 性能提升20倍!NVIDIA A100 GPU打破16项AI芯片性能记录
性能提升20倍!NVIDIA A100 GPU打破16项AI芯片性能记录
2020年7月30日,MLPerf组织发布第三个版本MLPerf Trainingv0.7基准测试(Benchmark)结果。结果显示,英伟达基于今年5月最新发布的Ampere架构A100 TensorCore GPU,和HDR InfiniBand实现多个DGXA100系统互联的庞大集群——DGX SuperPOD系统在性能上开创了八个全新里程碑,共打破16项纪录。
MLPerf是成立于2018年5月的行业基准测试组织,致力于机器学习硬件、软件和服务的训练和推理性能测试,囊括行业中几乎所有知名企业和机构,比如Intel、NVIDIA、Google、微软、阿里巴巴等。
DGX SuperPOD系统公布于去年6月17号。最初由96台NVIDIA DGX-2H超级计算机和Mellanox互连技术在短短三周内建成,提供9.4千兆次的处理能力,用于该公司在无人驾驶车辆部署计划中的需求。
而此次创造纪录的NVIDIA DGX SuperPOD系统主要基于Ampere架构以及Volta架构,并且搭载了今年5月份发布的Ampere架构GPU A100。
黄仁勋在GTC 2020大会上说道,A100是迄今为止人类制造出的最大7纳米制程芯片。A100采用目前最先进的台积电(TSMC)7纳米工艺,拥有540亿个晶体管,它是一块3D堆叠芯片,面积高达826mm^2,GPU的最大功率达到了400W。
这块GPU上搭载了容量40G的三星HBM2显存(比DDR5速度还快得多,就是很贵),第三代TensorCore。同时它的并联效率也有了巨大提升,其采用带宽600GB/s的新版NVLink,几乎达到了10倍PCIE互联速度。
随着安培架构出现的三代TensorCore对稀疏张量运算进行了特别加速:执行速度提高了一倍,也支持TF32、FP16、BFLOAT16、INT8和INT4等精度的加速——系统会自动将数据转为TF32格式加速运算,现在你无需修改任何代码量化了,直接自动训练即可。
A100也针对云服务的虚拟化进行了升级,因为全新的multi-instanceGPU机制,在模拟实例时,每块GPU的吞吐量增加了7倍。
最终在跑AI模型时,如果用PyTorch框架,相比上一代V100芯片,A100在BERT模型的训练上性能提升6倍,BERT推断时性能提升7倍。
电子发烧友综合报道,参考自镁客网、机器之心,转载请注明来源和出处。
-
NVIDIA
+关注
关注
14文章
4585浏览量
101684 -
gpu
+关注
关注
27文章
4413浏览量
126636
发布评论请先 登录
相关推荐
NVIDIA特供中国的芯片,AI性能大降10%售价依然高
对英伟达A100芯片算力服务收费价格上调100%,这家企业的硬气来自哪里?

传英伟达新AI芯片H20综合算力比H100降80%
英伟达a100和h100哪个强?英伟达A100和H100的区别
英伟达h800和a100的区别
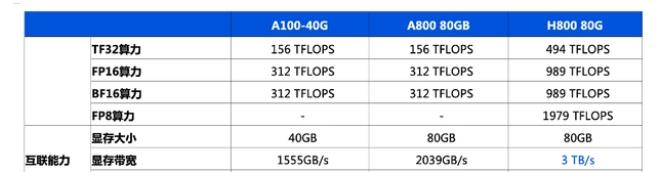
英伟达h800和a100参数对比
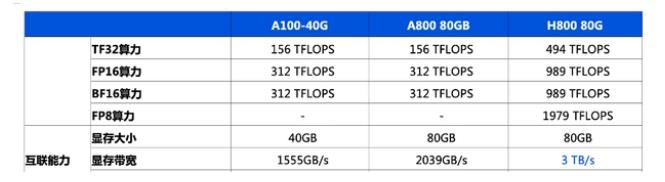
英伟达A100的算力是多少?
英伟达A100的优势分析
英伟达A100的简介
英伟达A100是什么系列?
英伟达A100和A40的对比
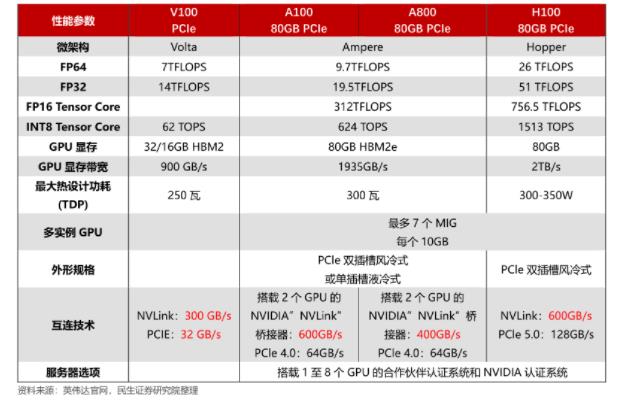
英伟达A100和V100参数对比





 工商网监
工商网监
评论