 电子发烧友App
电子发烧友App


语音识别技术的发展
与机器进行语音交流,让它听明白你在说什么。语音识别技术将人类这一曾经的梦想变成了现实。语音识别就好比“机器的听觉系统”,该技术让机器通过识别和理解,把语音信号转变为相应的文本或命令。
在1952年的贝尔研究所,Davis等人研制了世界上第一个能识别10个英文数字发音的实验系统。1960年英国的Denes等人研制了第一个计算机语音识别系统。
大规模的语音识别研究始于上世纪70年代以后,并在小词汇量、孤立词的识别方面取得了实质性的进展。上世纪80年代以后,语音识别研究的重点逐渐转向大词汇量、非特定人连续语音识别。
同时,语音识别在研究思路上也发生了重大变化,由传统的基于标准模板匹配的技术思路开始转向基于统计模型的技术思路。此外,业内有专家再次提出了将神经网络技术引入语音识别问题的技术思路。
上世纪90年代以后,在语音识别的系统框架方面并没有什么重大突破。但是,在语音识别技术的应用及产品化方面出现了很大的进展。比如,DARPA是在上世界70年代由美国国防部远景研究计划局资助的一项计划,旨在支持语言理解系统的研究开发工作。进入上世纪90年代,DARPA计划仍在持续进行中,其研究重点已转向识别装置中的自然语言处理部分,识别任务设定为“航空旅行信息检索”。
我国的语音识别研究起始于1958年,由中国科学院声学所利用电子管电路识别10个元音。由于当时条件的限制,中国的语音识别研究工作一直处于缓慢发展的阶段。直至1973年,中国科学院声学所开始了计算机语音识别。
进入上世纪80年代以来,随着计算机应用技术在我国逐渐普及和应用以及数字信号技术的进一步发展,国内许多单位具备了研究语音技术的基本条件。与此同时,国际上语音识别技术在经过了多年的沉寂之后重又成为研究的热点。在这种形式下,国内许多单位纷纷投入到这项研究工作中去。
1986年,语音识别作为智能计算机系统研究的一个重要组成部分而被专门列为研究课题。在“863”计划的支持下,中国开始组织语音识别技术的研究,并决定了每隔两年召开一次语音识别的专题会议。自此,我国语音识别技术进入了一个新的发展阶段。
自2009年以来,借助机器学习领域深度学习研究的发展以及大数据语料的积累,语音识别技术得到突飞猛进的发展。
将机器学习领域深度学习研究引入到语音识别声学模型训练,使用带RBM预训练的多层神经网络,提高了声学模型的准确率。在此方面,微软公司的研究人员率先取得了突破性进展,他们使用深层神经网络模型(DNN)后,语音识别错误率降低了30%,是近20年来语音识别技术方面最快的进步。
2009年前后,大多主流的语音识别解码器已经采用基于有限状态机(WFST)的解码网络,该解码网络可以把语言模型、词典和声学共享音字集统一集成为一个大的解码网络,提高了解码的速度,为语音识别的实时应用提供了基础。
随着互联网的快速发展,以及手机等移动终端的普及应用,可以从多个渠道获取大量文本或语音方面的语料,这为语音识别中的语言模型和声学模型的训练提供了丰富的资源,使得构建通用大规模语言模型和声学模型成为可能。
在语音识别中,训练数据的匹配和丰富性是推动系统性能提升的最重要因素之一,但是语料的标注和分析需要长期的积累和沉淀,随着大数据时代的来临,大规模语料资源的积累将提到战略高度。
现如今,语音识别在移动终端上的应用最为火热,语音对话机器人、语音助手、互动工具等层出不穷,许多互联网公司纷纷投入人力、物力和财力展开此方面的研究和应用,目的是通过语音交互的新颖和便利模式迅速占领客户群。(雨田整理) 相关产品 siri
Siri技术来源于美国国防部高级研究规划局所公布的CALO计划:一个让军方简化处理一些繁复庶务,并具学习、组织以及认知能力的数字助理,其所衍生出来的民用版软件Siri虚拟个人助理。
Siri成立于2007年,最初是以文字聊天服务为主,随后通过与语音识别厂商Nuance合作,Siri实现了语音识别功能。2010年,Siri被苹果以2亿美金收购。
Siri成为苹果公司在其产品iPhone和iPad Air上应用的一项语音控制功能。Siri可以令iPhone和iPad Air变身为一台智能化机器人。Siri支持自然语言输入,并且可以调用系统自带的天气预报、日程安排、搜索资料等应用,还能够不断学习新的声音和语调,提供对话式的应答。
Google Now
Google Now是谷歌随安卓4.1系统同时推出的一款应用,它可以了解用户的各种习惯和正在进行的动作,并利用所了解的资料来为用户提供相关信息。
今年3月24日,谷歌宣布Google Now语音服务正式登陆Windows和Mac桌面版Chrome浏览器。
Google Now的应用会更加方便用户收取电子邮件,当你接收到新邮件时,它就会自动弹出以便你查看。Google Now还推出了步行和行车里程记录功能,这个计步器功能可通过Android设备的传感器来统计用户每月行驶的里程,包括步行和骑自行车的路程。
此外,Google Now增加了一些旅游和娱乐特色功能,包括:汽车租赁、演唱会门票和通勤共享方面的卡片;公共交通和电视节目的卡片进行改善,这些卡片现在可以听音识别音乐和节目信息;用户可以为新媒体节目的开播设定搜索提醒,同时还可以接收实时NCAA(美国大学体育协会)橄榄球比分。
百度语音
百度语音一般指百度语音搜索,是百度公司为广大互联网用户提供的一种基于语音的搜索服务,用户可以使用多种客户端发起语音搜索,服务器端根据用户的发出的语音请求,进行语音识别然后将检索结果反馈给用户。
百度语音搜索不仅提供一般的通用语音搜索服务,还有针对地图用户制定的特色搜索服务,后续还会有更多的个性化搜索和识别服务出现。
目前百度语音搜索以移动客户端为主要平台,内嵌于百度的其他产品中,比如掌上百度,百度手机地图等,用户可以在使用这些客户端产品的同时体验语音搜索,支持全部主流的手机操作系统。
微软Cortana
Cortana是Windows Phone平台下的虚拟语音助手,由游戏《光晕》中Cortana的声优Jen Taylor配音,Cortana中文版又名“微软小娜”。
微软对Cortana的描述为“你手机上的私人助手,为你提供设置日历项、建议、进程等更多帮助”,它能够和你之间进行交互,并且尽可能的模拟人的说话语气和思考方式跟你进行交流。此外圆形的图标按钮会随着你手机的主题进行调整,如果说你设置了绿色的主题,那么Cortana就是绿色的图标。
此外,你能够通过开始屏幕或者设备上的搜索按钮来呼出Cortana,Cortana采用一问一答的方式,它只有在你咨询它的时候才会显示足够多的信息。
语音识别技术难点
语音识别成为争夺焦点
据悉,全球范围人工智能公司多专攻深度学习方向,而我国人工智能方向的200家左右的创业公司有超过70%的公司主攻图像或语音识别这两个分类。全球都有哪些公司在布局语音识别?他们的发展情况又如何?
其实,早在计算机发明之前,自动语音识别的设想就已经被提上了议事日程,早期的声码器可被视作语音识别及合成的雏形。最早的基于电子计算机的语音识别系统是由AT&T贝尔实验室开发的Audrey语音识别系统,它能够识别10个英文数字。到1950年代末,伦敦学院(Colledge of London)的Denes已经将语法概率加入语音识别中。
1960年代,人工神经网络被引入了语音识别。这一时代的两大突破是线性预测编码Linear Predictive Coding(LPC),及动态时间规整Dynamic Time Warp技术。语音识别技术最重大的突破是隐含马尔科夫模型Hidden Markov Model的应用。从Baum提出相关数学推理,经过Rabiner等人的研究,卡内基梅隆大学的李开复最终实现了第一个基于隐马尔科夫模型的大词汇量语音识别系统Sphinx。
苹果Siri
许多人认识语音识别可能还得归功于苹果鼎鼎大名的语音助手Siri。2011年苹果将语音识别技术融入到iPhone 4S中并发布了Siri语音助理,不过Siri并不是苹果研发的技术,而是收购成立于2007年的Siri Inc.这家公司获得的技术。在iPhone4s发布以后,Siri的体验并不理想,遭到了吐槽。因此,2013年苹果又收购了Novauris Technologies。Novauris是一种可识别整个短语的语音识别技术,这种技术并非简单识别单个词句,而是试图利用超过2.45亿个短语的识别辅助理解上下文,这让Siri的功能进一步完善。
不过Siri并没有因为收购Novauris变得完美,2016年苹果又收购了开发的人工智能软件,能够帮助计算机与用户进行更为自然的对话英国语音技术初创公司VocalIQ。随后,苹果还收购了美国圣地牙哥AI技术公司Emotient,接收其脸部表情分析与情绪辨别技术。据悉,Emotient开发的情绪引擎可读取人们的面部表情并且预测其情绪状态。
谷歌Google Now
与苹果Siri类似,谷歌的Google Now知名度也比较高。不过相比苹果谷歌在语音识别领域的动作稍显迟缓。2011年谷歌才出手收购语音通信公司SayNow和语音合成公司Phonetic Arts。SayNow可以把语音通信、点对点对话、以及群组通话和Facebook、Twitter、MySpace、Android和iPhone等等应用等整合在一起,而Phonetic Arts可以把录制的语音对话转化成语音库,然后把这些声音结合到一起,从而生成听上去非常逼真的人声对话。
2012年的Google I/O开发者大会上,Google Now第一次亮相。
2013年谷歌又以超过3000万美元收购了新闻阅读应用开发商Wavii。Wavii擅长“自然语言处理”技术,可以通过扫描互联网发现新闻,并直接给出一句话摘要及链接。之后,谷歌又收购了SR Tech Group的多项语音识别相关的专利,这些技术和专利谷歌也很快应用到市场,比如YouTube已提供标题自动语音转录支持,Google Glass使用了语音控制技术,Android也整合了语音识别技术等等,Google Now更是拥有了完整的语音识别引擎。
谷歌可能出于战略布局方面的考虑,2015年入资了中国的出门问问,这是一款以语音导航为主的公司,最近也发布了智能手表,出门问问也有国内著名声学器件厂商歌尔声学的背景。
微软Cortana小冰
微软语音识别最吸引眼球的就是Cortana和小冰。Cortana是微软在机器学习和人工智能领域方面的尝试,Cortana可以记录用户的行为和使用习惯,利用云计算、搜索引擎和“非结构化数据”分析,读取和学习包括手机中的图片、视频、电子邮件等数据理解用户的语义和语境,从而实现人机交互。
微软小冰是微软亚洲研究院2014年发布的人工智能机器人,微软小冰除了智能对话之外,还兼具群提醒、百科、天气、星座、笑话、交通指南、餐饮点评等实用技能。
除了Cortana和微软小冰,Skype Translator,可以为英语、西班牙语、汉语、意大利语用户提供实时翻译服务。
Amazon的语音技术起步于2011年收购语音识别公司Yap,Yap成立于2006年,主要提供语音转换文本的服务。2012年Amazon又收购了语音技术公司Evi,继续加强语音识别在商品搜索方面的应用,Evi也曾经应用过Nuance的语音识别技术。2013年,Amazon继续收购Ivona Software,Ivona是一家波兰公司,主要做文本语音转换,其技术已被应用在Kindle Fire的文本至语音转换功能、语音命令和Explore by Touch应用之中,Amazon智能音箱Echo也是利用了这项技术。
Facebook在2013年收购了创业型语音识别公司Mobile Technologies,其产品Jibbigo允许用户在25种语言中进行选择,使用其中一种语言进行语音片段录制或文本输入,然后将翻译显示在屏幕上,同时根据选择的语言大声朗读出来。这一技术使得Jibbigo成为出国旅游的常用工具,很好地代替了常用语手册。
之后,Facebook继续收购了语音交互解决方案服务商Wit.ai。Wit.ai的解决方案允许用户直接通过语音来控制移动应用程序、穿戴设备和机器人,以及几乎任何智能设备。Facebook的希望将这种技术应用到定向广告之中,将技术和自己的商业模式紧密结合在一起。
传统语音识别行业贵族Nuance
除了以上介绍的大家熟知的科技巨头的语音识别发展情况,传统语音识别行业贵族Nuance也值得了解。Nuance曾经在语音领域一统江湖,世界上有超过80%的语音识别都用过Nuance识别引擎技术,其语音产品可以支持超过50种语言,在全球拥有超过20亿用户,几乎垄断了金融和电信行业。现在,Nuance依旧是全球最大的语音技术公司,掌握着全球最多的语音技术专利。苹果语音助手Siri、三星语音助手S-Voice、各大航空公司和顶级银行的自动呼叫中心,刚开始都是采用他们的语音识别引擎技术。
不过由于Nuance有点过于自大,现在的Nuance已经不如当年了。
国外其他语音识别公司
2013年英特尔收购了西班牙的语音识别技术公司Indisys,同年雅虎收购了自然语言处理技术初创公司SkyPhrase。而美国最大的有线电视公司Comcast也开始推出自己的语音识别交互系统。Comcast希望利用语音识别技术让用户通过语音就可以更自由控制电视,并完成一些遥控器无法完成的事情。
国内语音识别厂商
科大讯飞
科大讯飞成立于1999年底,依靠中科大的语音处理技术以及国家的大力扶持,很快就走上了正轨。科大讯飞2008年挂牌上市,目前市值接近500亿,根据2014年语音产业联盟的数据调查显示,科大讯飞占据了超过60%的市场份额,绝对是语音技术的国内龙头企业。
提到科大讯飞,大家可能想到的都是语音识别,但其实它最大的收益来源是教育,特别是在2013年左右,收购了很多家语音评测公司,包括启明科技等,对教育市场形成了垄断,经过一系列的收购后,目前所有省份的口语评测用的都是科大讯飞的引擎,由于其占据了考试的制高点,所有的学校及家长都愿意为其买单。
百度语音
百度语音很早就被确立为战略方向,2010年与中科院声学所合作研发语音识别技术,但是市场发展相对缓慢。直到2014年,百度重新梳理了战略,请来了人工智能领域的泰斗级大师吴恩达,正式组建了语音团队,专门研究语音相关技术,由于有百度强大的资金支持,到目前为止收获颇丰,斩获了近13%的市场份额,其技术实力已经可以和拥有十多年技术与经验积累的科大讯飞相提并论。
捷通和信利
捷通华声凭借的是清华技术,成立初期力邀中科院声学所的吕士楠老先生加入,奠定了语音合成的基础。中科信利则完全依托于中科院声学所,其成立初期技术实力极为雄厚,不仅为国内语音识别行业培养了大量人才,而且也在行业领域,特别是军工领域发挥着至关重要的作用。
中科院声学所培养的这些人才,对于国内语音识别行业的发展极为重要,姑且称之为声学系,但是相对于市场来说,这两家公司已经落后了科大讯飞一大段距离。中科信利由于还有行业市场背景,目前基本上不再参与市场运作,而捷通华声最近也因为南大电子“娇娇”机器人的造假事件被推上了风口浪尖,着实是一个非常负面的影响。
思必驰
2009年前后,DNN被用于语音识别领域,语音识别率得到大幅提升,识别率突破90%,达到商用标准,这极大的推动了语音识别领域的发展,这几年内又先后成立许多语音识别相关的创业公司。
思必驰2007年成立,创始人大部分来源于剑桥团队,其技术有一定的国外基础,当时公司主要侧重于语音评测,也就是教育,但经过多年的发展,虽然占有了一些市场,但在科大讯飞把持着考试制高点的情况下,也很难得到突破。
于是在2014年的时候,思必驰痛下决心将负责教育行业的部门剥离,以9000万卖给了网龙,自己则把精力收缩专注智能硬件和移动互联网,最近更是集中精力聚焦车载语音助手,推出了“萝卜”,可市场反响非常一般。
云知声
借着2011年苹果Siri的宣传势头,2012年云知声成立。云知声团队主要来源于盛大研究院,凑巧的是CEO和CTO也是中科大毕业,与科大讯飞可以说是师兄弟。但语音识别技术则更多的源于中科院自动化所,其语音识别技术有一定的独到之处,有一小段时期内语音识别率甚至超越科大讯飞。因此也受到了资本的热捧,B轮融资达到3亿,主要瞄准智能家居市场。但至今已经成立了3年多,听到的更多是宣传,市场发展较为缓慢,B2B市场始终不见起色,B2C市场也很少听到实际应用,估计目前还处在烧钱阶段。
出门问问
出门问问成立于2012年,其CEO曾经在谷歌工作,在拿到红杉资本和真格基金的天使投资之后,从谷歌辞职创办了上海羽扇智信息科技有限公司,并立志打造下一代移动语音搜索产品————“出门问问”。
出门问问的成功之处便是苹果APP的榜单排名,但是笔者不知道有那么多内置地图的情况下,为啥还要下载这个软件,显然有时候比直接查找地图还要麻烦。出门问问同样也具有较强的融资能力,2015年拿到了Google的C轮融资,融资额累计已经7500万美元。出门问问主要瞄准可穿戴市场,最近自己也推出了智能手表等产品,但也是雷声大,雨点小,没见得其智能手表的销量如何。
国内其他的语音识别公司
语音识别的门槛并不高,因此国内各大公司也逐渐加入进来。搜狗开始采用的是云知声的语音识别引擎,但很快就搭建起自己的语音识别引擎,主要应用于搜狗输入法,效果也还可以。
腾讯当然不会落后,微信也建立了自己语音识别引擎,用于将语音转换为文字,但这个做的还是有点差距。
阿里,爱奇艺,360,乐视等等也都在搭建自己的语音识别引擎,但这些大公司更多的是自研自用,基本上技术上泛善可陈,业界也没有什么影响力。
当然,除了以上介绍的产业界的语音识别公司,学术界Cambridge的HTK工具对学术界研究推动巨大,还有CMU、SRI、MIT、RWTH、ATR等同样推动语音识别技术的发展。
语音识别技术原理是什么?
对于语音识别技术,相信大家或多或少都已经有了接触和应用,上面我们也已经介绍了国内外主要的语音识别技术公司的情况。但你仍然可能想知道,语音识别技术的原理是什么?那么接下来就为大家做介绍。
语音识别技术
语音识别技术就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的技术。语音识别的目的就是让机器赋予人的听觉特性,听懂人说什么,并作出相应的动作。目前大多数语音识别技术是基于统计模式的,从语音产生机理来看,语音识别可以分为语音层和语言层两部分。
语音识别本质上是一种模式识别的过程,未知语音的模式与已知语音的参考模式逐一进行比较,最佳匹配的参考模式被作为识别结果。
当今语音识别技术的主流算法,主要有基于动态时间规整(DTW)算法、基于非参数模型的矢量量化(VQ)方法、基于参数模型的隐马尔可夫模型(HMM)的方法、基于人工神经网络(ANN)和支持向量机等语音识别方法。
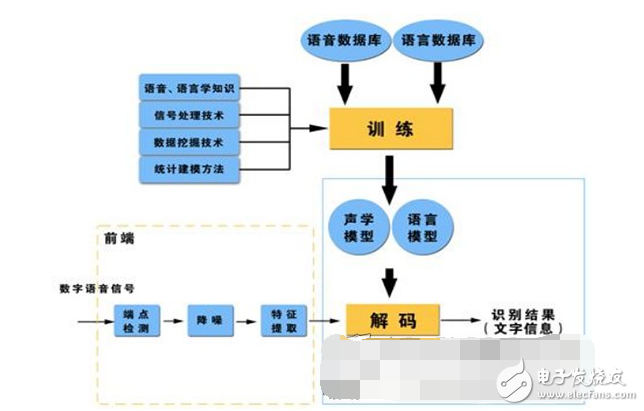
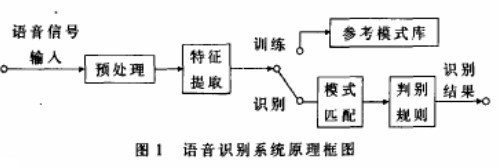
语音识别基本框图
语音识别分类:
根据对说话人的依赖程度,分为:
(1)特定人语音识别(SD):只能辨认特定使用者的语音,训练→使用。
(2)非特定人语音识别(SI):可辨认任何人的语音,无须训练。
根据对说话方式的要求,分为:
(1)孤立词识别:每次只能识别单个词汇。
(2)连续语音识别:用者以正常语速说话,即可识别其中的语句。
语音识别系统
语音识别系统的模型通常由声学模型和语言模型两部分组成,分别对应于语音到音节概率的计算和音节到字概率的计算。
Sphinx是由美国卡内基梅隆大学开发的大词汇量、非特定人、连续英语语音识别系统。一个连续语音识别系统大致可分为四个部分:特征提取,声学模型训练,语言模型训练和解码器。
(1)预处理模块
对输入的原始语音信号进行处理,滤除掉其中的不重要的信息以及背景噪声,并进行语音信号的端点检测(找出语音信号的始末)、语音分帧(近似认为在10-30ms内是语音信号是短时平稳的,将语音信号分割为一段一段进行分析)以及预加重(提升高频部分)等处理。
(2)特征提取
去除语音信号中对于语音识别无用的冗余信息,保留能够反映语音本质特征的信息,并用一定的形式表示出来。也就是提取出反映语音信号特征的关键特征参数形成特征矢量序列,以便用于后续处理。
目前的较常用的提取特征的方法还是比较多的,不过这些提取方法都是由频谱衍生出来的。
(3)声学模型训练
根据训练语音库的特征参数训练出声学模型参数。在识别时可以将待识别的语音的特征参数同声学模型进行匹配,得到识别结果。
目前的主流语音识别系统多采用隐马尔可夫模型HMM进行声学模型建模。
(4)语言模型训练
语言模型是用来计算一个句子出现概率的概率模型。它主要用于决定哪个词序列的可能性更大,或者在出现了几个词的情况下预测下一个即将出现的词语的内容。换一个说法说,语言模型是用来约束单词搜索的。它定义了哪些词能跟在上一个已经识别的词的后面(匹配是一个顺序的处理过程),这样就可以为匹配过程排除一些不可能的单词。
语言建模能够有效的结合汉语语法和语义的知识,描述词之间的内在关系,从而提高识别率,减少搜索范围。语言模型分为三个层次:字典知识,语法知识,句法知识。
对训练文本数据库进行语法、语义分析,经过基于统计模型训练得到语言模型。语言建模方法主要有基于规则模型和基于统计模型两种方法。
(5)语音解码和搜索算法
解码器:即指语音技术中的识别过程。针对输入的语音信号,根据己经训练好的HMM声学模型、语言模型及字典建立一个识别网络,根据搜索算法在该网络中寻找最佳的一条路径,这个路径就是能够以最大概率输出该语音信号的词串,这样就确定这个语音样本所包含的文字了。所以解码操作即指搜索算法:是指在解码端通过搜索技术寻找最优词串的方法。
连续语音识别中的搜索,就是寻找一个词模型序列以描述输入语音信号,从而得到词解码序列。搜索所依据的是对公式中的声学模型打分和语言模型打分。在实际使用中,往往要依据经验给语言模型加上一个高权重,并设置一个长词惩罚分数。当今的主流解码技术都是基于Viterbi搜索算法的,Sphinx也是。
语音识别技术的难点
说话人的差异
不同说话人:发音器官,口音,说话风格
同一说话人:不同时间,不同状态
噪声影响
背景噪声
传输信道,麦克风频响
鲁棒性技术
区分性训练
特征补偿和模型补偿
语音识别的具体应用
命令词系统
识别语法网络相对受限,对用户要求较严格
菜单导航,语音拨号,车载导航,数字字母识别等等
智能交互系统
对用户要求较为宽松,需要识别和其他领域技术的结合
呼叫路由,POI语音模糊查询,关键词检出
大词汇量连续语音识别系统
海量词条,覆盖面广,保证正确率的同时实时性较差
音频转写
结合互联网的语音搜索
实现语音到文本,语音到语音的搜索











 工商网监
工商网监
评论