 三种LM任务形式:单向LM,双向LM,序列到序列LM
三种LM任务形式:单向LM,双向LM,序列到序列LM

今天分享一个论文UniLM[1],核心点是掌握三种LM任务形式:单向LM,双向LM,序列到序列LM;
1. 生成任务
NLP任务大致可以分为NLU和NLG两种;Bert在NLU任务上效果很好,但是天生不适合处理生成任务。
原因在于Bert的预训练过程是使用的MLM,和生成任务的目标并不一致。
生成任务目标是每次蹦出来一个词,只能看到当前位置之前的词汇。
而Bert采用的是双向的语言模型,除了mask的单词,两个方向的词汇都可以被看到。
所以对Bert的一个改进思路就是让它在具有NLU能力的时候,同时兼备NLG能力。
2. 三种LM任务
UniLM做的就是这样一个事情。
具体的实现方式是设计了一系列的完形填空任务,这些完形填空任务的不同之处在于对上下文的定义。
从左到右的LM:使用mask单词的左侧单词来预测被遮掩的单词
从右到左的LM:和上面第一个相比就是方向的变化,使用mask单词的右侧单词来预测遮掩的单词
双向LM:就是当前mask的左右词汇都可以看到
sequence-to-sequence LM:这个就是UniLM能够具有生成能力的关键。我们的输入是source句子和target句子,mask单词在target上,那么当前mask的上下文就是source句子的所有单词和target句子中mask单词左侧的词汇可以被看到
我们把从左到右LM和从右到左LM我们归为一种任务叫单向LM;
有个点需要注意,三个任务是一起优化的,具体来讲是这样做的:
在训练的时候,1/3的时候使用双向LM,1/3的时候使用序列到序列 LM,1/6的时候使用从左到右的LM,1/6的时间使用从右到做的LM。
我们是使用不同的Mask矩阵来对应不同任务输入数据形式。
文中使用的是这样一张图来展示:
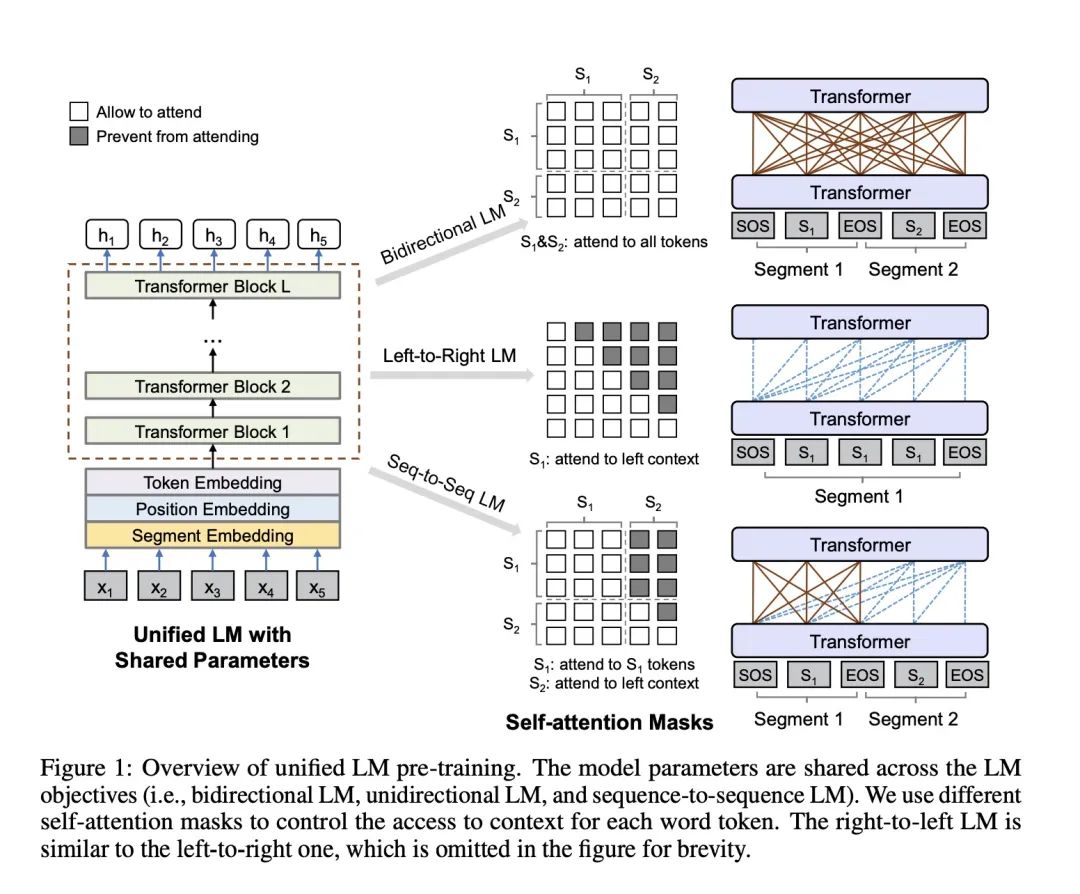
UniLM不同mask
3. 其他细枝末节
Gelu 激励函数
24层TRM,最大长度512,1024Hidden Size,16Heads,340M参数量
初始化使用Bert Large
15%被mask,其中80%真正替换mask,10%随机替换,10%不动。替换的时候,80% 的时候替换单个token,20%的时候替换bigram 或者 trigram
第四个步骤类似中文实体词的mask,也算是一点改进。
有个细节点需要注意的是,作者强调,不同的segment embedding用来区分不同LM任务。
Bert的时候,区分上下句子,我们使用0和1,在这里,我们使用这个segment embedding用来区分任务:
比如说,双向对应0和1;单向left-right对应2;单向right-left对应3;序列对应4和5;
4. 总结
掌握以下几个细节点就可以:
联合训练三种任务:单向LM,双向LM,序列LM
segment embedding可以区分不同的任务形式
mask的时候15% 的有被替换的概率,其中80% 被真正替换。在这80%真正替换的里面有80%单个token被替换,20%的二元或者三元tokens被替换
参考资料
[1]
Unified Language Model Pre-training for Natural Language Understanding and Generation: https://arxiv.org/pdf/1905.03197.pdf,
责任编辑:xj
原文标题:如何让BERT具有文本生成能力
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
-
自然语言
+关注
关注
1文章
292浏览量
13923 -
nlp
+关注
关注
1文章
491浏览量
23192
原文标题:如何让BERT具有文本生成能力
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
德州仪器LM63460/LM64460评估模块技术解析与应用指南
LM3410/LM3410-Q1 LED驱动器数据手册总结
德州仪器LMx39x/LM2901x系列比较器技术解析
LM3881系列 3轨简单功率定序器技术手册
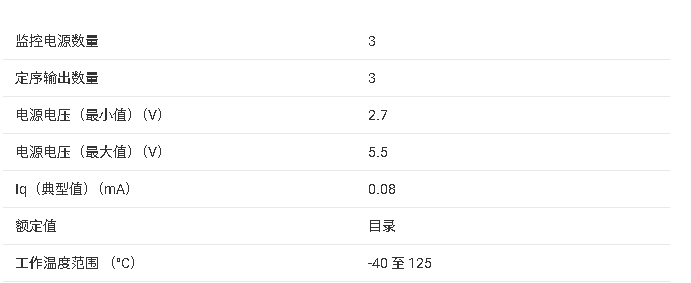
LM185/LM285/LM385-2.5-N系列微功耗电压基准芯片技术文档总结
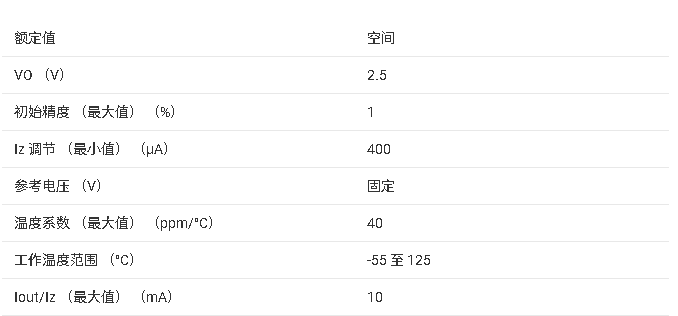
LM136A-2.5QML/LM136A-2.5QML-SP 技术文档摘要
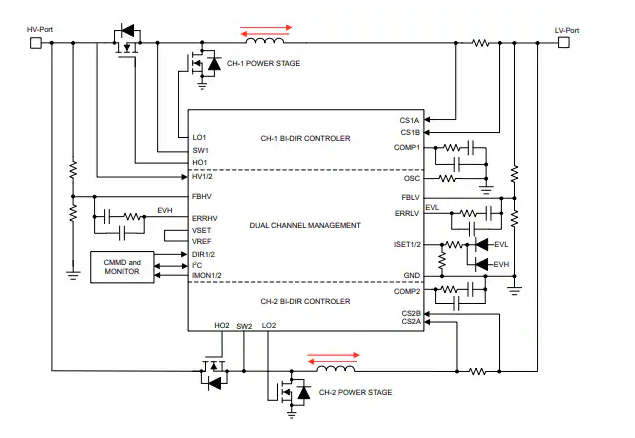
Texas Instruments LM5171双通道双向控制器数据手册
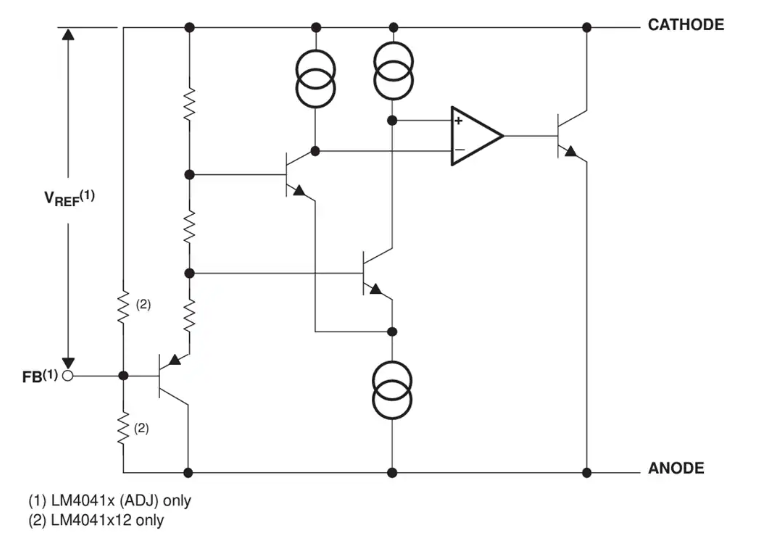
Texas Instruments LM4041/LM4041xQ精密电压基准数据手册
LM5068 -10V至 -80V热插拔控制器数据手册

LM3017系列 具有真正关断功能的高效低侧控制器数据手册
LM5171 80V 双通道双向降压-升压控制器数据手册






 工商网监
工商网监
评论