Python 卷积神经网络(CNN)在图像识别领域具有广泛的应用。通过使用卷积神经网络,我们可以让计算机从图像中学习特征,从而实现对图像的分类、识别和分析等任务。以下是使用 Python 卷积神经网络进行图像识别的基本步骤。
2023-11-20 11:20:33 1468
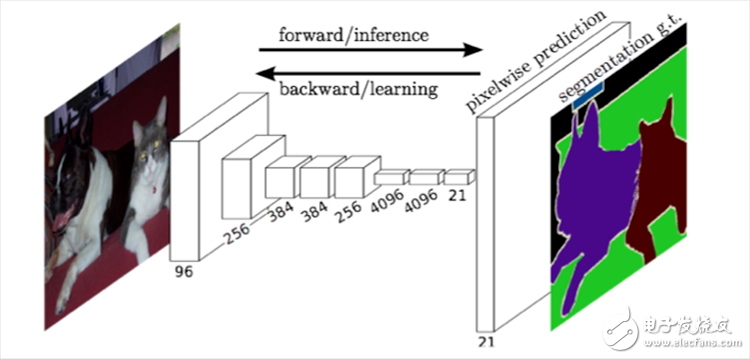
1468 尽管FCN意义重大,在当时来讲效果也相当惊人,但是FCN本身仍然有许多局限。
2024-01-13 15:53:07635 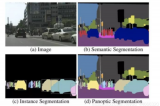
全连接神经网络和卷积神经网络的区别
2019-06-06 14:21:42
卷积神经网络为什么适合图像处理?
2022-09-08 10:23:10
卷积神经网络(CNN)究竟是什么,鉴于神经网络在工程上经历了曲折的历史,您为什么还会在意它呢? 对于这些非常中肯的问题,我们似乎可以给出相对简明的答案。
2019-07-17 07:21:50
神经网络已经广泛应用于图像分类、目标检测、语义分割以及自然语言处理等领域。首先分析了典型卷积神经网络模型为提高其性能增加网络深度以及宽度的模型结构,分析了采用注意力机制进一步提升模型性能的网络结构,然后归纳
2022-08-02 10:39:39
卷积神经网络的层级结构 卷积神经网络的常用框架
2020-12-29 06:16:44
复杂数据中提取特征的强大工具。例如,这包括音频信号或图像中的复杂模式识别。本文讨论了 CNN 相对于经典线性规划的优势。后续文章“训练卷积神经网络:什么是机器学习?——第2部分”将讨论如何训练CNN
2023-02-23 20:11:10
我正在做labview的图像处理,其中有一步是要求进行图像分割,但我编完程序之后老是卡掉,运行不了,求大神帮我看看哪里出错了。
2013-05-21 10:00:03
最近在研究vision assistant,需要识别一个图像,但需要对采集的图像进行图像分割从而提取我们感兴趣的部分,但是目前找不到什么好的方法,我用的是图像掩模,然后手动选取感兴趣的区域,想请问
2016-04-13 20:28:11
限制了感知域的大小。基于存在的这些问题,由Long等人在2015年提出的FCN结构,第一个全卷积神经网络的语义分割模型。我们要了解到的是,FCN是基于VGG和AlexNet网络上进行预训练,然后将最后
2021-12-28 11:03:35
限制了感知域的大小。基于存在的这些问题,由Long等人在2015年提出的FCN结构,第一个全卷积神经网络的语义分割模型。我们要了解到的是,FCN是基于VGG和AlexNet网络上进行预训练,然后将最后
2021-12-28 11:06:01
,得到训练参数2、利用开发板arm与FPGA联合的特性,在arm端实现图像预处理已经卷积核神经网络的池化、激活函数和全连接,在FPGA端实现卷积运算3、对整个系统进行调试。4、在基本实现系统的基础上
2018-12-19 11:37:22
项目名称:基于cortex-m系列核和卷积神经网络算法的图像识别试用计划:本人在图像识别领域有三年多的学习和开发经验,曾利用nesys4ddr的fpga开发板,设计过基于cortex-m3的软核
2019-04-09 14:12:24
可以框选图片中一辆车,然后删除它,然后用背景进行填充。
完整的测试视频发到B站上了,可以访问https://www.bilibili.com/video/BV1kN4y1z7vL/观看。
图像分割
2023-12-26 11:22:49
摘要我们提出了一种基于机器学习的建筑物分割掩模自动正则化和多边形化方法。以图像为输入,首先使用通用完全卷积网络( FCN )预测建筑物分割图,然后使用生成对抗网络( GAN )对建筑物边界进行正则
2021-09-01 07:19:28
OpenCv-C++-深度神经网络(DNN)模块-使用FCN模型实现图像分割
2019-05-28 07:33:35
者则是把整幅图分成许多子图像,每幅图像分别使用不同的阈值进行分割。 本文分析了文献[1]中的算法,并在此基础上提出了一种改进的自适应阈值选取方法,实践证明,这种方法简单、计算量小、速度快、统计准确
2018-08-29 10:53:08
1、基于MLP的快速医学图像分割网络UNeXt 方法概述 之前我们解读过基于 Transformer 的 U-Net变体,近年来一直是领先的医学图像分割方法,但是参数量往往不乐观,计算复杂,推理
2022-09-23 14:53:05
请问,怎么用matlab编程实现将锁个图像进行字符分割,可将图像中的七段数码管单独分割出来并保存?求程序代码。。。。
2013-01-02 19:09:01
图像的亮度矩和阈值分割:简要介绍图像的亮度矩以及在保持图像亮度矩不变的条件下对图像进行两级阉值分割的方法,并对这种方法得到的方程组采用最小=乘法进行求解,以减小噪
2009-10-26 11:22:45 22
22 用matlab编写的采用遗传算法进行图像分割程序:matlab编写的采用遗传算法进行图像分割的一个程序-using Matlab prepared using genetic algorithms for image segmentation of a program。
2010-02-10 10:19:14195 本文讨论了目前基于Gabor滤波器的多通道方法应用于图像分割的现状,给出了Gabor滤波器进行图像分割的原理、过程、实验结果及分析。介绍了图像边缘检测、图像阈值分割的各种算法,
2012-05-04 14:29:1662 摘要: 利用多层感知器神经网络和自组织映射神经网络对球墨铸铁、可锻铸铁和灰铸铁的金相图像进行了分割提取。通过对比以上两种方法分割后的图像质量和定量分析样本图像中的石
2013-03-12 16:27:3325 图像分割—基于图的图像分割图像分割—基于图的图像分割
2015-11-19 16:17:110 特性的分割、边缘分割、指纹图像的分割方法进行了详细的分析比较,分别对这些方法进行了图像仿真,并分析了仿真效率与效果。实验表明,基于Matlab实现的图像分割算法,既简单快速,又能得到很好的分割效果。
2016-01-04 15:10:490 通过图像分割算法在脑图像中自动分割出脑室并计算脑室面积,可以弥补人工诊断的主观性和局限性,为临床诊疗提供了更加客观、全面的决策支持.另外,通过网络API的形式提供服务,复杂的算法运算在服务器端完成
2017-11-16 09:27:322 。 于是在这里记录下所学到的知识,关于CNN 卷积神经网络,需要总结深入的知识有很多: 人工神经网络 ANN 卷积神经网络 CNN 卷积神经网络 CNN - BP算法 卷积神经网络 CNN - LetNet分析 卷积神经网络 CNN - caffe应用 全卷积神经网 FCN 如果对于人工神经网络。
2017-11-16 13:18:4056168 
池化的过程:卷积层是对图像的一个邻域进行卷积得到图像的邻域特征,亚采样层(池化层)就是使用pooling技术将小邻域内的特征点整合得到新的特征。在完成卷积特征提取之后,对于每一个隐藏单元,它都提取
2017-11-16 16:57:014457 B型心脏超声图像分割是计算心功能参数前重要的一步。针对超声图像的低分辨率影响分割精度及基于模型的分割算法需要大样本训练集的问题,结合B型心脏超声图像的先验知识,提出了一种基于像素聚类进行图像分割
2017-12-06 16:44:110 针对图像自动标注中因人工选择特征而导致信息缺失的缺点,提出使用卷积神经网络对样本进行自主特征学习。为了适应图像自动标注的多标签学习的特点以及提高对低频词汇的召回率,首先改进卷积神经网络的损失函数
2017-12-07 14:30:504 邻近区域未充分用到全局信息和结构信息。故考虑基于像素点引入全卷积网络(FCN),以ESAR卫星图像为样本,基于像素点级别构建卷积网络进行训练,得到各像素的初始类别分类概率。为了考虑全局像素类别的影响后接CRF-循环神经网络( CRF-RNN),利用
2017-12-08 14:58:482 图像超分辨率一直是底层视觉领域的研究热点。现有基于卷积神经网络的方法直接利用传统网络模型,未对图像超分辨率属于回归问题这一本质进行优化,其网络学习能力较弱,训练时间较长,重建图像的质量仍有提升
2017-12-15 10:41:082 空气中的尘埃、污染物及气溶胶粒子的存在严重影响了大气预测的有效性,毫米波雷达云图的有效分割成为了解决这一问题的关键,本文提出了一种基于超像素分析的全卷积神经网路FCN和深度卷积神经网络CNN
2017-12-15 16:44:520 图像分割的研究多年来一直受到人们的高度重视,至今提出了各种类型的分割算法。Pal把图像分割算法分成了6类:阈值分割,像素分割、深度图像分割、彩色图像分割,边缘检测和基于模糊集的方法。但是,该方法
2017-12-19 09:29:3810131 
图像分割至今尚无通用的自身理论。随着各学科许多新理论和新方法的提出,出现了许多与一些特定理论、方法相结合的图像分割方法。特征空间聚类法进行图像分割是将图像空间中的像素用对应的特征空间点表示,根据它们在特征空间的聚集对特征空间进行分割
2017-12-19 15:00:3040227 
本文详细介绍了图像分割的基本方法有:基于边缘的图像分割方法、阈值分割方法、区域分割方法、基于图论的分割方法、基于能量泛函的分割方法、基于聚类的分割方法等。图像分割指的是根据灰度、颜色、纹理和形状
2017-12-20 11:06:04108008 
的方法、基于像素聚类的方法和语义分割方法这3种类型并分别加以介绍对每类方法所包含的典型算法,尤其是最近几年利用深度网络技术的语义图像分割方法的基本思想、优缺点进行了分析、对比和总结.介绍了图像分割常用的基准
2018-01-02 16:52:412 最近进行语义分割的结构大多用的是卷积神经网络(CNN),它首先会给每个像素分配最初的类别标签。卷积层可以有效地捕捉图像的局部特征,同时将这样的图层分层嵌入,CNN尝试提取更宽广的结构。随着越来越多的卷积层捕捉到越来越复杂的图像特征,一个卷积神经网络可以将图像中的内容编码成紧凑的表示。
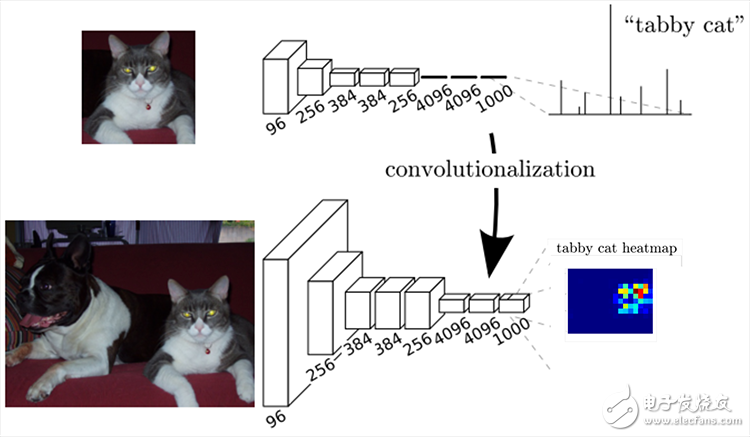
2018-05-25 10:09:165818 我们将当前分类网络(AlexNet, VGG net 和 GoogLeNet)修改为全卷积网络,通过对分割任务进行微调,将它们学习的表征转移到网络中。然后,我们定义了一种新架构,它将深的、粗糙的网络层语义信息和浅的、精细的网络层的表层信息结合起来,来生成精确的分割。
2018-06-03 09:53:56105065 卷积神经网络的特点是逐层提取特征,第一层提取的特征较为低级,第二层在第一层的基础上继续提取更高级别的特征,同样,第三层在第二层的基础上提取的特征也更为复杂。越高级的特征越能体现出图像的类别属性,卷积神经网络正是通过逐层卷积的方式提取图像的优良特征。
2018-07-04 08:59:409539 
同一对象。作者将沿着该领域的研究脉络,说明如何用卷积神经网络处理语义图像分割的任务。 更具体地讲,语义图像分割的目标在于标记图片中每一个像素,并将每一个像素与其表示的类别对应起来。因为会预测图像中的每一个像素,
2018-09-17 15:21:01421 更具体地讲,语义图像分割的目标在于标记图片中每一个像素,并将每一个像素与其表示的类别对应起来。因为会预测图像中的每一个像素,所以一般将这样的任务称为密集预测。
2018-10-15 09:51:002939 Networks for Semantic Segmentation》在图像语义分割挖了一个坑,于是无穷无尽的人往坑里面跳。 全卷积网络 Fully Convolutional Networks CNN
2018-09-26 17:22:02491 CNN能够对图片进行分类,可是怎么样才能识别图片中特定部分的物体,在2015年之前还是一个世界难题。神经网络大神Jonathan Long发表了《Fully Convolutional
2018-10-11 11:57:462124 仍以VGG为例,由于前面采样部分过大,有时候会导致后面进行反向卷积操作得到的结果分辨率较低,会出现细节丢失等问题。为此,FCN的解决方法是叠加第三、四、五层池化层的特征,以生成更精准的边界分割。
2018-10-31 08:53:3912465 在许多疾病的病理学诊断中,细胞核的形状、特征的变化是病变发生与否的重要依据,利用计算机智能分割出病理组织切片中的细胞核能为疾病诊断提供更多的参考。本研究将卷积神经网络应用在乳腺癌病理组织切片图像
2018-11-14 17:34:056 为了在不增加较多计算量的前提下,提高卷积网络模型用于图像分类的正确率,提出了一种基于复杂网络模型描述的图像深度卷积分类方法。首先,对图像进行复杂网络描述,得到不同阈值下的复杂网络模型度矩阵;然后
2018-12-24 16:40:234 针对人脸识别过程中人脸图像质量较低造成的低识别率问题,提出了一种基于卷积神经网络的人脸图像质量评价模型。首先建立一个8层的卷积神经网络模型,提取人脸图像质量的深层语义信息;然后在无约東环境下收集人脸
2019-03-29 14:45:436 卷积层中。现在取出输出,将它扔进一个黑盒子里然后再出现原始图像。这个黑盒子进行反卷积。它是卷积层的数学逆。
2019-04-19 16:48:323658 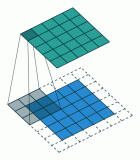
形成更快,更强大的语义分割编码器-解码器网络。DeepLabv3+是一种非常先进的基于深度学习的图像语义分割方法,可对物体进行像素级分割。本文将使用labelme图像标注工具制造自己的数据集,并使用DeepLabv3+训练自己的数据集,具体包括:数据集标注、数据集格式转换、修改程序文
2019-10-24 08:00:0011 为了避免上述问题,来自中科院自动化所、北京中医药大学的研究者们提出一个执行图像语义分割任务的图模型 Graph-FCN,该模型由全卷积网络(FCN)进行初始化。
2020-05-13 15:21:446734 针对在传统机器学习方法下单幅图像深度估计效果差、深度值获取不准确的问题,提出了一种基于多孔卷积神经网络(ACNN)的深度估计模型。首先,利用卷积神经网络(CNN)逐层提取原始图像的特征图;其次,利用
2020-09-29 16:20:005 分割任务论文集与各方实现:[链接]pytorch model zoo:[链接]gluon model zoo:[链接]SOTA Leaderboard:[链接]
2020-12-10 19:24:471336 OpenCV DNN模块支持的图像语义分割网络FCN是基于VGG16作为基础网络,运行速度很慢,无法做到实时语义分割。2016年提出的ENet实时语义分...
2020-12-15 00:18:15324 篇博客中,我们展示了我们在韦洛尔理工学院进行的研究。我们使用了一个基于变分推理技术的编码解码架构来分割脑肿瘤图像。我们比较了U-Net、V-Net和FCN等不同的主干架构作为编码器的条件分布采样数据。我们使用Dice相似系数(
2020-12-25 11:34:391555 
U-Net是一种卷积神经网络,最初是为分割生物医学图像而开发的。当它被可视化的时候,它的架构看起来像字母U,因此被命名为U-Net。其体系结构由两部分组成,左侧为收缩路径,右侧为扩展路径。收缩路径的目的是获取上下文,而扩展路径的作用是帮助精确定位。
2020-12-28 14:22:512259 提岀一种利用卷积神经网络的端到端岩心FIB-SEM图像分割算法。结合光流法与分水岭分割图像标注法构建岩心FB-SEM数据集,联合 Resnet50残差网络、通道和空间注意力机制提取特征信息,采用改进的特征金字塔注意力模块提取多尺度特征,利用亚像素卷
2021-03-11 17:35:446 为提高岀租车市场管理和运营效率以及实现岀租车效益最大化,在地图栅格化的基础上,提出一种融合ⅤGG网络与全卷积网络(FCN)的出租车多区域订单预测模型。将出租车轨迹数据转换为订单图像,去除VGG网络
2021-03-16 14:31:4414 随着深度学习技术的快速发展及其在语义分割领域的广泛应用,语义分割效果得到显著提升。对基于深度神经网络的图像语义分割方法进行分析与总结,根据网络训练方式的不同,将现有的图像语义分割分为全监督学习图像
2021-03-19 14:14:0621 针对深度学习在图像识别任务中过分依赖标注数据的问题,提岀一种基于特征交换的卷积神经网络(CNN)图像分类算法。结合CNN的特征提取方式与全卷积神经网络的像素位置预测功能,将CNN卷积层提取出的特征
2021-03-22 14:59:3427 喉白斑属于癌前组织病变,准确检测该病灶对癌变预防和病变治疗至关重要,但喉镜图像中病灶边界模糊且表面反光导致其不易分割。为此,提出一种基于U-Net的多尺度循环卷积神经网络(MRU-Net)进行
2021-03-24 11:14:505 在目前的文献中主要利用两种技术成功地解决了医学图像的分割问题,一种是利用全卷积网络(FCN),另一种是基于U-Net的技术。FCN体系结构的主要特点是在最后没有使用已成功用于图像分类问题的全连接层。另一方面,U-Net使用一种编码器-解码器架构,在编码器中有池化层,在解码器中有上采样层。
2021-03-29 13:46:101677 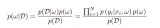
基于深度学习的图像融合技术易丢失网络浅层特征信息,难以实现图像的精准识别。提出一种利用全卷积神经网络(FCN)提取特征的红外与可见光图像融合方法。采用非下采样剪切波变换(NSsT)对源图像进行多尺度
2021-03-30 10:32:286 对应用于图像语义分割的几种深度神经网络模型进行简单介绍,接着详细阐述了现有主流的基于深度神经网络的图像语义分割方法,依据实现技术的区别对图像语义分割方法进行分类,并对每类方法中代表性算法的技术特点、优势和
2021-04-02 13:59:4611 环视鱼眼图像具有目标形变大和图像失真的缺点,导致传统网络结构在对鱼眼图像进行目标检测时效果不佳。为解决环视鱼眼图像中由于目标几何畸变而导致的目标检测难度大的问题,提出一种基于可变形卷积网络
2021-04-27 16:37:044 度差等问题。针对上述问题,文中提出了一种基于密集卷积生成对抗网络的图像修复算法。该算法采用生成对抗网络作为图像修复的基本框架。首先,利用密集卷积块构建具有编解码结枃的生成网络,不但加强了图像特征的提取,提高
2021-05-13 14:39:5215 利用卷积神经网络(CNN)进行医学图像分割时,通常将分割问题抽象为特征表示和参数优化问题,但在上采样和下采样过程中容易丢失特征信息,导致分割效果不理想。设计包含三级特征表示层和特征聚合模块的深度特征
2021-05-13 16:39:551 注意力网络的图像自动分割算法。将编码器-解码器全卷积神经网络的基础结构与密集连接网络相结合,以充分提取每一层的特征,在网络的解码器端引入注意力门模圢ˆ对不必要的特征进行抑制,提高视网膜血管图像的分割精度。在
2021-05-24 15:45:4911 在利用卷积神经网络分割肝脏边界较模糊的影像数据时容易丢失位置信息,导致分割精度较低。针对该问题,提出一种基于分水岭修正与U-Net模型相结合的肝脏图像自动分割算法。利用U-Net分层学习图像特征
2021-05-27 15:17:352 式的全卷积神经网络模型 HC-CFCN。利用第1级网络实现肝脏轮廓的粗略分割,并将其分割结果与原始CT图像、肝脏能量图共同作为第2级网络的输入,优化分割结果。在LiTS数据集上的实验结果表明,与U-NetFCN+3DCRF和V-Net模型相比,HC-CFCN模型的分割精
2021-06-02 17:11:583 为了提高医学图像分割的精确性和鲁棒性,提岀了一种基于改进卷积神经网络的医学图像分割方法。首先采用卷积神经网络对冠状面、矢状面以及横断面三个视图下的2D切片序列进行分割,然后将三个视图下的分割结果进行
2021-06-03 16:23:386 语义分割任务是对图像中的物体按照类别进行像素级别的预测,其难点在于在保留足够空间信息的同时获取足够的上下文信息。为解决这一问题,文中提出了全局双边网络语义分割算法。该算法将大尺度卷积核融入
2021-06-16 15:20:2216 在采用深度学习进行图像分类时,为减少下采样导致的空间信息损失,往往采用膨胀卷积代替下采样,但尚未有文献研究膨胀卷积作用于不同网络层的性能差异。文中进行了大量图像分类实验,找到了适宜膨胀卷积作用的最佳
2021-06-16 15:23:4114 ,对R-FCN模型的特征提取网络、区域推荐网络、位置敏感池化层和分类回归层进行了分析与改进,提出了增强区域全卷积网络用于单帧目标检测,并针对现在盲目多次尝试取最优训练结果的训练方法,提出了一种基于剪枝的网络模型训练
2021-06-21 14:19:3412 该项研究采用了基于多序列的3D卷积神经网络模型,由数坤科技自主研发,用于肝脏MR图像的精准分割。
2022-04-02 16:06:113522 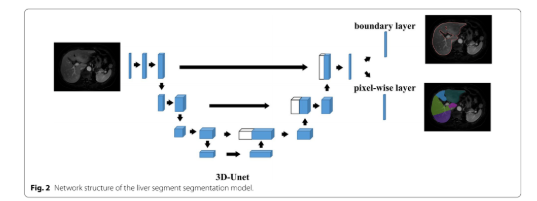
卷积神经网络是一种深度学习网络,主要用于识别图像和对其进行分类,以及识别图像中的对象。
2022-05-13 10:26:471992 UNet及其最新的扩展如TransUNet是近年来领先的医学图像分割方法。然而,由于这些网络参数多、计算复杂、使用速度慢,因此不能有效地用于即时应用中的快速图像分割。
2022-09-27 15:12:092407 以卷积结构为主,搭建起来的深度网络(一般都指深层结构的)
CNN目前在很多很多研究领域取得了巨大的成功,例如: 语音识别,图像识别,图像分割,自然语言处理等。对于大型图像处理有出色表现。
一般将图片作为网络的输入,自动提取特征,并且对图片的变形(平移,比例缩放)等具有高度不变形
2023-02-09 14:34:382048 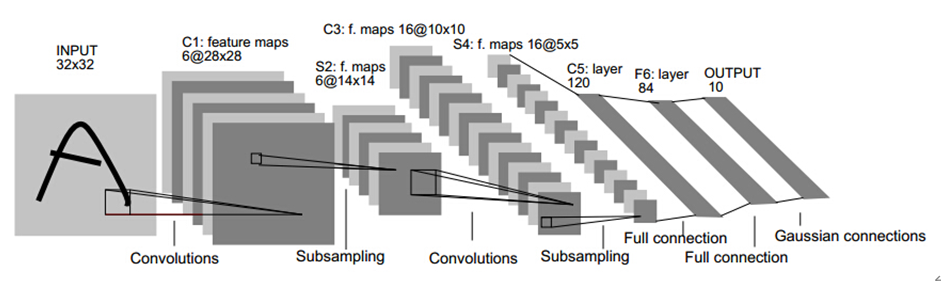
语义分割是区分同类物体的分割任务,实例分割是区分不同实例的分割任务,而全景分割则同时达到这两个目标。全景分割既可以区分彼此相关的物体,也可以区分它们在图像中的位置,这使其非常适合对图像中所有类别的目标进行分割。
2023-05-17 14:44:24810 
在 SageMaker Studio Lab 中打开笔记本
如第 14.9 节所述,语义分割在像素级别对图像进行分类。全卷积网络 (FCN) 使用卷积神经网络将图像像素转换为像素类( Long et
2023-06-05 15:44:38291 
人体分割识别图像技术是一种将人体从图像中分割出来,并对人体进行识别和特征提取的技术。该技术主要利用计算机视觉和图像处理算法对人体图像进行预处理、分割、特征提取和识别等操作,以实现自动化的身份认证
2023-06-15 17:44:49635 DerrickMwiti在一篇文章中,就什么是图像分割、图像分割架构、图像分割损失函数以及图像分割工具和框架等问题进行了讨论,让我们一探究竟吧。什么是图像分割?顾名思义,这是将一个图像
2023-05-16 09:21:44570 
摘要:针对复杂环境下人脸图像美感分类准确率低的问题,给出一种适用于人脸图像美感分类的网络模型F-Net。该模型以LeNet-5为基础网络,使用卷积层提取复杂背景下的人脸图像特征,优化网络模型
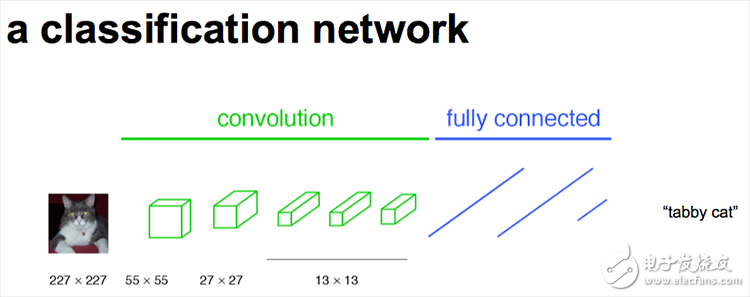
2023-07-19 14:38:250 Learning)的应用,通过运用多层卷积神经网络结构,可以自动地进行特征提取和学习,进而实现图像分类、物体识别、目标检测、语音识别和自然语言翻译等任务。 卷积神经网络的结构包括:输入层、卷积层、激活函数、池化层和全连接层。 在CNN中,输入层通常是代表图像的矩阵或向量,而卷积层是卷积神
2023-08-17 16:30:35804 图像分割(Image Segmentation)是计算机视觉领域中的一项重要基础技术,是图像理解中的重要一环。前端时间,数据科学家Derrick Mwiti在一篇文章中,就什么是图像分割、图像分割架构、图像分割损失函数以及图像分割工具和框架等问题进行了讨论,让我们一探究竟吧。
2023-08-18 10:34:042073 
卷积神经网络概述 卷积神经网络的特点 cnn卷积神经网络的优点 卷积神经网络(Convolutional neural network,CNN)是一种基于深度学习技术的神经网络,由于其出色的性能
2023-08-21 16:41:481659 为多层卷积层、池化层和全连接层。CNN模型通过训练识别并学习高度复杂的图像模式,对于识别物体和进行图像分类等任务有着非常优越的表现。本文将会详细介绍卷积神经网络如何识别图像,主要包括以下几个方面: 1. 卷积神经网络的基本结构和原理 2. 卷积神经网络模型的训练过程 3.
2023-08-21 16:49:271284 在不同领域的应用。 1.图像识别 卷积神经网络最早应用在图像识别领域。其核心思想是通过多层滤波器来提取图像的特征。卷积层主要包括卷积核、填充和步幅。卷积核通过滑动窗口的方式在输入图像上进行卷积运算,生成特征图。填充可以用来控
2023-08-21 16:49:292024 是一种基于图像处理的神经网络,它模仿人类视觉结构中的神经元组成,对图像进行处理和学习。在图像处理中,通常将图像看作是二维矩阵,即每个像素点都有其对应的坐标和像素值。卷积神经网络采用卷积操作实现图像的特征提取,具有“局部感知”的特点。 从直觉上理解,卷积神
2023-08-21 16:49:323045 中最重要的神经网络之一。它是一种由多个卷积层和池化层(也可称为下采样层)组成的神经网络。CNN 的基本思想是以图像为输入,通过网络的卷积、下采样和全连接等多个层次的处理,将图像的高层抽象特征提取出来,从而完成对图像的识别、分类等任务。 CNN 的基本结构包括输入层、卷积层、
2023-08-21 16:49:391127 卷积神经网络基本结构 卷积神经网络主要包括什么 卷积神经网络(Convolutional Neural Network,简称CNN)是一种深度学习模型,广泛用于图像识别、自然语言处理、语音识别等领域
2023-08-21 16:57:193553 卷积神经网络层级结构 卷积神经网络的卷积层讲解 卷积神经网络(Convolutional Neural Network,CNN)是一种基于深度学习的神经网络模型,在许多视觉相关的任务中表现出色,如图像
2023-08-21 16:49:423757 的深度学习算法。CNN模型最早被提出是为了处理图像,其模型结构中包含卷积层、池化层和全连接层等关键技术,经过多个卷积层和池化层的处理,CNN可以提取出图像中的特征信息,从而对图像进行分类。 一、卷积神经网络算法 卷积神经网络算法最早起源于图像处理领域。它是一种深
2023-08-21 16:49:461229 卷积神经网络算法是机器算法吗 卷积神经网络算法是机器算法的一种,它通常被用于图像、语音、文本等数据的处理和分类。随着深度学习的兴起,卷积神经网络逐渐成为了图像、语音等领域中最热门的算法之一。 卷积
2023-08-21 16:49:48437 图像识别卷积神经网络模型 随着计算机技术的快速发展和深度学习的迅速普及,图像识别卷积神经网络模型已经成为当今最受欢迎和广泛使用的模型之一。卷积神经网络(Convolutional Neural
2023-08-21 17:11:45486 卷积神经网络模型的优缺点 卷积神经网络(Convolutional Neural Network,CNN)是一种从图像、视频、声音和一系列多维信号中进行学习的深度学习模型。它在计算机视觉、语音识别
2023-08-21 17:15:191881
 电子发烧友App
电子发烧友App









 工商网监
工商网监
评论