 电子发烧友App
电子发烧友App












 创作
创作 发文章
发文章 发帖
发帖  提问
提问  发资料
发资料 发视频
发视频资料介绍
随着科技的不断发展,数据的获取及存储能力有了极大提升,致使数据规模呈现急速膨胀态势。这为数据挖掘和数据分析带来更多机遇的同时,各种数据质量问题的研究也给我们提出了巨大的挑战,其中数据缺失是影响数据质量的重点问题之一。数据库中大量的缺失值不仅严重影响应用者的查询质量,还会对数据挖掘与数据分析结果的正确性造成影响,进而误导决策。因此,本文针对缺失数据填补这类问题展开深入研究。目前缺失数据的填补方法很多,大部分方法是针对不完整数据中存在一种缺失类型的数据进行填补,但随着数据量的增长,庞杂的数据中缺失类型往往是混合的,单纯地应用现有的方法达不到一个很好的填补效果。为此,本文针对不同缺失类型同时出现在不完整数据中的这种复杂情况展开研究。主要工作如下:
首先,本文针对常规型缺失数据的特点结合关联规则的原理,提出了一种基于弱可用项集的数据填补方法,从关联规则填补缺失值存在的两个问题展开深入研究。第一,针对频繁项集挖掘时间长这个问题提出了一种基于布尔矩阵的关联规则挖掘方法,该方法结合布尔矩阵运算的特点来快速求解相关参数,减少 I/O 操作的同时也从整体上优化了频繁项集的挖掘效率。第二,针对产生规则少影响填补率这个问题提出了一种基于弱可用项集的填补方法,该方法通过在频繁与弱可用项集之间建立连接,一方面利用挖掘出的连接规则提高了填补率;另一方面利用挖掘出的互斥规则为下一步的填补提供了更有效的计算依据。
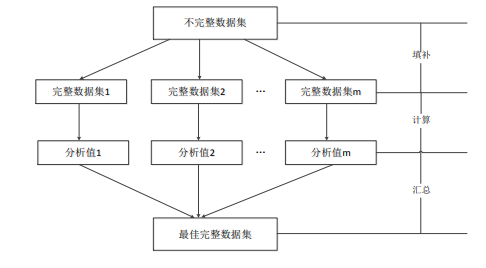
然后,本文针对异常型缺失数据的特点结合推荐算法的思想,提出了一种基于元组相似度的数据填补方法。从相似元组的查找效率和求解元组相似度的准确性上进行优化,一方面通过建立项目-元组倒排表来提高相似元组的查找效率;另一方面基于属性贡献度来计算元组相似度,最后利用 top-k 得分获得最优填补值。
最后,本文采用一组真实的 UCI 数据集进行实验,证明了本文提出的这套填补方法在混合型缺失数据中更高效。
随着互联网及信息技术的高速发展,数据作为这些技术不可或缺的资源正在被以指数级增长的速度开采和挖掘,庞大的数据给社会生产、经济研究、生物医学、信息科学研究等诸多领域的改革创新带来无限机遇的同时,也带来了越来越多的挑战,那就是如何挖掘出隐含在这些海量数据中有价值的信息和知识,因此,数据挖掘[1]作为一项重要的技术随之应运而生,并得到社会生产、经济研究、生物医疗、科学研究等许多领域的广泛应用,取得了巨大的社会效益和经济效益。然而许多模型和算法都是建立在高质量的数据集上,但现实世界中的数据集很多都存在数据缺失、数据不一致、数据冗余、噪声数据等问题[2,3]。这些问题将严重影响数据挖掘的成功与否和适用性能,成为数据挖掘的障碍。因此,为了能有效地应用数据挖掘的方法和提高挖掘的质量,在对数据库中的数据进行分析之前要对数据进行预处理,其中数据缺失问题的处理是预处理中非常重要的一个环节。
在现实社会的各个领域中,数据缺失现象可以说是无处不在,且处理不当会对后续的生产和研究工作带来很多不利影响。比如,在工业生产过程中,由于硬件设备等问题导致一些数据不能正常获取;在大型普查过程中,可能因为时间、地理位置的变化导致普查结果的不完整;在医疗领域,经常需要对各种病历进行临床实验,但由于有些病人的检验结果不能第一时间获取而导致实验数据缺失的情况;在市场调研时,由于被调研者对于问题的理解程度不同,或是主观的某些原因都会导致调研结果的缺失出现。可以看出数据缺失问题覆盖了经济研究、社会生产、人们生活产品制造和科学研究的各个方面且不可避免,并且随着数据量的激增呈现出一种上升的态势,如果对缺失数据的处理仅仅停留在单一地处理(像删除含缺失值记录或使用均值填充)层面上,很难从整体上来把握数据的趋势变化,更糟糕的是可能会因为这样的分析结果导出错误的决策,这不管对于科学研究还是社会生产等各个领域都是不愿看到的。
为了能在海量数据中挖掘出有意义的信息资源从而为决策者提供科学依据,
数据质量研究成为目前重要研究课题,其中合理填补缺失值、构建更为准确的完整数据集是课题研究中的一个难点和重点。因此,我们要认识到填补缺失值对于数据挖掘及数据分析有着重要的意义。
1. 填补缺失值能够防止删除含有少量缺失值的重要记录,这样使得数据集中某些重要信息得以保留从而为正确决策提供有效依据。
2. 填补缺失值能够重新修复出一个完整的数据集,从而让数据挖掘能在一个全总的数据集上进行分析,而不是在局部数据上进行分析,避免了因局部分析结果的片面性而产生错误的决策。
3. 填补正确的缺失值可以避免因引入新的噪音而影响数据挖掘的效果。因此,深入研究数据缺失问题,不仅为了全面、准确地利用现有数据去反映真实的实际情况,更是为了能够进行高层次的分析进而挖掘出这些数据隐含的、有用的关系和规则。所以,本文的主要工作就在于对现有的主流填补方法进行较全面的分析后,研究如何利用现有数据完成对数据集中存在的混合型缺失数据的填补工作,提出了一套新的缺失数据填补方法,并对其填补结果进行分析与评价,以期为实际数据预处理提供借鉴,具有非常重要的现实意义。
- 基于张量的车辆交通数据缺失估计方法 5次下载
- 一种对4/5G邻区缺失问题核查方法资料下载 5次下载
- 基于稀疏表示的电力负荷缺失数据补全方法 13次下载
- 封装缺陷与失效的研究方法论资料下载 11次下载
- ESL和DFM论文和资料免费分享 16次下载
- STC-ISP软件免费下载和使用方法资料免费下载 17次下载
- 大型阵列系统有什么仿真方法?详细案例讲解资料免费下载 23次下载
- 网络搜索-填补信息断层的详细中文资料免费下载 11次下载
- 一种直流混合型超导限流器的方案 0次下载
- 混合型限流及开断技术综述 6次下载
- 直流混合型断路器与直流故障限流器的匹配研究 1次下载
- 精密混合型注塑机熔胶机构模糊PID控制的研究与仿真 19次下载
- 高频高效率混合型潘尼管的理论分析 12次下载
- 混合型防火墙的研究与设计 13次下载
- 文本分类中一种混合型特征降维方法 7次下载
- 解析混合放大器的使用方法 418次阅读
- 制造等离子纳米金刚石 398次阅读
- 数据增强使用的传统算法方法 320次阅读
- DeepMind阿尔法被打脸,华为论文指出多项问题 2943次阅读
- 混合云是什么?混合云的详细资料介绍 5501次阅读
- 论文在NLP学术研究中的意义 3010次阅读
- 用AI打击论文图像造假,仍有4000多篇医学“问题论文” 4575次阅读
- CRYPTYK采用两个互补的去中心化平台组成“混合区块链” 2231次阅读
- 神经网络、机器翻译、情感分类和自动评论等研究方向的5篇论文 4930次阅读
- ACL公布的论文计算机语言学最前沿研究的详细资料概述 3869次阅读
- proteus和protel的区别 4.5w次阅读
- 电力电子变压器对交直流混合微网功率控制的研究 1437次阅读
- AUTOCAD2009免费下载中文版 CAD2009简体中文下载及安装方法 1.2w次阅读
- 基于LabVIEW和Matlab混合编程的小波降噪方法 1w次阅读
- 高压并联式混合型电网高次谐波有源滤波装置 992次阅读

 上传资料赚积分
上传资料赚积分下载排行
本周
- 1电子电路原理第七版PDF电子教材免费下载
- 0.00 MB | 1490次下载 | 免费
- 2单片机典型实例介绍
- 18.19 MB | 92次下载 | 1 积分
- 3S7-200PLC编程实例详细资料
- 1.17 MB | 27次下载 | 1 积分
- 4笔记本电脑主板的元件识别和讲解说明
- 4.28 MB | 18次下载 | 4 积分
- 5开关电源原理及各功能电路详解
- 0.38 MB | 10次下载 | 免费
- 6基于AT89C2051/4051单片机编程器的实验
- 0.11 MB | 4次下载 | 免费
- 7蓝牙设备在嵌入式领域的广泛应用
- 0.63 MB | 3次下载 | 免费
- 89天练会电子电路识图
- 5.91 MB | 3次下载 | 免费
本月
- 1OrCAD10.5下载OrCAD10.5中文版软件
- 0.00 MB | 234313次下载 | 免费
- 2PADS 9.0 2009最新版 -下载
- 0.00 MB | 66304次下载 | 免费
- 3protel99下载protel99软件下载(中文版)
- 0.00 MB | 51209次下载 | 免费
- 4LabView 8.0 专业版下载 (3CD完整版)
- 0.00 MB | 51043次下载 | 免费
- 5555集成电路应用800例(新编版)
- 0.00 MB | 33562次下载 | 免费
- 6接口电路图大全
- 未知 | 30320次下载 | 免费
- 7Multisim 10下载Multisim 10 中文版
- 0.00 MB | 28588次下载 | 免费
- 8开关电源设计实例指南
- 未知 | 21539次下载 | 免费
总榜
- 1matlab软件下载入口
- 未知 | 935053次下载 | 免费
- 2protel99se软件下载(可英文版转中文版)
- 78.1 MB | 537791次下载 | 免费
- 3MATLAB 7.1 下载 (含软件介绍)
- 未知 | 420026次下载 | 免费
- 4OrCAD10.5下载OrCAD10.5中文版软件
- 0.00 MB | 234313次下载 | 免费
- 5Altium DXP2002下载入口
- 未知 | 233045次下载 | 免费
- 6电路仿真软件multisim 10.0免费下载
- 340992 | 191183次下载 | 免费
- 7十天学会AVR单片机与C语言视频教程 下载
- 158M | 183277次下载 | 免费
- 8proe5.0野火版下载(中文版免费下载)
- 未知 | 138039次下载 | 免费





 工商网监
工商网监
评论