 电子发烧友App
电子发烧友App












 创作
创作 发文章
发文章 发帖
发帖  提问
提问  发资料
发资料 发视频
发视频资料介绍
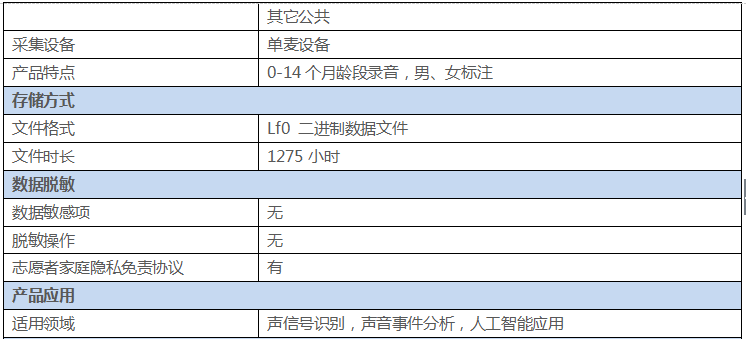
人类婴儿由于出生时过于虚弱,不具备主动接近成人的行为能力,因此在9个月之前,其主要通过哭声吸引成人的注意,并向成人表达他的需求。婴幼儿语料库是按照一定采样标准采集的电子数据集合,随着大数据时代的到来,语音智能产品已经渗透到移动通信、智能家居、工业生产等很多领域。语音识别技术逐渐趋于成熟,然而,语音识别产品所依赖的语音数据价值变得更加显著,语料库成为重要的基础资源。独有核心技术,让AI更进一步。
本语料库采集了近十六万条语音。录音采集人来自中国大陆各地,录制人数300多人,录制家庭300多家,采取0-14个月跟踪家庭录制,男女比例均衡,音频总时长1275小时,采集方式为单麦设备。每条音频单独存储为一个文件,并由专业标注人员手工进行两级标注。所有标注数据都是全检后再交付,以保证交付数据的质量。
随着以深度神经网络为代表的人工智能技术的发展,新一轮的人机交互技术热潮正在兴起。在机器视觉领域,由于海量图像和视觉场景数据库的诞生,催生了人脸识别、姿态识别、自动驾驶、无人机等领域的技术革新。目前世界上已有的典型的大规模海量图像和视觉场景数据库包括,ImageNet、MSCOCO等业界知名的数据库。
在声音场景和声音事件的识别领域,技术的发展已经成熟,然而商业应用滞后于机器视觉领域的应用。在声音领域,目前世界上最著名的音频数据库包括:欧洲的DCASE(声音场景和事件数据库)和谷歌的Audio Set(包括各类层次结构化的音频分类数据)等。
在家庭环境领域,能够用来服务于AI应用的声音数据极为缺乏,本产品旨在填补这一空白,为全球的智能家庭环境的AI应用落地做出贡献。
声音场景(Acoustic Scene)指的是室内、室外、火车站、餐厅、看电影、听音乐等实际生活中人们的有声的生活场景,通过声音信号的识别来辨识这类场景,就是声音场景识别;声音事件(Acoustic Event)指的是根据短时声学特征,利用统计学习的建模方法,对不同的声源所关联的事件,进行类别的分类。例如,对哭声、咳嗽声、脚步声,能够通过声音频率特征的分布规律,进行实时的检测,发现家居环境中的突发性事件、婴幼儿的行为事件、家庭成员的异常活动等。

- 2023年人工智能产业概况及应用趋势分析 0次下载
- 人工智能赋能的查询处理与优化技术 47次下载
- 人工智能技术的发展历史和未来发展趋势详细资料分析 27次下载
- 人工智能技术发展趋势与应用的经典复习题免费下载 8次下载
- 德勤人工智能创新解决方案手册详细资料免费下载 5次下载
- 如何使用Python来设计和实现语料分析系统设计? 17次下载
- 人工智能行业发展状况如何?人工智能行业研究报告详细资料免费下载 15次下载
- 如何使用变频和人工智能技术对冰箱节能的详细研究资料概述 6次下载
- 人工智能深度学习目标检测的详细资料免费下载 44次下载
- 检索式智能对话机器人开发实战案例详细资料分析概述 16次下载
- 使用非对称PKI的节点验证示例的详细中文资料概述 8次下载
- 汉语口语互动分级语料库的构建 0次下载
- 面向中文语料库的模式检索研究邱冰 0次下载
- 人工智能技术基础及其应用 149次下载
- 中医汉英双语语料库平台 19次下载
- 人工智能领域多模态的概念和应用场景 2201次阅读
- 一文综述人工智能技术的发展 1680次阅读
- 现在为什么有这么多人想学习Python人工智能技术? 3562次阅读
- 人工智能技术在电力系统中的应用现状和发展方向 4.1w次阅读
- 大数据与人工智能技术如何帮助智能电网和能源互联网的发展 8991次阅读
- 人工智能未来发展趋势分析 1.5w次阅读
- 浅谈人工智能中六大关键技术 2.8w次阅读
- 人工智能技术能应用于医疗行业的那些方面?详细分析 6486次阅读
- 人工智能基础高中教材已经正式发布人工智能入门必备籍 5704次阅读
- 人工智能的介绍和在计算机网络技术中的运用的详细概述 5750次阅读
- Python和人工智能的关系及应用的详细资料概述 5071次阅读
- 人工智能技术如何助推智能电网的发展概述 7649次阅读
- 人工智能之技术与算法 1317次阅读
- 人工智能技术有哪些_人工智能技术的原理 6w次阅读
- 人工智能相关的人与技术都在这里_人工智能的相关技术 4439次阅读

 上传资料赚积分
上传资料赚积分下载排行
本周
- 1TC358743XBG评估板参考手册
- 1.36 MB | 330次下载 | 免费
- 2开关电源基础知识
- 5.73 MB | 11次下载 | 免费
- 3100W短波放大电路图
- 0.05 MB | 4次下载 | 3 积分
- 4嵌入式linux-聊天程序设计
- 0.60 MB | 3次下载 | 免费
- 5DIY动手组装LED电子显示屏
- 0.98 MB | 3次下载 | 免费
- 6基于FPGA的C8051F单片机开发板设计
- 0.70 MB | 2次下载 | 免费
- 751单片机PM2.5检测系统程序
- 0.83 MB | 2次下载 | 免费
- 8基于51单片机的RGB调色灯程序仿真
- 0.86 MB | 2次下载 | 免费
本月
- 1OrCAD10.5下载OrCAD10.5中文版软件
- 0.00 MB | 234315次下载 | 免费
- 2555集成电路应用800例(新编版)
- 0.00 MB | 33566次下载 | 免费
- 3接口电路图大全
- 未知 | 30323次下载 | 免费
- 4开关电源设计实例指南
- 未知 | 21549次下载 | 免费
- 5电气工程师手册免费下载(新编第二版pdf电子书)
- 0.00 MB | 15349次下载 | 免费
- 6数字电路基础pdf(下载)
- 未知 | 13750次下载 | 免费
- 7电子制作实例集锦 下载
- 未知 | 8113次下载 | 免费
- 8《LED驱动电路设计》 温德尔著
- 0.00 MB | 6656次下载 | 免费
总榜
- 1matlab软件下载入口
- 未知 | 935054次下载 | 免费
- 2protel99se软件下载(可英文版转中文版)
- 78.1 MB | 537797次下载 | 免费
- 3MATLAB 7.1 下载 (含软件介绍)
- 未知 | 420027次下载 | 免费
- 4OrCAD10.5下载OrCAD10.5中文版软件
- 0.00 MB | 234315次下载 | 免费
- 5Altium DXP2002下载入口
- 未知 | 233046次下载 | 免费
- 6电路仿真软件multisim 10.0免费下载
- 340992 | 191186次下载 | 免费
- 7十天学会AVR单片机与C语言视频教程 下载
- 158M | 183279次下载 | 免费
- 8proe5.0野火版下载(中文版免费下载)
- 未知 | 138040次下载 | 免费





 工商网监
工商网监
评论