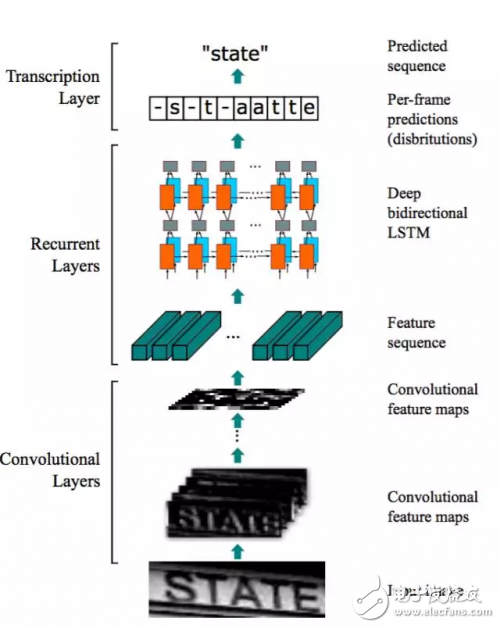
LabVIEW可以实现深度学习嘛,今天我们一起来看看使用LabVIEW 实现物体识别、图像分割、文字识别、人脸识别等深度视觉
2023-08-11 16:02:21 758
758 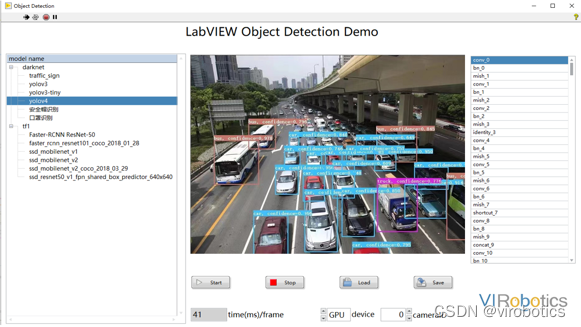
成为目前计算机视觉、模式识别、人工智能等领域最为重要的支撑技术之一。在此报告中,我将简要回顾深度学习的主要技术及其在图像识别、文字识别等方面一些最新研究进展,介绍基于Path Signature及深度
2017-03-22 17:16:00
为了促进业内生态环境良好发展,帮助开发者更好的专注于自己的产品。想让产品实现OCR图像智能字符识别技术,看此帖!楼主吐血为大家找到一个集身份证识别,驾驶证识别,行驶证识别,银行卡识别,文档识别
2015-09-25 13:48:03
;最近需要做一个OCR文字识别的自动测试,之前基本没有接触过图像处理的相关概念,对于纯数学上的算法目前也只是大致在看。 我需要识别的图片情况如下,准备是要用Labview 的VISION模块完成的,现在
2015-05-04 15:07:41
移动端车牌识别,OCR光学字符识别技术
2019-06-04 15:55:26
将OCR 集成到手机系统可为手机带来以下的功能扩张:- 以文字搜索手机内图像 [可自动为图像建立 OCR文字索引]- 取缔键盘或语音输入- 自动完成身份证,信用卡内容输入 [详见苹果 iOS 8]等
2015-01-16 14:31:03
微信公众账号试水商业化的消息近日引爆自媒体圈。厦门云脉公司把多年对OCR各种产品的研究成果集成于云脉OCR微信公众号中。云脉OCR公众号是首个OCR技术识别类微信公众服务号,集成了名片、文档
2014-09-09 18:11:32
OCR移动端车牌识别SDK:打造优质APP
2019-02-28 10:21:35
想要识别这个PH计上的数字,有下面的图片训练后,还是不能识别,大神们OCR训练有什么技巧吗,怎样数字和小数点都能识别啊,我现在只能识别数字,是需要把图片处理下吗?
2017-07-07 17:26:40
AUTOSAR架构深度解析本文转载于:AUTOSAR架构深度解析AUTOSAR的分层式设计,用于支持完整的软件和硬件模块的独立性(Independence),中间RTE(Runtime Environment)作为虚拟功能...
2021-07-28 07:02:13
AUTOSAR架构深度解析本文转载于:AUTOSAR架构深度解析目录AUTOSAR架构深度解析AUTOSAR分层结构及应用软件层功能应用软件层虚拟功能总线VFB及运行环境RTE基础软件层(BSW)层
2021-07-28 07:40:15
C语言深度解析,本资料来源于网络,对C语言的学习有很大的帮助,有着较为深刻的解析,可能会对读者有一定的帮助。
2023-09-28 07:00:01
I2C通信设计深度解析
2012-08-12 21:31:58
本人最近在做ocr识别,由于刚接触这个软件,因此处理起来困难重重,用VISION Assitant 做的时候,做了很多次train,各个角度都试过了,最后还是不行,识别的时候都是问号,不知道怎么回事,望大神帮助,小女子在此感谢大家。
2017-07-23 20:05:27
LabVIEW 使用OCR库 识别数码管字符。字符库只训练了附件中的图片,如果需要其他的字符,可在abc字符库的基础上进行训练。
2020-11-16 17:57:22
在实际应用中进行OCR识别时,字符的位置以及角度是经常变化的,怎么利用LabVIEW对彩色图像进行灰度处理以及定位识别?这里图一是彩色照片、图二是黑白照片、图三是OCR识别的样例程序,求OCR定位识别的LabView程序,在线急
2020-11-18 15:18:34
OCR Training.exe应用程序的目录位置,通过帮助了解调用它的命令格式,如图:Labview安装在哪个盘就去哪个盘找,找到后可以将Utility文件夹整个复制到你常用用的函数文件中方便后续
2020-08-16 17:36:58
1. 简介Tesseract(Apache 2.0 License)是一个可以进行图像OCR识别的C++库,可以跨平台运行 。本样例基于Tesseract库进行适配,使其可以运行在OpenAtom
2022-11-15 12:09:50
对他们彻底说拜拜,它的名字是 ddddocr 带带弟弟 OCR 通用验证码识别 SDK 免费开源版。 安装将自动安装符合自己电脑环境的最新 ddddocr。Python 环境需要小于等于 3.9
2022-03-30 17:26:25
你好,我最近在用NI视觉助手做这么一个工作,自动识别一个字符并计算中心点到某一条已知线段的距离(即求点到直线的距离),我想请教一下,在OCR识别出字符后,给出的结果为:匹配分数,红色框到绿色框左边
2016-06-20 22:28:38
GetTextObject-------------------用于获取字符分割后的目标GetTextResult--------------------用于获取字符识别结果以下动图:halcon自带ocr字库能识别不同类型的工业文字,如果识别效果
2020-07-26 01:36:28
翻译成计算机文字的过程;即,针对印刷体字符,采用光学的方式将纸质文档中的文字转换成为黑白点阵的图像文件,并通过识别软件将图像中的文字转换成文本格式,供文字处理软件进一步编辑加工的技术。如何除错或利用
2023-10-16 23:25:11
视觉领域的重要问题,主要是识别和理解图像或视频中的文字信息。字符检测和识别(OCR)技术最早在1929年由德国科学家Tausheck提出,定义为将印刷体的字符从纸质文档中识别出来。随着OCR技术的日益
2023-09-26 16:31:59
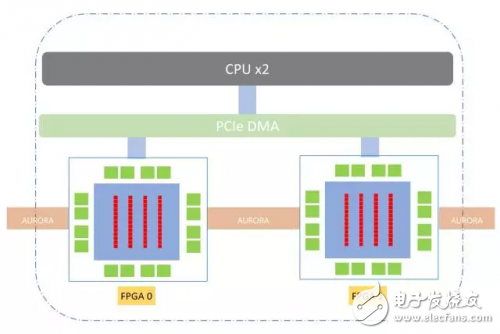
这些技术相互匹配,并激发对FPGA如何帮助深度学习领域发展的探讨。1.简介机器学习对日常生活影响深远。无论是在网站上点击个性化推荐内容、在智能手机上使用语音沟通,或利用面部识别技术来拍照,都用到了某种
2018-08-13 09:33:30
` 本帖最后由 讯飞开放平台 于 2018-7-2 08:55 编辑
语音识别是十年来发展最快的技术之一,随着AI的不断发展,深度学习让语音识别技术得到了质的飞跃,开始从实验室走向市场,并逐步
2018-06-28 11:27:08
都出现了重大突破。深度学习是这些领域中所最常使用的技术,也被业界大为关注。然而,深度学习模型需要极为大量的数据和计算能力,只有更好的硬件加速条件,才能满足现有数据和模型规模继续扩大的需求。 FPGA
2019-10-10 06:45:41
上述分类之外,还被用于多项任务(下面显示了四个示例)。在 FPGA 上进行深度学习的好处我们已经提到,许多服务和技术都使用深度学习,而 GPU 大量用于这些计算。这是因为矩阵乘法作为深度学习中的主要
2023-02-17 16:56:59
最近在LED视觉检测的项目,用的是labview 视觉里OCR的技术,基本上已经完成。但还有些问题,希望做过类似的实际项目的兄弟帮忙看看,指导指导,1. 识别的Accept Level一般设为
2020-03-27 21:14:22
领域的奥斯卡盛会之称,是全球OCR领域公认最权威的比赛之一。当前,OCR技术被广泛应用于多个领域。从名片、发票、银行卡等票据的数字化到室外街道商店索引,路标路牌识别;再到图片、视频文字内容理解与内容安全
2018-03-14 10:54:50
1. 介绍AI的通用文字识别可以对文档翻拍、街景翻拍等图片来源的文字检测和识别,可以集成在其他应用中,提供文字检测、识别的功能,并根据识别结果提供翻译、搜索等相关服务。该功能在一定程度上支持文本倾斜
2021-08-27 11:27:54
领先的深度学习算法,利用光学字符识别技术,将图片上的文字内容,直接转换为可编辑文本。不仅能精准快速识别身份证、名片、营业执照、驾驶证等卡证类信息,更有通用OCR识别技术支持更多场景、任意版面的文字信息
2018-09-26 18:11:49
嵌入式OCR技术是什么?
2021-12-27 06:44:26
、PC及服务器版本3.可识别十几种语言的印刷体文字想要了解更多详情和服务的亲们,请在微信公众服务号平台中搜索“云脉OCR”关注yunmai-OCR微信号。【软件截图】【软件安装包】觉得帖子有用的亲们,记得留个回复哦,3Q
2014-10-13 10:50:22
了方法,就和添加文字一样简单了。 这里向大家推荐一款捷速OCR文字识别软件。这是一款识别效果十分好的文字识别软件,软件采用的是深度图片多层次识别技术,借助强大的图片文字识别核心技术,准确识别图片中的文字
2017-07-26 10:40:12
如今高效便捷已是互联网金融时代的精髓,而作为能够让用户实现一键绑定银行卡的OCR技术,云脉银行卡识别技术它很好的诠释了这一精髓和本质。众所周知无论是电商平台、互联网金融平台还是第三方支付,都需要用
2015-09-16 17:35:20
识别功能API接口的平台——云脉OCR SDK开发者平台。“罗马不是一日建成的”,OCR识别技术它是经过十几年的研发沉淀积累的,不可一日而就。如今OCR它能识别银行卡、身份证、驾驶证、行驶证、护照
2015-09-22 17:21:16
就是进入OCR界面中的训练模式,在训练模板训练好了都能正常识别,保存为abc文件后关闭了,在识别界面框字符背景就都变成紫色的了,无法正常识别。。。。。弄了好久,看了小草的教学他就直接是正常识别。。求大神告知,图在下面
2016-04-13 16:55:41
`汽车VIN码识别系统是一款VIN码识别、采集、解析SDK,可集成在安卓、IOS平台。汽车VIN码识别系统•高效——视频流识别、一秒钟采集VIN码,识别率高达99%;汽车VIN码识别系统•便捷
2019-06-28 13:40:19
用ocr识别文字表格后,格式内容很乱,有没有什么算法可恢复成原有的数据结构
2022-08-26 09:47:50
进行算法添加,如下图:利用左键以下拉列表的形式设置算法参数至表格中如下图:然后将表格数据转换视觉参数进行有序的步骤运行:OCR字符识别在上次的公众文章中有进行讲解,这里就不多说了,我们直接拿出封装VI
2020-08-16 17:56:35
解决方案。1 语音听写借助讯飞开放平台领先的语音识别技术,长按录音(目前小程序中语音听写时长最多支持30秒),直接把语音转换成对应的文字信息,语音识别准确率已经超过98%,在业界遥遥领先。另外,还支持中
2018-07-24 09:02:15
,基于讯飞AI研究院独创的基于深度神经网络模型端到端文字识别系统,识别文字符号的数字影像,并将其转换为对应的电脑等设备可编辑的数字文本,最终达到识别的文字结果可编辑、可处理的目的,其中印刷文字识别技术面向
2018-05-17 15:18:23
手把手教你设计人工智能芯片及系统(全阶设计教程+AI芯片FPGA实现+开发板)详情链接:http://url.elecfans.com/u/c422a4bd15车牌识别SDK、车牌OCR、车牌识别
2019-01-02 16:59:47
什么是OCR
OCR的英文全称:
OCR是英文Optical Character Recognition的缩写,意思是光学字符识别,也可简单地称为文字识别,是文字自动输入的一种方法。它通过扫描和摄像
2009-04-10 12:55:055458 本文设计了一种基于SOPC的嵌入式文字识别系统。在FPGA平台下,基于SOPC的框架搭建软硬件协同系统,设计硬件电路完成文字图像的采集和预处理,嵌入Linux系统,使用其下的识别引擎完
2011-09-01 15:19:20 55
55 TH-OCR文字识别系统的工作原理为通过扫描仪或数码相机等光学输入设备获取纸张上的文字图片信息,OCR文字识别系统实际上是让计算机认字,实现文字自动输入。
2011-12-27 16:04:162003 电子发烧友网站提供《免费版文字识别系统 TH-OCR SDK11.0.exe》资料免费下载
2014-07-23 14:10:090 Android文字识别
2016-12-20 22:40:340 目前OCR技术在证件识别、快递单扫描、信息安全审核等领域有着广泛的应用。架构平台部FPGA团队研发的OCR硬件加速解决方案,提供低成本、实时性AI计算加速,将持续助力公司内各业务发展。在云端
2017-12-14 05:32:442663 
在图像中,文字信息包含了丰富的高层语义信息,提取出这些文字,对于图像高层语义的理解、索引和检索非常有帮助。基于matlab的文字识别算法具有局限性,模板匹配效率低,伸缩范围比较小的的特征。文字提取、识别的详细步骤下文将详细介绍。
2018-01-15 10:31:0429409 
一、证件识别/证件OCR介绍移动端证件识别是开发的基于移动平台的证件识别/证件OCR应用程序,支持Android、iOS等多种主流移动操作系统。该产品采用手机、平板电脑摄像头拍摄证件图像,然后通过
2018-06-15 15:42:05202 人脸识别是AI技术发展较快、应用较多的一个领域,目前国内人脸识别应用已相当广泛,并积累了不少实战经验。
2018-08-26 10:11:0611738 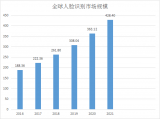
的检测与分割以及视频文字识别(Video OCR) 等。对于不同的典型算法, 分析了其理论基础和应用特点, 并且通过对比指出其不足和应用的局限。最后, 本文还展望了该技术未来发展的方向。
2018-09-17 17:58:0026 全面解析人脸识别技术原理、领域人才情况、技术应用领域和发展趋势。
2018-11-12 14:54:4024168 设计了一种基于SoPC的嵌入式文字识别系统。在FPGA平台下,基于SoPC框架搭建软硬件协同系统,设计硬件电路完成文字图像的采集和预处理,嵌入Linux系统,使用其下的识别引擎完成文字图像的识别
2018-12-19 11:43:581194 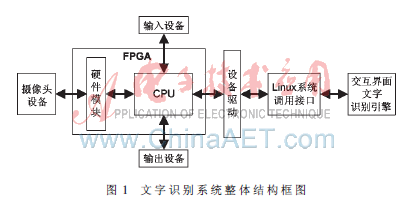
OCR (光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程;即,针对印刷体字符,采用光学的方式
2019-03-02 13:49:5620002 分享一种简单识别提取图中文字的方法,问题就可以轻松解决了。 参考工具:迅捷OCR文字识别软件 操作步骤: 1:因为接下来使用到的是PC端的工具,所以整个步骤都是在电脑中进行的,将OCR文字识别软件
2019-03-26 14:41:15819 来来看下吧! 辅助工具:迅捷OCR文字识别软件 操作步骤: 1:首先在电脑中打开迅捷OCR文字识别软件,选择极速识别板块,进入到接下来的操作。 2:进入极速识别操作界面后,点击添加文件按钮选择一张所需识别
2019-03-27 13:50:47661 本文从硬件加速的视角考察深度学习与FPGA,指出有哪些趋势和创新使得这些技术相互匹配,并激发对FPGA如何帮助深度学习领域发展的探讨。
2019-06-28 17:31:466528 cencrack识别图片转文字工具是一款免费实用的OCR图片转文字的软件-办公必备,软件操作简单,免安装,程序微小,功能强大。软件功能强大,操作简单,省去了安装的步骤。
2019-07-15 08:00:000 我们为什么用OCR?因为可以快速将文字转为可在设备上编辑的数字文本。因此能够得到用户青睐的OCR小编认为应能够准确生成文本,所见即所得,同时对不同字体,不同环境,不同颜色形状的文本准确识别。
2019-09-27 09:51:312391 你一定用过那种“OCR神器”,可以把图片中的文字提取出来,极大的提高工作效率。今天,我们就来做一款实时截图识别的小工具。顾名思义,运行程序时,可以实时的把你截出来的图片中的文字识别出来。
2020-01-04 11:27:003200 人工智能技术正在成为阻断疫情传播、便捷老百姓日常生活的有效手段。就在社会各界齐心协力共同阻击疫情过程中,腾讯云AI团队基于领先的深度学习技术打造的文字识别OCR产品,正在成为国内众多地区进行无接触化社区防疫管控,师生远程在线教育的重要工具。
2020-03-15 15:29:00457 本文档的主要内容详细介绍的是OCR文字识别视觉检测系统应用程序免费下载。
2020-05-28 17:31:0022 科技之中,人工智能作为“流量担当”拥有居高不下的热度,即使文字识别只是人工智能技术之中的一个小模块,但也能够为我们的生活增添更多的便利。
2020-06-18 11:24:572455 本文档的主要内容详细介绍的是使用数字识别和AI实现OCR的资料合集。
2020-07-17 08:00:0020 近年来,学生党们拥有了一款新的学习神器拍照搜题。当遇到不会做的题目时,只需要对着题目拍照,手机中就会出现这道题目的详细解答思路和答案。 拍照搜题背后的黑科技就是光学字符识别技术,即OCR。OCR
2020-09-17 11:34:071963 好介绍下这个项目。 众所周知,OCR(Optical Character Recognition,光学字符识别) 技术已被广泛应用到我们生活中的方方面面,从印刷稿的文字识别、身份证电子化信息录入,到传统邮件自动分拣、汽车牌照识别等领域,都上正式开源了一款 OCR 神器,在发布后不久便多次冲上 GitHu
2020-10-30 10:54:393084 
在爬虫对验证码进行破解时,经常需要对图片中的文字内容进行识别,这时就需要用到OCR技术了,那么 OCR识别技术是如何实现对文字内容“即拍即得”的呢?
2021-03-12 09:07:154205 计算机文字识别技术研究。
2021-03-24 14:15:3916 光学字符识别(Optical Character Recognition,OCR)是将图像中的文字信息转化为可供计算机处理的字符信息的技术,发挥着计算机“眼睛”的功能,是机器与现实世界进行视觉交互的重要技术基础。
2021-04-09 10:54:116940 在资讯大爆炸的时代,我们经常面临文件、图片找不到的情况,HarmonyOS基于AI的通用文字识别技术,可以有效帮助我们解决这些难题。 基于AI的通用文字识别,将OCR技术和AI分词技术集成,可以
2021-08-20 10:42:262805 HDC 2021华为开发者大会HarmonyOS测试技术与实战-HarmonyOS图形栈测试技术深度解析
2021-10-23 15:09:001252 
近日浏览网上一些图片提取文字的网站,觉得甚是有趣,花费半日也做了个在线图片识别程序,完成了两个技术方案的选择,一是tesseract+python flask的方案实现,二是
2021-10-28 14:05:341723 
的生产情况、智能匹配识别产品的印刷信息,进行分拣等多种应用。 OCR最常见应用场景之一就是将物料上的字符进行OCR识别后再做分拣,它通过识别相对应的字符样本后,产线就可以进行智能匹配分拣。正运动技术的机器视觉OCR字符识别技术可
2022-02-24 17:27:331172 
./oschina_soft/tools-ocr.zip
2022-05-30 09:42:225 ./oschina_soft/darknet-ocr.zip
2022-06-17 15:07:291 对于文字识别,实际中一般首先需要通过文字检测定位文字在图像中的区域,然后提取区域的序列特征,在此基础上进行专门的字符识别。但是随着CV发展,也出现很多端到端的End2End OCR。
2022-06-20 14:31:401827 OCR技术发展到今天,对于常规文本的识别已经达到了较高的准确率。
2022-08-08 16:04:511106 让1 0000 条防疫信息实现秒级录入与核验! ——华为云OCR文字识别服务助力智能化疫情防控 人工智能实现效率千倍提升,为基层抗疫工作减负提效 ——华为云实现万条防疫信息秒级录入与核验,助力基层
2022-10-21 14:54:04461 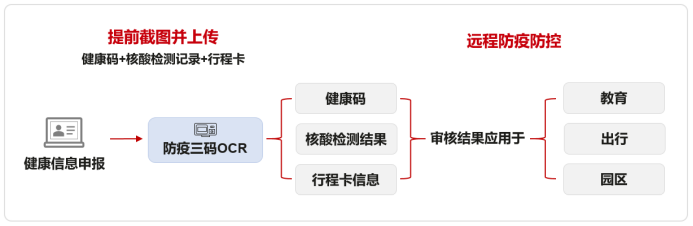
本文主要介绍一个通过图像处理改善OCR识别结果的实例,并给出详细步骤和源码。
**背景介绍**
在很多情况下,文字识别会遇到困难。比如非单一的背景、杂讯干扰、文字部分缺失等。
2023-02-08 16:54:36571 OCR 是光学字符识别(英语:Optical Character Recognition,OCR)是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。
2023-02-24 10:36:16677 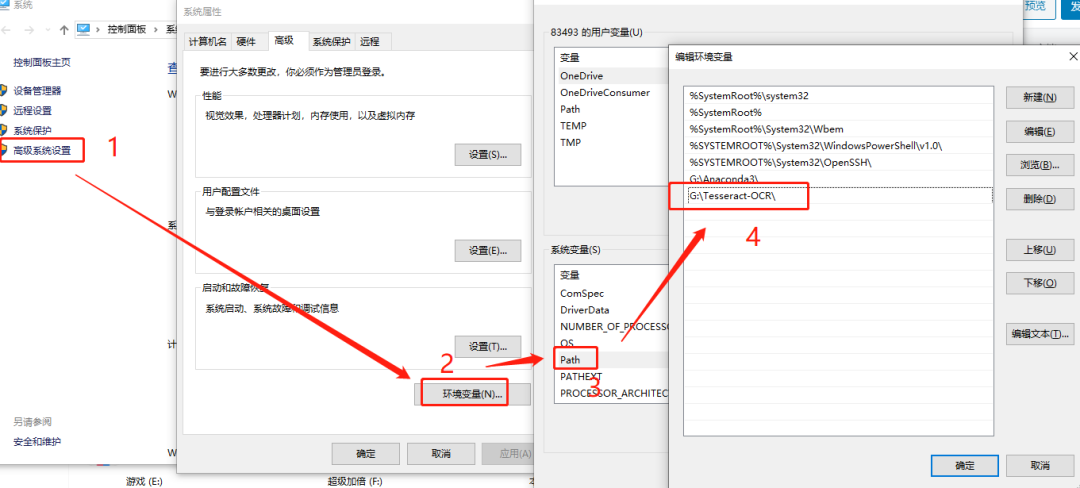
语音识别技术,也被称为自动语音识别Automatic Speech Recognition,(ASR),(迅 捷ocr文字识别软件)其目标是将人类的语音中的词汇内容转换为计算机可读的输入,例如
2023-04-13 16:03:193689 ,收集了很多的名片,但是要一一输入资料,进行整合;月末结算时,财务人员需要额外腾出时间,整理录入成山成堆的票据表单数据,快递公司每天都要花大量的时间去记录运输单。实际上,通过华为云文字识别OCR,可以让我们的工
2023-04-26 10:47:57359 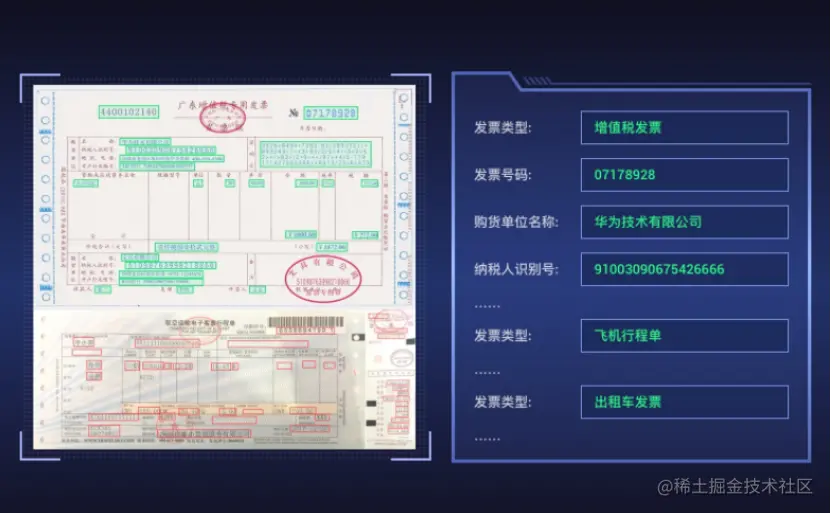
。想象一下,如果我们能够快速地提取出图片中的文本信息,并将其转化为结构化的数据,那么我们就能够实现很多智能化的应用场景,提升我们的业务效率和用户体验。这就是我为什么推荐华为云文字识别 OCR 的原因。 OCR 是什么?
2023-07-04 14:43:07346 光学字符识别 Optical Character Recognition(OCR)
其目标是对图像中的字符进行分析识别,将其转换为文本格式的字符序列。
利用模式识别和数字图像处理技术,解决文字输入问题。
2023-07-05 11:50:15289 
一、引言 随着深度学习技术的快速发展,其在语音识别领域的应用也日益广泛。深度学习技术可以有效地提高语音识别的精度和效率,并且被广泛应用于各种应用场景。本文将探讨深度学习在语音识别中的应用及所面临
2023-10-10 18:14:53444 OCR 是光学字符识别(英语:Optical Character Recognition,OCR)是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。 很早之前就有同学在公众号后台
2023-10-31 16:45:39358 预处理主要是基于OpenCV、场景文字检测与识别基于OpenVINO框架 + PaddleOCR模型完成。直接按图索骥即可得到最终结果。 OpenCV预处理主要是完成偏斜矫正、背景矫正等操作,然后使用场景文字检测模型+OCR识别模型完成中英文识别。
2023-11-07 11:21:47315 
伴随着工业自动化的发展,光学字符识别(OCR)技术已成为产品质量管控的刚需,常用于部件入库跟踪、产品工艺溯源、商品保质期管理等场景。然而,为了促进精益生产、柔性生产、保障品控,产线不仅对此类技术
2023-12-16 08:24:50488 
 电子发烧友App
电子发烧友App










 工商网监
工商网监
评论