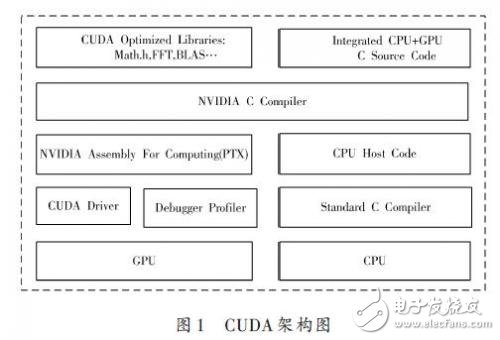
采用空位标记的方法对计算模式进行构建与切换,结合数据缓冲机制和计算任务加载方式,设计了众核多计算模式处理系统,实现了众核处理机多模式计算的功能。##在统一计算设备架构CUDA编程模型中,CUDA
2014-01-14 11:38:32 3702
3702 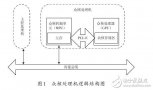
本文综合运用工业控制和视频监控两种不同专业领域的最新技术,设计了一套完整的解决方案,可以在同一监控网络中同时传输数据、视频、控制信号,在同一计算机软件的同一画面中同时进行工情和视频监控,从而实现了工业控制系统与视频监控系统真正意义上的“两网合一”。
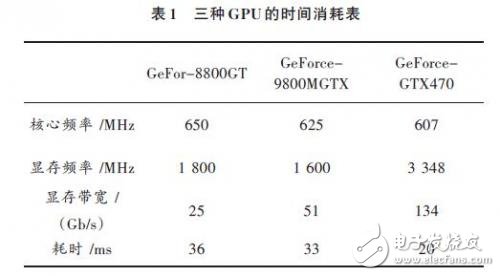
2014-04-29 09:51:074722 内存读写等方面的优化。 本文在此采用CUDA技术,实现了计算机桌面环境的多屏幕融合显示的纯软件拼接系统。该系统不但较以往单一的视频拼接系统功能更加强大,也较采用分屏器等硬件辅助的融合系统成本更低,适应性更强。目前实验表明,CUDA 技术在并行处理方面
2018-01-18 07:30:005395 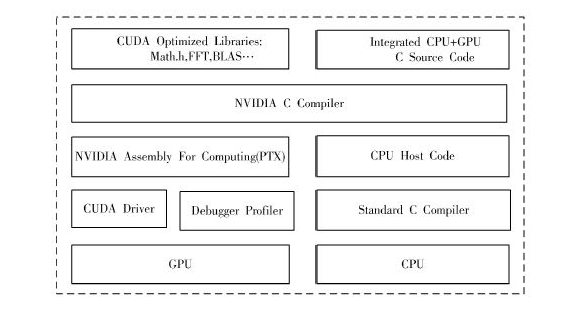
平安城市视频监控系统的建设以“统一规划、统一标准、技术先进、突出应用、稳定可靠、资源共享、信息安全”为原则,确保系统的设计和建设满足城市管理的全局需求,体现城市管理的数字化、自动化和智能化的领先水平。
2020-10-15 10:57:001997 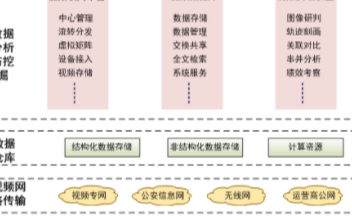
,宏观上也要做很多的工作。对宏观算力影响最大最直接的,就是算力的利用率。需要把宏观的遍布在云网边端的所有计算的资源,连成一个宏大的资源池,统一调度。原作者:软硬件融合
2022-11-24 16:37:10
随着计算机和数字图像处理技术的飞速发展,视频监控技术应用广泛。传统的视频监控系统都是用单一摄像头对某一固定场景进行监控,不仅视频的视野范围有限,而且不能对同一个物体的不同方位进行监控。这里提出
2019-06-24 07:39:08
,人们可以自助查询自己感兴趣的信息,并且可以通过高清可视电话功能向赛会服务人员咨询,由此方便观众对各项赛事信息的把握。如此便利地掌握信息,有赖于视联动力V2V™视联网™技术和Univideo™统一视频
2011-09-28 11:11:27
统一通信平台(UnifiedCommunications platform),简称UCP,是指把计算机技术与传统通信技术融为一体的新通信模式,作为一种解决方案和应用,其核心内容是:让人们无论任何
2015-01-13 13:09:41
`视频: 让人惊叹的未来显示技术`
2012-04-26 17:33:00
视频监控系统图像处理技术应用解析随着物联网和移动互联网技术的迅速发展,传统的IT架构逐渐云端化,计算资源和承载业务将进一步深度整合,在物联网和云计算汇聚的潮流中,视频监控技术将发生彻底的变革:视频
2013-09-23 15:00:02
视频转码技术与系统要求相匹配,不看肯定后悔
2021-06-08 06:49:40
`视频门禁系统视频联动的技术方案对比视频门禁是在***社会管理创新的背景下,基于人口管理尤其流动人口管理的一项新事物,其通过在流动人口聚集比较多的出租屋、农民房、老屋村、工厂、写字楼等的出入口安装
2013-03-05 09:40:06
制定一套开源标准的系统架构,用来提取并重构ADAS系统所需的数据; 2. 制定统一的地图数据(含车辆位置数据)的接口协议,让数据能够成功被提取并传输到ADAS系统之中。 在ADASIS
2020-06-05 08:39:00
引言 德州仪器DLP投影技术是一项被广泛使用的成熟技术,用于多种显示应用,包括:手持投影机、会议室和数字影院。DLP技术可满足先进的HUD系统的需求。DLP电子系统可支持视频处理和格式化,满足需要
2019-07-03 08:21:25
1. 技术架构概要 如图7-22所示,DSP系统从技术架构上涉及:投放平台、投放设置用户交互模块(setup UI)、报表(Report)、算法引擎等等模块。算法引擎模块主要是大数据及算法
2020-11-30 17:50:16
开发者统一和简化基于英特尔计算路线图进行编程的通用软件。英特尔表示,对这些领域的重大投资和技术创新,将为更多元化的计算时代奠定了基石,预计到2022年,潜在市场规模将超过3,000亿美元。
2020-11-02 07:47:14
LED显示屏作为一项高科技产品引起了人们的高度重视,采用计算机控制,将光、电融为一体的智能全彩显示屏已经在广泛领域得到应用。其像素点采用LED发光二极管,将许多发光二极管以点阵方式排列起来,构成
2019-09-07 09:45:28
嵌入式系统中使用的微型微控器到数据中心使用的众核,到处都可以发现基于MIPS的处理器。下面视频回溯了MIPS的生根以及演示了架构如何随时间演化;在暂停之后继续阅读并找出定义我们处理器技术的里程碑。一
2019-07-18 08:17:30
WiMAX的应用特点是什么?WiMAX技术在视频监控系统中的应用是什么?
2021-06-01 06:19:46
视频主题:智能家居系统关键技术分析与应用视频主讲:易老师,华清远见金牌讲师。视频简介:主讲:易老师,华清远见金牌讲师。课程内容:1 智能家居起源及概念;2 智能家居应用现状;3 智能家居与物联网
2016-02-26 10:50:43
鸿蒙OS的设计初衷是为满足全场景智慧体验的高标准的连接要求,为此华为提出了4大特性的系统解决方案。1. 分布式架构首次用于终端OS,实现跨终端无缝协同体验鸿蒙OS的“分布式OS架构”和“分布式软总线
2020-09-03 21:09:28
从技术发展来看,计算机电话集成技术大致经历了两个阶段:一是单个专用业务的计算技术整合阶段——即所有的应用业务都基于PBX接口开发; 二是以标准为基础,形成一个统一的公共平台和一系列开发工具的阶段
2019-09-10 10:42:17
和缩放后的显示区域。目前一些监控场合的监控系统并不完善,通常只能记录概况而得不到所需的细节。针对这一弊端,该装置将视频叠加技术应用于上述场合,成功升级了监控系统。升级后的系统,又哪些作用呢?
2019-08-08 06:16:41
随着移动通信技术的飞速发展和移动通信网络技术的广泛应用,移动视频监控技术(mobile video supervision,MVS)也随之得到发展。相比于有线视频监控技术,MVS具有更高的应用灵活性,适合移动监控和远程监控,部署方便。因此,MVS系统在防暴、军事、气象、环保等领域的需求越来越迫切。
2019-08-09 06:52:35
、RK3568、RK3288均有成熟的解决方案,下面将为大家介绍视频拼接的技术方案。 采用RK3588的10K视频拼接方案 RK3588是瑞芯微的新一代旗舰芯片,CPU采用8核心ARM架构,集成
2022-07-18 16:51:55
”(Quantum Paper)的设计语言。 消息称,谷歌正在着手开发一款经过完全重新设计的“L”版Android系统,革新程度堪比苹果iOS 7所带来的巨大变化,谷歌计划统一或整合Android应用和服务
2014-11-25 11:53:09
光电系统中的视频处理技术作者:上海凯视力成信息科技有限公司转载请标明出处飞机、舰船、车辆等上的光电系统应用时常常会面临如下一些技术问题:1) 恶劣的气象环境。如雾霾、雨雪、沙尘、雨雪等,严重影响
2013-10-28 10:01:21
我用的是12单片机,外界的高低电平信号接到一个IO口,波形图是这样的,但是低电平时间不确定(大约10~15s),需要把它计算出来。需要计算的是t那段时间(两个t之间的不要),简单点的程序就统一计算
2016-05-09 17:02:11
本系统采用基于FPGA与DSP协同工作进行视频处理的方案,实现视频采集、处理到传输的整个过程。 实时视频图像处理中,低层的预处理算法处理的数据量大,对处理速度要求高,但算法相对比较简单,适合于
2019-06-28 08:10:26
机载视频图形显示系统主要实现2D图形的绘制,构成各种飞行参数画面,同时叠加实时的外景视频。由于FPGA具有强大逻辑资源、丰富IP核等优点,基于FPGA的嵌入式系统架构是机载视频图形显示系统理想的架构
2019-06-24 06:07:53
基于AI算法的视频压缩技术,在高清化视频监控日益增长的现在,运用压缩技术减小存储空间,10倍高比例压缩技术。
2020-02-20 10:39:47
1.视频监控系统的现状 视频监控系统从最初的模拟闭路电视监控开始,经历了数字化,网络化的发展,正在向分布式、智能化的方向迈进。视频压缩技术的发展促进了视频监控系统的数字化,节约了大量的存储空间
2019-07-18 08:09:22
摘要: Serverless概念是近年来特别火的一个技术概念,基于这种架构能构建出很多应用场景,适合各行各业,只要对轻计算、高弹性、无状态等场景有诉求的用户都可以通过本文来普及一些基础概念,看看这些
2018-01-25 11:06:42
显示内容,灵活性高。此外,用一套嵌入式系统取代计算机来提供视频源,既可以降低成本,又具有很高的可行性和灵活性,易于工程施工。因此,独立视频源LED显示系统的需求越来越大。利用ARM和FPGA设计全彩独立视频LED系统,从而可以实时地进行灵活而方便的更改和开发,提高了系统效率,但我们具体该怎么做呢?
2019-08-06 06:06:38
对汽车音响中音/视频系统一般性故障诊断有哪些建议?如何去诊断汽车音响中音/视频系统的噪声问题?
2021-05-12 07:26:30
本文简单介绍了视频转码技术的定义、分类及实现手段,重点分析了如何在视频工程中使用转码技术,包括转码技术的使用方式及其优势所在。分析了在流方式和文件方式下如何使用转码技术。通过对移动非线性编辑系统远程传输视频数据和节目制作网络素材集中上载两个工程实例的分析,探讨了转码系统工作的灵活性和通用性。
2021-06-02 07:06:20
如何实现TSINGSEE青犀视频EasyRTC在线视频会议管理系统架构设计?
2022-02-10 06:09:07
本文提出采用内存接口的液晶显示模块,在现有点阵式液晶显示屏上附加一个MCU(Micro-Controller Unit微处理器)及相关器件,利用内存与外部控制器进行接口,从而解决了统一接口和显示速度的问题。
2021-06-07 06:34:14
随着视频编解码技术、计算机网络技术、数字信号处理技术和嵌入式系统的发展,以嵌入式网络视频服务器为核心的远程视频监控系统开始在市场上崭露头角。该系统把摄像机输出的模拟视频信号通过内置的嵌入式视频编码器直接转换成视频流,通过计算机网络传输出去。
2019-10-31 08:08:06
的新型视频监控系统,该系统在解决模拟视频监控系统的部分弊端的基础上迅速崛起。在互联网的普遍推广和网络带宽逐渐提高的背景下,视频监控技术飞速发展,出现了集多媒体技术、网络通信技术、嵌入式技术于一体的嵌入式网络视频监控系统。那么有谁知道,嵌入式无线视频监控系统该怎么实现吗?
2019-08-09 07:47:42
MCU+DSP的硬件架构。其中 DSP实现视频处理算法, FPGA/MCU主要实现各种接口电路及一些辅助性工作。随着大规模集成电路设计技术的进步和制造工艺水平的提高,FPGA的功能和处理能力越来越强,通过一
2019-08-02 06:18:40
本文介绍一种基于视差原理的立体显示器的视频转换系统,它能够将已有的立体视频格式转换成所需的视频格式。
2021-04-29 06:20:29
数字视频监控系统是以计算机或嵌入式系统为中心、视频处理技术为基础,是符合图像数据压缩的国际标准。综合利用图像传感器、计算机网络、自动控制和人工智能等技术的一种新型监控系统。由于数字视频监控系统对视频
2019-10-18 08:26:58
为了满足 LED显示技术对视频源质量更加严格的要求,本文提出了一种基于 HDMI的实时视频/音频传输系统,将 HDMI色深技术应用到 LED显示技术中,详细介绍了视频,音频等系统的各个部分工作原理,分析了其可行性。
2021-06-04 06:10:08
随着图像处理技术及传感器技术的不断发展,高清数字图像取代模拟图像成为一种趋势。设计了一种基于HD-SDI技术的高清图像处理系统,可通过FPGA+DSP架构对1080P全高清图像进行采集和字符叠加,并
2021-06-01 07:03:16
目前,所有顶尖视频显示板生产商都在使用不同色彩像素尺寸的LED视频显示模块,结构相似但又各具特色。Maxim将其独特的技术应用于这一领域,推出了MAX6974 LED驱动器,并结合低成本、中等规模的FPGA芯片提供了一个基于LED的视频显示板参考设计。
2021-06-04 06:39:14
什么是数字视频监控系统?数字视频监控系统中的DVR技术有哪些?
2021-06-07 07:02:34
,技术难度太大限制了它的普及程度。但能够提供政务大数据解决方案的也是有一些的,这里就简单介绍下大快搜索的政务大数据解决方案,以供学习参考。首先,通过一张图来看一下大快搜索的政务大数据解决的总体架构
2018-10-23 15:52:15
本文介绍一种基于CUDA技术的视频显示系统的设计与开发方案。
2021-06-02 06:48:03
哪个大神有labview加一计数器的例子呀?按一下按钮输出的数值加一。谢谢
2015-07-09 13:50:03
汽车动力传动系统一体化智能控制是什么?汽车动力传动系统一体化控制系统由什么组成?智能控制技术及其在动力传动系统中的应用是什么
2021-05-17 06:32:25
ARM架构是怎样构成的?STM32系统架构地基本原理是什么?
2021-10-20 06:10:22
浅谈大数据视频图像处理系统技术近年来,随着计算机、网络以及图像处理、传输技术的飞速发展,视频监控系统正向着高清化、智能化和网络化方向发展。视频监控系统的高清化、智能化和网络化为视频监控图像处理技术
2013-09-24 15:22:25
传统的视频监控系统一般采用PC服务器的C/S(Client/Server)结构,视频服务器由计算主机和许多存放视频的磁盘陈列组成,专门用于视频的存储和传输。流式传输采用的是边接收边播放的原则,这需要
2019-10-10 08:04:59
怎样去设计VGA视频显示系统的硬件部分?怎样去设计VGA视频显示系统的软件部分?
2021-05-06 08:13:40
应用都可得到显著改进。节点分析技术和对数成像器实现的改进有助于解决物联网中的视频分析应用问题。安全、决策制定延迟、数据带宽和计算能力是物联网应用中常见的一些工程难题。通过减少数据传输可大大减少这些工程
2018-08-06 09:54:21
什么是达芬奇技术?达芬奇技术在数字视频系统的应用是什么?
2021-06-04 07:17:50
系统功能 高压输电线路远程视频在线监测系统利用数字视频压缩技术、嵌入式计算机技术和 GPRS/CDMA/4G 无线通讯技术等先进技术,对恶劣环境中
2021-11-16 10:36:10
定义机器人系统的通用架构视频教程
2010-03-31 10:25:26 36
36 巴塞罗那超级计算中心使用布莱德统一网络架构
位于西班牙的巴塞罗那超级计算中心创建于2006年,是欧洲功能最强大的超级计算机中心,启动规模位列全球第五,
2010-01-26 17:52:371143 希捷统一存储架构 降低存储系统复杂
从3.5英寸到1.8英寸,从FC、SCSI到SAS,选择存储介质对企业和OEM厂商来说都是一件头疼的
2010-04-01 13:15:00688 【摘要】针对有机电致发光(OLED)器件在个人多媒体系统中的应用,提出一种小尺寸OLED屏视频显示的驱动方法。系统基于 FPGA器件,使用硬件描述语言设计了显示控制电路。视频显示系统
2011-04-09 17:29:3433 IMS是公认的解决FMC的统一系统架构,IPTV系统架构的实现可以基于多种网络技术,其中基于统一IMS实现是当前研究的热点。
2011-11-21 15:33:591633 本书以云计算架构技术为核心,从讨论云计算发展为起点,围绕云计算架构涉及的核心技术与商业实践进行展开。论及的核心技术包括计算、存储、网络、数据、管理、接入、安全等,涵盖了云计算的最新趋势、原理、特性与实践。
2016-04-19 16:49:022 本书以云计算架构技术为核心,从讨论云计算发展为起点,围绕云计算架构涉及的核心技术与商业实践进行展开。论及的核心技术包括计算、存储、网络、数据、管理、接入、安全等,涵盖了云计算的最新趋势、原理、特性与实践。
2016-04-19 16:49:023 本书以云计算架构技术为核心,从讨论云计算发展为起点,围绕云计算架构涉及的核心技术与商业实践进行展开。论及的核心技术包括计算、存储、网络、数据、管理、接入、安全等,涵盖了云计算的最新趋势、原理、特性与实践。
2016-04-19 16:49:022 本文介绍了基于FPGA的机载视频图形显示系统架构的设计与优化,并介绍了三种系统架构,对系统各组成部分进行了详细的分析与概述。
2017-10-15 10:19:562 自下而上可分为五个层次:物理层、核心层、资源架构层、开发平台层和应用层。 (1)物理层:云计算的最底层基础设施,提供云计算系统的硬件支持,包括网络资源、计算资源和存储资源等。 (2)核心层:对物理资源实施统一管理,将
2017-10-27 17:25:488 本文设计一种基于FPGA的机载显示系统架构,能够实现2D图形绘制,构成各种飞行参数画面,同时叠加外景视频图像。BRAM资源占用方面,视频旋转算法需要279个36Kb的BRAM;DDR3吞吐量方面
2017-11-18 03:03:041659 随着航空电子技术的不断发展,现代机载视频图形显示系统对于实时性等性能的要求日益提高。常见的系统架构主要分为三种: (1)基于 GSP+VRAM+ASIC 的架构,优点是图形 ASIC 能够有效提高
2017-11-30 15:10:0921 本文首先介绍了什么是云计算和云计算的特点,其次详细的介绍了云计算技术的几个架构层,最后介绍了云计算和大数据它们两者之间的区别。
2018-01-11 14:31:0111097 内容,灵活性高。此外,用一套嵌入式系统取代计算机来提供视频源,既可以降低成本,又具有很高的可行性和灵活性,易于工程施工。因此,独立视频源LED显示系统的需求越来越大。
2018-12-19 09:34:001349 
随着数字电子技术的发展,嵌入式计算机逐渐开始显露头角,并以强大的功能证明自己的存在。其中视频系统的发展最引入注目,从最初简单的指示灯,到能显示数字、字母的数码管,直到能显示汉字的LCD视频的出现
2020-03-09 08:02:001184 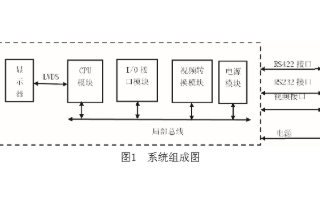
介绍了一种基于FPGA的LED视频显示系统的设计方案,详细阐述了系统各模块的工作原理及调试情况,给出了单色LED视频显示系统的实验结果,并对由单色显示屏扩展成彩色显示屏的技术进行了探讨。
2018-09-18 16:07:3813 华为视频云的支撑框架为云平台FusionCloud,可承建北京城市副中心行政办公区的视频监控系统,构建计算、存储等资源池适配视频的应用业务,通过基于主流开放的OpenStack架构的云虚拟化技术
2018-12-14 16:35:537806 和人工智能等技术的一种新型监控系统。由于数字视频监控系统对视频图像进行了数字化,所以与传统的模拟监控系统相比,数字监控具有许多优点。数字化的视频系统可以充分利用计算机的快速处理能力,对其进行压缩、分析、存储和显示。数字化视频处理技术
2019-01-01 12:20:01253 基于嵌入式WEB技术的网络视频监控系统概述目前,以网络为基础的数字视频监控系统是视频监控系统发展的主流,而随着微处理器技术、计算机网络技术的进步,基于嵌入式WEB的网络视频监控系统逐渐得到了人们的广泛关注
2020-03-17 15:36:261585 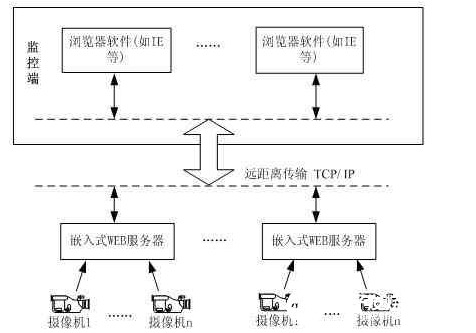
中国联通为全球服务贸易峰会提供云视频会议服务保障,这也是联通云视频首次为国际重大会议提供视频服务。云视频系统是中国联通基于先进云计算技术搭建的云视频会议架构平台,在时延、流畅性、稳定性、安全性等方面
2020-09-10 09:39:553098 本次建设的视频监控系统设计以数字网络架构为基础,应用基于计算机网络的多媒体控制管理技术,将监控视频图像的控制、储存、传输、查询纳入计算机网络的统一管理,两者互为补充、相辅相成,共同构建实用、效率
2020-11-17 17:43:106609 univideoTM统一视频教育信息化平台可以将多个分校互通互联,实现资源共享,统一管理,并且V2V视联网技术与univideoTM统一视频服务平台很好的解决了多种视频业务跨地域的,全高清的进行视频
2021-01-04 11:23:452106 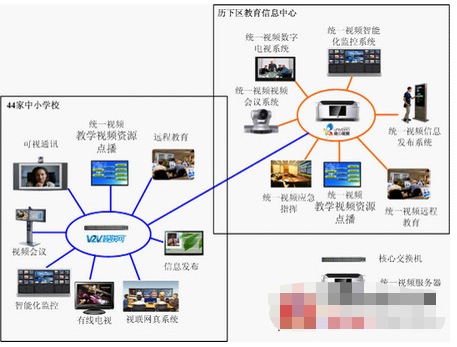
英特尔公司高级副总裁兼加速计算系统和图形事业部总经理 Raja M. Koduri 英特尔推出两大x86 CPU内核、两大数据中心SoC、两款独立GPU,以及变革性的客户端多核性能混合架构 架构
2021-08-20 13:36:531337 
为了降低超大规模、实时处理对中心架构的挑战,通过基于ROI的视频编码理念,来架构对应的计算与存储架构,这不仅取得带宽成本的收益,在用户指标方面,包括平均时长等也有显著的提升。
2022-07-07 17:29:50851 社区中的全球领导者采用 NVIDIA QODA 统一编程平台, 支持量子加速 AI、HPC 以及健康和金融应用
2022-07-14 09:58:08779 电子发烧友网站提供《日立统一计算平台选择Microsoft Exchange Server 2010.pdf》资料免费下载
2023-08-29 11:51:300 电子发烧友网站提供《日立统一计算平台选择SAP HANA:融合横向扩展解决方案.pdf》资料免费下载
2023-08-29 11:46:430 电子发烧友网站提供《日立统一计算平台VMware vSphere Pro.pdf》资料免费下载
2023-08-30 09:20:310 电子发烧友网站提供《Hitachi统一计算平台(UCP)解决方案与Brocade网络.pdf》资料免费下载
2023-08-30 10:31:040 视频采集与显示子系统可以实时采集多路视频信号,并存储到视频采集队列中,借助高效的硬实时视频帧出入队列管理和PCIe C2H DMA引擎,将采集到的视频帧实时传递到上位机采集缓冲区。在超带宽视频采集
2024-02-22 20:05:39115 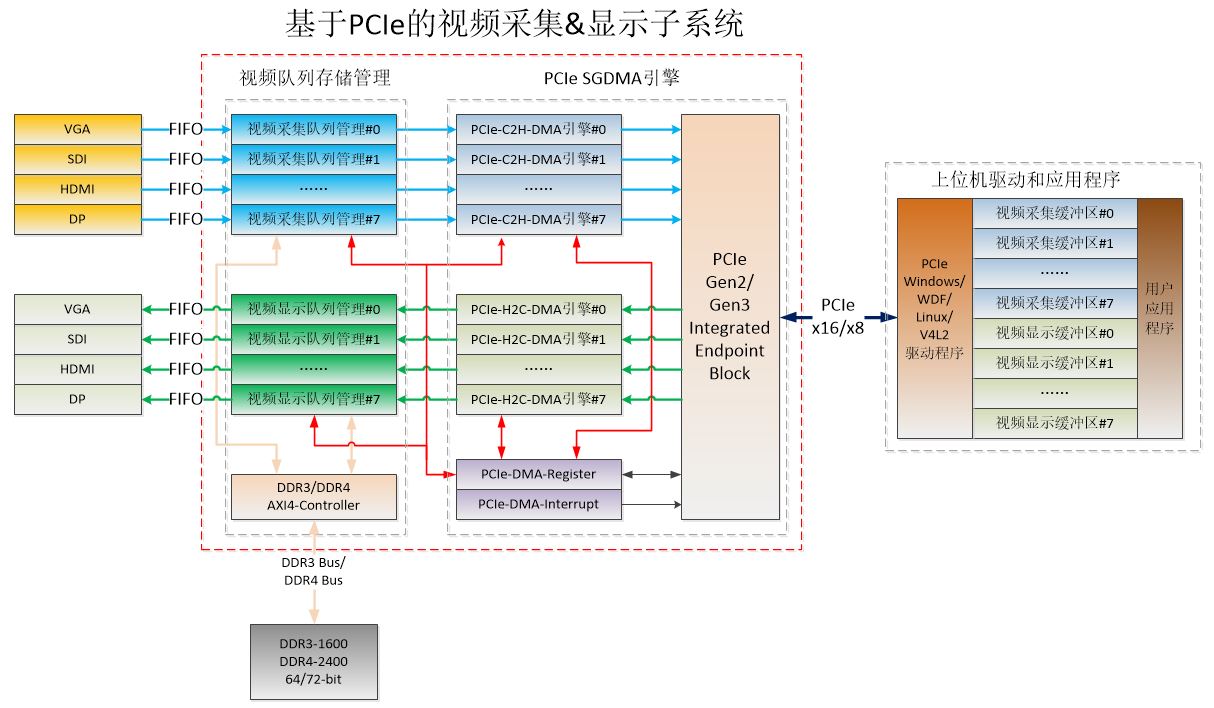
 电子发烧友App
电子发烧友App











 工商网监
工商网监
评论