Machine Learning SDK 相集成以供预览。客户可以使用 Azure 大规模部署的英特尔® FPGA(现场可编程逻辑门阵列)技术,为其模型提供行业领先的人工智能 (AI) 推理性能。
2018-05-16 17:25:03 6184
6184 最新MLPerf基准测试表明,NVIDIA已将其在AI推理性能和能效方面的高标准扩展到Arm以及x86计算机。
2021-09-23 14:18:062518 
不久前,AI性能基准评测平台MLPerf公布了2022年首次推理(Inference v2.0)测试成绩,NVIDIA的AI平台表现依然抢眼。
2022-04-15 22:12:002738 
NVIDIA Turing GPU和Xavier 芯片系统在首个独立AI推理基准测试 ——MLPerf Inference 0.5中取得第一名。
2019-11-08 16:53:295054 年5月的行业基准测试组织,致力于机器学习硬件、软件和服务的训练和推理性能测试,囊括行业中几乎所有知名企业和机构,比如Intel、NVIDIA、Google、微软、阿里巴巴等。 DGX Su
2020-07-31 08:03:005270 时间、麦克风和惯性测量单元(IMU)的多种传感器。SensPro2™系列建立在CEVA业界领先的传感器中枢DSP领先地位上,在相同的工艺节点上,为计算机视觉提供了六倍DSP处理性能提升,为雷达处理提供了八倍DSP性能提升,并在AI推理性能方面提升了两倍,其功率效率相比前代产品提高了20%。
2021-01-21 16:15:411050 首发极术社区如对Arm相关技术感兴趣,欢迎私信 aijishu20加入技术微信群。分享内容NVIDIA Jetson是嵌入式计算平台,具有低功耗、高性能和小体积等特点,可加速各行业的AI应用落地
2021-12-14 08:05:01
Jetson概述爆炸式增长的AI模型的复杂性专为自主机器开发人员设计的AI计算板加快AI处理的SDK“JetPack”概述NVIDIA Jetson是NVIDIA公司嵌入式单板计算机的一系列
2021-11-09 08:26:45
的BERT、GNMT 和Jasper 等AI模型开源优化帮助开发者实现顶尖推理性能。NVIDIA的客户和合作伙伴中包括有会话式AI领域的一流公司,比如Kensho、微软、Nuance、Optum等。最后要
2019-11-08 19:44:51
类型在运行两种常见的 FP32 ML 模型时的 ML 推理性能。我们将在以后的博客中介绍量化推理 (INT8) 的性能。工作负载[MLCommons]在其[MLPerf 推理基准套件]中提供了代表性
2022-08-31 15:03:46
DLLite-Micro 是一个轻量级的 AI 推理框架,可以为 OpenHarmony OS 的轻量设备和小型设备提供深度模型的推理能力DLLite-Micro 向开发者提供清晰、易上手的北向接口
2021-08-05 11:40:11
三星打破上网本既有模式 性能尺寸接近传统笔记本CNET科技资讯网7月1日国际报道 Nvidia证实,三星将推出一款采用其Ion芯片组的上网本,打破这类产品既有的模式。 Nvidia笔记本电脑产品部门
2009-07-01 21:47:27
的是要知道它提供的选项来提高推理性能。作为开发人员,您会寻找可以压缩的每一毫秒,尤其是在需要实现实时推理时。让我们看一下Arm NN中可用的优化选项之一,并通过一些实际示例评估它可能产生
2022-04-11 17:33:06
基于SRAM的方法可加速AI推理
2020-12-30 07:28:28
Tengine是什么?如何在RK3399这一 Arm64 平台上搭建 Tengine AI 推理框架,并运行图像识别相关应用?
2022-03-07 07:53:43
使用 PyTorch 对具有非方形图像的 YOLOv4 模型进行了训练。
将 权重转换为 ONNX 文件,然后转换为中间表示 (IR)。
无法确定如何获得更好的推理性能。
2023-08-15 06:58:00
的参考。评估TI处理器模型性能的方式有两种:TDA4VM入门套件评估模块(EVM)或TI Edge AI Cloud,后者是一项免费在线服务,可支持远程访问TDA4VM EVM,以评估深度学习推理性能。借助
2022-11-03 06:53:28
生成两个 IR文件(相同的 .xml 文件,但不同的 .bin 文件)
具有不同重量的类似模型,以不同的 fps (27fps 和 6fps) 运行
更多样化的权重是否会影响 Myriad X 上的推理性能?
2023-08-15 07:00:25
1 简介AI任务管理与统一的推理能力提供了接口的统一标准系统上CPU提供了AI任务调度管理的能力,对AI的能力进行了开放的推理和推理,同时,提供了一个不同的生命周期框架层级的应用程序。推理接口
2022-03-25 11:15:36
,支持广泛的应用程序和动态工作负载。本文将讨论这些行业挑战可以在不同级别的硬件和软件设计采用Xilinx VERSAL AI核心,业界首创自适应计算加速平台超越了CPU/GPU和FPGA的性能。
2020-11-01 09:28:57
基于最小集覆盖理论的拥塞链路推理算法,仅对共享瓶颈链路进行推理,当拥塞路径存在多条链路拥塞时,算法的推理性能急剧下降.针对该问题,提出一种基于贝叶斯最大后验(Bayesian maxlmum
2017-12-27 10:35:00 0
0 针对CLINK算法在路由改变时拥塞链路推理性能下降的问题,建立一种变结构离散动态贝叶斯网模型,通过引入马尔可夫性及时齐性假设简化该模型,并基于简化模型提出一种IP网络拥塞链路推理算法(VSDDB
2018-01-16 18:46:260 Azure Machine Learning SDK 相集成以供预览。客户可以使用 Azure 大规模部署的英特尔 FPGA(现场可编程逻辑门阵列)技术,为其模型提供行业领先的人工智能 (AI) 推理性能。 “作为一家整体技术提供商,我们通过与 Microsoft 密切合作为人工智能提供支持。
2018-05-20 00:10:002865 Xavier主要用于边缘计算的深度神经网络推理,其支持Caffe、Tensorflow、PyTorch等多种深度学习框架导出的模型。为进一步提高计算效率,还可以使用TensorRT对训练好的模型利用
2019-04-17 16:55:4017861 
Nvidia用于开发和运行可理解和响应请求的对话式AI的GPU强化平台,已经达成了一些重要的里程碑,并打破了一些记录。
2019-08-15 14:26:252278 MLPerf Inference 0.5是业内首个独立AI推理基准套件,其测试结果证明了NVIDIA Turing数据中心GPU以及 NVIDIA Xavier 边缘计算芯片系统的性能。
2019-11-29 14:45:022696 Graphcore表示,MK2的BERT-Large训练性能比MK1改进了9.3倍,BERT-3Layer推理性能提高了8.5倍,EfficientNet-B3培训的性能提高了7.4倍。
2020-07-20 14:58:003213 DeepCube专注于深度学习技术的研发,这些技术可改善AI系统的实际部署。该公司的众多专利创新包括更快,更准确地训练深度学习模型的方法,以及在智能边缘设备上大大提高的推理性能的方法。
2020-09-10 14:40:371878 你已经建立了你的深度学习推理模型并将它们部署到 NVIDIA Triton Inference Serve 最大化模型性能。 你如何进一步加快你的模型的运行速度? 进入 NVIDIA模型分析器
2020-10-21 19:01:03407 美国东部时间10月21日,全球备受瞩目的权威AI基准测试MLPerf公布今年的推理测试榜单,浪潮AI服务器NF5488A5一举创造18项性能纪录,在数据中心AI推理性能上遥遥领先其他厂商产品
2020-10-23 16:59:441615 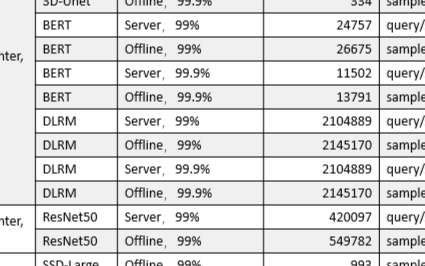
)的12个提交者增加了近一倍。 结果显示,今年5月NVIDIA(Nvidia)发布的安培(Ampere)架构A100 Tensor Core GPU,在云端推理的基准测试性能是最先进Intel CPU
2020-10-23 17:40:023929 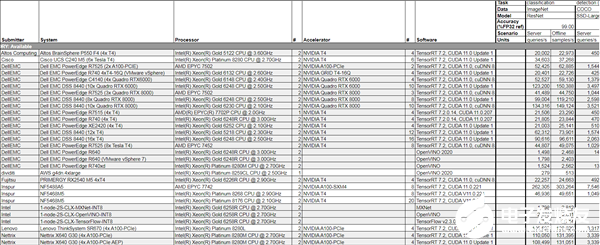
美国东部时间10月21日,全球倍受瞩目的权威AI基准测试MLPerf公布今年的推理测试榜单,浪潮AI服务器NF5488A5一举创造18项性能记录,在数据中心AI推理性能上遥遥领先其他厂商产品。
2020-10-26 16:30:441709 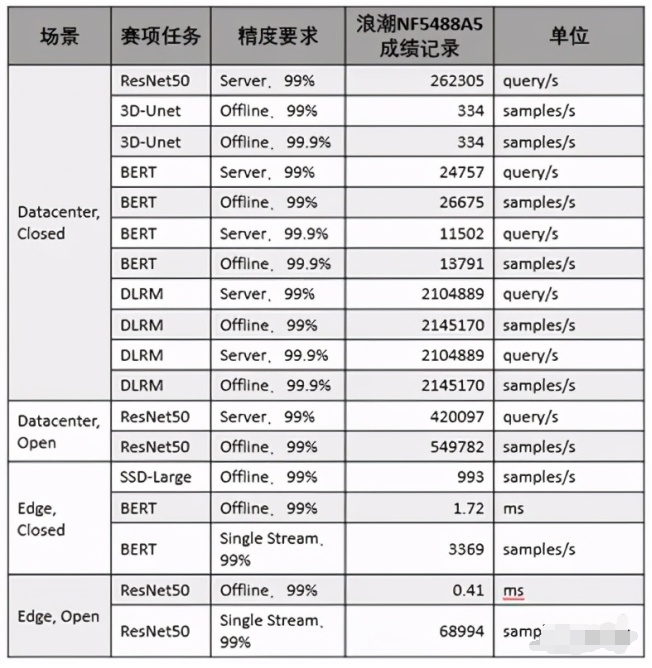
近日,在GTC China元脑生态技术论坛上,中科极限元、趋动科技、睿沿科技等元脑生态伙伴分享了多个场景下浪潮AI服务器NF5488A5的实测数据,结果表明浪潮NF5488A5大幅提升了智能语音、图像识别等AI模型的训练和推理性能,促进了产业AI解决方案的开发与应用。
2020-12-24 15:25:012123 
一个支持边缘实时推理的姿态估计模型,其推理性能比OpenPose模型快9倍。
2021-06-25 11:55:521450 NVIDIA于今日发布公司第八代AI软件TensorRT™ 8。该软件将语言查询推理时间缩短了一半,使开发者能够从云端到边缘构建全球最佳性能的搜索引擎、广告推荐和聊天机器人。
2021-07-21 15:07:573208 。并基于8张NVIDIA A100 GPU和开放规则,以离线场景下每秒处理107.8万张图片的成绩,打破MLPerf 1.0推理性能测试纪录。 阿里云自研震旦异构计算加速平台,适配GPU、ASIC等多种异构
2021-08-13 10:17:293119 ,其中的模型数量达数千个,日均调用服务达到千亿级别。无量推荐系统,在模型训练和推理都能够进行海量Embedding和DNN模型的GPU计算,是目前业界领先的体系结构设计。 传统推荐系统面临挑战 传统推荐系统具有以下特点: 训练是基于参数
2021-08-23 17:09:034486 NVIDIA 认证系统可以帮助客户在高性能、经济高效且可扩展的基础设施上为各种现代 AI 应用识别、获取和部署系统,该认证系统现在包含两个新的边缘AI类别。
2021-11-10 14:27:211216 
软件的新功能,该软件为所有AI模型和框架提供跨平台推理;同时也包含对NVIDIA TensorRT的更新,该软件优化AI模型并为NVIDIA GPU上的高性能推理提供运行时优化。 NVIDIA还推出了NVIDIA A2 Tensor Core GPU,这是一款用于边
2021-11-12 14:42:531684 MegEngine「训练推理一体化」的独特范式,通过静态图优化保证模型精度与训练时一致,无缝导入推理侧,再借助工业验证的高效卷积优化技术...
2022-02-07 10:59:490 在首次参加行业 MLPerf 基准测试时,基于 NVIDIA Ampere 架构的低功耗系统级芯片 NVIDIA Orin 就创造了新的AI推理性能纪录,并在边缘提升每个加速器的性能。
2022-04-08 10:14:444200 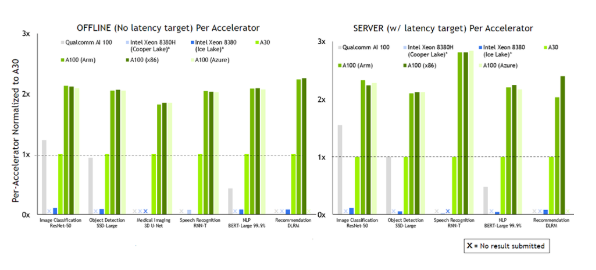
现在,您和开发人员社区的其他成员都可以使用这些成果,主要是以开源软件的形式。此外, TensorRT 和 Triton 推理服务器可从 NVIDIA NGC 免费获得,以及预训练模型、深度学习框架
2022-04-08 16:31:31931 
“在使用 NVIDIA TensorRT和NVIDIA T4 GPU对平台赋能后,“极星”推理平台的算法推理效率得到了进一步的提升,更好地支持速接入各类算法、数据及智能设备,实现AI自闭环能力,并通过应用服务和标准化接口,帮助终端客户低成本实现AI与业务的结合,快速构建智能应用。
2022-04-13 14:49:19862 NVIDIA Triton 有助于在每个数据中心、云和嵌入式设备中实现标准化的可扩展生产 AI 。它支持多个框架,在 GPU 和 DLA 等多个计算引擎上运行模型,处理不同类型的推理查询。通过与 NVIDIA JetPack 的集成, NVIDIA Triton 可用于嵌入式应用。
2022-04-18 15:40:022306 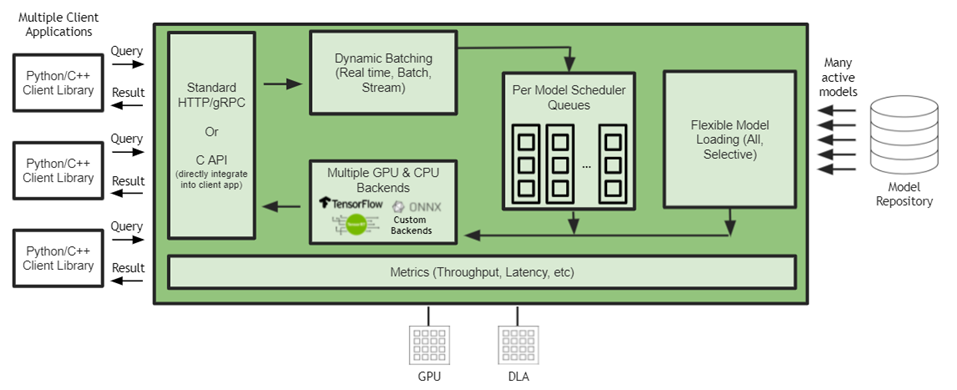
在虚拟人项目中,NVIDIA CUDA技术大幅提升了渲染速度,NVIDIA TensorRT 方便快速地加速深度学习模型的推理,结合MPS技术,实现了单卡多路推流,使整体推理效率达到了原来的三倍!性能的大幅提升,既提升了GPU的利用率,又降低了AI技术的使用成本。
2022-04-21 10:50:24751 NVIDIA DRIVE Orin 现已投产,可在深度神经网络推理性能方面实现重大飞跃。6 月 9 日,NVIDIA 将举办一场网络会议,介绍 DNN 架构设计以及 NVIDIA TensorRT 的范围,旨在为生产提供经过优化的推理引擎。
2022-05-21 10:24:051154 OpenVINO 开发套件是Intel平台原生的深度学习推理框架,自2018年推出以来,Intel已经帮助数十万开发者大幅提升了AI推理性能,并将其应用从边缘计算扩展到企业和客户端。
2022-06-24 11:05:301153 最新的 AI 推理基准显然具有重要意义,因为它是目前可用的最接近真实世界 AI 推理性能的衡量标准。但随着它的成熟和吸引更多的提交,它也将成为成功部署技术堆栈的晴雨表和新实施的试验场。
2022-07-08 15:37:551246 
DeepRec 集成了英特尔开源的跨平台深度学习性能加速库oneDNN (oneAPI Deep Neural Network Library),该程序库已经针对大量主流算子实现了性能优化。与搭载 BF16 指令的第三代英特尔 至强 可扩展处理器同时使用,可显著提高模型训练和推理性能。
2022-07-10 10:56:19864 综上所述,这个新版本的 OpenVINO 工具包提供了许多好处,不仅优化了用户部署应用程序的体验,还增强了性能参数。它使用户能够开发具有易于部署、更多深度学习模型、更多设备可移植性和更高推理性能且代码更改更少的应用程序。
2022-07-12 10:08:57864 Kit 不仅大大提升了 GPU 集群上多机多卡分布式训练的效率,对于 GPU 上的模型推理也通过集成 NVIDIA TensorRT 带来了显著加速。双方团队就 GPU 推理加速这一话题将进行持续深入的合作,推出定制化的优化方案,为业界客户带来显著的性能收益。
2022-08-31 09:24:071235 腾讯云 TI 平台 TI-ONE 利用 NVIDIA Triton 推理服务器构造高性能推理服务部署平台,使用户能够非常便捷地部署包括 TNN 模型在内的多种深度学习框架下获得的 AI 模型,并且显著提升推理服务的吞吐、提升 GPU 利用率。
2022-09-05 15:33:011419 蚂蚁链 AIoT 团队与 NVIDIA 合作,将量化感知训练(QAT)技术应用于深度学习模型性能优化中,并通过 NVIDIA TensorRT 高性能推理 SDK 进行高效率部署, 通过 INT8 推理, 吞吐量提升了 3 倍, 助力蚂蚁链版权 AI 平台中的模型推理服务大幅降本增效。
2022-09-09 09:53:52872 NVIDIA 发布 NVIDIA DLSS 3--一款由 AI 驱动的性能倍增器,开启 NVIDIA RTX 神经网络渲染游戏和应用的新时代。
2022-09-22 10:36:12880 每个 AI 应用程序都需要强大的推理引擎。无论您是部署图像识别服务、智能虚拟助理还是欺诈检测应用程序,可靠的推理服务器都能提供快速、准确和可扩展的预测,具有低延迟(对单个查询的响应时间较短)和高吞吐量(在给定时间间隔内处理大量查询)。然而,检查所有这些方框可能很难实现,而且成本高昂。
2022-10-11 09:49:22790 
高效的体系结构搜索和部署就绪模型是 NAS 设计方法的关键目标。这意味着几乎不与领域专家进行交互,并且有效地使用集群节点来培训潜在的架构候选。最重要的是,生成的模型已准备好部署。
2022-10-11 10:14:43677 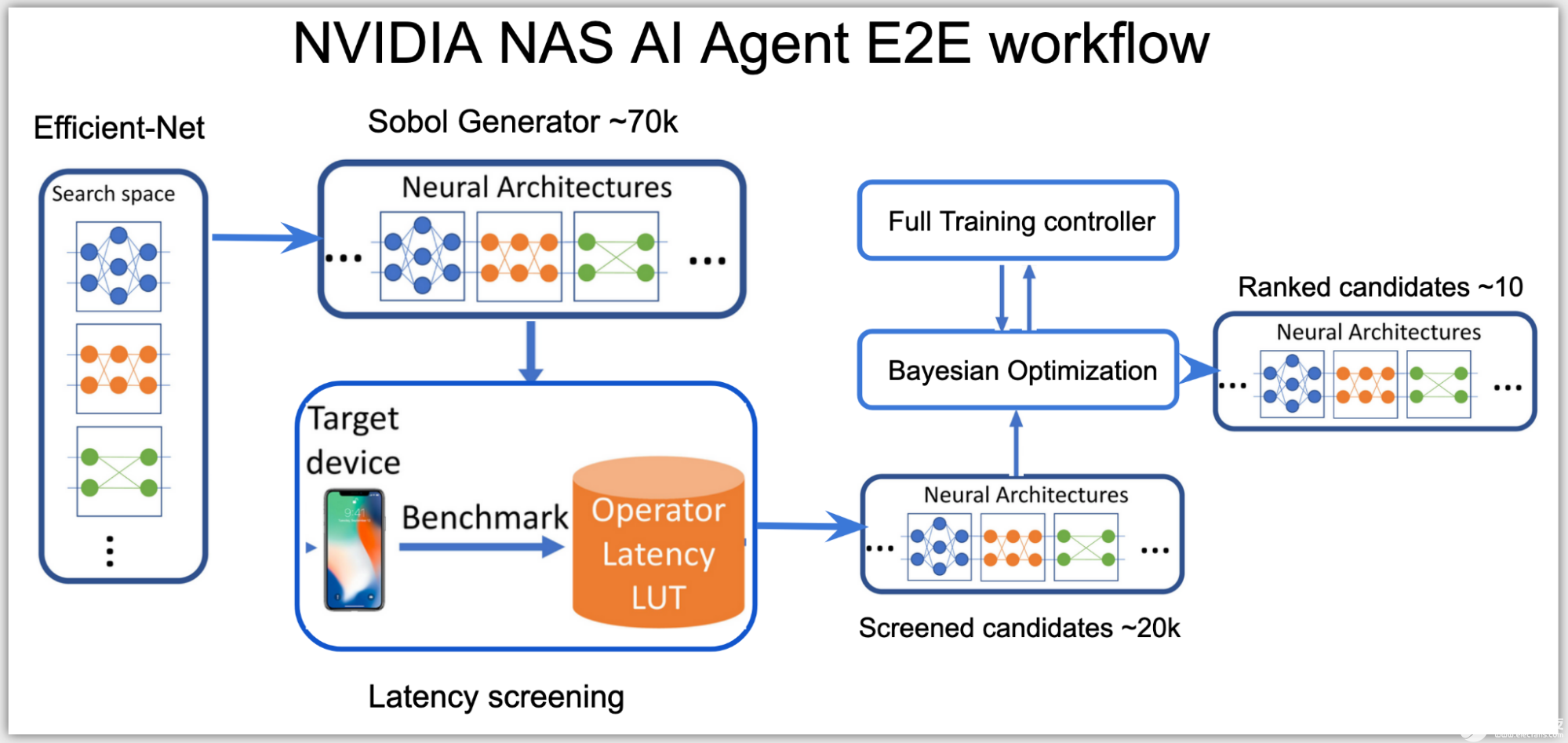
NVIDIA 张量RT 是一个高性能推理平台,对于利用 NVIDIA 张量核心 GPU 的强大功能至关重要。TensorRT 8 是一个具有增强功能的软件开发工具包,旨在提高性能和准确性,以应对边缘和嵌入式设备中发生的越来越多的 AI 推理。它允许对张量流和PyTorch神经网络进行广泛的计算推断。
2022-10-18 09:32:46390 推理识别是人工智能最重要的落地应用,其他与深度学习相关的数据收集、标注、模型训练等工作,都是为了得到更好的最终推理性能与效果。
2022-10-26 09:43:571370 为了解决AI部署落地难题,我们发起了FastDeploy项目。FastDeploy针对产业落地场景中的重要AI模型,将模型API标准化,提供下载即可运行的Demo示例。相比传统推理引擎,做到端到端的推理性能优化。
2022-11-08 14:28:121576 为了解决AI部署落地难题,我们发起了FastDeploy项目。FastDeploy针对产业落地场景中的重要AI模型,将模型API标准化,提供下载即可运行的Demo示例。相比传统推理引擎,做到端到端的推理性能优化。FastDeploy还支持在线(服务化部署)和离线部署形态,满足不同开发者的部署需求。
2022-11-10 10:18:32909 (3D-UNet)、目标物体检测(SSD-ResNet34)、语音识别(RNN-T)、自然语言理解(BERT)以及智能推荐(DLRM)。在MLPerf V2.0推理竞赛中,浪潮AI服务器基于ImageNet数据集在离线场景中运行Resnet50,达到了449,856 samples/s的计算性能,位居世界第一。
2022-11-10 14:43:401197 起初,AI 作图需要几天,再缩减到几十分钟,再到几分钟,出图时间在不断加速,问题是,究竟快到什么程度,才会在专业的美术从业者甚至普通大众之间普及开来?
2022-11-30 10:03:57704 模型,并提供开箱即用的云边端部署体验,实现 AI 模型端到端的推理性能优化。 欢迎广大开发者使用 NVIDIA 与飞桨联合深度适配的 NGC 飞桨容器,在 NVIDIA GPU 上进
2022-12-13 19:50:05909 、NVIDIA 的技术专家将带来 AI Infra 、 推理引擎 相关的专题分享,包括目前各企业面临的模型推理挑战、Triton 的应用及落地的具体方案等,现身说法,干货十足。此外,还有来自
2023-02-15 16:10:05207 了基于L4和L40的NVIDIA推理平台,得益于对全新FP8 精度的支持,其可提供高达4倍的性能提升,将视频和图形处理性能也提升了4倍。NVIDIA L4 Tensor Core G
2023-03-22 14:27:49525 
日 – NVIDIA于今日推出四款推理平台。这些平台针对各种快速兴起的生成式AI应用进行了优化,能够帮助开发人员快速构建用于提供新服务和洞察的AI驱动的专业应用。 这些平台将NVIDIA的全栈推理
2023-03-22 14:48:39256 
日 – NVIDIA 于今日推出四款推理平台。这些平台针对各种快速兴起的生成式 AI 应用进行了优化,能够帮助开发人员快速构建用于提供新服务和洞察的 AI 驱动的专业应用。 这些平台将 NVIDIA
2023-03-23 06:55:02654 的第三方基准测试,MLPerf 仍是衡量 AI 性能的权威标准。自 MLPerf 诞生以来,NVIDIA 的 AI 平台在训练和推理这两个方面一直展现出领先优势,包括最新发布的 MLPerf
2023-04-08 00:30:08389 的多元化,给人工智能(AI)技术在旅游行业的应用带来更多机遇和挑战。例如自然语言处理(NLP)、机器翻译、计算机视觉、搜索排序等 AI 技术的快速发展和日臻成熟,可以为游客提供更便捷的服务和更精准的内容。 作为一站式旅行平台,携程旅行已经将诸多AI 技术应用
2023-06-09 20:30:02333 
AI推理性能对比 / Ampere 从性能对比上,我们可以看出AmpereOne在AI推理负载上的领先,比如在生成式AI和推荐算法上,AmpereOne的单机架性能是AMD EYPC 9654 Genoa的两倍或以上,但两者却有着近乎相同的系统功耗,AmpereOne的优势在此展现得一览无余。
2023-06-13 15:03:51789 
1792个CUDA和56个Tensor内核,使其算力能够达到200TOPS。这使得BOXER-8640AI能够同时在多个视频流中利用颠覆性的转换推理性能。研扬专业设计
2023-03-15 14:26:20426 
使用集成模型在 NVIDIA Triton 推理服务器上为 ML 模型管道提供服务
2023-07-05 16:30:341082 
达沃斯论坛|英特尔王锐:AI驱动工业元宇宙,释放数实融合无穷潜力 英特尔研究院发布全新AI扩散模型,可根据文本提示生成360度全景图 英特尔内部代工模式的最新进展 原文标题:英特尔® AMX 加速AI推理性能,助阿里电商推荐系统成功应对峰值负载
2023-07-08 14:15:03294 
科技赋能千行百业 人民网携手英特尔启动“数智加速度”计划 WAIC 2023:英特尔以技术之力推动边缘人工智能发展,打造数字化未来“芯”时代 英特尔 AMX 加速AI推理性能,助阿里电商推荐系统成功应对峰值负载压力 原文标题:英特尔® AMX 助力百度ERNIE-T
2023-07-14 20:10:05245 
中,网络软、硬件对于端到端推理性能的影响。 在网络评测中,有两类节点:前端节点生成查询,这些查询通过业界标准的网络(如以太网或 InfiniBand 网络)发送到加速节点,由加速器节点进行处理和执行推理。 图 1:单节点封闭测试环境与多节点网络测试环境 图 1 显示了在单个节点上运行的封闭测试环
2023-07-19 19:10:03603 
工智能市场规模在 2023 年将超过 147 亿美元,到 2026年将超过 264 亿美元 1 。 在端到端的 AI 整体应用流程中,AI 推理是其中的关键环节。在 AI 推理的算力设备选择方面,CPU 服务器具备更强的灵活性、敏捷性,能够支持大数据、云计算、虚拟化等多种业务的弹
2023-07-28 19:45:06470 商业 AI 技术创新大赛在北京百度科技园圆满落幕,来自各大高校的 12 支技术团队,分别在“商业转化行为预测”、“AIGC 推理性能优化”两大赛道取得了丰硕的创新成果。 NVIDIA 全球副总裁刘念宁、百度集团副总裁,移动生态商业体系负责人王凤阳、NVIDIA 中国区工程和
2023-08-21 21:05:02388 
这些性能强大的新系统将利用 NVIDIA Omniverse 平台加速高计算密集度的复杂应用,包括 AI 训练和推理、3D 设计和可视化、视频处理、工业数字化等。
2023-08-23 14:20:18224 是高性能的AI推理芯片。该芯片推理性能达到78563 IPS,能效比500 IPS/W。 含光800AI芯片基于RISC-V和阿里自有算法,含光800芯片性能的突破得益于软硬件的协同创新:硬件层面采用自研芯片架构,通过推理加速等技术有效解决芯片性能瓶颈问题;软件层面集成了达摩院先进算法,针对CNN及视
2023-08-31 17:31:241805 英特尔产品在全新MLCommons AI推理性能测试中尽显优势 今日,MLCommons公布针对 60 亿参数大语言模型及计算机视觉与自然语言处理模型GPT-J的 MLPerf推理v3.1 性能基准
2023-09-12 17:54:32200 
从云端到网络边缘,NVIDIA GH200、H100 和 L4 GPU 以及 Jetson Orin 模组在运行生产级 AI 时均展现出卓越性能。 NVIDIA GH200 Grace Hopper
2023-09-12 20:40:04249 从云端到网络边缘,NVIDIA GH200、H100和L4 GPU以及Jetson Orin模组在运行生产级 AI 时均展现出卓越性能。 NVIDIA GH200 Grace
2023-09-13 09:45:40139 
近日,MLCommons公布针对60亿参数大语言模型及计算机视觉与自然语言处理模型GPT-J的MLPerf推理v3.1性能基准测试结果,其中包括英特尔所提交的基于Habana Gaudi 2加速器
2023-09-15 19:35:05303 
的AI推理芯片。该芯片推理性能达到78563 IPS,能效比500 IPS/W。 含光800AI芯片基于RISC-V和阿里自有算法,含光800芯片性能的突破得益于软硬件的协同创新:硬件层面采用自研芯片架构,通过推理加速等技术有效解决芯片性能瓶颈问题;软件层面集成了达摩院先进算法,针对CNN及视觉类算法
2023-10-16 17:29:421021 加利福尼亚州圣克拉拉——Nvidia通过一个名为TensorRT LLM的新开源软件库,将其H100、A100和L4 GPU的大型语言模型(LLM)推理性能提高了一倍。 正如对相同硬件一轮又一轮改进
2023-10-23 16:10:19284 由 CSDN 举办的 NVIDIA AI Inference Day - 大模型推理线上研讨会,将帮助您了解 NVIDIA 开源大型语言模型(LLM)推理加速库 TensorRT-LLM 及其功能
2023-10-26 09:05:02174 NVIDIA 于 2023 年 10 月 19 日公开发布 TensorRT-LLM ,可在 NVIDIA GPU 上加速和优化最新的大语言模型(Large Language Models)的推理性能
2023-10-27 20:05:02478 
上以交互速率运行的 Llama-2-70B 模型。 图 1. 领先的生成式 AI 模型在 Jetson AGX Orin 上的推理性能 如要在 Jetson 上快速测试最新的模型和应用,请使用 Jetson 生成式 AI 实验室提供的教程和资源。
2023-11-07 21:25:01398 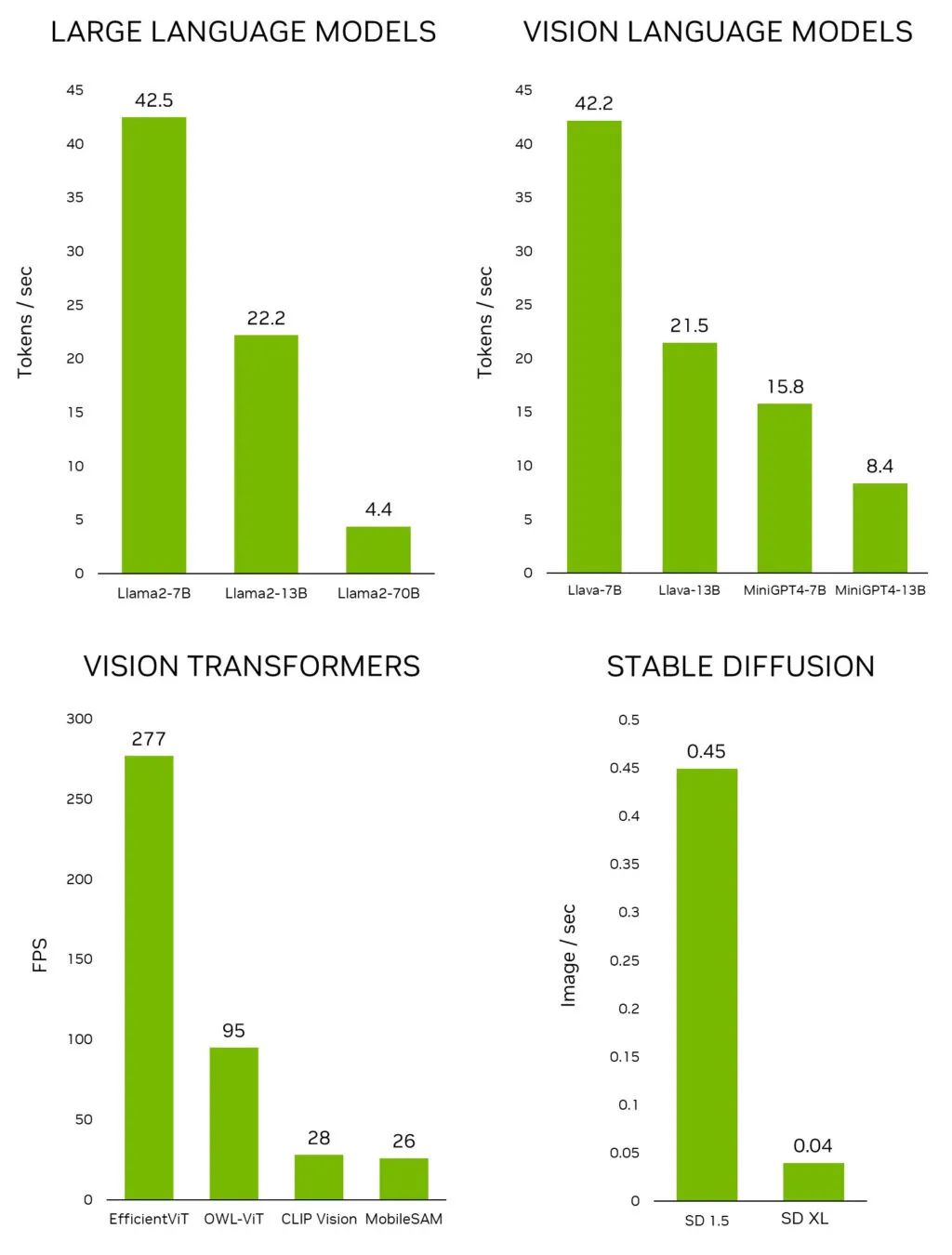
的 Windows PC 和工作站提高生产力带来前所未有的机会。NVIDIA RTX 技术使开发者更轻松地创建 AI 应用,从而改变人们使用计算机的方式。 在微软 Ignite 2023 技术大会上发布的
2023-11-16 21:15:03408 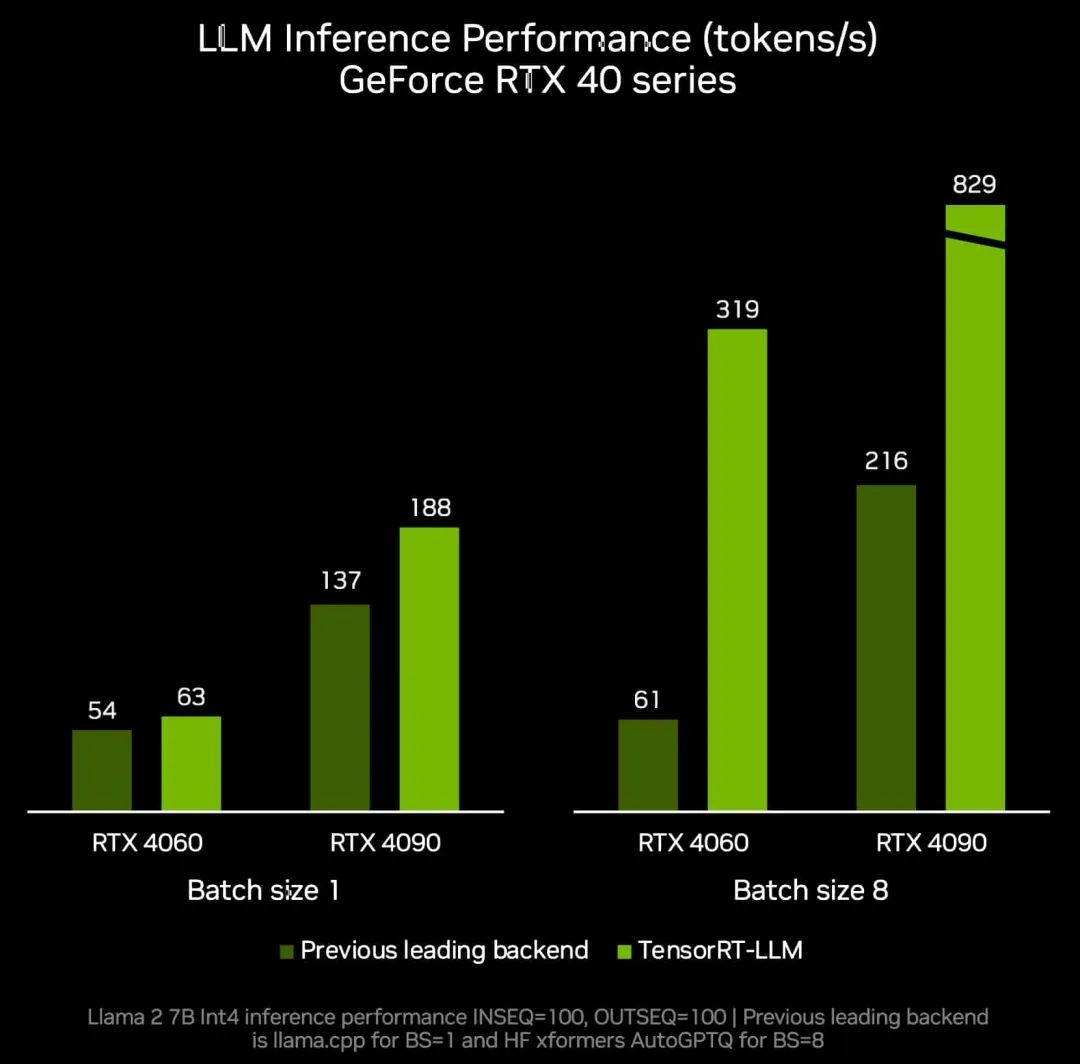
Gridspace 机器学习主管Wonkyum Lee表示:“我们的速度基准测试表明,在 Google Cloud TPU v5e 上训练和运行时,AI 模型的速度提高了 5 倍。我们还看到推理
2023-11-24 10:27:30206 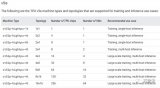
作者: 英特尔公司 沈海豪、罗屿、孟恒宇、董波、林俊 编者按: 只需不到9行代码, 就能在CPU上实现出色的LLM推理性能。 英特尔 Extension for Transformer 创新
2023-12-01 20:40:03552 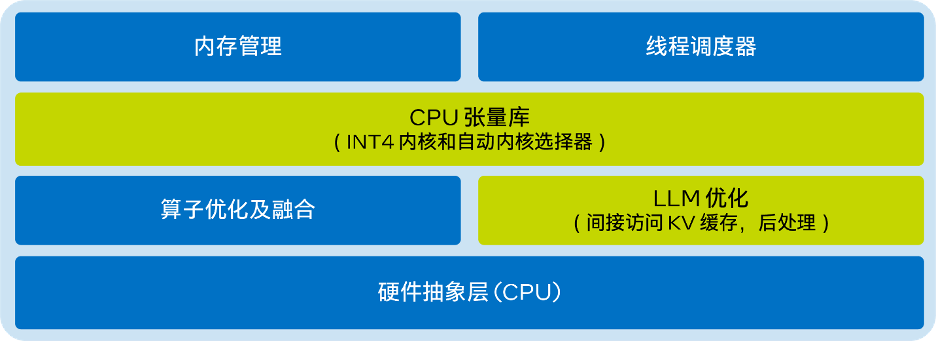
此外,至强可扩展处理器被誉为行业首屈一指的内置AI加速器数据中心处理器,全新第五代产品更能优化参数量高达200亿的大型语言模型,使其推理性能提升42%。眼下,它还是唯一历次刷新MLPerf训练及推理基准测试表现记录并持续进步的CPU。
2023-12-15 11:02:55437 处理器,它来了! 若是用一句话来概括它的特点,那就是——AI味道越发得浓厚。 以训练、推理大模型为例: • 与第四代相比,训练性能提升多达29%,推理性能提升高达42%; • 与第三代相比,AI训练和推理性能提升高达14倍。 什么概念? 现在若
2023-12-22 11:52:06338 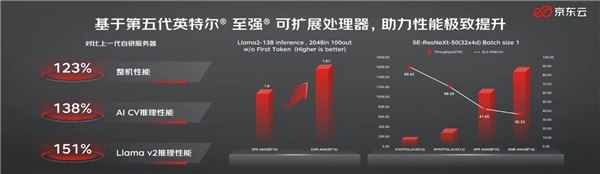
那么,什么是Torch TensorRT呢?Torch是我们大家聚在一起的原因,它是一个端到端的机器学习框架。而TensorRT则是NVIDIA的高性能深度学习推理软件工具包。Torch TensorRT就是这两者的结合。
2024-01-09 16:41:51286 
AI技术应用已经深入到各行各业,特别是云服务提供商将AI能力集成到云服务中,能够更好地满足用户对性能、效率和体验的需求。
2024-01-13 10:46:11520 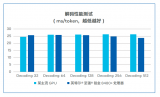
这家云计算巨头的计算机视觉和数据科学服务使用 NVIDIA Triton 推理服务器来加速 AI 预测。
2024-02-29 14:04:40162 具有10TOPS/W能效的新一代AI加速器无需冷却风扇即可提供高达80TOPS的AI推理性能
2024-03-01 10:41:38425 
 电子发烧友App
电子发烧友App









 工商网监
工商网监
评论