作者:Mculover666 1.实验目的 通过例程探索Vivado HLS设计流 用图形用户界面和TCL脚本两种方式创建Vivado HLS项目 用各种HLS指令综合接口 优化Vivado HLS
2020-12-21 16:27:21 3153
3153 的Zynq 7000, 找了一个HLS的教程,就开始了如下入门实验,体验高级语言综合设计IP。Vivado HLS是Xilinx 推出的高层次综合工具,采用C/C++语言进行FPGA设计。HLS提供了一些
2020-10-14 15:17:192881 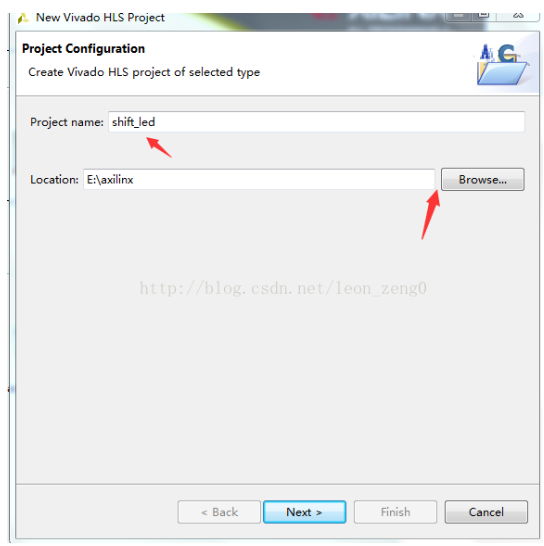
本帖最后由 繎77 于 2013-9-5 16:40 编辑
用vi编辑器写的c程序,执行时出现‘Floating point exception (core dumped
2013-09-04 19:05:40
, Mat 类型的关系和VivadoHLS中图像hls::Mat类型介绍OpenCv中常见的与图像操作有关的数据容器有Mat,cvMat和IplImage,这三种类型都可以代表和显示图像,但是,Mat类型
2021-07-08 08:30:00
SoC器件上快速地加速和集成您的计算机视觉应用。本次研讨会将通过对一个具体案例的流程进行“逐层拆解(Step-by-Step)一个设计案列”的方式,向您介绍如何利用Vivado HLS(高层次综合
2013-12-30 16:09:34
我在Vivado HLS中有以下错误的合成。我试图更新许可证文件但没有成功。请给我一个建议。@E [HLS-72]许可证签出不成功。确保可以访问许可证或通过环境变量指定适当的许可证。 执行
2020-05-20 09:13:21
1.实验目的通过例程探索Vivado HLS设计流用图形用户界面和TCL脚本两种方式创建Vivado HLS项目用各种HLS指令综合接口优化Vivado HLS设计来满足各种约束用不用的指令来探索
2021-11-11 07:09:49
本帖最后由 FindSpace博客 于 2017-4-19 16:57 编辑
在c simulation时,如果使用gcc编译器报错:/home/find/d/fpga/Vivado_HLS
2017-04-19 16:56:06
vivado可以正常使用,但是HLS总是出现图片中的错误。请问该如何解决?谢谢!
2020-08-12 01:36:19
你好!如果我想使用vivado hls来合成具有axi流接口的代码,是否有必须遵循的标准编码风格?
2020-04-21 10:23:47
本人在学习vivado系列软件开发套件的时候遇到以下问题.硬件平台:米尔科技 Z-turn 7020 Board.问题描述:我在Vivado hls 里面写了一个函数int add(int a
2016-01-28 18:40:28
VIVADO DEBUG FLOATING LICENSE
2023-03-30 12:04:13
FLOPS,即每秒浮点运算次数, 是每秒所执行的浮点运算次数(Floating-point operations per second;缩写:FLOPS)的简称,被用来评估电脑效能.FLOPs:注意
2021-07-29 06:48:14
1、HLS最全知识库介绍高层次综合(High-level Synthesis)简称HLS,指的是将高层次语言描述的逻辑结构,自动转换成低抽象级语言描述的电路模型的过程。对于AMD Xilinx而言
2022-09-07 15:21:54
floating-point data to the specified channel.将复数,双精度浮点数据写入指定的通道。请教,这三种发送模式,在具体应用中,都有什么独特的地方,使用时有什么需要考虑的。
2017-11-20 21:24:21
,这些都无法以标准 C++ 的形式来表达。因为在本教程中不涉及使用SystemC进行设计开发,在此我们不多作介绍。1.2HLS设计流程Vivado HLS 的功能简单地来说就是把 C、C++ 或
2020-10-10 16:44:42
【资料分享】Vivado HLS学习资料
2013-11-02 11:21:14
Xilinx而言,Vivado 2019.1之前(包括),HLS工具叫Vivado HLS,之后为了统一将HLS集成到Vitis里了,集成之后增加了一些功能,同时将这部分开源出来了。Vitis
2022-09-09 16:45:27
模拟过程完成没有0错误,但在合成期间显示错误。我无法找到错误。我在合成期间在HLS工具中收到这样的错误“在E中包含的文件:/thaus / fact_L / facoriall
2020-05-21 13:58:09
嗨,大家好,我有一个问题,在VIVADO HLS 2017.1中运行C \ RTL协同仿真。我已成功运行2014和2016版本的代码。任何人都可以告诉我为什么报告NA仅用于间隔
2020-05-22 15:59:30
FPGA的HLS案例开发|基于Kintex-7、Zynq-7045_7100开发板前 言本文主要介绍HLS案例的使用说明,适用开发环境:Windows 7/10 64bit、Xilinx
2021-02-19 18:36:48
你好,我使用Vivado HLS生成了一个IP。从HLS测量的执行和测量的执行时间实际上显着不同。由HLS计算的执行非常小(0.14 ms),但是当我使用AXI计时器在真实场景中测量它时,显示3.20 ms。为什么会有这么多差异? HLS没有告诉实际执行时间?等待回复。问候
2020-05-05 08:01:29
在启动CPU之后,M4内部浮点单元将被默认禁用。有任何CY系统调用来启用或禁用FPU吗?鲍勃 以上来自于百度翻译 以下为原文The M4 internal floating-point unit
2018-12-24 16:23:22
了共享文件夹ofxapp1167 \ xapp1167_vivado \ sw \ share中configure.mk中的OPENCV_VER,但没有区别。../sw/acme”/ bin / sh
2020-03-26 07:59:19
案例的使用说明,适用开发环境: Windows 7/10 64bit、Xilinx Vivado2017.4 、Xilinx Vivado HLS 2017.4 、Xilinx SDK 2017.4
2023-01-01 23:52:54
案例的使用说明,适用开发环境: Windows 7/10 64bit、Xilinx Vivado2017.4 、Xilinx Vivado HLS 2017.4 、Xilinx SDK 2017.4
2023-08-24 14:40:42
说明 374.4.2 PS 端 IP 核测试裸机工程说明 374.4.3 测试说明 39
前 言本文主要介绍 HLS 案例的使用说明,适用开发环境: Windows 7/10 64bit、Xilinx
2023-08-24 14:52:17
说明 374.4.2 PS 端 IP 核测试裸机工程说明 374.4.3 测试说明 39前 言本文主要介绍 HLS 案例的使用说明,适用开发环境: Windows 7/10 64bit、Xilinx
2023-01-01 23:50:04
7/10 64bit、Xilinx Vivado2017.4 、Xilinx Vivado HLS 2017.4 、Xilinx SDK 2017.4。Xilinx Vivado HLS
2023-01-01 23:46:20
7/10 64bit、Xilinx Vivado2017.4 、Xilinx Vivado HLS 2017.4 、Xilinx SDK 2017.4。Xilinx Vivado HLS
2023-08-24 14:54:01
前 言本文主要介绍HLS案例的使用说明,适用开发环境:Windows 7/10 64bit、Xilinx Vivado 2017.4、Xilinx Vivado HLS 2017.4、Xilinx
2021-11-11 09:38:32
是否有可能代表IEEE-754-2008号。在Xilinx上(即没有拆包)??或者是否有一个std方法来解压no。从ieee十进制浮点数到二进制格式??以上来自于谷歌翻译以下为原文
2019-04-26 11:15:07
你好我在vivado hls 2013.2中执行c代码。我使用斯巴达3E作为我的设备我在我的代码中使用了exp,即我必须找到e ^ x。所以虽然合成它给我一个关于库中没有匹配浮点核心的错误。那么它与
2019-03-29 13:03:06
的经验几乎为0,因此我想就如何解决这个问题提出建议。这就是我的想法:1 - 首先,用Vivado HLS转换VHDL中的C代码(我现在有一些经验)2 - 在Vivado HLS中生成IP核(如果我
2020-03-24 08:37:03
你好我正在尝试在vivado HLS中创建一个IP,然后在vivado中使用它每次我运行Export RTL我收到了这个警告警告:[Common 17-204]您的XILINX环境变量未定义。您将
2020-04-03 08:48:23
completly提到xilinx hls网站上提到。请帮助我从过去三天起因为这个问题我无法工作。vivado_HLS_problem.docx 2610 KB
2020-04-09 06:00:49
无法为单个数据类型找到Assembler浮点库IEEE 754。想要任何帮助或链接。 #floating-point #assembler #library以上来自于谷歌翻译以下为原文 Can
2018-12-06 16:16:02
您好我有一个关于vivado hls的问题。RTL是否来自xivix FPGA的vivado hls onyl?我们可以在Design Compiler上使用它进行综合吗?谢谢
2020-04-13 09:12:32
编译器,我试图在float.h中更改FLT_DIG但没有任何改变。 如果有人有线索请帮助我。 提前谢谢了 #floating-point
2019-01-04 15:45:21
您好Xilinx的用户和员工,我们正在考虑购买Zynq 7000用于机器视觉任务。我们没有编程FPGA的经验,并希望使用Vivado HLS来指导和加速我们的工作。关于这种方法的一些问题:您对
2020-03-25 09:04:39
你好,我有一个与switch语句的合成有关的问题。我开始使用Vivado HLS并且我已经创建了一个小的file.cpp,仅用于学习,但是当Vivado HLS合成文件时,我没有得到任何开关语句
2019-11-05 08:21:53
请问Vivado HLS出现这种情况是什么原因呢
2021-06-23 06:13:13
)[ // // Enable the floating-point unit. This must be done here to handle the // case where main() uses
2020-08-26 15:11:40
嗨伙计,在我的PC Vivado设计套件2015.2和SDK 2015.2工作,但只有vivado HLS 2015.2没有打开,这就是为什么我想重新安装Vivado HLS 2015.2。如何下载
2018-12-27 10:57:49
of high-performance 32-/64-bit floating-point digital signal processors. The TMS320C672x
2010-12-06 01:48:37 25
25
The TMS320C67x™ DSPs (including the TMS320C6713B device) compose the floating-point DSP generati
2010-12-06 02:05:2735
The TMS320C67x™ DSPs (including the TMS320C6713B device) compose the floating-point DSP generati
2010-12-06 02:07:2724
The TMS320C67x™ DSPs (including the TMS320C6713B device) compose the floating-point DSP generati
2010-12-06 02:10:4733
The TMS320C67x™ DSPs (including the TMS320C6713B device) compose the floating-point DSP generati
2010-12-06 02:12:3424 The TMS320C67x DSPs are the floating-point DSP family in the TMS320C6000™ DSP platform.
2010-12-07 21:34:5219 for the TMS320C6748Fixed/Floating-Point DSP . For more detailed information, see the TMS320C6748 Fixed/Floating-PointDSP data manual (lit
2010-12-07 21:43:5614 for the . For more detailedinformation, see the TMS320C6746 Fixed/Floating-Point DSP data manual (literature number SPRS591).
2010-12-07 21:59:348 for the TMS320C6743Fixed/Floating-point Digital Signal Processor . For more detailed information, see the TMS320C6743Fixed/Floating-point
2010-12-07 22:07:013 for the . For more detailedinformation, see the TMS320C6742 Fixed/Floating-Point DSP data manual (literature number SPRS587).
2010-12-07 22:10:285 for the TMS320C6748
Fixed/Floating-Point DSP . For more detailed information, see the TMS320C6748 Fixed/Floating-Point
DSP d
2010-12-12 23:47:0426 爱特梅尔推出全新浮点单元(Floating Point Unit)技术 爱特梅尔公司(Atmel Corporation)宣布推出全新浮点单元(Floating Point Unit)技术,用于爱特梅尔32位AVR UC3产品系列。此新技术可使
2010-04-21 17:05:03607 WP409利用Xilinx FPGA打造出高端比特精度和周期精度浮点DSP算法实现方案: High-Level Implementation of Bit- and Cycle-Accurate Floating-Point DSP Algorithms with Xilinx FPGAs
2012-01-26 18:03:0525 Introduction to FPGA Design with Vivado High-Level Synthesis,使用 Vivado 高层次综合 (HLS) 进行 FPGA 设计的简介
2016-01-06 11:32:5565 Comparing Fixed- and Floating-Point DSP。
2016-01-19 14:12:105 Floating Point,好东西,喜欢的朋友可以下载来学习。
2016-02-22 15:04:040 Fixed/Floating-Point DSP . For more detailed information, see the TMS320C6748 Fixed/Floating-Point DSP data manual (literature number: SPRS590).
2016-11-14 16:55:120 介绍如何设计HLS IP,并且在IP Integrator中使用它来作一个设计——这里生成两个HLS blocks的IP,并且在一个FFT(Xilinx IP)的设计中使用他们,最终使用RTL
2017-02-07 17:59:294179 
众所周知 Hackaday.com 网站上聚集着众多极客(Geeker),他们打破传统,标新立异,敢于尝试新的东西,今天这篇文章搜集了这些极客对Xilinx Vivado HLS工具使用经验和心得
2017-02-08 20:01:59550 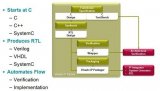
大,我是否能够利用Vivado HLS完成这项要求较高的运算呢? 我开始从软件方面考虑这个转换,我开始关注软件界面。毕竟,HLS创建专用于处理硬件接口的硬件。幸好Vivado HLS支持创建AXI slave的想法,同时工作量较少。 我发现Vivado HLS编码限制相当合理。它支持大多数C + +语言
2017-02-09 02:15:11310 本实验练习使用的设计是实验1并对它进行优化。 步骤1:创建新项目 1.打开Vivado HLS 命令提示符 a.在windows系统中,采用Start>All Programs>Xilinx
2017-02-09 05:07:11411 
14.10 浮点运算 大多数的ARM处理器硬件上并不支持浮点运算。但ARM上提供了以下几个选项来实现浮点运算。 浮点累加协处理器FPA(Floating-Point Accelerator):ARM
2017-10-17 16:48:391 随着无线网络的数据流量和密集度不断增加,所有运营商都面临着非常大的挑战。一套好的数据压缩算法能够帮助运营商节省不少的网络基础设备的开支。使用Xilinx Vivado HLS工具评估开放式无线电设备
2017-11-17 02:25:411267 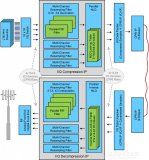
使用Xilinx Vivado HLS(Vivado 高层次综合)工具实现浮点复数QRD矩阵分解并提升开发效率。使用VivadoHLS可以快速、高效地基于FPGA实现各种矩阵分解算法,降低开发者
2017-11-17 17:47:433293 
尽管通常Fixed-Point(定点)比Floating-Point(浮点)算法的FPGA实现要更快,且面积更高效,但往往有时也需要Floating-Point来实现。这是因为Fixed-Point
2017-11-22 15:20:011234 1 Vivado HLS简介 2创建一个Vivado-HLS工程 2.1打开Vivado HLS GUI 2.2创建新工程 在 Welcome Page, 选择Create New Project
2017-12-04 10:07:170 在实际工程中,如何利用好这一工具仍值得考究。本文将介绍使用Vivado HLS时的几个误区。
2018-01-10 14:33:0219813 
本文内容介绍了基于用Vivado-HLS为软件提速,供参考
2018-03-26 16:09:107 Vivado HLS 是 Xilinx 提供的一个工具,是 Vivado Design Suite 的一部分,能把基于 C 的设计 (C、C++ 或 SystemC)转换成在 Xilinx 全可编程芯片上实现用的 RTL 设计文件 (VHDL/Verilog 或 SystemC)。
2018-06-05 10:31:006326 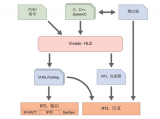
了解如何使用GUI界面创建Vivado HLS项目,编译和执行C,C ++或SystemC算法,将C设计合成到RTL实现,查看报告并了解输出文件。
2018-11-20 06:09:003651 了解如何使用Tcl命令语言以批处理模式运行Vivado HLS并提高工作效率。
该视频演示了如何从现有的Vivado HLS设计轻松创建新的Tcl批处理脚本。
2018-11-20 06:06:002887 尽管 Vivado HLS支持C、C++和System C,但支持力度是不一样的。在v2017.4版本ug871 第56页有如下描述。可见,当设计中如果使用到任意精度的数据类型时,采用C++ 和System C 是可以使用Vivado HLS的调试环境的,但是C 描述的算法却是不可以的。
2019-07-29 11:07:165072 
介绍了如何利用Vivado HLS生成FIR滤波算法的HDL代码,并将代码添加到ISE工程中,经过综合实现布局布线等操作后生成FPGA配置文件,下载到FPGA开发板中,Darren采用的目标板卡是Spartan-3 FPGA。
2019-07-30 17:04:244554 接着开始正文。据观察,HLS的发展呈现愈演愈烈的趋势,随着Xilinx Vivado HLS的推出,intel也快马加鞭的推出了其HLS工具。HLS可以在一定程度上降低FPGA的入门门槛(不用编写
2019-07-31 09:45:176232 
作者:OpenSLee 1、float IP的创建 搜索float双击Floating-point 1 Operation Selection 我们这里选择浮点数的加减法验证
2020-11-13 11:06:533731 
floating-point to fixed-point浮点转定点 14)Conversion from fixed-point to floating-point定点转浮点 15) Conversion between floating-point types浮点类型之间的转换 2、Flo
2020-11-13 15:17:362906 Vivado HLS 2020.1将是Vivado HLS的最后一个版本,取而代之的是VitisHLS。那么两者之间有什么区别呢? Default User Control Settings
2020-11-05 17:43:1637066 本文介绍如何一步一步将设计从SDSoC/Vivado HLS迁移到Vitis平台。
2022-07-25 17:45:483058 
本文介绍如何一步一步将设计从SDSoC/Vivado HLS迁移到Vitis平台。
2021-01-31 08:12:028 本文以浮点数Floating-point IP核将定点数转换为浮点数为例,详细讲解AXI DMA IP核的使用方法。
2022-02-16 16:21:377547 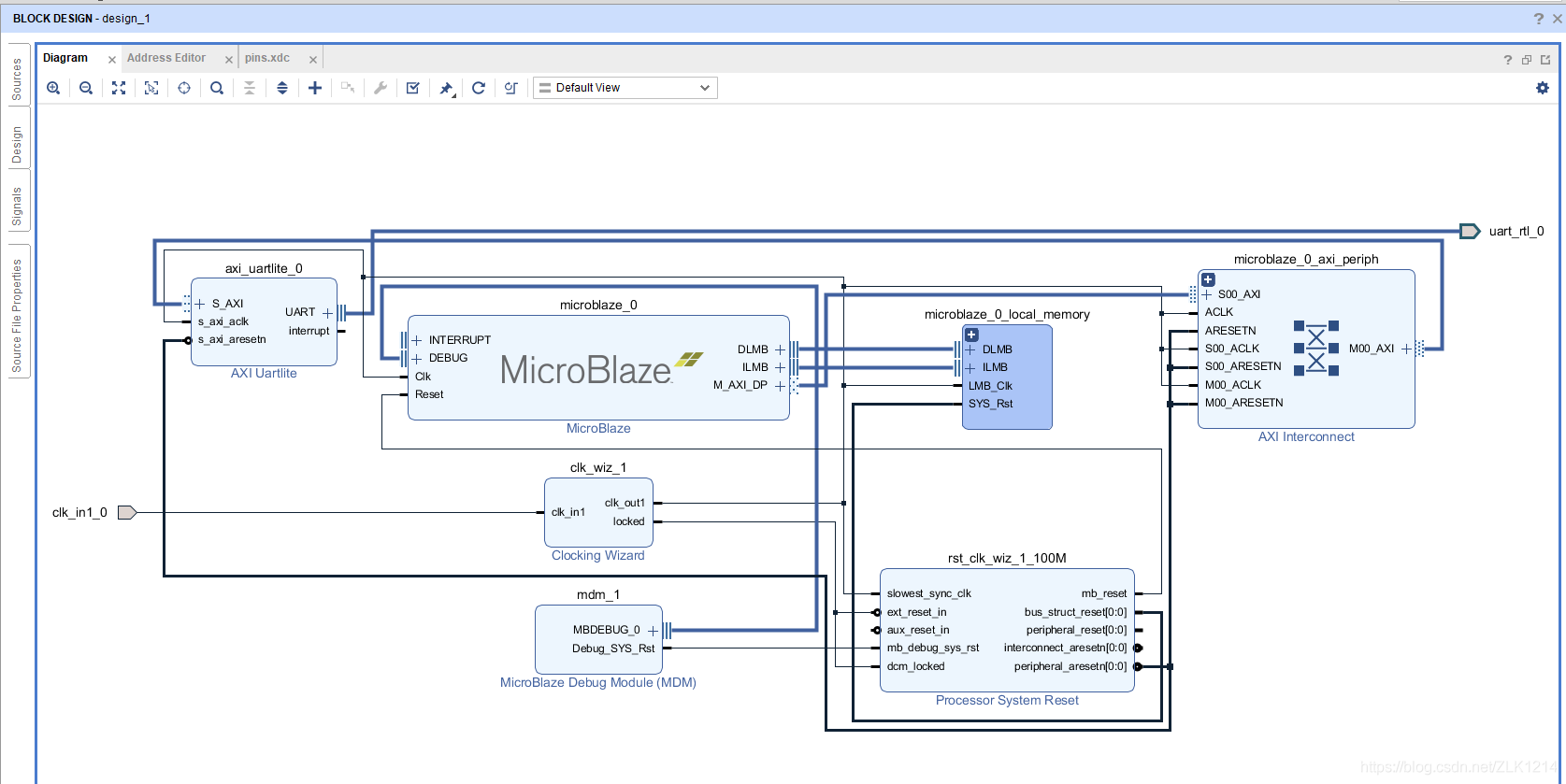
对于AMD Xilinx而言,Vivado 2019.1之前(包括),HLS工具叫Vivado HLS,之后为了统一将HLS集成到Vitis里了,集成之后增加了一些功能,同时将这部分开源出来了。Vitis HLS是Vitis AI重要组成部分,所以我们将重点介绍Vitis HLS。
2022-09-02 09:06:232857 对于AMD Xilinx而言,Vivado 2019.1之前(包括),HLS工具叫Vivado HLS,之后为了统一将HLS集成到Vitis里了,集成之后增加了一些功能,同时将这部分开源出来了。Vitis HLS是Vitis AI重要组成部分,所以我们将重点介绍Vitis HLS。
2023-01-15 11:27:491317 Xilinx平台的Vivado HLS 和 Vitis HLS 使用的 export_ip 命令会无法导出 IP
2023-07-07 14:14:57338 
FLOPS是Floating-point Operations Per Second每秒所执行的浮点运算次数的英文缩写
2023-07-07 14:14:581073 
电子发烧友网站提供《UltraFast Vivado HLS方法指南.pdf》资料免费下载
2023-09-13 11:23:190 电子发烧友网站提供《将VIVADO HLS设计移植到CATAPULT HLS平台.pdf》资料免费下载
2023-09-13 09:12:462
 电子发烧友App
电子发烧友App









 工商网监
工商网监
评论