tar.gz”, # 2019-04-04
],
)
git_repository(
name = “org_tensorflow”,
remote = “https://github.com.cnpmjs.org/tensorflow/tensorflow.git”,
tag = “v2.4.0”
)
load(“@org_tensorflow//tensorflow:workspace.bzl”, “tf_workspace”)
tf_workspace(tf_repo_name = “org_tensorflow”)
可以看到上述内容中,我们不仅仅制定了 TensorFlow 仓库,而且 Bazel 还允许我们通过 tag 来选择特定版本的内容。除此之外,在配置好 TensorFlow 仓库之后,还能使用 @org_tensorflow 来进行额外的配置,如继承仓库中的 WORKSPACE 配置。
2. 修改 .bazelrc 文件
我们参考 TensorFlow 库中的配置, 修改项目路径中的 edge-brain/.bazelrc 如下:
# TF settings
build:elinux --crosstool_top=@local_config_embedded_arm//:toolchain
build:elinux --host_crosstool_top=@bazel_tools//tools/cpp:toolchain
build:elinux_armhf --config=elinux
build:elinux_armhf --cpu=armhf
经过第一步的配置,我们已经使得 Bazel 不仅知道从何处下载什么版本的 TensorFlow 源码,还加载了 TF 仓库中已有的相关配置。这样当我们使用 --config elinux_armhf 时,bazel 将知道应使用 TF 库中 @local_config_embedded_arm//:toolchain 来编译代码,至此便轻松的完成了交叉编译的环境配置工作,接下来让我们来测试下编译环境。
3.验证 TFLite 的 Bazel 配置
我们的 Edge Brain 仓库已经为你提前完成上述的相关环境配置。现在,我们可以执行下面的指令尝试编译 TFLite 提供的 minial.cc 程序验证编译环境。
edge-brain$ bazel build --config elinux_armhf //examples/hello_world:hello_world --experimental_repo_remote_exec
Bazel OpenCV
OpenCV 是一个轻量高效的计算机视觉和机器学习软件库,可以跨平台运行在 Linux、Windows、Android 和 MacOS 的操作系统上,而且集成许多图像处理和计算机视觉方面的通用优秀算法。再之,计算机视觉作为最先引入卷积神经网络的前沿领域,它的智能算法相对成熟并且已被广泛应用于各种生活场景,如安防常用的人脸识别与目标跟踪等都属于这一领域。
但是,如前文所述,我们现有的嵌入式系统平台的种类繁多而且硬件资源特别有限。所以, OpenCV 团队难以支持各式各样系统平台的库文件预编译(binary prebuilt),而我们也不愿意忍受嵌入式系统上编译 OpenCV 库的漫长过程。因此,我们基于 Bazel 工具搭建 OpenCV 智能应用的交叉编译环境,希望它帮助一些计算机视觉领域同学快速构建他们自己的嵌入式视觉应用。
下面我们将简单介绍 Bazel 搭建 OpenCV 编译环境的解决思路。我们了解到 OpenCV 主要构建工具是 CMake,所以它的所有编译配置都写在 CMakeList.txt 文件中。CMake 是现在开源项目的主流编译工具,过去如 Caffe、Tesseract 以及 Boost 等开源项目都是用 CMake 编译的。因此,Bazel 为了兼容 CMake 的编译规则扩展提供一个名为 cmak_external 函数接口,实现对第三方库编译参数的控制。
cmak_external 函数接口有两个控制编译参数的关键变量:cache_entries 与 make_commands。Bazel 会根据这两个变量的参数自动编写一个适合的 CMake 运行脚本并执行得到理想的编译结果。简单来说,我们可以认为 cmak_external 就是让 Bazel 通过 Shell 脚本控制本地终端完成 CMake 的编译过程。下面我们展示 edge-brain/third_party/BUILD 如何配置 OpenCV 的静态库编译。
load(“@rules_foreign_cc//tools/build_defs:cmake.bzl”, “cmake_external”)
load(“//third_party:opencv_configs.bzl”,
“OPENCV_SO_VERSION”,
“OPENCV_MODULES”,
“OPENCV_THIRD_PARTY_DEPS”,
“OPENCV_SHARED_LIBS”)
exports_files([“LICENSE”])
package(default_visibility = [“//visibility:public”])
alias(
name = “opencv”,
actual = select({
“//conditions:default”: “:opencv_cmake”,
}),
visibility = [“//visibility:public”],
)
OPENCV_DEPS_PATH = “$BUILD_TMPDIR/$INSTALL_PREFIX”
cmake_external(
name = “opencv_cmake”,
cache_entries = {
“CMAKE_BUILD_TYPE”: “Release”,
“CMAKE_TOOLCHAIN_FILE”: “$EXT_BUILD_ROOT/external/opencv/platforms/linux/arm-gnueabi.toolchain.cmake”,
“BUILD_LIST”: “,”.join(sorted(OPENCV_MODULES)),
“BUILD_TESTS”: “OFF”,
“BUILD_PERF_TESTS”: “OFF”,
“BUILD_EXAMPLES”: “OFF”,
“BUILD_SHARED_LIBS”: “ON” if OPENCV_SHARED_LIBS else “OFF”,
“WITH_ITT”: “OFF”,
“WITH_TIFF”: “OFF”,
“WITH_JASPER”: “OFF”,
“WITH_WEBP”: “OFF”,
“BUILD_PNG”: “ON”,
“BUILD_JPEG”: “ON”,
“BUILD_ZLIB”: “ON”,
“OPENCV_SKIP_VISIBILITY_HIDDEN”: “ON” if not OPENCV_SHARED_LIBS else “OFF”,
“OPENCV_SKIP_PYTHON_LOADER”: “ON”,
“BUILD_opencv_python”: “OFF”,
“ENABLE_CCACHE”: “OFF”,
},
make_commands = [“make -j4”, “make install”] + [“cp {}/share/OpenCV/3rdparty/lib/*.a {}/lib/”.format(OPENCV_DEPS_PATH, OPENCV_DEPS_PATH)],
lib_source = “@opencv//:all”,
linkopts = [] if OPENCV_SHARED_LIBS else [
“-ldl”,
“-lm”,
“-lpthread”,
“-lrt”,
],
shared_libraries = select({
“@bazel_tools//src/conditions:darwin”: [“libopencv_%s.%s.dylib” % (module, OPENCV_SO_VERSION) for module in OPENCV_MODULES],
“//conditions:default”: [“libopencv_%s.so.%s” % (module, OPENCV_SO_VERSION) for module in OPENCV_MODULES],
}) if OPENCV_SHARED_LIBS else None,
static_libraries = [“libopencv_%s.a” % module for module in OPENCV_MODULES]
+ [module for module in OPENCV_THIRD_PARTY_DEPS] if not OPENCV_SHARED_LIBS else None,
alwayslink=True,
)
最后,我们在 edge-brain 目录运行下面的指令编译测试程序,并将测试程序拷贝到树莓派上运行,从而验证 Bazel 搭建 OpenCV 编译环境正确性。
edge-brain$ bazel build --config elinux_armhf //examples/hello_opencv:hello-opencv --experimental_repo_remote_exec
应用实践
下面我们将介绍如何利用 Edge Brain 的编译环境完成实际的智能应用在嵌入式平台的部署。
低照度图像增强
MIRNet 是 Learning Enriched Features for Real Image Restoration and Enhancement 提出的一种图像增强网络模型。该模型学习了一组丰富的特征,这些特征结合了来自多个尺度的上下文信息,同时保留了高分辨率的空间细节。其算法的核心是:并行多分辨率卷积流,用于提取多尺度特征;跨多分辨率流的信息交换;空间和通道注意力机制来捕获上下文信息;基于注意力的多尺度特征聚合。下面是 MIRNet 的一些原理图示。
MIRNet 整体框架
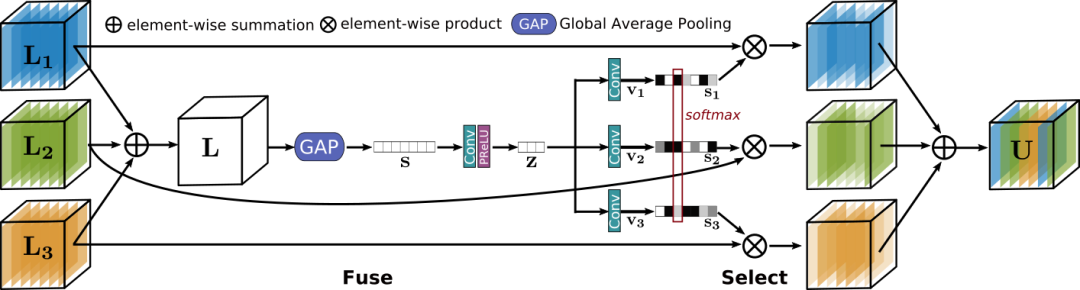
选择核心特征融合模块 (Selective Kernel Feature Fusion, SKFF)
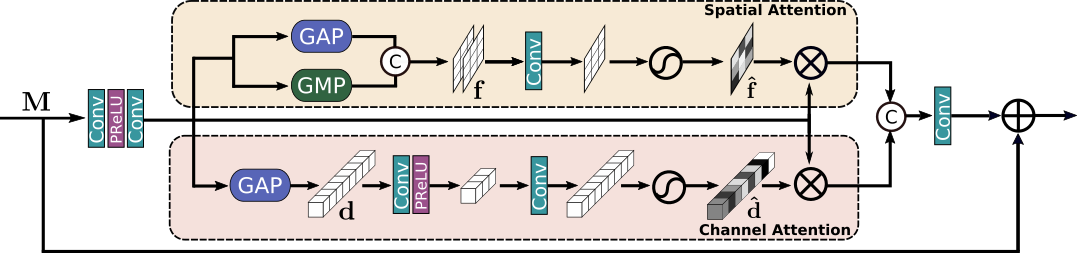
对偶注意力机制单元 (Dual Attention Unit, DAU)
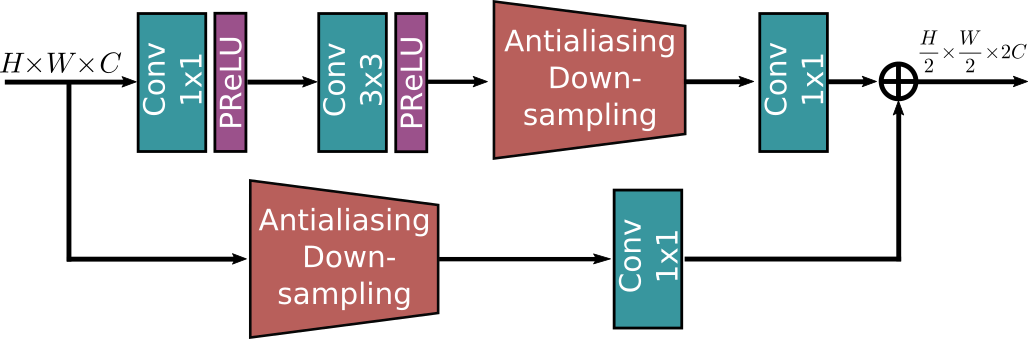
下采样模块 (Downsampling Module)
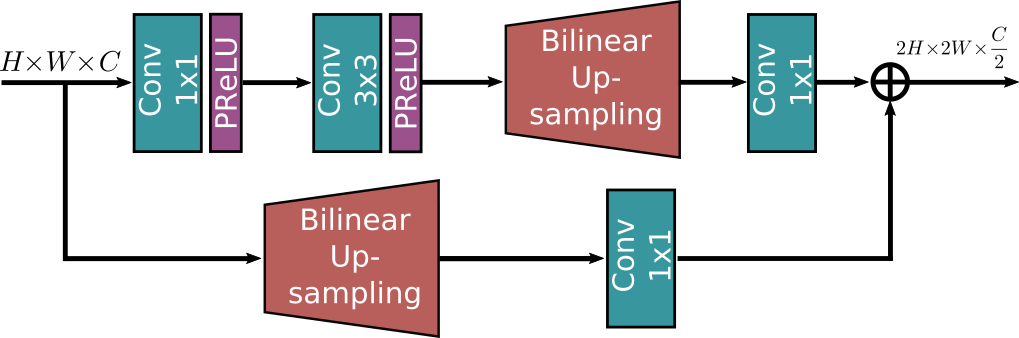
上采样模块 (Upsampling Module)
Learning Enriched Features for Real Image Restoration and Enhancement
https://arxiv.org/pdf/2003.06792v2.pdf
基于 sayakpaul/MIRNet-TFLite-TRT 提供的 MIRNet 模型可以实现图像照度的恢复,其运行效果如图所示。
MIRNet-TFLite-TRT 的展示效果
最后,我们简单介绍在树莓派上部署这个 MIRNet 模型的实际操作。
1. 交叉编译 MIRNet 应用。
edge-brain$ bazel build --config elinux_armhf //examples/mir_net:mir_net --experimental_repo_remote_exec
2. 将编译出来的可执行文件 mir_net 与它的模型文件 lite-model_mirnet-fixed_dr_1.tflite 和测试图片 data/test.jpg 上传至树莓派,其中 192.168.1.2 是树莓派的 IP。
edge-brain$ scp bazel-bin/examples/mir_net pi@192.168.1.2:~
edge-brain$ scp lite-model_mirnet-fixed_dr_1.tflite pi@192.168.1.2:~
edge-brain$ scp data/test.jpg pi@192.168.1.2:~
3. 在树莓派的终端运行 MIRNet 应用。
~$ 。/mir_net -i=test.jpg -m=lite-model_mirnet-fixed_dr_1.tflite -o=output.jpg
4. 查看 output.jpg,可以看到运行后的结果。
使用入门
为了让读者能够相当轻松地应用我们的 Edge Brain 环境入门嵌入式智能应用部署,我们介绍两种简单的程序编译方式,供读者参考完成自己的 AI 业务部署。同时,我们也欢迎各位小伙伴为开源社区贡献你们的应用案例与实践反馈。
编译外部 GitHub 工程
我们以 SunAriesCN/image-classifier 的图像分类应用为例,详细介绍如何两步完成外部 GitHub 工程的交叉编译,还能为我们 Edge Brain 贡献新案例。
1. 在 edge-brain/WORKSPACE 工程环境配置文件导入外部 image-classifier 工程。
load(“@bazel_tools//tools/build_defs/repo:git.bzl”, “git_repository”)
# Custom other thirdparty applications into repo as examples.
git_repository(
name = “image-classifier”,
remote = “https://github.com/SunAriesCN/image-classifier.git”,
commit= “72d80543f1887375abb565988c12af1960fd311f”,
)
上述代码很清晰地告诉我们,Bazel 将从远程仓库 image-classifier 中拉取特定 commit 版本的代码到本地,并以 @image-classifier 代表其路径。我们未来可以直接使用 @image-classifier//XXX 访问该外部工程配置的编译文件。这样我们不仅仅可以获得对应的代码文件,还能轻松的进行版本控制。
2. 在 example 文件夹中新建对应文件夹,并配置 BUILD 编译配置描述。
SunAriesCN/image-classifier 工程项目提供了一些图像分类的模型应用。我们可以分别将它们配置到Edge Brain 对应的 example 文件夹中。比如,我们在 edge-brain/examples 下创建一个 image_benchmark 案例目录,再添加相应的 BUILD 编译配置描述。我们将得到目录结构如下:
├── examples
│ ├── BUILD
│ ├── hello_opencv
│ │ ├── BUILD
│ │ └── hello-opencv.cc
│ ├── hello_world
│ │ ├── BUILD
│ │ └── minimal.cc
│ ├── image_benchmark
│ │ └── BUILD
其中,examples 下的每个目录代表一个应用案例。而且,所有案例目录都有一个 BUILD 文件描述对应案例项目的编译配置。比如, image_benchmark 对应 SunAriesCN/image-classifier 的图像分类基准测试应用。它的 BUILD 描述如下:
alias(
name=“image_benchmark”,
actual=“@image-classifier//image_classifier/apps/raspberry_pi:image_classifier_benchmark”
)
我们可以看到其内容非常易懂,即给第三方仓库 @image-classifier 中对应的 image_classifier_benchmark 应用创建别名为 image_benchmark。
完成上述外部工程导入操作后,我们可以使用下面的指令轻松完成应用的交叉编译:
edge-brain$ bazel build --config elinux_armhf //examples/image_benchmark:image_benchmark --experimental_repo_remote_exec
为了便于 Edge Brain 项目的长期维护,同时,我们也希望能为每位开源贡献者带来项目成功的荣誉。我们更加推荐这种编译外部 GitHub 工程的应用方式,毕竟它能实现我们项目间协同开发。只要你的项目工程也使用 Bazel 工具进行编译,你便可以在 edge-brain 的 WORKSPACE 中添加简单的几行代码配置完成嵌入式智能应用的部署。
直接添加 examples 案例
该方式也特别简单,参考 “Bazel TensorFlow Lite” 部分内容或 edge-brain/examples/hello_world 案例,我们在 examples 目录下创建案例目录,编写 BUILD 描述文件以及相应的智能应用代码,再回到 edge-brain 目录执行 bazel build。编译成功后,我们从 bazel-bin/examples/hello_world 中将测试程序与相关模型文件上传到树莓派上运行即完成部署。
最后,如果你愿意为我们的项目贡献代码案例,请你在完成程序调试后,向 Edge Brain 项目提交 Pull Request,我们将继续完善后面代码审核和 README 文档更新工作,最后会予以署名致谢。
原文标题:社区分享 | TensorFlow Lite 边缘智能快速入门
文章出处:【微信公众号:TensorFlow】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
智能终端
+关注
关注
6文章
990浏览量
36382 -
边缘计算
+关注
关注
22文章
3472浏览量
52682
原文标题:社区分享 | TensorFlow Lite 边缘智能快速入门
文章出处:【微信号:tensorflowers,微信公众号:Tensorflowers】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
一个面向单片机、事件驱动的嵌入式开发平台介绍
RA8P1部署ai模型指南:从训练模型到部署 | 本周六

2025嵌入式行业现状如何?
新一代嵌入式开发平台 AMD嵌入式软件和工具2025.1版现已推出
AMD 2025.1版嵌入式软件和工具的新增功能
嵌入式工程师为什么要学QT?
新唐科技推出高效AI MCU部署工具NuML Toolkit
高效开发 | 瑞迅基于瑞芯微系列主板QT移植部署(上)

ArkUI-X跨平台应用改造指南
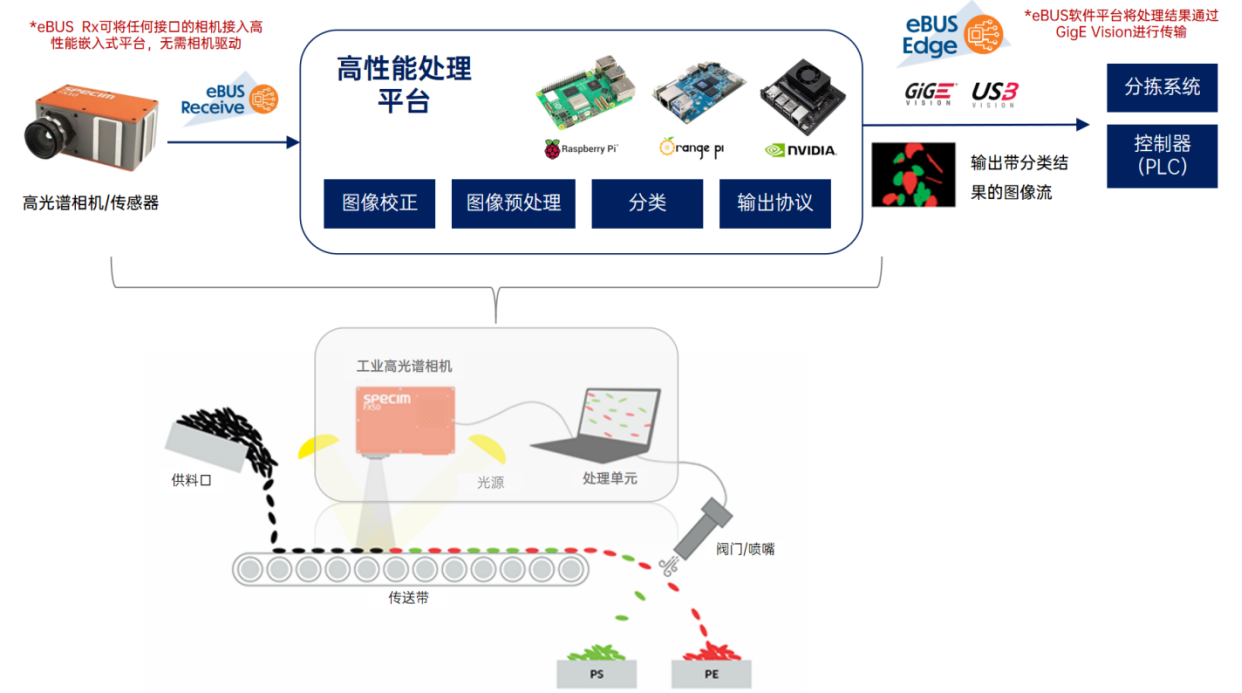
如何在嵌入式平台上部署高光谱相机
物联网工程师为什么要学Linux?
嵌入式开发入门指南:从零开始学习嵌入式
RT-Thread虚拟化部署DeepSeek大模型实践

嵌入式机器学习的应用特性与软件开发环境






 工商网监
工商网监
评论