 一套符合标准SQL语义的开发语言,link的最新特性
一套符合标准SQL语义的开发语言,link的最新特性
一、Flink SQL 背景
Flink SQL 是 Flink 实时计算为简化计算模型,降低用户使用实时计算门槛而设计的一套符合标准 SQL 语义的开发语言。
自 2015 年开始,阿里巴巴开始调研开源流计算引擎,最终决定基于 Flink 打造新一代计算引擎,针对 Flink 存在的不足进行优化和改进,并且在 2019 年初将最终代码开源,也就是我们熟知的 Blink。Blink 在原来的 Flink 基础上最显著的一个贡献就是 Flink SQL 的实现。
Flink SQL 是面向用户的 API 层,在我们传统的流式计算领域,比如 Storm、Spark Streaming 都会提供一些 Function 或者 Datastream API,用户通过 Java 或 Scala 写业务逻辑,这种方式虽然灵活,但有一些不足,比如具备一定门槛且调优较难,随着版本的不断更新,API 也出现了很多不兼容的地方。
在这个背景下,毫无疑问,SQL 就成了我们最佳选择,之所以选择将 SQL 作为核心 API,是因为其具有几个非常重要的特点:
SQL 属于设定式语言,用户只要表达清楚需求即可,不需要了解具体做法;
SQL 可优化,内置多种查询优化器,这些查询优化器可为 SQL 翻译出最优执行计划;
SQL 易于理解,不同行业和领域的人都懂,学习成本较低;
SQL 非常稳定,在数据库 30 多年的历史中,SQL 本身变化较少;
流与批的统一,Flink 底层 Runtime 本身就是一个流与批统一的引擎,而 SQL 可以做到 API 层的流与批统一。
二、Flink 的最新特性(1.7.0 和 1.8.0 更新)
2.1 Flink 1.7.0 新特性
在 Flink 1.7.0 中,我们更接近实现快速数据处理和以无缝方式为 Flink 社区构建数据密集型应用程序的目标。最新版本包括一些新功能和改进,例如对 Scala 2.12 的支持、一次性 S3 文件接收器、复杂事件处理与流 SQL 的集成等。
Apache Flink 中对 Scala 2.12 的支持(FLINK-7811)
Apache Flink 1.7.0 是第一个完全支持 Scala 2.12 的版本。这允许用户使用较新的 Scala 版本编写 Flink 应用程序并利用 Scala 2.12 生态系统。
状态演进(FLINK-9376)
许多情况下,由于需求的变化,长期运行的 Flink 应用程序需要在其生命周期内发展。在不失去当前应用程序进度状态的情况下更改用户状态是应用程序发展的关键要求。使用 Flink 1.7.0,社区添加了状态演变,允许您灵活地调整长时间运行的应用程序的用户状态模式,同时保持与以前保存点的兼容性。通过状态演变,可以在状态模式中添加或删除列,以便更改应用程序部署后应用程序捕获的业务功能。现在,使用 Avro 生成时,状态模式演变现在可以立即使用作为用户状态的类,这意味着可以根据 Avro 的规范来演变国家的架构。虽然 Avro 类型是 Flink 1.7 中唯一支持模式演变的内置类型,但社区仍在继续致力于在未来的 Flink 版本中进一步扩展对其他类型的支持。
MATCH RECOGNIZE Streaming SQL 支持(FLINK-6935)
这是 Apache Flink 1.7.0 的一个重要补充,它为 Flink SQL 提供了 MATCH RECOGNIZE 标准的初始支持。此功能结合了复杂事件处理(CEP)和 SQL,可以轻松地对数据流进行模式匹配,从而实现一整套新的用例。此功能目前处于测试阶段,因此我们欢迎社区提供任何反馈和建议。
流式 SQL 中的时态表和时间连接(FLINK-9712)
时态表是 Apache Flink 中的一个新概念,它为表的更改历史提供(参数化)视图,并在特定时间点返回表的内容。例如,我们可以使用具有历史货币汇率的表格。随着时间的推移,这种表格不断增长/发展,并且增加了新的更新汇率。时态表是一种视图,可以将这些汇率的实际状态返回到任何给定的时间点。使用这样的表,可以使用正确的汇率将不同货币的订单流转换为通用货币。时间联接允许使用不断变化/更新的表来进行内存和计算有效的流数据连接。
Streaming SQL 的其他功能
除了上面提到的主要功能外,Flink 的 Table&SQL API 已经扩展到更多用例。以下内置函数被添加到 API:TO_BASE64、LOG2、LTRIM、REPEAT、REPLACE、COSH、SINH、TANH SQL Client 现在支持在环境文件和 CLI 会话中定义视图。此外,CLI 中添加了基本的 SQL 语句自动完成功能。社区添加了一个 Elasticsearch 6 表接收器,允许存储动态表的更新结果。
Kafka 2.0 连接器(FLINK-10598)
Apache Flink 1.7.0 继续添加更多连接器,使其更容易与更多外部系统进行交互。在此版本中,社区添加了 Kafka 2.0 连接器,该连接器允许通过一次性保证读取和写入 Kafka 2.0。
本地恢复(FLINK-9635)
Apache Flink 1.7.0 通过扩展 Flink 的调度来完成本地恢复功能,以便在恢复时考虑以前的部署位置。如果启用了本地恢复,Flink 将保留最新检查点的本地副本任务运行的机器。通过将任务调度到以前的位置,Flink 将通过从本地磁盘读取检查点状态来最小化恢复状态的网络流量。此功能大大提高了恢复速度。
2.2 Flink 1.8.0 新特性
Flink 1.8.0 引入对状态的清理
使用 TTL(生存时间)连续增量清除旧的 Key 状态 Flink 1.8 引入了对 RocksDB 状态后端(FLINK-10471)和堆状态后端(FLINK-10473)的旧数据的连续清理。这意味着旧的数据将(根据 TTL 设置)不断被清理掉。
新增和删除一些 Table API
1) 引入新的 CSV 格式符(FLINK-9964)
此版本为符合 RFC4180 的 CSV 文件引入了新的格式符。新描述符可以使用 org.apache.flink.table.descriptors.Csv。目前,只能与 Kafka 一起使用。旧描述符 org.apache.flink.table.descriptors.OldCsv 用于文件系统连接器。
2) 静态生成器方法在 TableEnvironment(FLINK-11445)上的弃用
为了将 API 与实际实现分开,TableEnvironment.getTableEnvironment() 不推荐使用静态方法。现在推荐使用Batch/StreamTableEnvironment.create()。
3) 表 API Maven 模块中的更改(FLINK-11064)
之前具有 flink-table 依赖关系的用户需要更新其依赖关系 flink-table-planner,以及正确的依赖关系 flink-table-api-*,具体取决于是使用 Java 还是 Scala: flink-table-api-java-bridge 或者 flink-table-api-scala-bridge。
Kafka Connector 的修改
引入可直接访问 ConsumerRecord 的新KafkaDeserializationSchema(FLINK-8354),对于 FlinkKafkaConsumers 推出了一个新的 KafkaDeserializationSchema,可以直接访问 KafkaConsumerRecord。
三、Flink SQL 的编程模型
Flink 的编程模型基础构建模块是流(streams)与转换 (transformations),每一个数据流起始于一个或多个 source,并终止于一个或多个 sink。
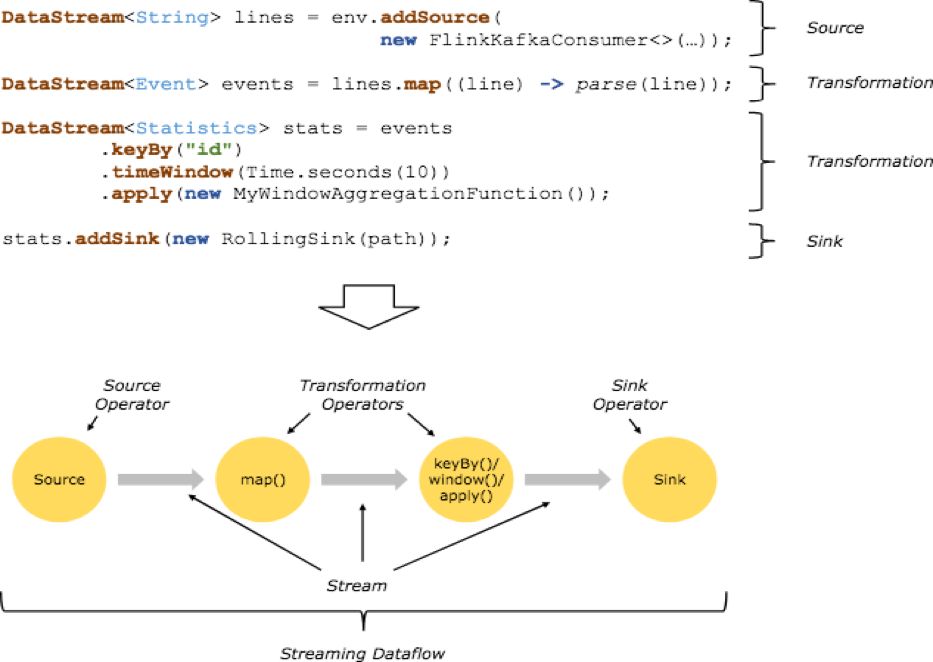
相信大家对上面的图已经十分熟悉了,当然基于 Flink SQL 编写的 Flink 程序也离不开读取原始数据,计算逻辑和写入计算结果数据三部分。
一个完整的 Flink SQL 编写的程序包括如下三部分:
Source Operator:Soruce operator 是对外部数据源的抽象, 目前 Apache Flink 内置了很多常用的数据源实现例如 MySQL、Kafka 等;
Transformation Operators:算子操作主要完成例如查询、聚合操作等,目前 Flink SQL 支持了 Union、Join、Projection、Difference、Intersection 及 window 等大多数传统数据库支持的操作;
Sink Operator:Sink operator 是对外结果表的抽象,目前 Apache Flink 也内置了很多常用的结果表的抽象,比如 Kafka Sink 等
我们通过用一个最经典的 WordCount 程序作为入门,看一下传统的基于 DataSet/DataStream API 开发和基于 SQL 开发有哪些不同?
DataStream/DataSetAPI
public class WordCount { public static void main(String[] args) throws Exception { final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); DataSet
Flink SQL
//省略掉初始化环境等公共代码SELECT word, COUNT(word) FROM table GROUP BY word;
我们已经可以直观体会到,SQL 开发的快捷和便利性了。
四、Flink SQL 的语法和算子
4.1 Flink SQL 支持的语法
Flink SQL 核心算子的语义设计参考了 1992、2011 等 ANSI-SQL 标准,Flink 使用 Apache Calcite 解析 SQL ,Calcite 支持标准的 ANSI SQL。
那么 Flink 自身支持的 SQL 语法有哪些呢?
insert: INSERT INTO tableReference queryquery: values | { select | selectWithoutFrom | query UNION [ ALL ] query | query EXCEPT query | query INTERSECT query } [ ORDER BY orderItem [, orderItem ]* ] [ LIMIT { count | ALL } ] [ OFFSET start { ROW | ROWS } ] [ FETCH { FIRST | NEXT } [ count ] { ROW | ROWS } ONLY]orderItem: expression [ ASC | DESC ]select: SELECT [ ALL | DISTINCT ] { * | projectItem [, projectItem ]* } FROM tableExpression [ WHERE booleanExpression ] [ GROUP BY { groupItem [, groupItem ]* } ] [ HAVING booleanExpression ] [ WINDOW windowName AS windowSpec [, windowName AS windowSpec ]* ]selectWithoutFrom: SELECT [ ALL | DISTINCT ] { * | projectItem [, projectItem ]* }projectItem: expression [ [ AS ] columnAlias ] | tableAlias . *tableExpression: tableReference [, tableReference ]* | tableExpression [ NATURAL ] [ LEFT | RIGHT | FULL ] JOIN tableExpression [ joinCondition ]joinCondition: ON booleanExpression | USING '(' column [, column ]* ')'tableReference: tablePrimary [ [ AS ] alias [ '(' columnAlias [, columnAlias ]* ')' ] ]tablePrimary: [ TABLE ] [ [ catalogName . ] schemaName . ] tableName | LATERAL TABLE '(' functionName '(' expression [, expression ]* ')' ')' | UNNEST '(' expression ')'values: VALUES expression [, expression ]*groupItem: expression | '(' ')' | '(' expression [, expression ]* ')' | CUBE '(' expression [, expression ]* ')' | ROLLUP '(' expression [, expression ]* ')' | GROUPING SETS '(' groupItem [, groupItem ]* ')'windowRef: windowName | windowSpecwindowSpec: [ windowName ] '(' [ ORDER BY orderItem [, orderItem ]* ] [ PARTITION BY expression [, expression ]* ] [ RANGE numericOrIntervalExpression {PRECEDING} | ROWS numericExpression {PRECEDING} ] ')'
上面 SQL 的语法支持也已经表明了 Flink SQL 对算子的支持,接下来我们对 Flink SQL 中最常见的算子语义进行介绍。
4.2 Flink SQL 常用算子
SELECT
SELECT 用于从 DataSet/DataStream 中选择数据,用于筛选出某些列。
示例:
SELECT * FROM Table;// 取出表中的所有列SELECT name,age FROM Table;// 取出表中 name 和 age 两列
与此同时 SELECT 语句中可以使用函数和别名,例如我们上面提到的 WordCount 中:
SELECT word, COUNT(word) FROM table GROUP BY word;
WHERE
WHERE 用于从数据集/流中过滤数据,与 SELECT 一起使用,用于根据某些条件对关系做水平分割,即选择符合条件的记录。
示例:
SELECT name,age FROM Table where name LIKE ‘% 小明 %’;SELECT * FROM Table WHERE age = 20;
WHERE 是从原数据中进行过滤,那么在 WHERE 条件中,Flink SQL 同样支持 =、<、>、<>、>=、<=,以及 AND、OR 等表达式的组合,最终满足过滤条件的数据会被选择出来。并且 WHERE 可以结合 IN、NOT IN 联合使用。举个负责的例子:
SELECT name, ageFROM TableWHERE name IN (SELECT name FROM Table2)
DISTINCT
DISTINCT 用于从数据集/流中去重根据 SELECT 的结果进行去重。
示例:
SELECT DISTINCT name FROM Table;
对于流式查询,计算查询结果所需的 State 可能会无限增长,用户需要自己控制查询的状态范围,以防止状态过大。
GROUP BY
GROUP BY 是对数据进行分组操作。例如我们需要计算成绩明细表中,每个学生的总分。
SELECT name, SUM(score) as TotalScore FROM Table GROUP BY name;
UNION和UNION ALL
UNION 用于将两个结果集合并起来,要求两个结果集字段完全一致,包括字段类型、字段顺序。不同于 UNION ALL 的是,UNION 会对结果数据去重。
示例:
SELECT * FROM T1 UNION (ALL) SELECT * FROM T2;
JOIN
JOIN 用于把来自两个表的数据联合起来形成结果表,Flink 支持的 JOIN 类型包括:
JOIN - INNER JOIN
LEFT JOIN - LEFT OUTER JOIN
RIGHT JOIN - RIGHT OUTER JOIN
FULL JOIN - FULL OUTER JOIN
这里的 JOIN 的语义和我们在关系型数据库中使用的 JOIN 语义一致。
示例:
JOIN(将订单表数据和商品表进行关联)SELECT * FROM Orders INNER JOIN Product ON Orders.productId = [Product.id](http://product.id/)
LEFT JOIN 与 JOIN 的区别是当右表没有与左边相 JOIN 的数据时候,右边对应的字段补 NULL 输出,RIGHT JOIN 相当于 LEFT JOIN 左右两个表交互一下位置。FULL JOIN 相当于 RIGHT JOIN 和 LEFT JOIN 之后进行 UNION ALL 操作。
示例:
SELECT *FROM Orders LEFT JOIN Product ON Orders.productId = [Product.id](http://product.id/)SELECT *FROM Orders RIGHT JOIN Product ON Orders.productId = [Product.id](http://product.id/)SELECT *FROM Orders FULL OUTER JOIN Product ON Orders.productId = [Product.id](http://product.id/)
Group Window
根据窗口数据划分的不同,目前 Apache Flink 有如下 3 种 Bounded Window:
Tumble,滚动窗口,窗口数据有固定的大小,窗口数据无叠加;
Hop,滑动窗口,窗口数据有固定大小,并且有固定的窗口重建频率,窗口数据有叠加;
Session,会话窗口,窗口数据没有固定的大小,根据窗口数据活跃程度划分窗口,窗口数据无叠加。
Tumble Window
Tumble 滚动窗口有固定大小,窗口数据不重叠,具体语义如下:
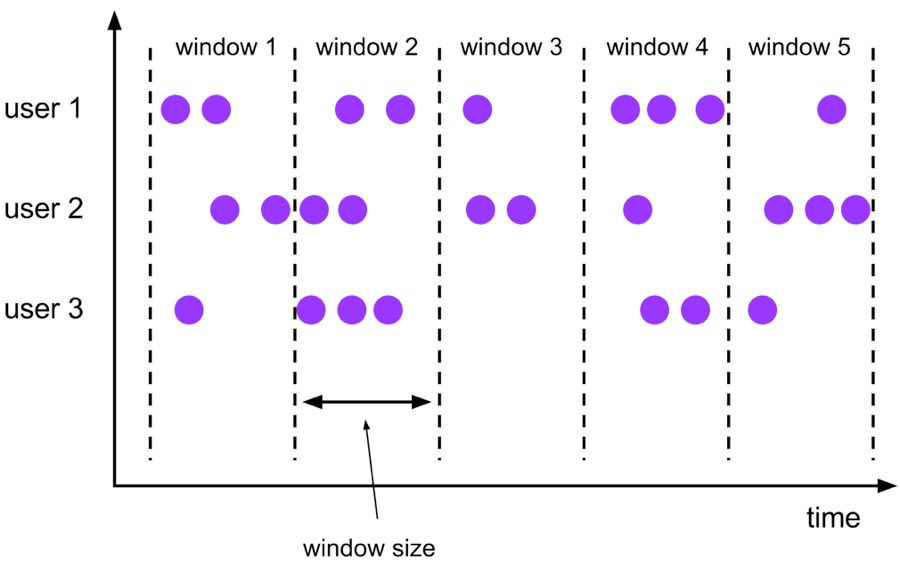
Tumble 滚动窗口对应的语法如下:
SELECT [gk], [TUMBLE_START(timeCol, size)], [TUMBLE_END(timeCol, size)], agg1(col1), ... aggn(colN)FROM Tab1GROUP BY [gk], TUMBLE(timeCol, size)
其中:
[gk] 决定了是否需要按照字段进行聚合;
TUMBLE_START 代表窗口开始时间;
TUMBLE_END 代表窗口结束时间;
timeCol 是流表中表示时间字段;
size 表示窗口的大小,如 秒、分钟、小时、天。
举个例子,假如我们要计算每个人每天的订单量,按照 user 进行聚合分组:
SELECT user, TUMBLE_START(rowtime, INTERVAL ‘1’ DAY) as wStart, SUM(amount) FROM Orders GROUP BY TUMBLE(rowtime, INTERVAL ‘1’ DAY), user;
Hop Window
Hop 滑动窗口和滚动窗口类似,窗口有固定的 size,与滚动窗口不同的是滑动窗口可以通过 slide 参数控制滑动窗口的新建频率。因此当 slide 值小于窗口 size 的值的时候多个滑动窗口会重叠,具体语义如下:
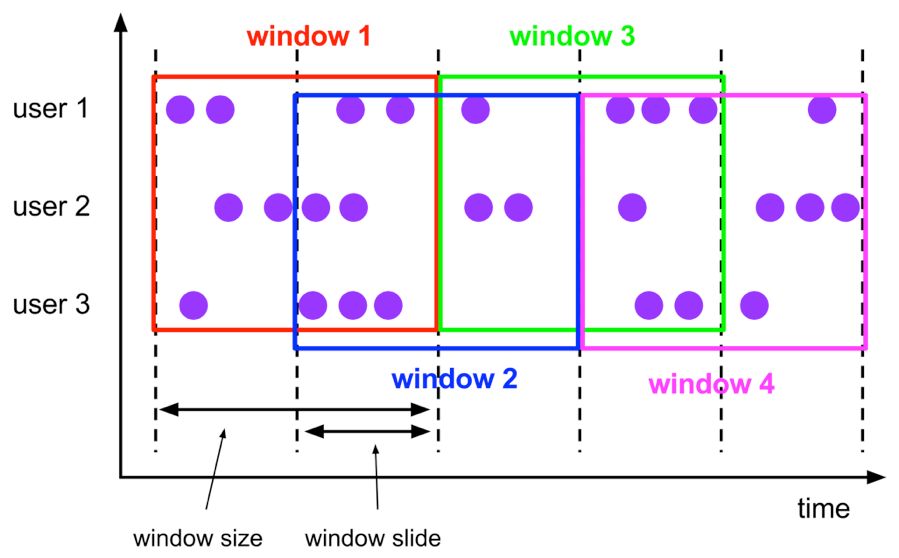
Hop 滑动窗口对应语法如下:
SELECT [gk], [HOP_START(timeCol, slide, size)] , [HOP_END(timeCol, slide, size)], agg1(col1), ... aggN(colN) FROM Tab1GROUP BY [gk], HOP(timeCol, slide, size)
每次字段的意思和 Tumble 窗口类似:
[gk] 决定了是否需要按照字段进行聚合;
HOP_START 表示窗口开始时间;
HOP_END 表示窗口结束时间;
timeCol 表示流表中表示时间字段;
slide 表示每次窗口滑动的大小;
size 表示整个窗口的大小,如 秒、分钟、小时、天。
举例说明,我们要每过一小时计算一次过去 24 小时内每个商品的销量:
SELECT product, SUM(amount) FROM Orders GROUP BY HOP(rowtime, INTERVAL '1' HOUR, INTERVAL '1' DAY), product
Session Window
会话时间窗口没有固定的持续时间,但它们的界限由 interval 不活动时间定义,即如果在定义的间隙期间没有出现事件,则会话窗口关闭。
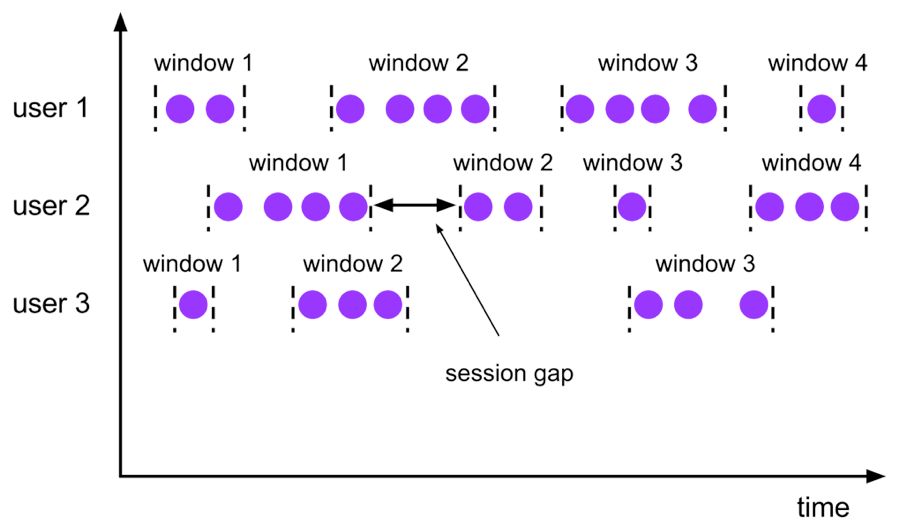
Seeeion 会话窗口对应语法如下:
SELECT [gk], SESSION_START(timeCol, gap) AS winStart, SESSION_END(timeCol, gap) AS winEnd, agg1(col1), ... aggn(colN)FROM Tab1GROUP BY [gk], SESSION(timeCol, gap)
[gk] 决定了是否需要按照字段进行聚合;
SESSION_START 表示窗口开始时间;
SESSION_END 表示窗口结束时间;
timeCol 表示流表中表示时间字段;
gap 表示窗口数据非活跃周期的时长。
例如,我们需要计算每个用户访问时间 12 小时内的订单量:
SELECT user, SESSION_START(rowtime, INTERVAL ‘12’ HOUR) AS sStart, SESSION_ROWTIME(rowtime, INTERVAL ‘12’ HOUR) AS sEnd, SUM(amount) FROM Orders GROUP BY SESSION(rowtime, INTERVAL ‘12’ HOUR), user
五、Flink SQL 的内置函数
Flink 提供大量的内置函数供我们直接使用,我们常用的内置函数分类如下:
比较函数
逻辑函数
算术函数
字符串处理函数
时间函数
我们接下来对每种函数举例进行讲解。
5.1 比较函数
比较函数
描述
| value1=value2 | 如果 value1 等于 value2,则返回 TRUE ; 如果 value1 或 value2 为 NULL,则返回 UNKNOWN |
| value1<>value2 | 如果 value1 不等于 value2,则返回 TRUE ; 如果 value1 或 value2 为 NULL,则返回 UNKNOWN |
| value1>value2 | 如果 value1 大于 value2,则返回 TRUE ; 如果 value1 或 value2 为 NULL,则返回 UNKNOWN |
| value1 < value2 | 如果 value1 小于 value2,则返回 TRUE ; 如果 value1 或 value2 为 NULL,则返回 UNKNOWN |
| value IS NULL | 如果 value 为 NULL,则返回 TRUE |
| value IS NOT NULL | 如果 value 不为 NULL,则返回 TRUE |
| string1 LIKE string2 | 如果 string1 匹配模式 string2,则返回 TRUE ; 如果 string1 或 string2为 NULL,则返回UNKNOWN |
| value1 IN (value2, value3…) | 如果给定列表中存在 value1 (value2,value3,…),则返回 TRUE 。当(value2,value3,…)包含 NULL,如果可以找到该数据元则返回 TRUE,否则返回 UNKNOWN。如果 value1 为 NULL,则始终返回 UNKNOWN |
5.2 逻辑函数
逻辑函数
描述
| A OR B | 如果 A 为 TRUE 或 B 为 TRUE,则返回 TRUE |
| A AND B | 如果 A 和 B 都为 TRUE,则返回 TRUE |
| NOT boolean | 如果 boolean 为 FALSE,则返回 TRUE,否则返回 TRUE。如果 boolean 为 TRUE,则返回 FALSE |
| A IS TRUE 或 FALSE | 判断 A 是否为真 |
| — | — |
5.3 算术函数
算术函数
描述
| numeric1 ±*/ numeric2 | 分别代表两个数值加减乘除 |
| ABS(numeric) | 返回 numeric 的绝对值 |
| POWER(numeric1, numeric2) | 返回 numeric1 上升到 numeric2 的幂 |
除了上述表中的函数,Flink SQL 还支持种类丰富的函数计算。
5.4 字符串处理函数
字符串函数
描述
| UPPER/LOWER | 以大写 / 小写形式返回字符串 |
| LTRIM(string) | 返回一个字符串,从去除左空格的字符串, 类似还有 RTRIM |
| CONCAT(string1, string2,…) | 返回连接 string1,string2,…的字符串 |
5.5 时间函数
时间函数
描述
| DATE string | 返回以“yyyy-MM-dd”形式从字符串解析的 SQL 日期 |
| TIMESTAMP string | 返回以字符串形式解析的 SQL 时间戳,格式为“yyyy-MM-dd HH:mm:ss [.SSS]” |
| CURRENT_DATE | 返回 UTC 时区中的当前 SQL 日期 |
| DATE_FORMAT(timestamp, string) | 返回使用指定格式字符串格式化时间戳的字符串 |
六、Flink SQL 实战应用
上面我们分别介绍了 Flink SQL 的背景、新特性、编程模型和常用算子,这部分我们将模拟一个真实的案例为大家使用 Flink SQL 提供一个完整的 Demo。
相信这里应该有很多 NBA 的球迷,假设我们有一份数据记录了每个赛季的得分王的数据,包括赛季、球员、出场、首发、时间、助攻、抢断、盖帽、得分等。现在我们要统计获得得分王荣誉最多的三名球员。
原数据存在 score.csv 文件中,如下:
17-18,詹姆斯-哈登,72,72,35.4,8.8,1.8,0.7,30.416-17,拉塞尔-威斯布鲁克,81,81,34.6,10.4,1.6,0.4,31.615-16,斯蒂芬-库里,79,79,34.2,6.7,2.1,0.2,30.114-15,拉塞尔-威斯布鲁克,67,67,34.4,8.6,2.1,0.2,28.113-14,凯文-杜兰特,81,81,38.5,5.5,1.3,0.7,3212-13,卡梅罗-安东尼,67,67,37,2.6,0.8,0.5,28.711-12,凯文-杜兰特,66,66,38.6,3.5,1.3,1.2,2810-11,凯文-杜兰特,78,78,38.9,2.7,1.1,1,27.709-10,凯文-杜兰特,82,82,39.5,2.8,1.4,1,30.108-09,德维恩-韦德,79,79,38.6,7.5,2.2,1.3,30.207-08,勒布朗-詹姆斯,75,74,40.4,7.2,1.8,1.1,3006-07,科比-布莱恩特,77,77,40.8,5.4,1.4,0.5,31.605-06,科比-布莱恩特,80,80,41,4.5,1.8,0.4,35.404-05,阿伦-艾弗森,75,75,42.3,7.9,2.4,0.1,30.703-04,特雷西·麦克格雷迪,67,67,39.9,5.5,1.4,0.6,2802-03,特雷西·麦克格雷迪,75,74,39.4,5.5,1.7,0.8,32.101-02,阿伦-艾弗森,60,59,43.7,5.5,2.8,0.2,31.400-01,阿伦-艾弗森,71,71,42,4.6,2.5,0.3,31.199-00,沙奎尔-奥尼尔,79,79,40,3.8,0.5,3,29.798-99,阿伦-艾弗森,48,48,41.5,4.6,2.3,0.1,26.897-98,迈克尔-乔丹,82,82,38.8,3.5,1.7,0.5,28.796-97,迈克尔-乔丹,82,82,37.9,4.3,1.7,0.5,29.695-96,迈克尔-乔丹,82,82,37.7,4.3,2.2,0.5,30.494-95,沙奎尔-奥尼尔,79,79,37,2.7,0.9,2.4,29.393-94,大卫-罗宾逊,80,80,40.5,4.8,1.7,3.3,29.892-93,迈克尔-乔丹,78,78,39.3,5.5,2.8,0.8,32.691-92,迈克尔-乔丹,80,80,38.8,6.1,2.3,0.9,30.190-91,迈克尔-乔丹,82,82,37,5.5,2.7,1,31.589-90,迈克尔-乔丹,82,82,39,6.3,2.8,0.7,33.688-89,迈克尔-乔丹,81,81,40.2,8,2.9,0.8,32.587-88,迈克尔-乔丹,82,82,40.4,5.9,3.2,1.6,3586-87,迈克尔-乔丹,82,82,40,4.6,2.9,1.5,37.185-86,多米尼克-威尔金斯,78,78,39.1,2.6,1.8,0.6,30.384-85,伯纳德-金,55,55,37.5,3.7,1.3,0.3,32.983-84,阿德里安-丹特利,79,79,37.8,3.9,0.8,0.1,30.682-83,阿历克斯-英格利什,82,82,36.4,4.8,1.4,1.5,28.481-82,乔治-格文,79,79,35.7,2.4,1,0.6,32.3
首先我们需要创建一个工程,并且在 Maven 中有如下依赖:
第一步,创建上下文环境:
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); BatchTableEnvironment tableEnv = BatchTableEnvironment.getTableEnvironment(env);
第二步,读取 score.csv 并且作为 source 输入:
DataSet
第三步,将 source 数据注册成表:
Table topScore = tableEnv.fromDataSet(topInput);tableEnv.registerTable("score", topScore);
第四步,核心处理逻辑 SQL 的编写:
Table queryResult = tableEnv.sqlQuery("select player, count(season) as num FROM score GROUP BY player ORDER BY num desc LIMIT 3");
第五步,输出结果:
DataSet
我们直接运行整个程序,观察输出结果:
...16:28:06,162 INFO org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Shut down complete.16:28:06,162 INFO org.apache.flink.runtime.taskexecutor.JobLeaderService - Stop job leader service.16:28:06,164 INFO org.apache.flink.runtime.taskexecutor.TaskExecutor - Stopped TaskExecutor akka://flink/user/taskmanager_2.16:28:06,166 INFO akka.remote.RemoteActorRefProvider$RemotingTerminator - Shutting down remote daemon.16:28:06,166 INFO akka.remote.RemoteActorRefProvider$RemotingTerminator - Remote daemon shut down; proceeding with flushing remote transports.16:28:06,169 INFO akka.remote.RemoteActorRefProvider$RemotingTerminator - Remoting shut down.16:28:06,177 INFO org.apache.flink.runtime.rpc.akka.AkkaRpcService - Stopping Akka RPC service.16:28:06,187 INFO org.apache.flink.runtime.blob.PermanentBlobCache - Shutting down BLOB cache16:28:06,187 INFO org.apache.flink.runtime.blob.TransientBlobCache - Shutting down BLOB cache16:28:06,188 INFO org.apache.flink.runtime.blob.BlobServer - Stopped BLOB server at 0.0.0.0:5170316:28:06,188 INFO org.apache.flink.runtime.rpc.akka.AkkaRpcService - Stopped Akka RPC service.迈克尔-乔丹:10凯文-杜兰特:4阿伦-艾弗森:4
我们看到控制台已经输出结果了:
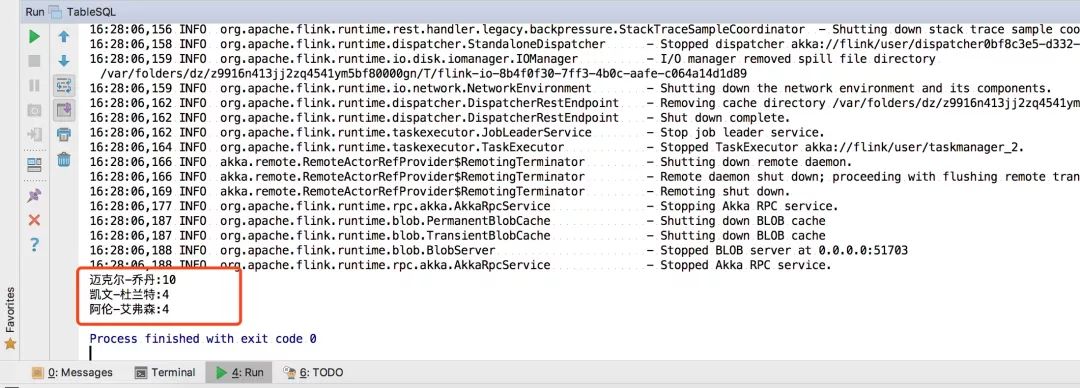
完整的代码如下:
import org.apache.flink.api.common.functions.MapFunction;import org.apache.flink.api.java.DataSet;import org.apache.flink.api.java.ExecutionEnvironment;import org.apache.flink.table.api.Table;import org.apache.flink.table.api.java.BatchTableEnvironment;public class TableSQL { public static void main(String[] args) throws Exception{ //1. 获取上下文环境 table的环境 ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); BatchTableEnvironment tableEnv = BatchTableEnvironment.getTableEnvironment(env); //2. 读取score.csv DataSet
当然我们也可以自定义一个 Sink,将结果输出到一个文件中,例如:
TableSink sink = new CsvTableSink("/home/result.csv", ","); String[] fieldNames = {"name", "num"}; TypeInformation[] fieldTypes = {Types.STRING, Types.INT}; tableEnv.registerTableSink("result", fieldNames, fieldTypes, sink); sqlQuery.insertInto("result"); env.execute();
然后我们运行程序,可以看到 /home 目录下生成的 result.csv,查看结果:
迈克尔-乔丹,10凯文-杜兰特,4阿伦-艾弗森,4
七、总结
本篇向大家介绍了 Flink SQL 产生的背景,Flink SQL 大部分核心功能,并且分别介绍了 Flink SQL 的编程模型和常用算子及内置函数。最后以一个完整的示例展示了如何编写 Flink SQL 程序。Flink SQL 的简便易用极大地降低了 Flink 编程的门槛,是我们必需掌握的使用 Flink 解决流式计算问题最锋利的武器!
-
编程
+关注
关注
88文章
3439浏览量
92369 -
SQL
+关注
关注
1文章
737浏览量
43458 -
应用程序
+关注
关注
37文章
3132浏览量
56359
原文标题:Flink最锋利的武器:Flink SQL入门和实战 | 附完整实现代码
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论